
【初めてのStable Diffusion】最新4通りの始め方を解説!ローカル/生成AI GO/Colab【SDXL・StabilityMatrix対応】

これからStable Diffusionを始める方向けに、最適な始め方を解説します。
・Stable Diffusionのメリット・デメリット
・MidjourneyやDALL-Eとの比較
・AIマンガの現状
・SDXLとSD1.5の違い
なども解説した、現在4.5万文字の記事です。続編の使い方編はこちら。
より分かりやすい動画版はこちら。時間を節約したい方にオススメです。note版は、無料で視聴できます。
■ この記事の使い方 ■

この記事は、4つのパートに分かれます。また、上のような画像を生成できるプロンプト90個以上を、動画講義の方で配布しています。
✓1.Stable Diffusionって何?
まずは、Stable Diffusionって何?から、メリット・デメリットを解説します。
また、MidjourneyやDALL-Eの特徴の解説や比較をして、それぞれのメリット・デメリット、使い道を説明します。
さらに、画像生成AIで漫画は作れるのか?現状の解説もします。
✓2.Stable Diffusionの種類を知る
Stable Diffusionには、以下の3つの種類があります。
・高性能なPCで使う方法(ローカル環境)
・サーバーを借りて使う方法(クラウド環境)
・Webサイトで使う方法(Web版)
それぞれの特徴と違いについて説明します。
✓3.Stable Diffusionを始める
・高性能なPCで使う方法(ローカル環境)
・サーバーを借りて使う方法(Colab2つ、生成AI GO)
の4通りの始め方を解説します。自分に合うものを1つ選んで始めてください。
✓4.Stable DiffusionのXLと1.5の違いを知る
Stable Diffusionには、主に以下の2つがあります。
・まだ現役でよく使われているStable Diffusion1.5
・最新版で高品質なStable Diffusion XL
これら2つの特徴や違いなどを、解説します。
✓ 注意点:使い方の解説は、別の記事で行います
以上が、この記事の概要です。使い方の記事と合わせて、実際に画像生成を試しながら学んでください。
■ 初めての画像生成AI ■
■ Stable Diffusionとは
Stable Diffusionとは、主にテキストから画像を生成できるAIツールです。2022年8月に公開されました。
画像生成AIサービスは、他には
・Midjourney
・DALL-E
・Adobe Firefly
などがあります。それぞれの特徴や違いに関しては、後ほど解説します。

Stable Diffusionの開発元は、以下の通り。
・ミュンヘン大学のCompVisグループ(ドイツ)
・Runway(アメリカ)
・Stability AI(イギリス)
最近は、Stability AI社が開発と普及に取り組んでいるのを、ニュースでよく見かけます。
□ Stable Diffusionで、何ができる?特徴とメリット
Stable Diffusionを使えば、以下のことができます。
・テキストから画像の生成:イラスト風やリアル風など、あらゆる画風や絵柄の再現が可能。
・画像から画像の生成:オリジナル画像をもとに別の画像を生成したり、オリジナル画像の微調整ができます。
・最も絵の微調整ができる:画像生成AIサービスの中で最も多機能なので、画像を調整できる機能が豊富です。
さらにControlNetという拡張機能を使えば
・元画像の絵を保ったまま、色や絵柄だけ変更
・落書きから画像の生成
・特定のポーズの再現
・キャラクターの顔を維持したまま、新たな画像の生成
・画像の内容を保ったまま、画像の拡大・高品質化
など。
Stable Diffusionは、オープンソースであり、世界中の開発者が開発に取り組んでいるので、たくさんある画像生成AIサービスの中で、最も多機能です。例えば、
・再現できる画風/絵柄の種類
・機能や微調整できることの数
は、Stable Diffusionが1番多いです。他にも
・無料で画像生成が可能(ただし高性能なPCがある場合 ※後述)
・暴力やアダルト系の内容でも、自由に画像生成可能
など、オープンソースという強みがあるため、ユーザー数が多く、応用の幅がとても広いです。
□ デメリット
・実質有料
・始め方が難しい
・使い方が難しい
・DALL-EやMidjourneyよりは、手軽に高品質な画像を作れない
Stable Diffusionは、オープンソースであり、無料で使えるのですが、高性能なPCが必要です。15万円くらいの費用がかかります。
PCスペックについては、後ほど説明しますが、GPUが重要です。具体的には、Nvidia製のRTX 3060 VRAM12GBくらいのスペックが必要になります。こんな性能のPCを持っている方は、あまり居ないはずです。結局、ほとんどの方がPCを購入することになるので、お金がかかります。
高性能なPCを持っていなくても、クラウド環境(Google Colab、生成AI GO)などで、GPUを借りながらStable Diffusionを使うこともできます。こちらは、自分のPCの性能が低くても、大丈夫です。ただし、少なくとも月1000円かかるので、他の画像生成AIサービスと同じくらいの費用がかかります。
SeaArtやPixAIなどWebサービス上で、Stable Diffusionが簡単に使えるものもあります。こちらは、無料で使えるサービスもありますが
・Stable Diffusionの機能が限られている
・アダルト系の画像生成に制限がある(規約変更あり)
・たくさん使うには課金が必要
・ユーザーが増えたら有料化することもある
など、Stable Diffusionの良さが激減します。そのため、オススメはしませんが、無料で使えるので、Stable Diffusionのお試しには丁度よいです。
① ローカル環境(高性能なPC)
② クラウド環境(Colab、生成AI GOなど)
③ Web版
いずれも、一長一短です。私は、Stable Diffusionで漫画を作るのが最近の目標なので、①と②を使っています。
①と②では、使い方に少しだけ違いがあります。後ほど解説しますが、①の方がユーザー数が多く、情報の多いので、できれば①を使ってください。
Stable Diffusionでは、できることが最も多いので、その分だけ始め方や使い方が難しいです。ただ、基本的な内容に関しては、私が丁寧に解説するので、Stable Diffusionを1度は使ってみてください。
Stable Diffusionのクオリティは高いですが、DALL-EやMidjourneyほど手軽に高品質な画像は作れません。ただし、画像生成AIサービスごとに、得意不得意があります。例えば、日本人女性に特化した画像を生成するとなると、Stable Diffusionが1番クオリティが高いです。暴力系・エロ系の画像は、Stable Diffusionでしか作れません。
目的ごとに画像生成AIサービスを使い分けるのがオススメです。
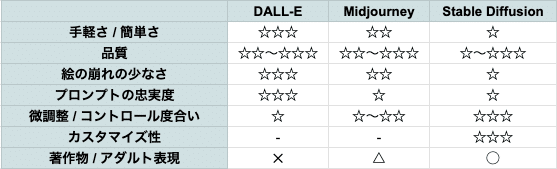
□ 他の画像生成AIサービスとの違いは?
画像生成AIサービスでは
・Stable Diffusion
・Midjourney(にじジャーニー)
・DALL-E
が有名です。特徴と違いは、画像のとおりです。
この画像は、私が感じたことをまとめたものです。ご自身で使ってみて、確かめてみてください。
✓ 手軽さ / 簡単さ
DALL-Eは、ChatGPTやBing AIに搭載されているので、日本語で会話をするように画像生成ができます。この点で、最も簡単に使えるのがDALL-Eです。
Midjourneyは、主にDiscordを使うので少し面倒ですが、慣れてしまえばとても簡単に使えます。
Stable Diffusionは、始めるのも使うのも少し難しいです。習得に最も時間がかかります。
✓ 品質









どれも品質は、十分に高いです。画像生成サービスごとに得意不得意があり、比較するのが難しいです。
強いて言うなら、DALL-EかMidjourneyが最も高品質です。
・手軽に高品質な画像を作るならDALL-E
・オシャレで高品質な画像を作るならMidjourney
です。
Stable Diffusionは、自分で画風や絵柄を選んで画像生成ができるので、再現できないものは無いといっても過言ではありません。例えば、日本人を描きたい場合、Stable Diffusionが1番クオリティが高いです。とはいえ、てきとうに画像生成すると、Stable Diffusionではあまり高品質な絵は作れません。
✓ 絵の崩れの少なさ
品質と被りますが、最も絵の崩れが少ないのがDALL-Eです。画像生成AIでは、手指がおかしいことが多いです。しかしDALL-Eで生成される画像は、そのような絵の崩れがほとんどありません。
✓ プロンプトの忠実度
最も要望どおりの画像が出てきやすいのが、DALL-Eです。DALL-EのAIは優秀で、ユーザーの意図を最も汲み取ってくれます。
MidjourneyとStable Diffusionは、DALL-Eよりは思ったとおりの画像は出てきません。MidjourneyとStable Diffusionの場合は、色々な機能を使い、修正や調整して絵の完成度を上げる必要があります。
✓ 微調整 / コントロール度合い
Stable Diffusionが最もコントロールできます。オープンソースなので機能がとても多く、細かい調整が可能です。特にControlNetを使うと、ある程度ではありますが、特定のポーズを取らせたり、人物を保ったまま色々な画像を作れます。そのため、ビジネスで使うとしたら、Stable Diffusionがオススメです。
Midjourneyは、Stable Diffusionほどではないですが、微調整できる機能があります。
DALL-Eは、現在は微調整できる機能がほとんどありません。
✓ カスタマイズ性
Stable Diffusionはオープンソースなので、多くの機能が実装されていて、自分でも追加することができます。開発のスピードも速くて、最先端のテクノロジーをすぐに試せるのがStable Diffusionです。
他は、企業がAIツールを管理しているため、カスタマイズすることはできません。
✓ 著作物 / アダルト表現
Stable Diffusionは、NGなしで自由に画像生成ができます。何でもアリの世界です。
Midjourneyは、著作物や有名人はある程度は生成できますが、エロ系は生成できません。
DALL-Eは、エロ系だけではなく、著作物や有名人すら生成できないことが多いです。
それぞれのAIツールに、得意・不得意があるので、用途に合わせて使い分けるのがオススメです。例えば、
・手軽に簡単に画像生成したいならDALL-E
・オシャレな1枚絵を作りたいならMidjourney
・絵をコントロールし、目的通りの絵を作りたいならStable Diffusion
という風に使っています。
□ 画像生成AIで漫画は作れる?現状を解説


1年前はAI漫画を作るのは無理に近くて、この記事でも、そのように記載していました。しかし最近になり、ある程度は作れるようになってきました。
まだ難しい表現はできませんが、Stable DiffusionやControlNetの性能が上がったことで、かなり漫画の形に近づけられます。
実際に私もAI漫画を作り、販売しています。すみませんがアダルト向けなので、内容と規約的に、ここでは公開できません。
その代わり、培ってきたAI漫画の作り方を、こちらで公開します。動画版もあります。
以前ここに記載していた内容は、古くなったので消去しました。代わりとして、AI漫画制作の流れを以下に記載します。できそうな方は、私の漫画講義は不要です。自信がない方は、ぜひ上記の漫画講義も見てみてください。
AI漫画制作の手順
・物語のセリフを、クリスタに配置する
・ControlNetを使うため、シーンに合う画像を探す(自撮りや3DCGでもOK)
・Cannyを使い画像を生成する(簡単なシーンであれば、普通の生成でもOK)
・プロンプトやWeightを調整しても上手くいかない場合は、別の画像を探すか、ポーズを変えてみる
・Batch countを増やしたり、XYZ plotで画像を一気に生成し、修正の手間が少なそうなイラストを選ぶ
・インペイント、ADetailerなどで、イラストの修正をする
・img2imgとControlNetで画像を拡大する
・AIイラストをクリスタに配置し、トーン化する
・コマ枠を作成し、AIイラストやフキダシなどを配置する
・LT変換し、手描きでAIイラストを修正する
・効果線を追加する
・グレー化して書き出す
■ Stable Diffusionの始め方 ■
■ はじめ方の種類

先ほど少し説明したとおり、Stable Diffusionを始めるには、大きく分けて以下の3種類があります。 それぞれのメリット・デメリットは、画像のとおりです。
① ローカル環境(高性能なPC)
② クラウド環境(Colab、生成AI GOなど)
③ Web版
本格的にStable Diffusionで画像生成をして行くとすると、できれば①、厳しいなら②を使っていくことになります。③は、お試しには良いですが、先ほど話した機能制限などの理由から、本格的使用の候補から除外します。
□ ①ローカル環境
ローカル環境は、安くない初期費用がかかります。しかし、ユーザー数と情報が最も多くて、困ったときには調べればだいたい解決します。最もストレスなくStable Diffusionを使いたいなら、ローカル環境にしてください。
以前までは、ローカル環境で始めるために、PythonやGitのインストールが必要だったり、ターミナル(黒い画面)を開いて、コードを入力する必要があったり、面倒でした。しかし最近になって、StabilityMatrixというツールが登場しました。
StabilityMatrixは、Stable Diffusionを簡単にインストールして始められるようにしたツールです。クリックだけでローカル環境版のStable Diffusionを始められます。
StabilityMatrixの特徴は、以下のとおり。
・簡単に開始可能:GitやPythonのインストールなし、クリックするだけ
・追加コマンドも簡単:低VRAM向けの設定などが、クリックするだけ
・モデルの管理が簡単:モデル(チェックポイント)、VAE、LoRA、拡張機能などを一括で管理できて、他WebUIに流用可能(WebUIごとのインストール不要)
・フォルダは、別のドライブやコンピュータに移動可能
StabilityMatrixのおかげで、Colabなどのクラウド環境でStable Diffusionを始めるのと同じくらい簡単になりました。これから始める方も、既にローカル環境でStable Diffusionを使っている方も、StabilityMatrixに切り替えるメリットは、相当あります。
ただし
・Macユーザー
・Windowsだけど、GPUがNvidia製以外の方
・GPUの性能が低い方(VRAM6〜8GB以下くらい)
は、次に解説するクラウド環境がオススメです。
□ ②クラウド環境(Colab、生成AI GOなど)
クラウド環境では、GPUなどのPCの性能が低かったり、Macユーザーの場合に、オススメです。
また、クラウド環境は、以前まではローカル環境よりも簡単にStable Diffusionを始めることができました(初心者向けのテンプレを使えば)。
しかし、先ほど話したとおり、StabilityMatrixが登場したため、「クラウド環境の方が、ローカル環境よりも簡単に始められる」とは言いにくくなりました。
さらに、モデルや拡張機能を使うには、普通は自分でコマンドを入力してコードを編集する必要があります。後で私が紹介するColab版を使えば、この工程を省略できるので簡単ですが、それでもデメリットがあります。
メリット
・MacやNvidia以外のGPUのPC/低性能PCユーザーでも、快適に画像生成できる
・ローカル環境よりは、手軽に始められる
・初期費用が月1000〜なので、大きく損することはない
デメリット
・テンプレのコードにないものは、自分で編集する必要があり、非エンジニアには難しい(長期的に見ると、ローカル環境の方が非エンジニア向け)
・ローカル環境よりも情報が少ない
・起動やモデルの切り替えに時間がかかる(生成AI GOは速いです)
・数年単位で考えると、高性能なPC費用と同じくらいの金額がかかる
私は、Stable Diffusionをローカル環境で始めましたが、Macを使いたかったためクラウド環境を使うようになりました。しかし、起動に時間がかかるため、最近はローカル環境を使っています。(ちなみにMacからリモートデスクトップでWindowsを使っています)
□ ③Web版(SeaArt、PixAIなど)
SeaArtやPixAIなどWebサービス上で、Stable Diffusionが簡単に使えるものもあります。中身はほとんどStable Diffusionだったり、カスタマイズされたStable Diffusionだったりと、様々です。
こちらは、無料で使えるサービスもありますが
・Stable Diffusionの機能が限られている
・アダルト系の画像生成に制限がある(規約変更あり)
・たくさん使うには課金が必要
・ユーザーが増えたら無料お試しができなくなることがある
など、Stable Diffusionの良さが激減します。そのため、オススメはしませんが、無料で使えるのでStable Diffusionのお試しには丁度よいです。
・テキストから画像を生成するだけで十分
・微調整や難しいことはしない
という方は、Web版がオススメです。
■ Stable Diffusion WebUIの種類
Stable Diffusionは、画像を生成するためのAI技術ですが、Pythonというプログラミング言語で開発されているので、本来はプログラミングなどの知識が必要です。しかし、 Stable Diffusion WebUIという、Stable DiffusionをWeb上で簡単に使えるサービスが開発されたおかげで、非エンジニアでもStable Diffusionが簡単に使えるようになっています。
この画面がStable Diffusion WebUIであり、その内部で動作しているのがStable Diffusionです。よって、この2つは別々のものです。
とはいえ、Stable Diffusionは、Stable Diffusion WebUIという意味で話されることも多いので、この記事でも
・Stable Diffusion
・Stable Diffusion WebUI
は、あまり区別せずに話します。
そのStable Diffusion WebUIには、いくつか種類があります。1番使われているのが、「stable-diffusion-webui」です。AUTOMATIC1111さんが、主に開発しています。
8〜9割以上の Stable Diffusionユーザーが、このWebUIを使っているように感じます。Stable Diffusion WebUIと言ったら、これのことだと思ってください。
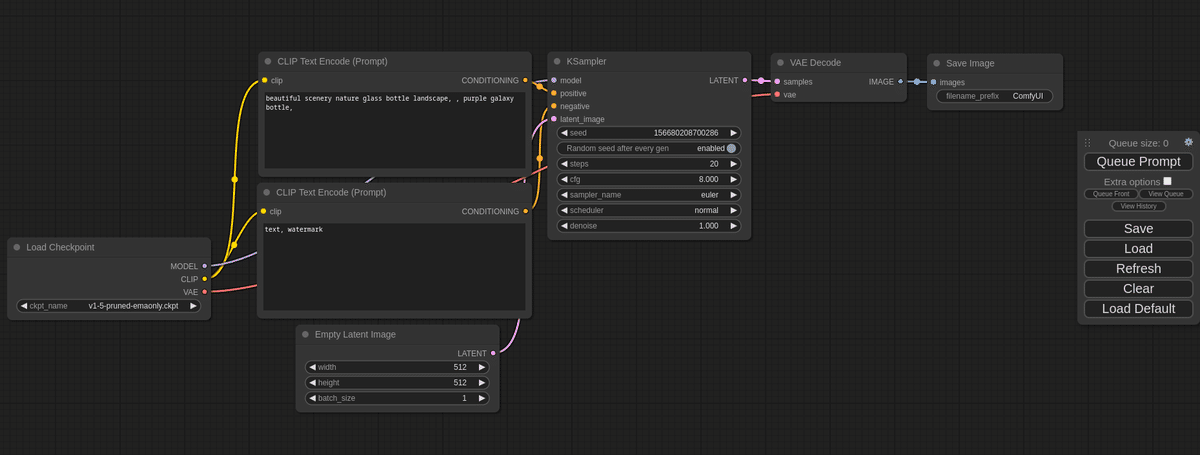
他には、
・ComfyUI:ノードで画像生成するWebUI
・Fooocus:機能を減らしシンプルにしたWebUI
など、最近は色々あります。ただし、調べたときに出てくる情報は、ほとんどがAUTOMATIC1111さんのWebUIなので、初心者ほど、こちらを使うようにしてください。
■ ローカル環境で、Stable Diffusionを始める方法(StabilityMatrix)
ここでは、StabilityMatrixを使い、ローカル環境でStable Diffusionを始めます。
クラウド環境で始める方は、読む必要はありません。「クラウド環境でStable Diffusionを始める方法」まで飛ばしてください。
□ PCスペックの確認
PCが以下のものか確認してください。これから確認方法も紹介します。
・Windows
・Nvidia製のGPU
・VRAMが6〜8GB以上
以下の場合は、クラウド環境の利用をオススメします。
・Macユーザー
・Windowsだけど、GPUがNvidia製以外の方
・GPUの性能が低い方(VRAM6GB以下くらい)
前2つは、ローカル環境でもできますが、情報が少なくて初心者向けではありません。また、低VRAMだと画像生成にとても時間がかかったり、エラーが出るので、オススメしません。できれば、後で解説するクラウド環境を使ってください。
GPUとは、画像処理や動画処理などのグラフィック処理に使われるPCの部品です。VRAMは、GPU専用のメモリのことです。普通のメモリ(システムRAM)とは異なるので、注意してください。
ちなみにPCの部品は、以下のように例えられます。
・CPU:頭脳
・メモリ:机の広さ
・GPU:画家や絵筆
画像生成AIでは、GPUとくにVRAMが重要です。VRAMの容量が大きいほど、GPUが一度に処理できるデータが増えるので、その分、画像生成が速くなります。
注意点として、同じ画像サイズであれば、GPUが高性能であっても、生成される画像の品質は変わらないです。高価なGPUだからといって、上手い絵が生成されるわけではありません。
ただし、GPUが高性能だと、大きな画像を作れます。低性能だと、大きな画像を作るのに時間がかかったり、エラーが出てしまうことがあります。1番よく使われているRTX3060 VRAM12GBでは、画像サイズが1500×1500くらいになるとエラーが出てくるので、それ以上のサイズを生成するには拡張機能を入れるなどの工夫が必要です。
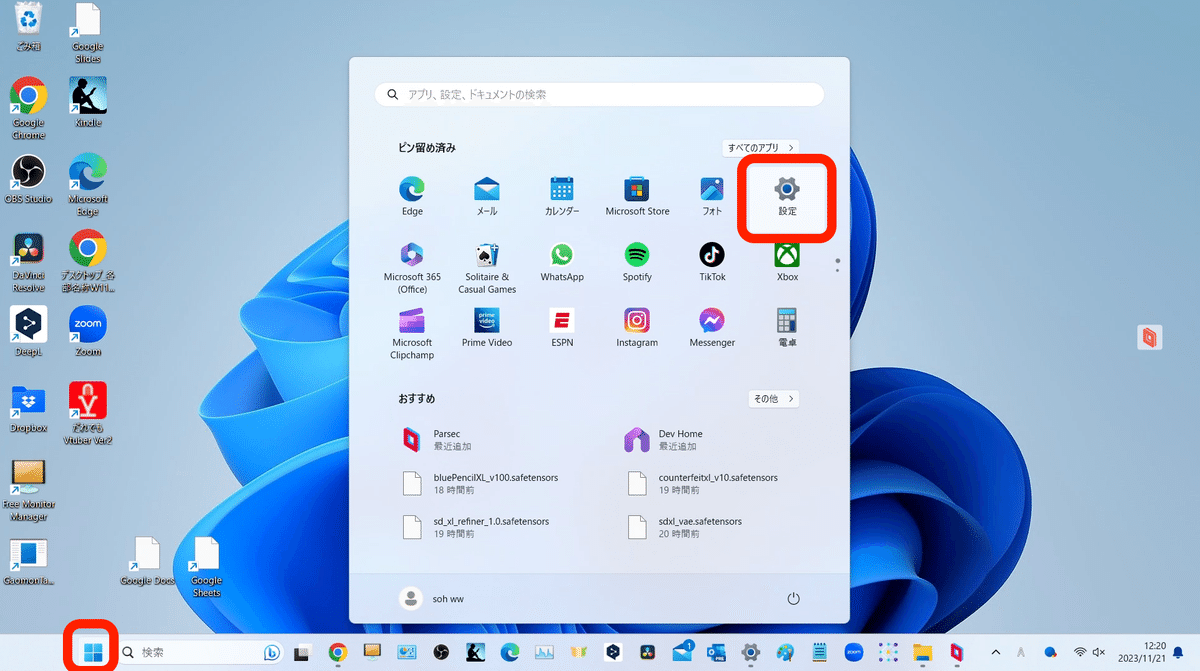
Windowsマーク → 設定から
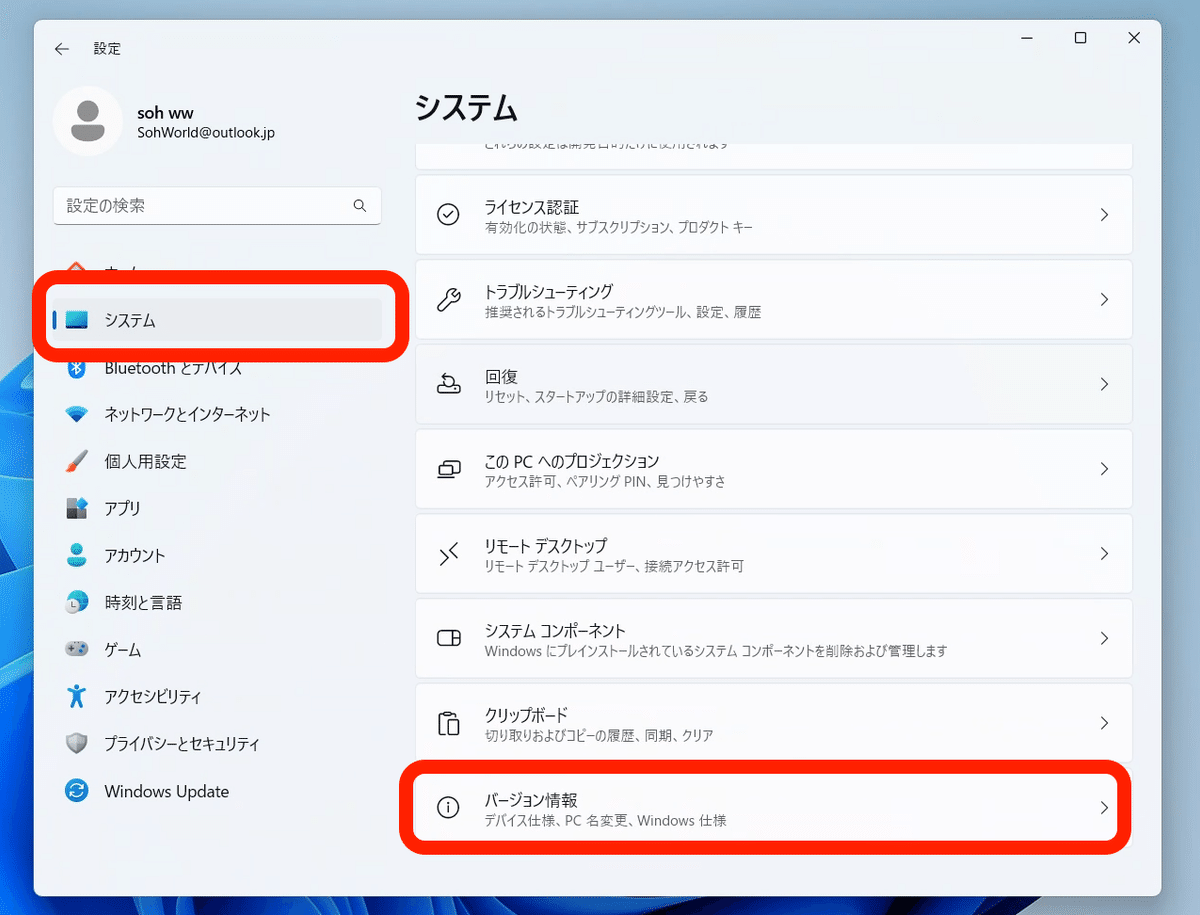
システム → バージョン情報 をクリックすると、自分のPC情報が分かります。ただし、GPUの情報がないので、
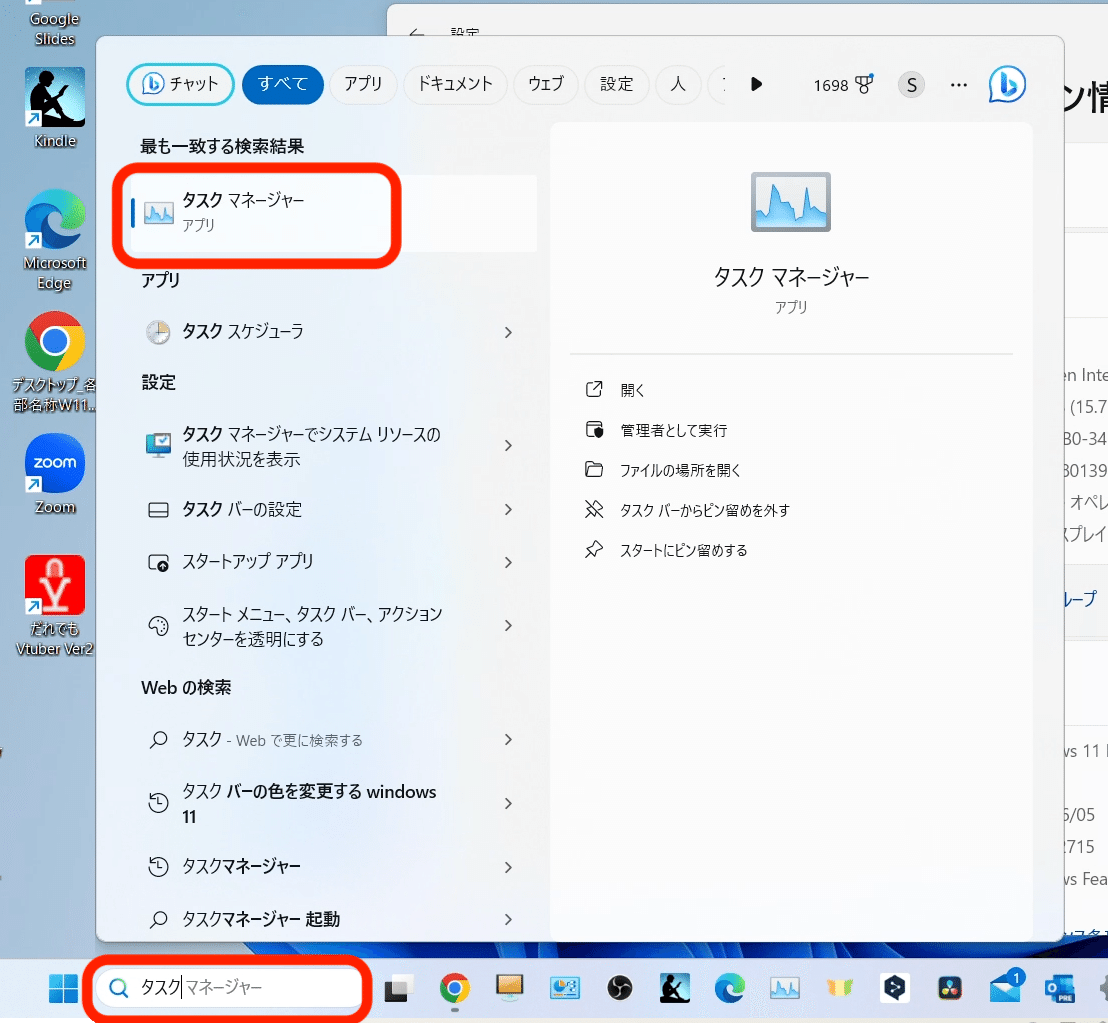
検索欄から「タスク」と入力すると、タスクマネージャーが表示されるので、クリックするか、
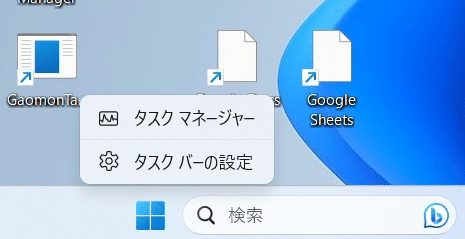
下にあるタスクバーを右クリックすると、タスクマネージャーが表示されるので、クリックしてください。
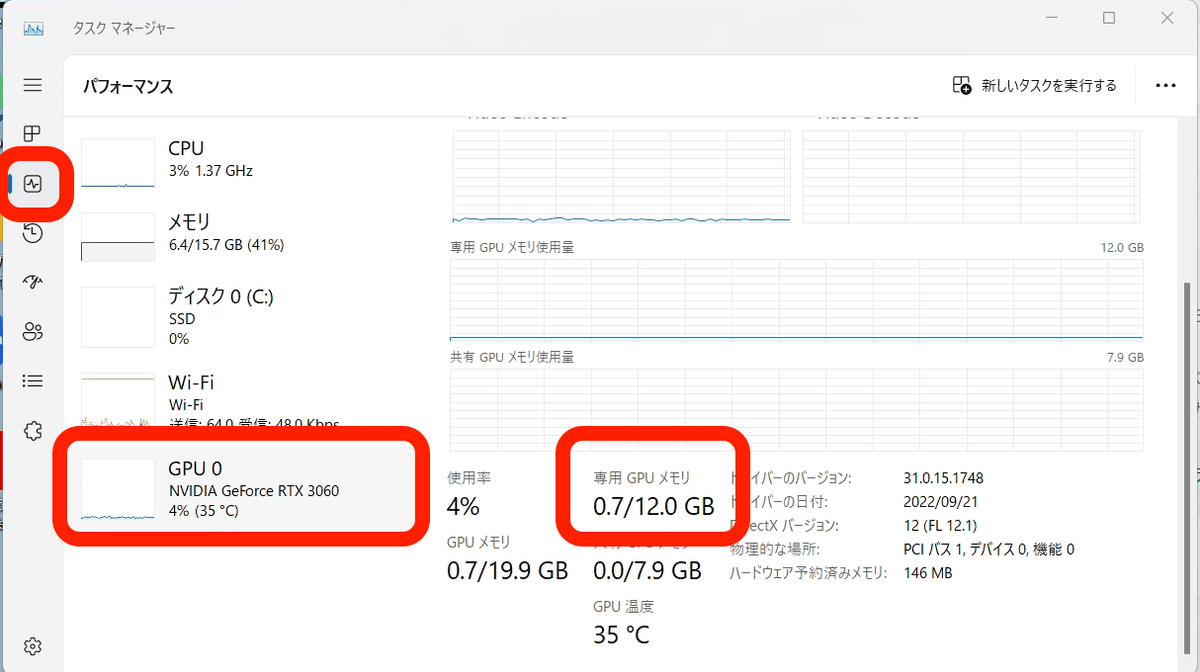
これがタスクマネージャーです。左側のパフォーマンスを選び、GPUをクリックするとGPU情報が表示されます。少し下にスクロールすると、専用GPUメモリがあり、これがVRAMです。画像生成では、VRAMをたくさん使うので、重要です。

私が使っているPCは、こちらです。ドスパラは、サイトが見やすく、発送がとても早いので、オススメです。
私はPCの専門家ではないので、簡潔に説明しますが、初心者に最もオススメされるGPUが「GeForce RTX 3060 VRAM12GB(Nvidia製)」です。他のサイトを調べてもらえれば分かる通り、これがエントリーモデルとして初心者に1番オススメされています。PC代金は、15万円くらいです。
Stable Diffusionは、VRAM6〜8GBでも動きますが、画像生成のスピードがとても遅くなります。また、Stable Diffusionの最新版である、Stable Diffusion XL(SDXL)では、要求されるGPU(VRAM)の性能がさらに上がっています。
もし、これからPCを買うなら、最低でも「GeForce RTX 3060 VRAM12GB(Nvidia製)」、できれば「VRAM16GB」がオススメです。お金に余裕があるなら、さらに高性能のVRAMを選んでも大丈夫です。
また、
・メモリ(システムRAM):16GB以上
・ストレージ:Stable Diffusionだけで、50〜100GBくらいは使うので、500GBのSSDがオススメです。HDDは処理が遅くなるので、オススメしません。私は1TBのSSDを買いました。
・CPU:重要ではありません。最近のものであれば、大丈夫です。
□ StabilityMatrixを使い、Stable Diffusionを始める方法
以前までは、ローカル環境で始めるために、PythonやGitのインストールが必要だったり、ターミナル(黒い画面)を開いてコードを入力する必要があったり、面倒でした。しかし最近になって、StabilityMatrixというツールが登場しました。
StabilityMatrixは、Stable Diffusionを簡単にインストールして始められるツールです。このおかげで、クリックするだけでローカル環境でStable Diffusionを始められます。
StabilityMatrixの特徴は、以下のとおり。
・簡単にSDを開始可能:GitやPythonのインストールなし、数クリックするだけ
・追加コマンドも簡単:低VRAM設定などが、クリックするだけ
・モデルの管理が簡単:モデル(チェックポイント)、VAE、Embedding、LoRA、拡張機能などを簡単にインストール&一括で管理可能。また、他UIに流用可能(UIごとのインストール不要)
・Stable Diffusionをインストールするときにできるフォルダは、別のドライブやコンピュータに移動可能(ポータブル版のみ)
StabilityMatrixのおかげで、Colabなどのクラウド環境でStable Diffusionを始めるのと同じくらい簡単になりました。これから始める方も、既にStable Diffusionを使っている方も、StabilityMatrixに切り替えるメリットは、相当あります。
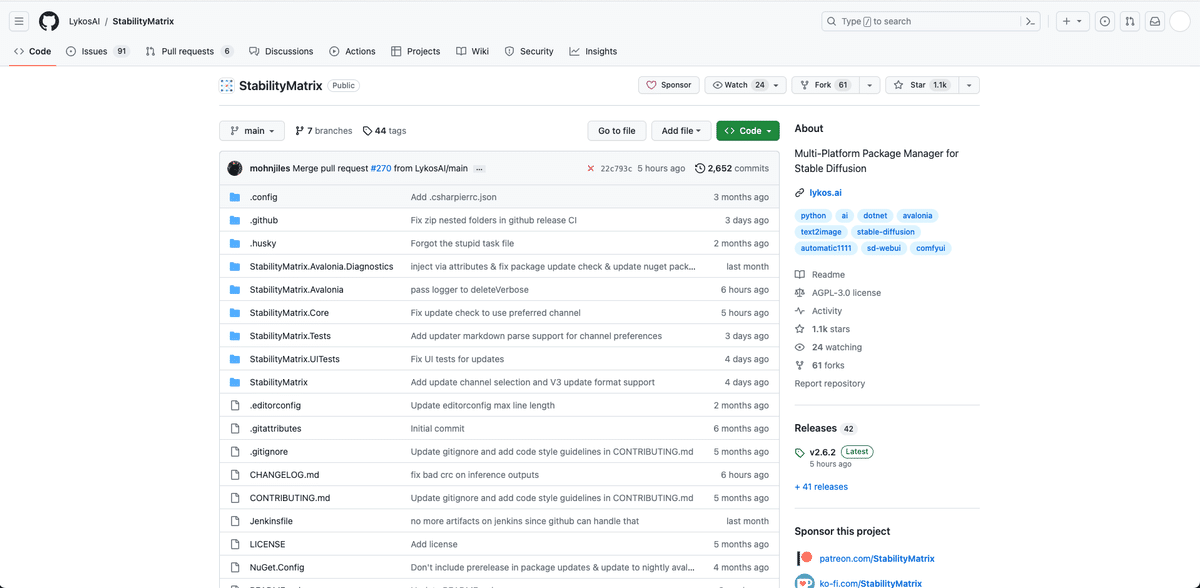
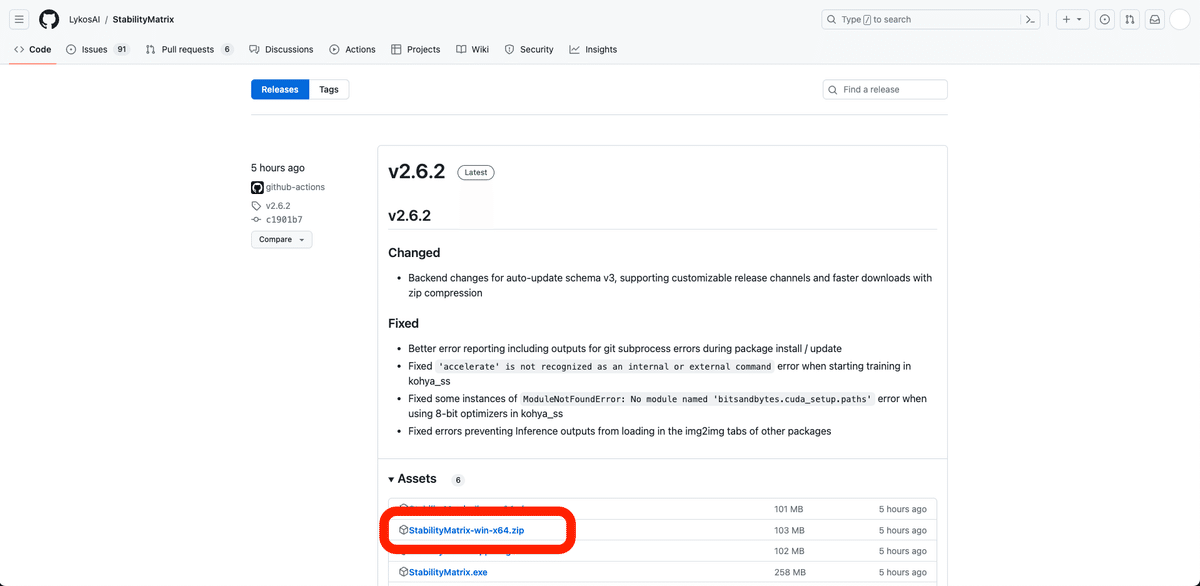
GitHubの公式ページのこちらから、「StabilityMatrix-win-x64.zip」をダウンロードしてください。バージョンは、最新のものを選んでください。
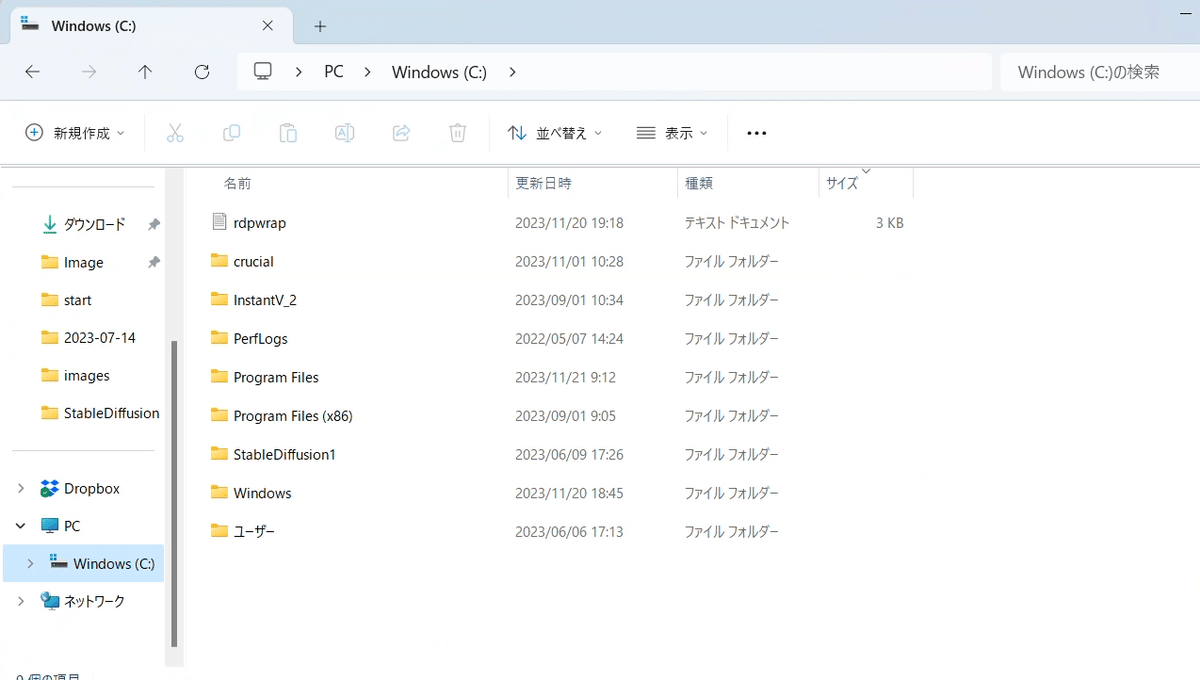
保存場所は、Cドライブがオススメです。ストレージがSSDのドライブに保存してください。ストレージがHDDだと、動作が遅くなってしまうことがあるからです。
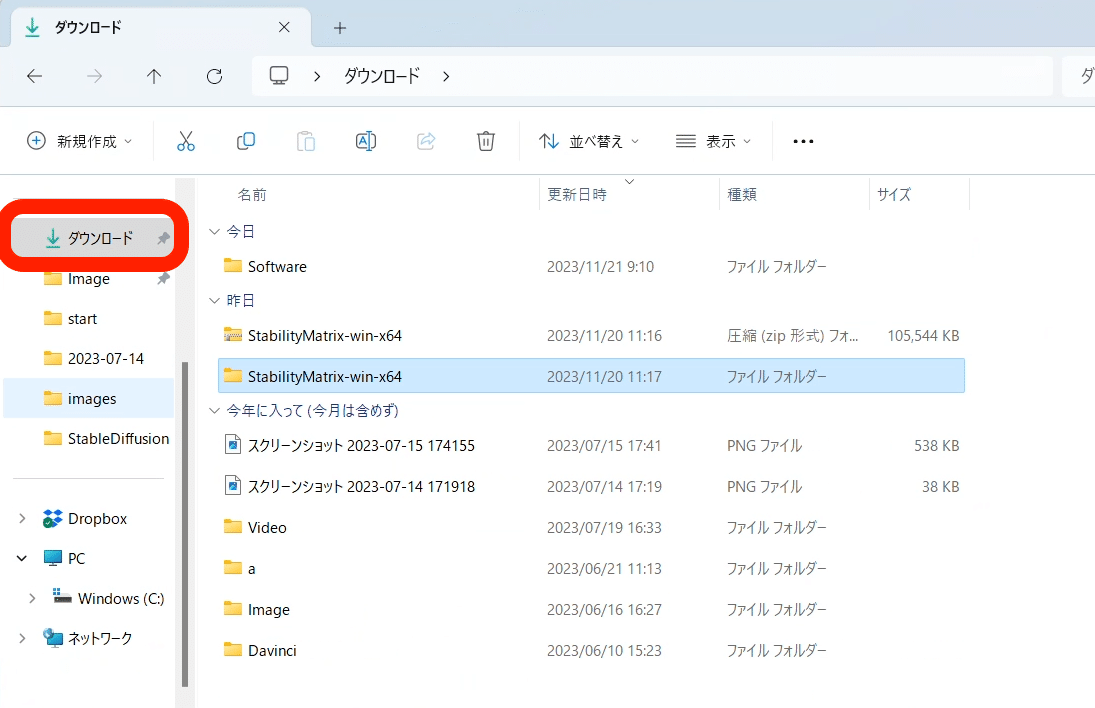
Cドライブ直下に保存しようとしたら、なぜかできなかったので、私は「ダウンロード」に保存しました。
保存場所は、後からでも変えられます。
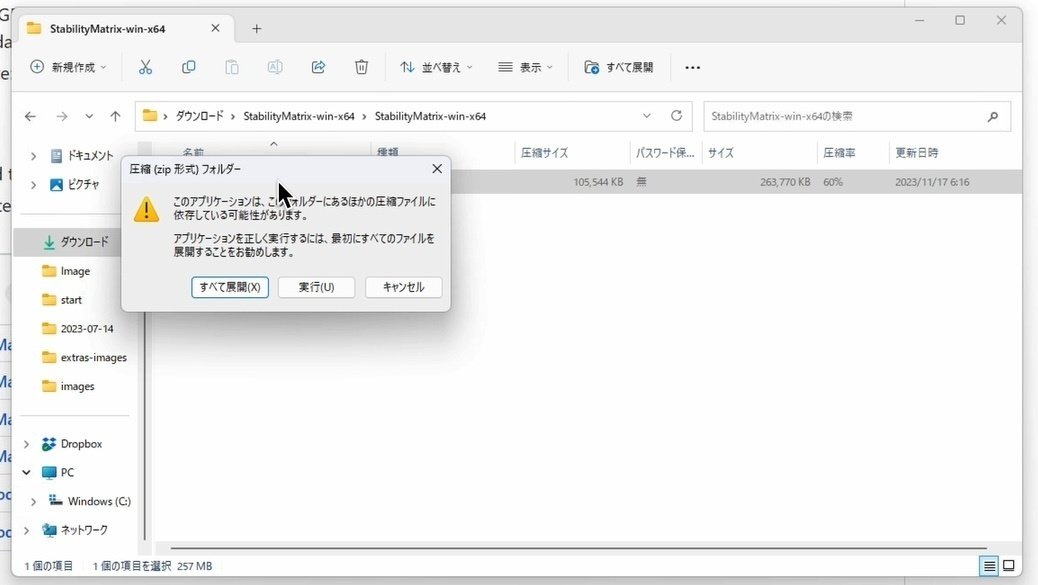
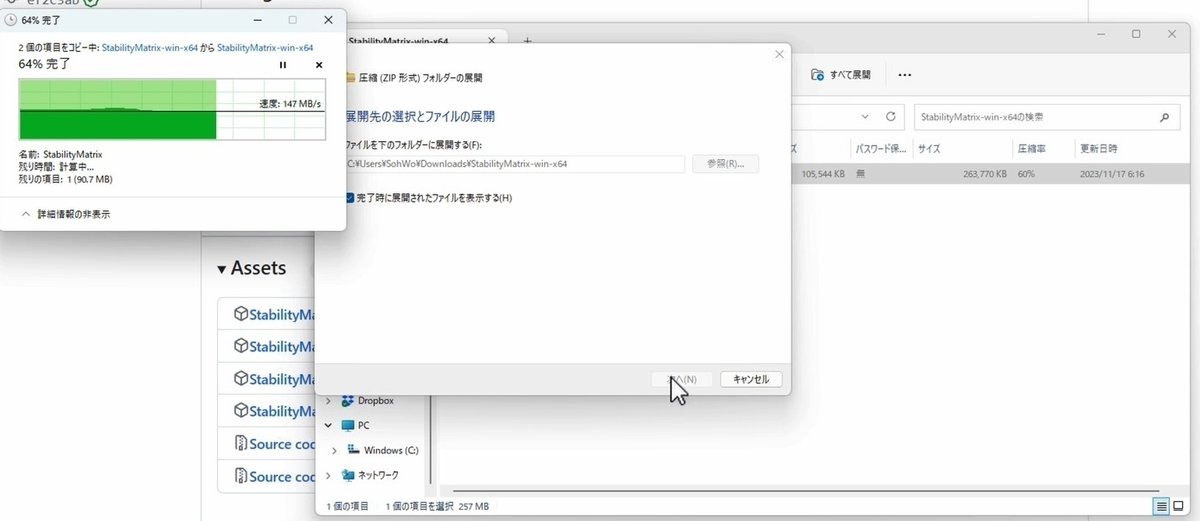
ダウンロードしたフォルダをダブルクリックすると、このような画面になります。「すべて展開」をクリックしてください。
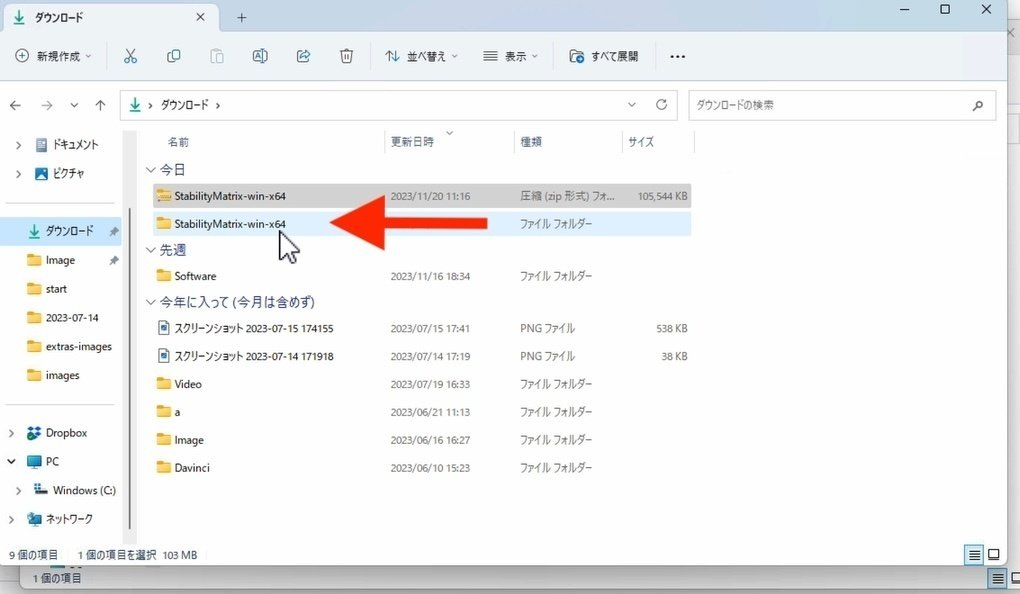
展開した方のフォルダを開き、
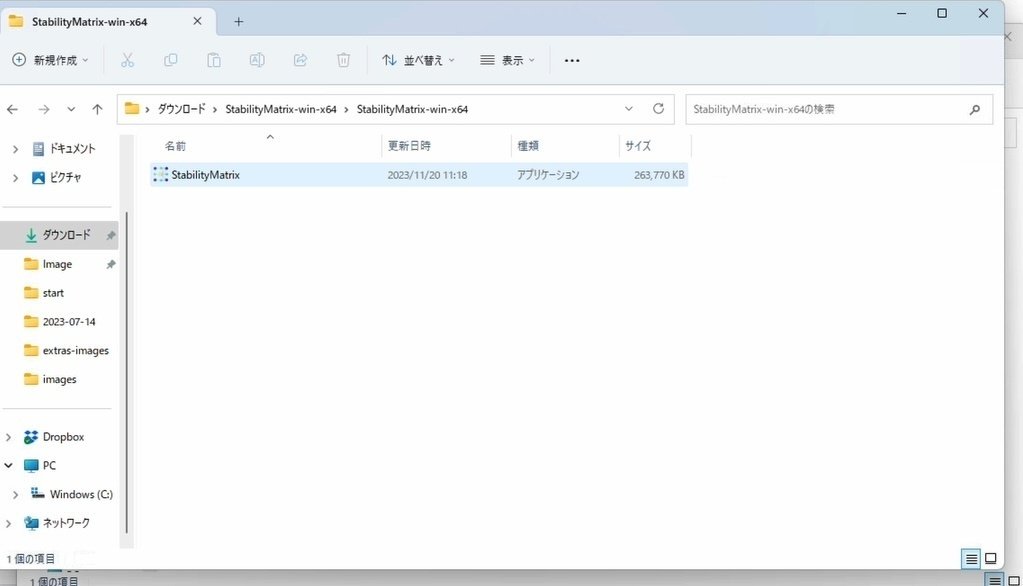
StabilityMatrixをクリックしてください。
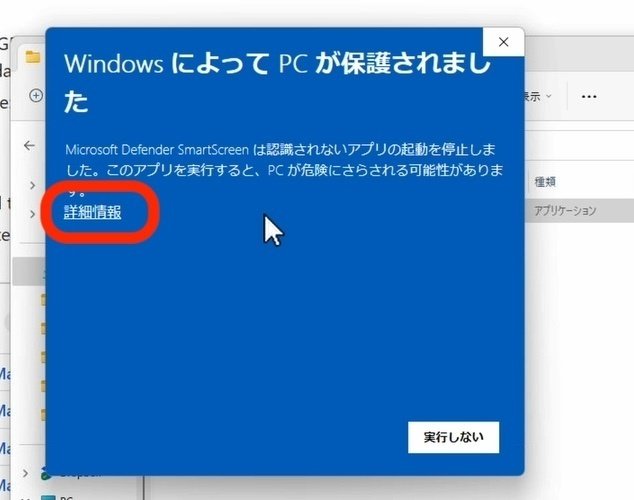
これが表示されるので、詳細情報 → 実行 をクリックしてください。
この画面になるので、「同意」にチェックを入れて、「続ける」をクリックしてください。
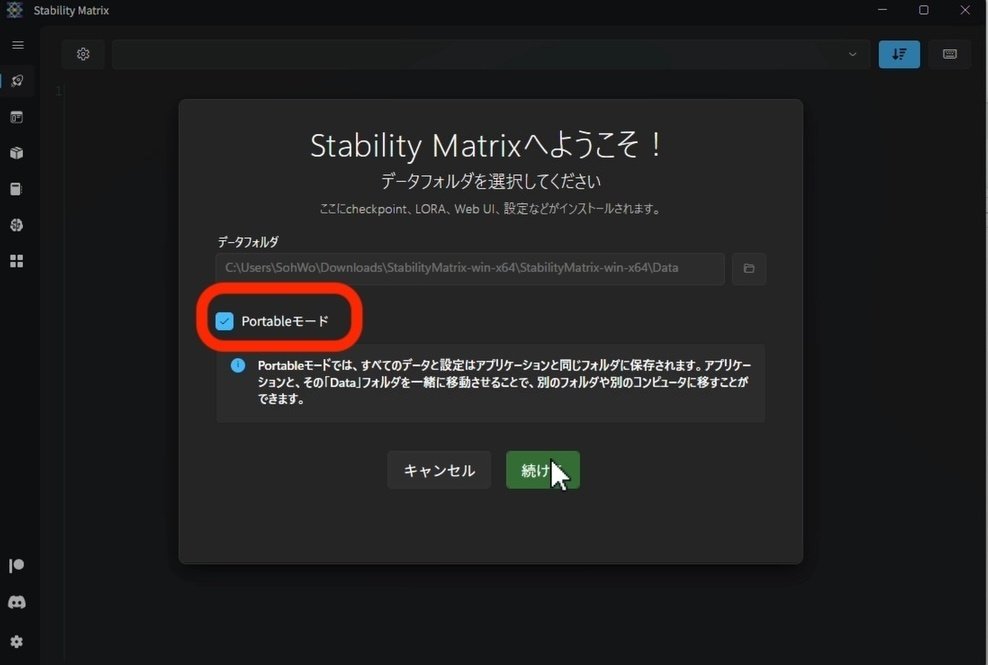
ポータブルモードにチェックを入れると、書いてあるとおり、後からフォルダの場所を変えられるので、チェックを入れるのがオススメです。あとは、「続ける」をクリックしてください。
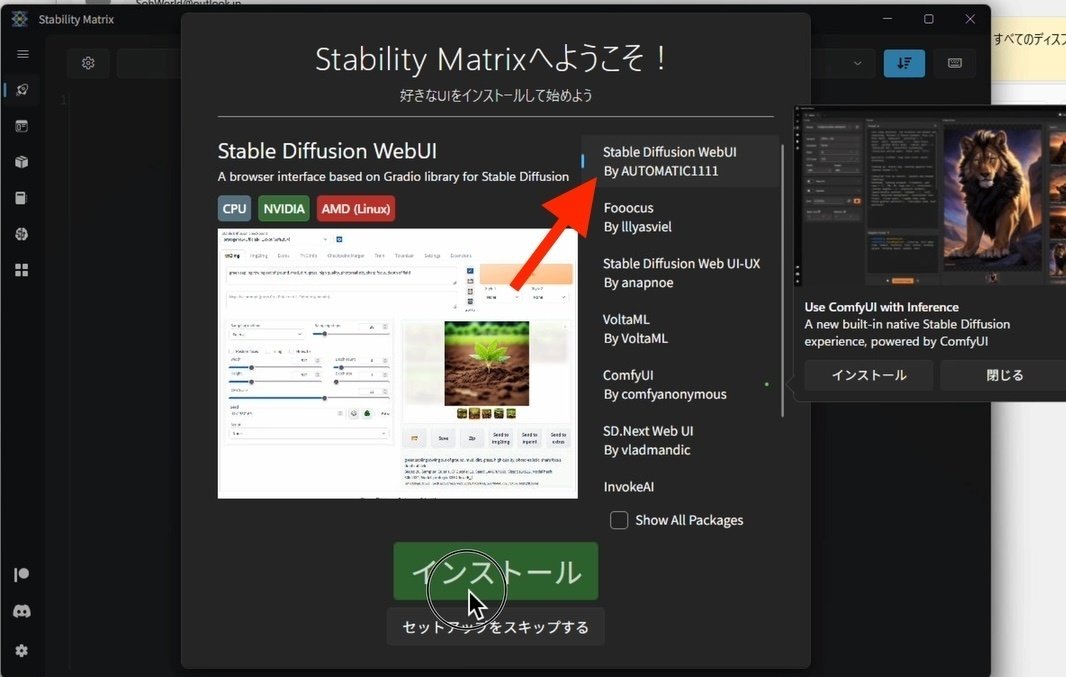
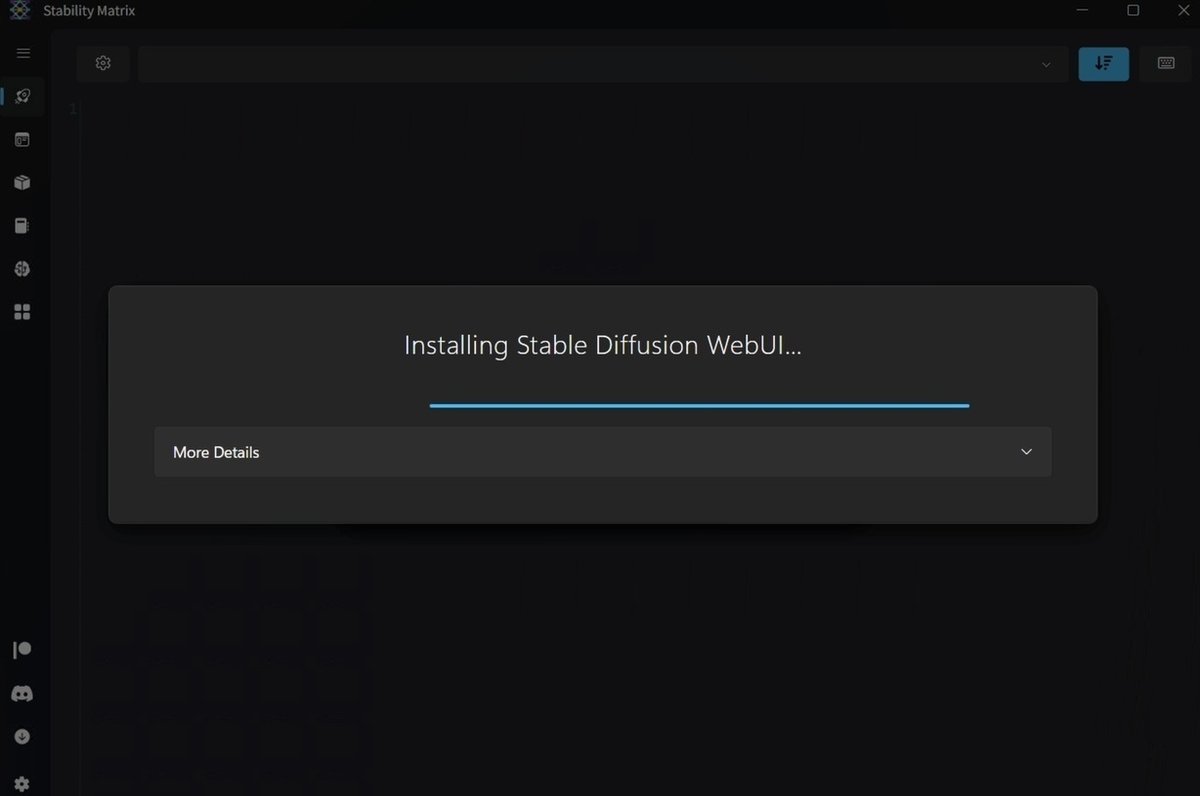
右上の、「Stable Diffusion WebUI By AUTOMATIC1111」を選択し、インストールをクリックしてください。インストールには、数十分かかります。私の場合は、たしか30分以上はかかった気がします。
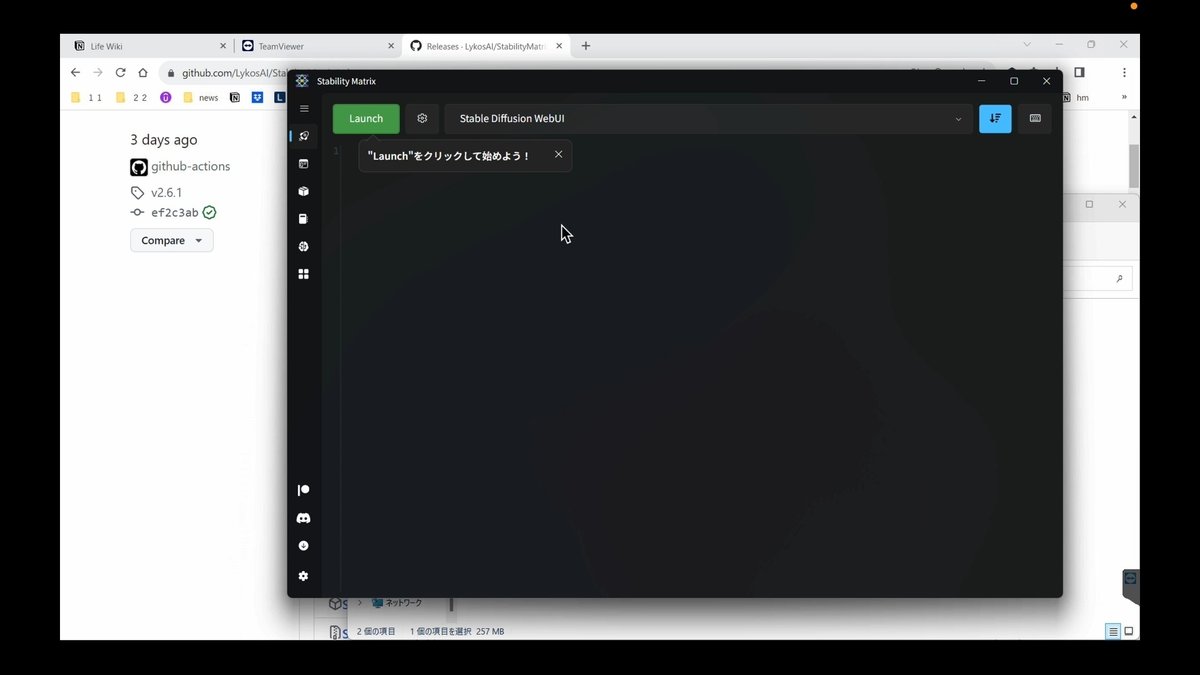
インストールが終わると、このような画面になるので、「Launch」をクリックしてください。
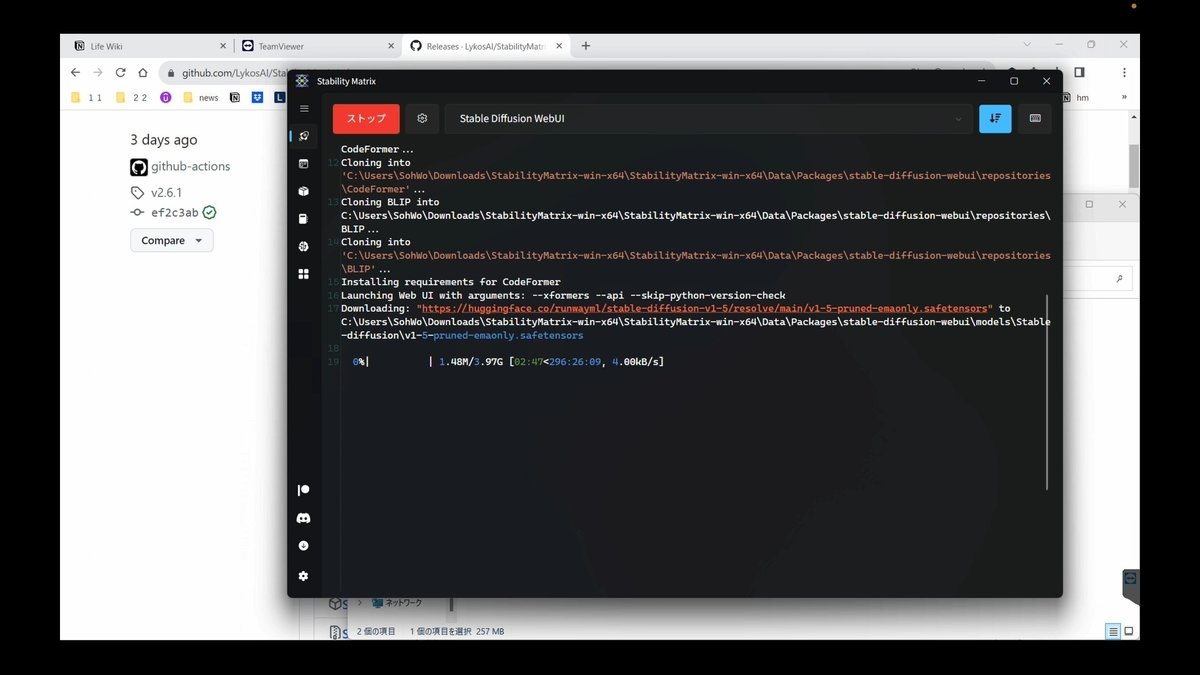
次は、初期モデル(ベースモデル)のインストールで、さらに数十分〜数時間かかります。時間がかかるのは、初回だけで、2回目からは数秒で起動します。
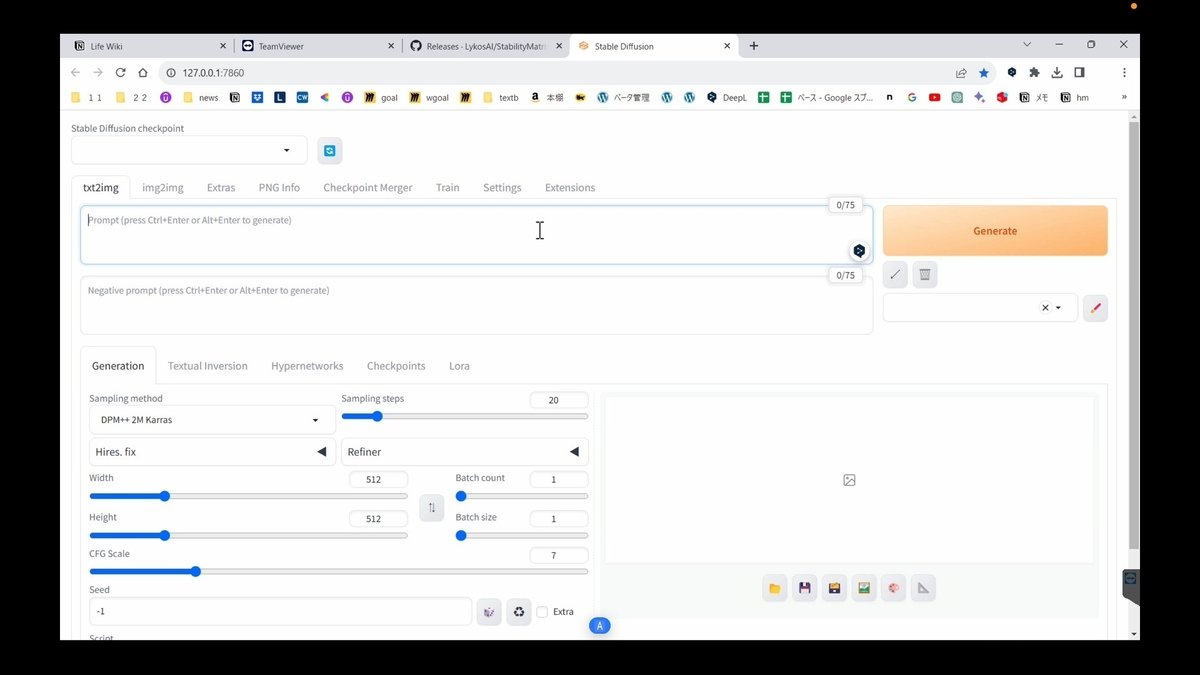
すべてが完了すると、自動でこの画面が開かれます。これがStable Diffusion WebUIです。この画面が開かれなかった場合は、
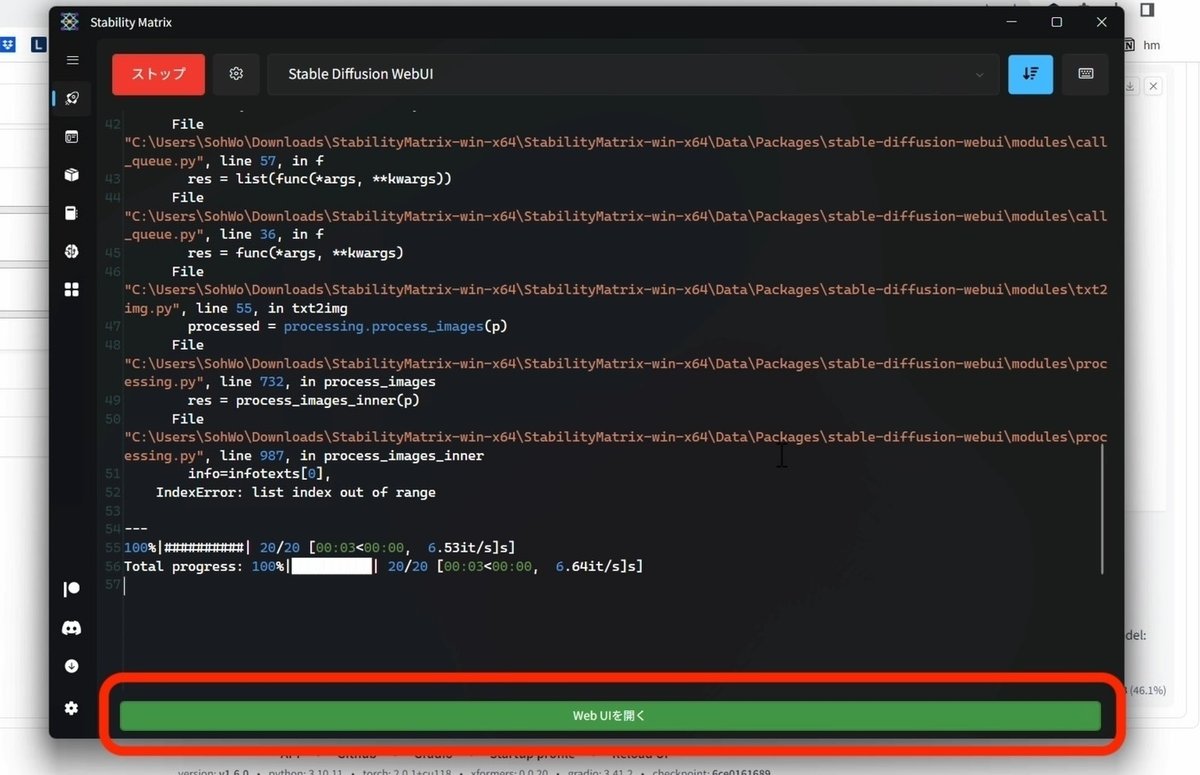
StabilityMatrix画面の下にある「WebUI開く」をクリックしてください。
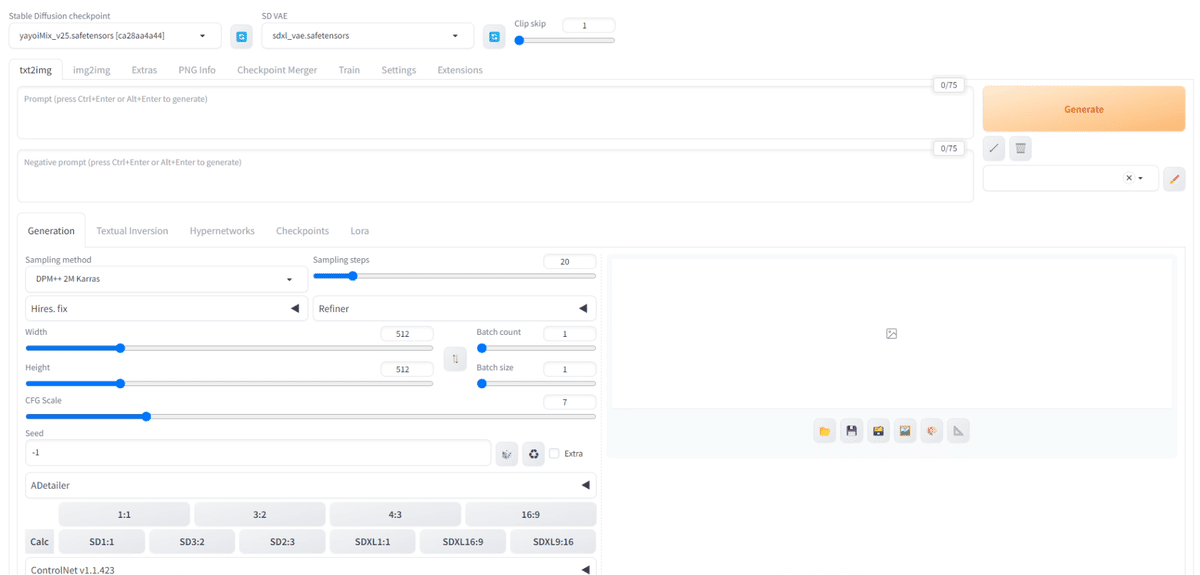
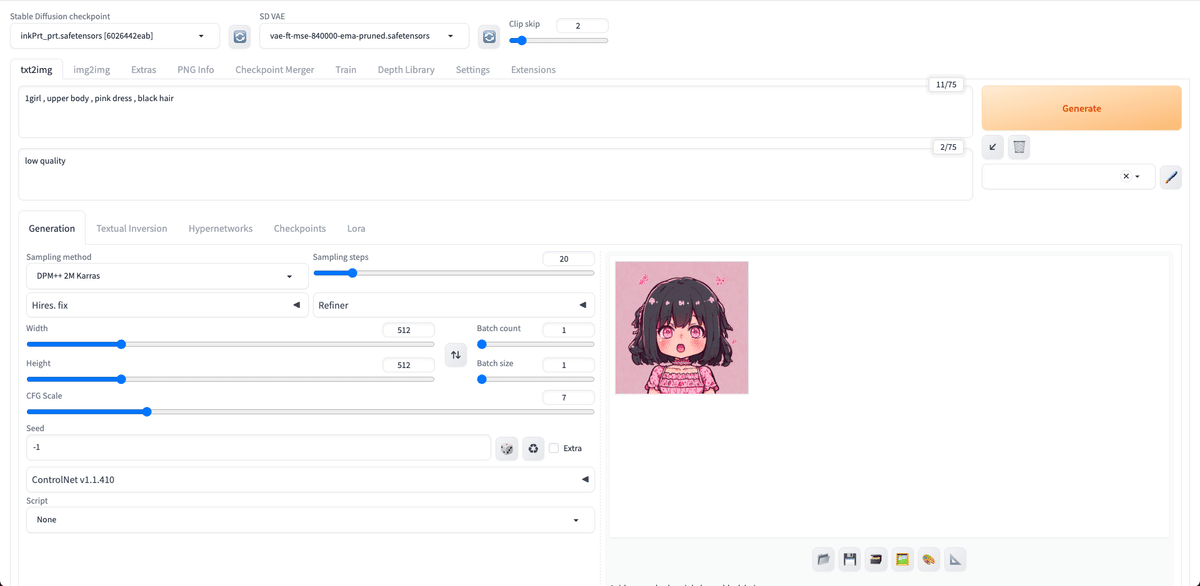
□ 基本操作
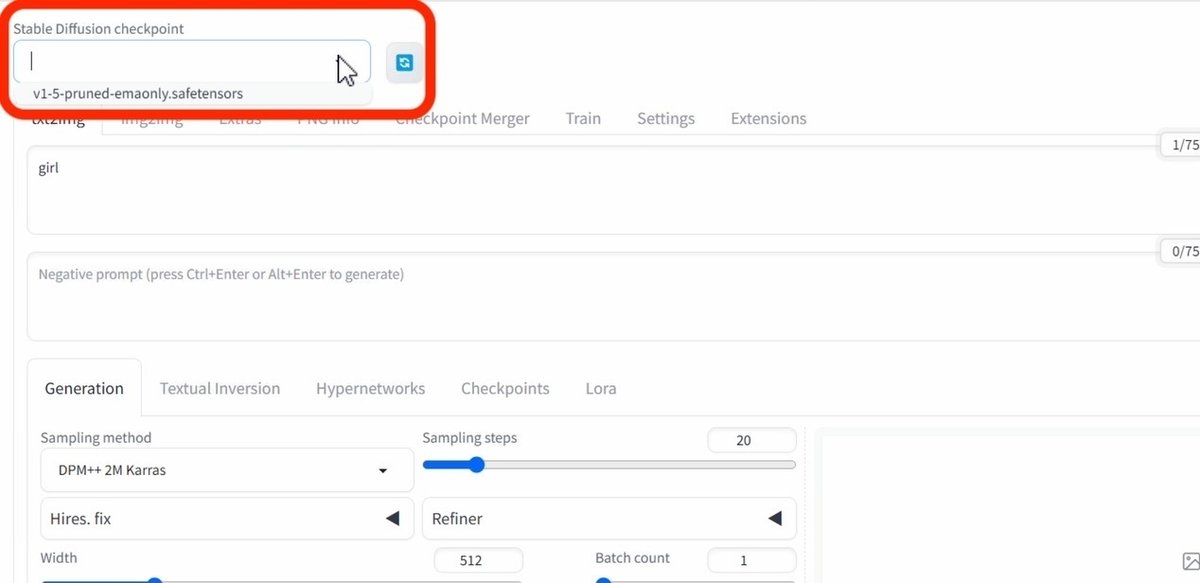
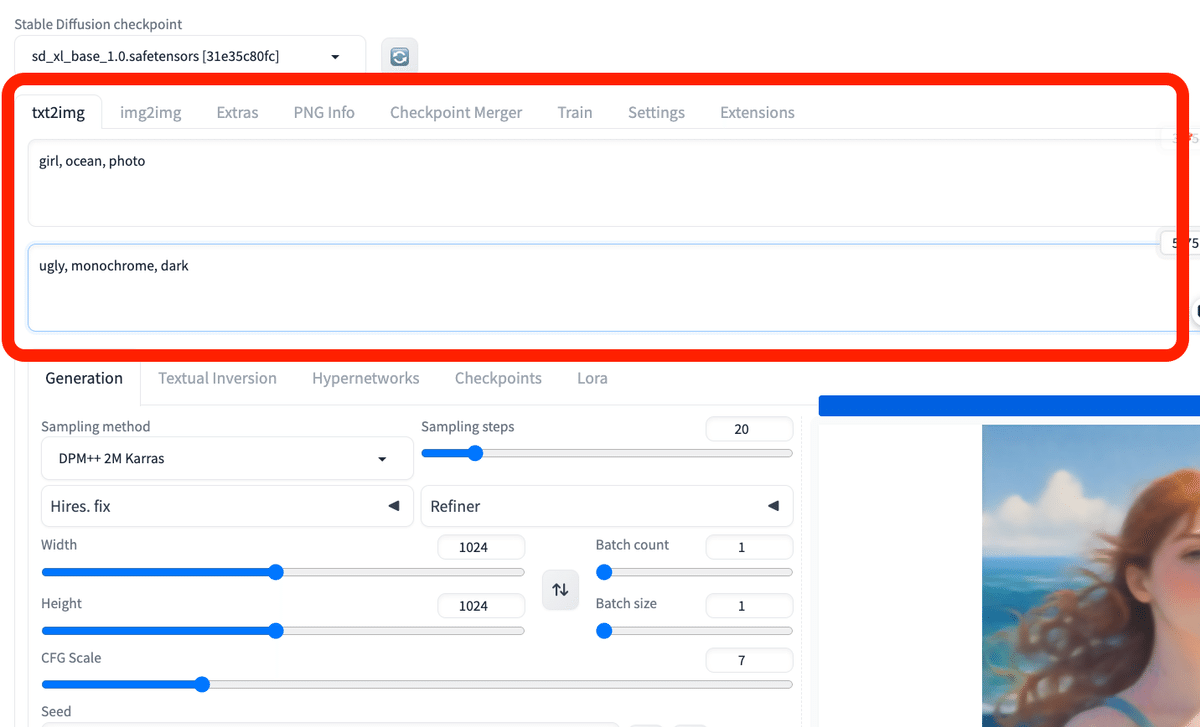
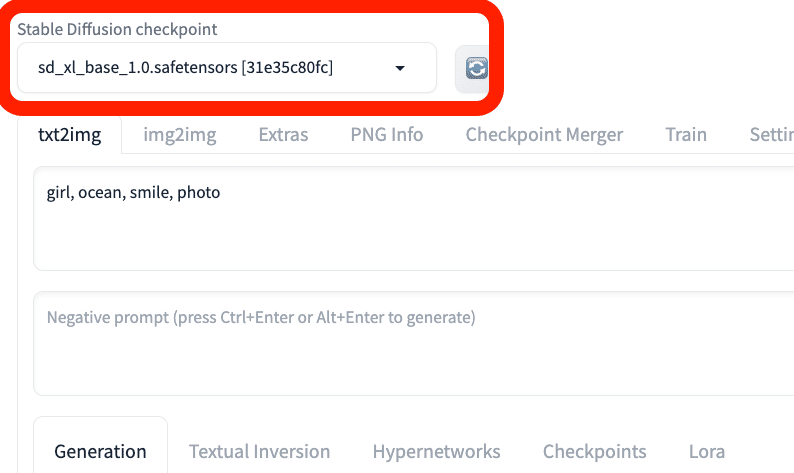
画像生成するには、まず「Stable Diffusion Checkpoint」でチェックポイントを選択してください。チェックポイントは「モデル」と呼ばれることが多いですが、同じ意味です。モデルとチェックポイントという言葉は、覚えてください。
初期モデルが1つ入っているので、それを選択してください。Stable Diffusionの公式モデル(ベースモデル)では、あまり高品質な画像は生成できないので、後でモデルを自分で追加します。とりあえずは、これで画像生成を試してみます。
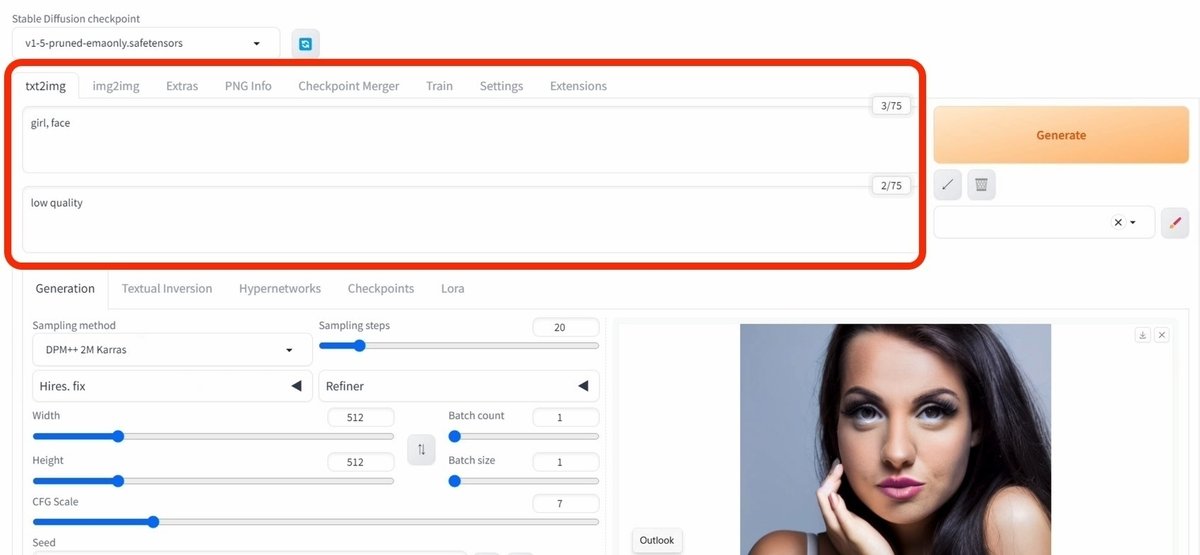
まず、生成したい画像の説明文を入力します。
・上の段(プロンプト):生成したい画像の特徴
・下の段(ネガティブプロンプト):生成したくない画像の特徴
を入力してください。
入力するテキストは、英語で、カンマで区切って入力します。文章でも生成できますが、「可愛いネコを書いてください」のような命令文や会話文ではなく、「可愛いネコ」のように書いてください。
ちなみにChatGPTやBing AIに搭載されているDALL-E3では、命令文や会話文、日本語でも画像生成できます。DALL-Eの強みです。
以下は、プロンプトの例です。
・プロンプト:girl, face, smile, photo
・プロンプト:girl, ocean, standing, anime style
・ネガティブプロンプト:worst quality, bad quality, low quality, ugly, monochrome, dark
画像を生成するには、右側の「Generate」ボタンをクリックしてください。
クリックするごとに、違う画像が生成されます。同じ画像や似た画像を生成する方法は、別の記事で解説します。
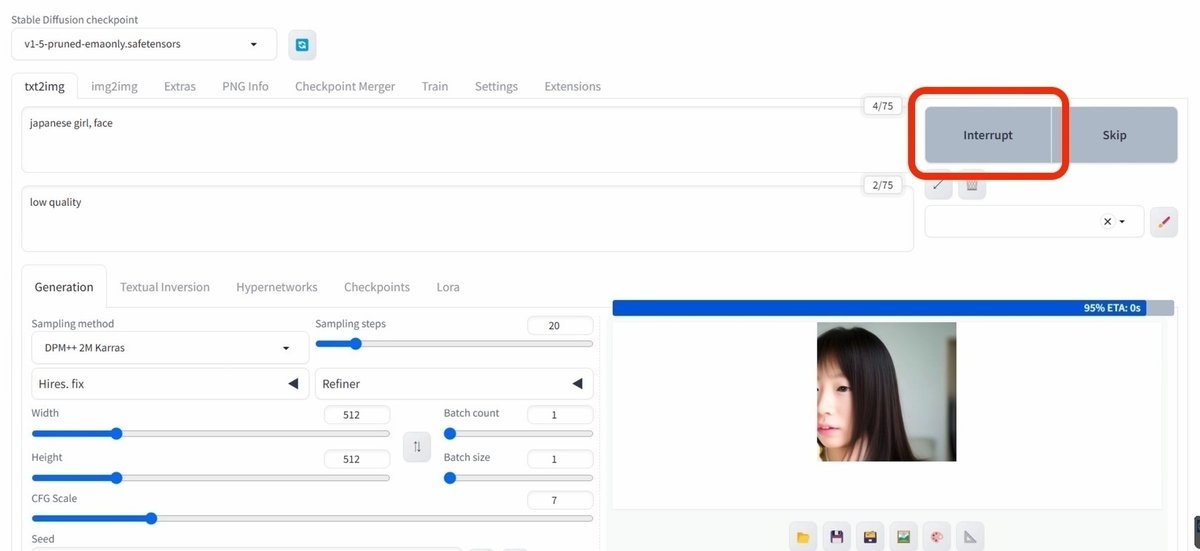
画像生成中に「Interrupt」をクリックすると、画像生成を途中でストップできて、途中結果のまま表示されます。
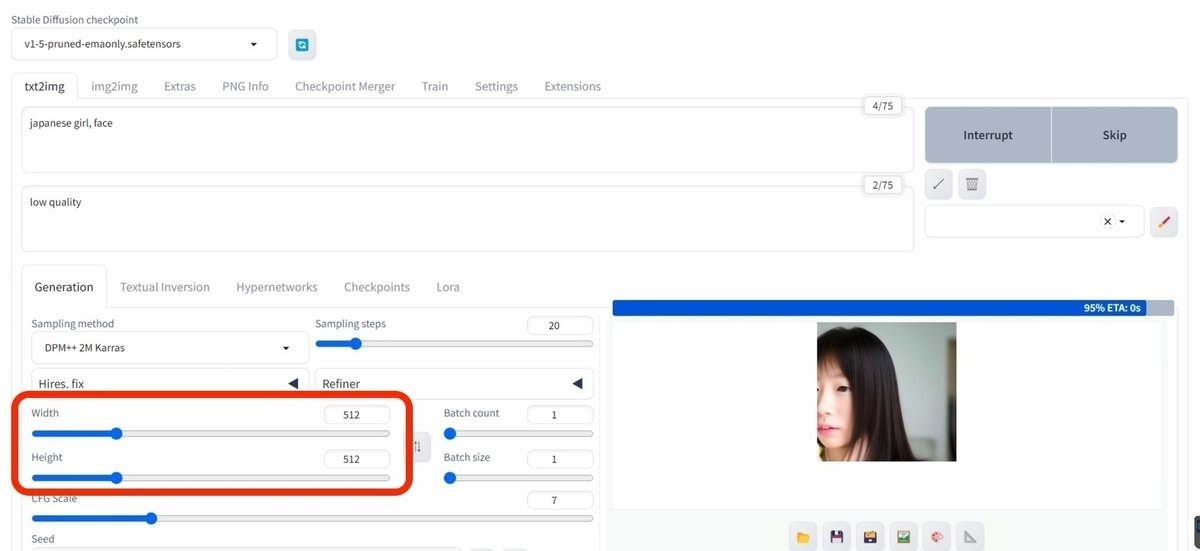
Width / Heightでは、画像サイズを変えられます。後で詳しく説明しますが、今使っているモデルは、バージョンがSD1.5のモデルです。
SD1.5は、512サイズの正方形の画像で多く学習されたので、512サイズから離れるほど、崩れた画像が出やすくなります。そのため、
・512×512
・400×600
・600×400
サイズがオススメです。例えば、Width / Heightで、1024×1024などの大きめの画像を、最初から生成しても良いですが、崩れやすくなります。
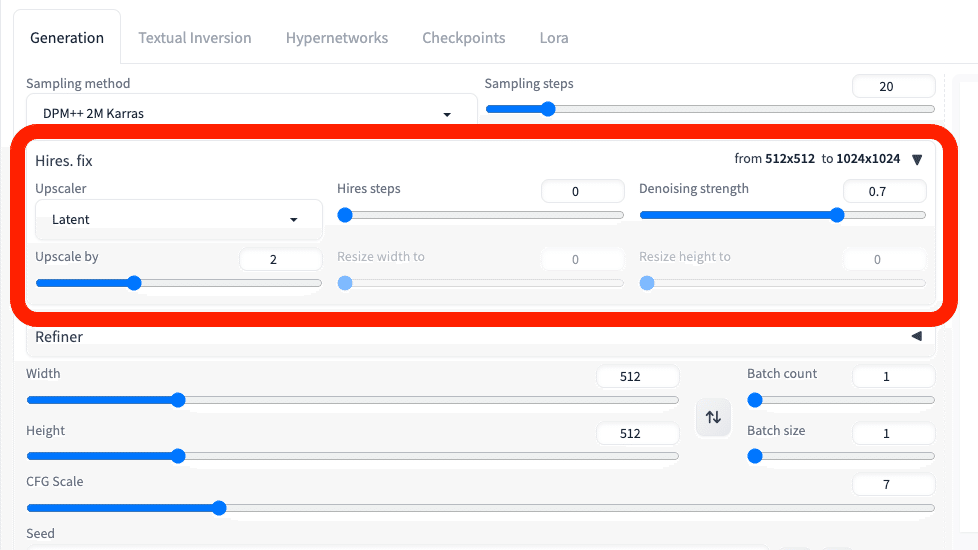
そのため、大きな画像を作るときは、Hires.fixを使うのがオススメです。これは2段階で画像を拡大する機能です。最初に512×512などの小さめのサイズで生成し、画質を改善しつつ画像の拡大をしてくれます。
他の拡大方法については、別の記事で解説します。
注意点として
・Width / Height
・Hires.fix
どちらに関しても、1500×1500サイズを超える画像になると、GPUにかかる負担が大きくなり、エラーが出やすくなります。特に性能が低いGPUを使っている方は、注意してください。
次回から開きやすいように、タスクバーにピン留めしておいてください。
□ パラメータを初期設定に戻す方法
色々と設定を変えた後で、初期設定(デフォルト)に戻したい場合は、Webページを再読み込みしてください。
□ Stable Diffusionの終了方法
Stable Diffusionを終了するには、StabilityMatrixで「ストップ」をクリックするだけです。
ストップがLaunchに変わっていれば、終了できています。
このWebUI画面も閉じて大丈夫です。
□ 2回目以降の起動方法
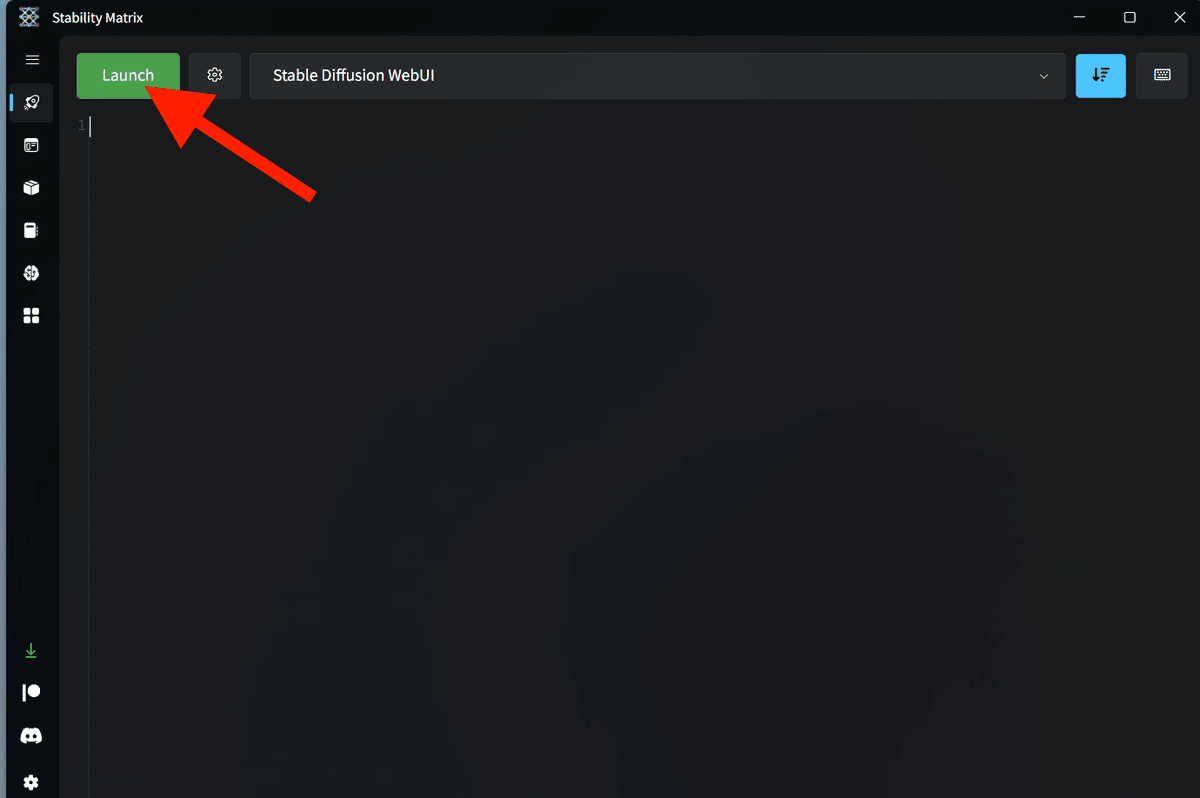
起動方法は、StabilityMatrixを開き、Launchボタンをクリックするだけです。
たった数秒でStable Diffusionが立ち上がるのが、ローカル環境のメリットです。クラウド環境(Colab)では、数分〜十数分かかります。生成AI GOは、ローカル環境より少し遅いくらいで、数十秒です。
□ StabilityMatrixの設定
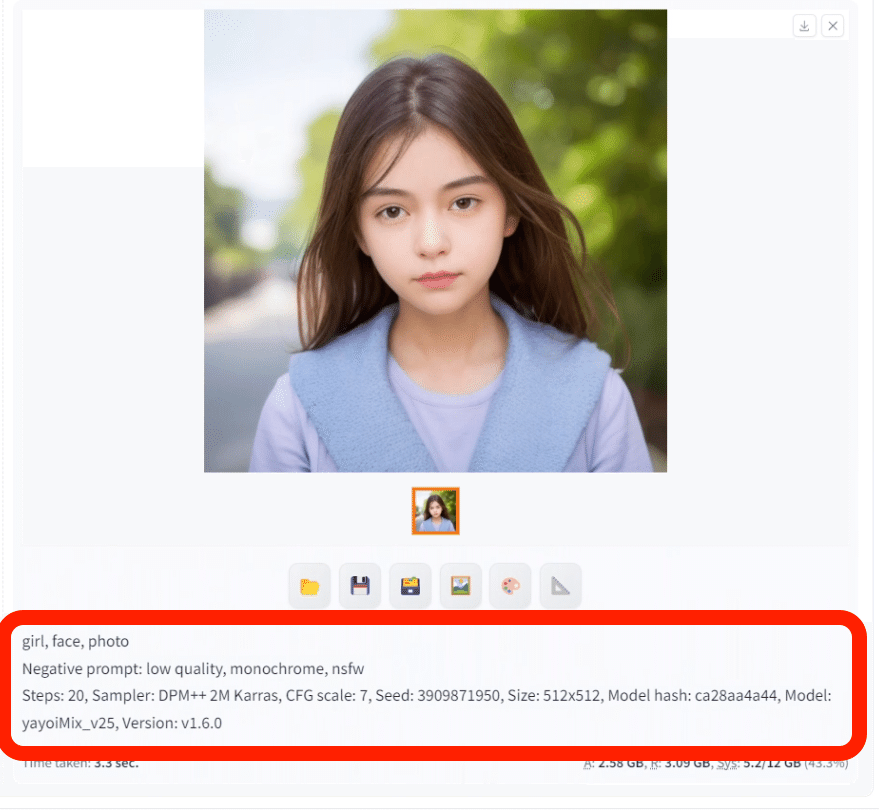
大きめの画像を作ると、GPUが足りないというエラーが出てきます。エラーはこの欄に表示されます。例えば「Out of memory…」など。
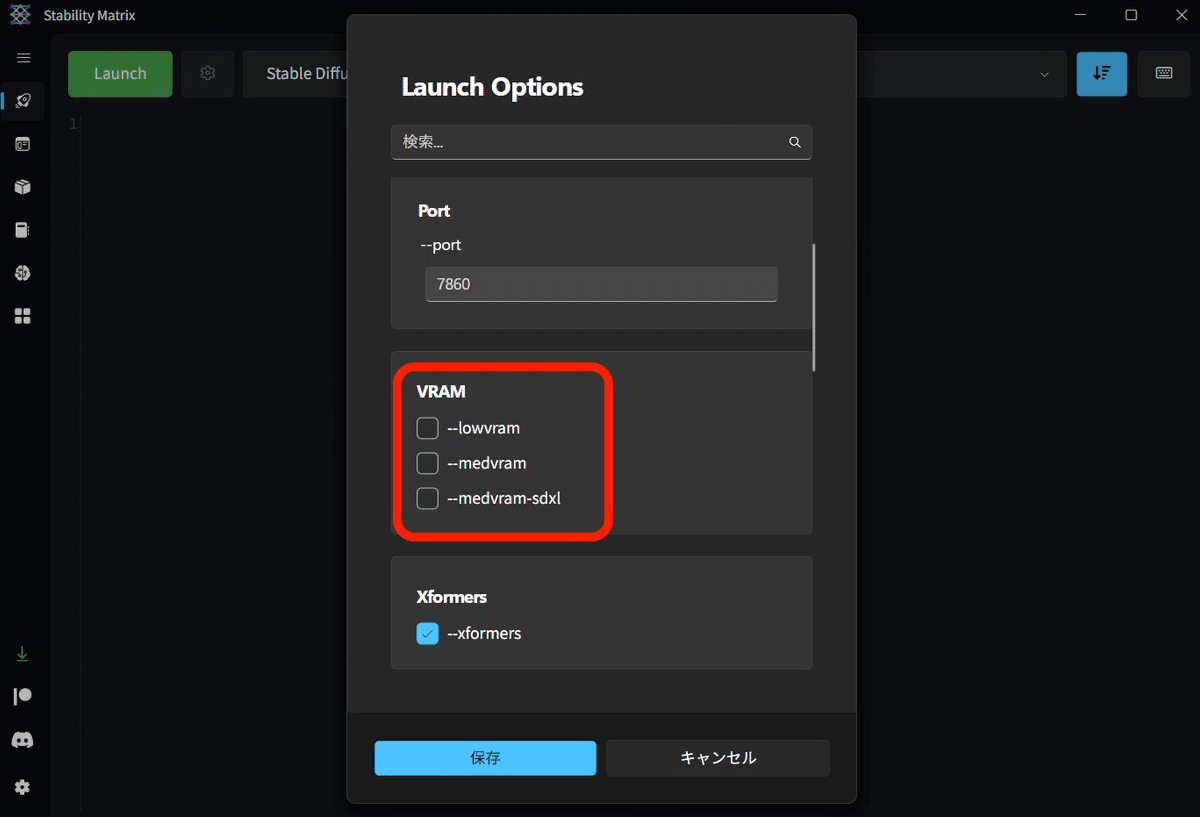
私はVRAMが12GBですが、画像が1400〜1500サイズくらいになると、GPU不足エラーがでます。
エラーが出たら、「--medvram」にチェックを入れてください。VRAMが8〜10GB以下の方は、最初からチェックを入れておいてください。
それでもエラーが出たり、VRAMが6〜8GB以下の方は、「--lowvram」にチェックを入れてください。
チェックは1つだけで大丈夫です。
この設定をすることで、大きめの画像サイズでも生成できるようになる代わりに、画像生成に時間がかかるようになります。
「--medvram-sdxl」は、最新のSDXL用モデルを使うときにだけ --medvramを適用するオプションです。--medvramにチェックしている場合は、チェック不要です。SDXLについては、後ほど解説します。
□ モデルの説明
モデルとは「学習済みのデータ」のことで、「チェックポイント」とも呼ばれています。
Stable Diffusionをインストールした時点では、SD1.5版の公式モデルしかインストールされていません。
SD1.5版の公式モデルは、クオリティが高い画像はあまり出すことができないので、自分でモデルを追加する必要があります。
・写真のようなリアルな画像を生成したいときは、リアル用のモデル
・イラスト風の画像を生成したいときは、イラスト用のモデル
を使う方が、目的に近い画像を生成しやすいです。そのため、モデルは自分の目的に合ったものを選んでインストールします。
Stable Diffusionは起動していても、停止していても、どちらでも大丈夫です。
StabilityMatrixには、Civitaiというモデル共有サイトが搭載されています。そのため、StabilityMatrix内だけでモデルのインストールが可能です。
左側のModel Browserをクリックすると、このCivitaiの画面になります。何も表示されない場合は、右上の「検索」をクリックしてください。このModel Browser画面は、少し見づらいので、私はCivitaiのサイトでモデルを探しています。Civitaiの使い方についても後ほど解説します。
StabilityMatrixでのインストール方法は、「最新版DL」をクリックするだけです。右の「すべてのバージョン」をクリックすることで、バージョンを選んでインストールすることもできます。基本的に最新版で大丈夫です。
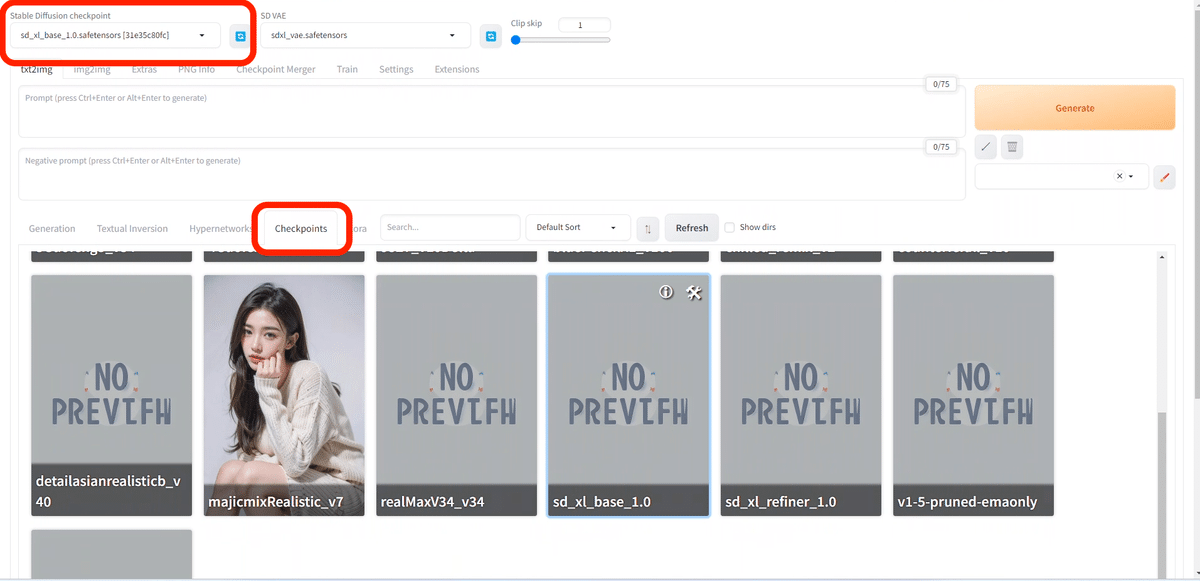
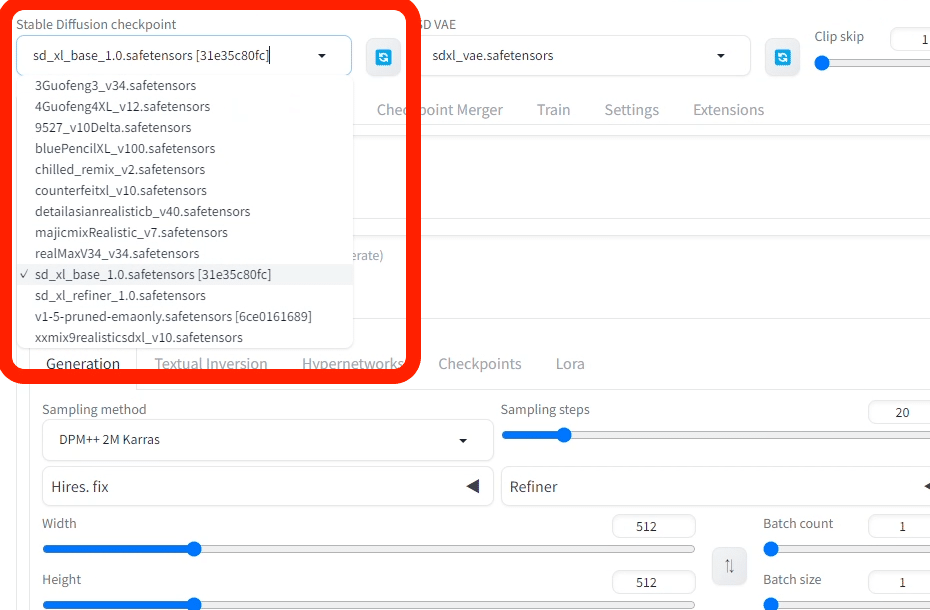
モデル(チェックポイント)を変えるときは、Stable Diffusion画面の以下のどちらかから、変更できます。
・左上のStable Diffusion checkpoint
・中央あたりのCheckpoints
StabilityMatrixでモデルをインストールすると、モデルのサムネイル画像が自動で割り当てられるのがメリットです。
モデルを入手できるサイトは、「Civitai」と「hugging face」が有名です。Civitaiは画像生成AIに特化していますが、hugging faceは画像生成AI以外にも自然言語処理や音声処理など、様々な学習済みのデータが共有されています。
hugging faceは、Civitaiのサイトと違い画像が少なく文字がメインで、上級者向けのサイトです。どちらの使い方も紹介しますが、Civitaiがオススメです。
□ Civitaiとは?
Civitaiは、Stable Diffusionのような画像生成AIサービスで使うモデルが共有されているサイトです。モデルはチェックポイントとも言います。
様々なモデルを閲覧したりダウンロードすることができます。

サイトを見てもらえれば、モデルごとにどんな画像が生成できるか、だいたい分かると思います。モザイクがかかっているのは主にアダルト系のモデルです。ログインすると、すべて見れるようになります。
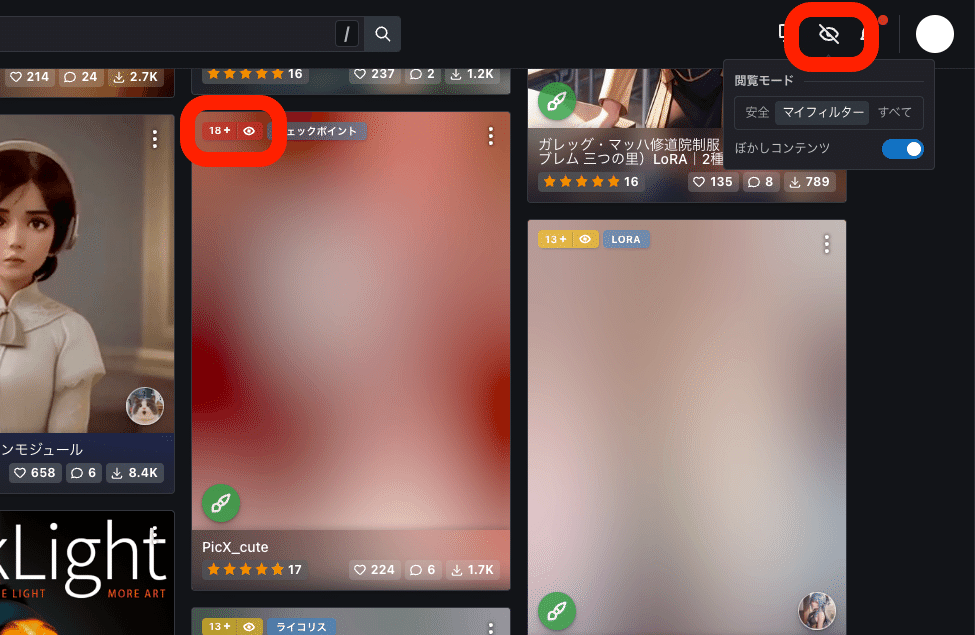
モザイクを解除するには、「18+」などの部分をクリックしたり、画面右上の目のマークから、モザイクの設定を変更してください。
□ Civitaiの使い方、インストール方法
試しに1つモデルをダウンロードしてみましょう。好みのモデルを選んでください。
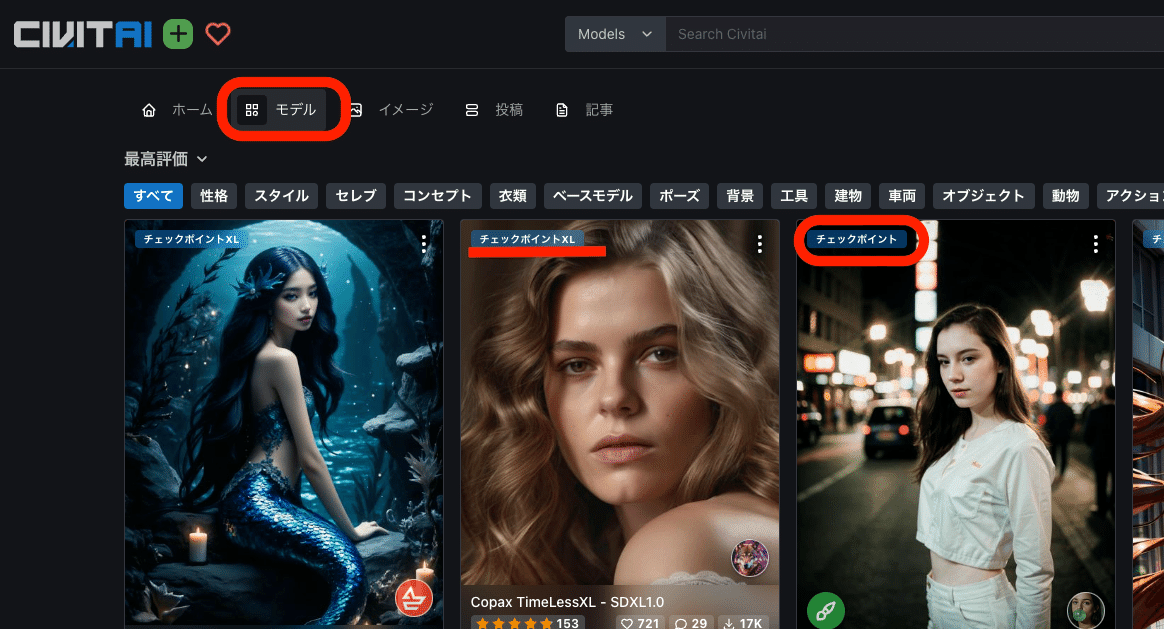
左上の「Models」をクリックしてモデルだけを表示させます。チェックポイントと書かれているのが、モデルです。
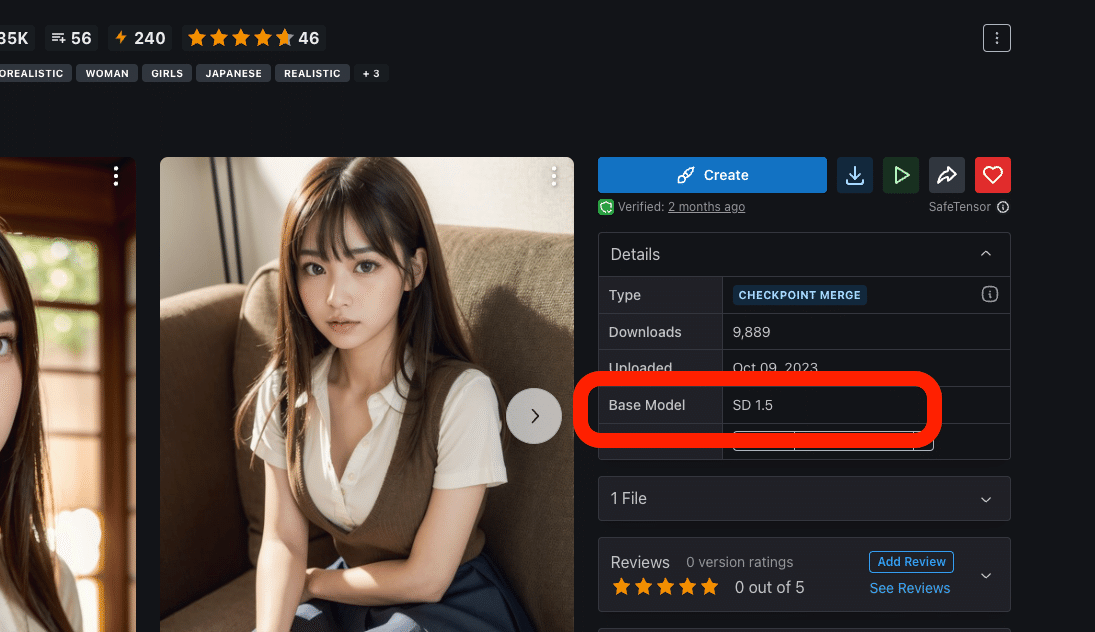
・チェックポイント:SD1.5版のモデル
・チェックポイントXL:SDXL版のモデル
SD1.5とSDXLの比較は、後ほど解説します。簡単に説明すると以下のとおりです。
・SD1.5:有名で使用者が多い、まだ現役のモデル。拡張機能と相性が良い。
・SDXL:最新版のモデル。手軽に高品質な画像が作れる。
比較のために、両方インストールするのがオススメですが、PC性能が高くない方はSD1.5だけでも大丈夫です。
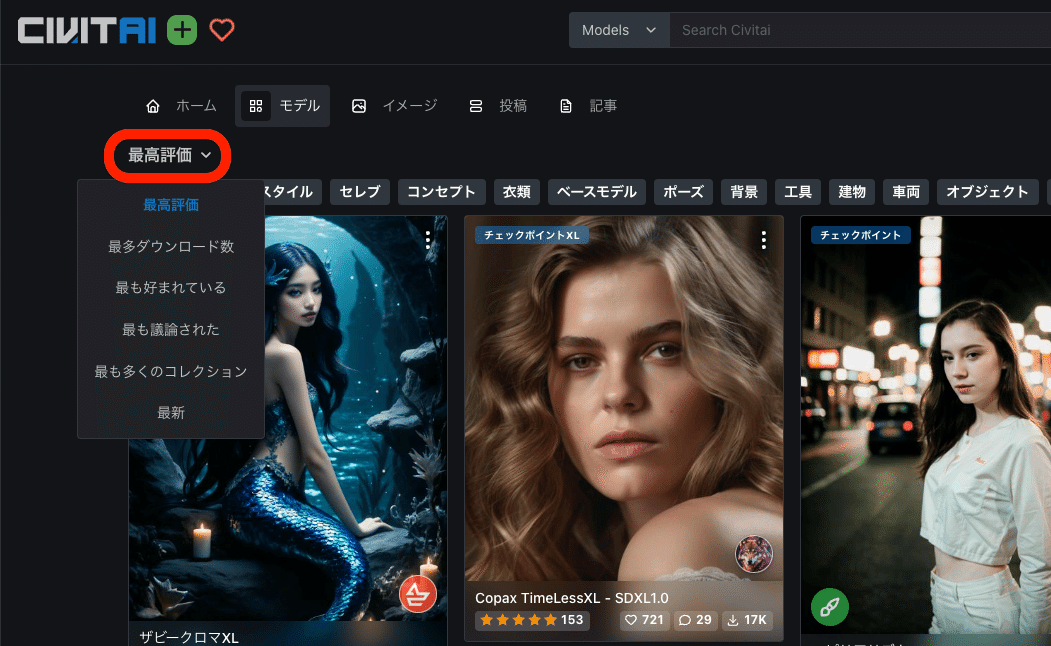
初期設定では、評価順に並んでいるので、上に位置するモデルが高評価されているモデルです。並びの設定は、上の画像のように変えることができます。
画面右上にある設定から、期間も指定可能です。
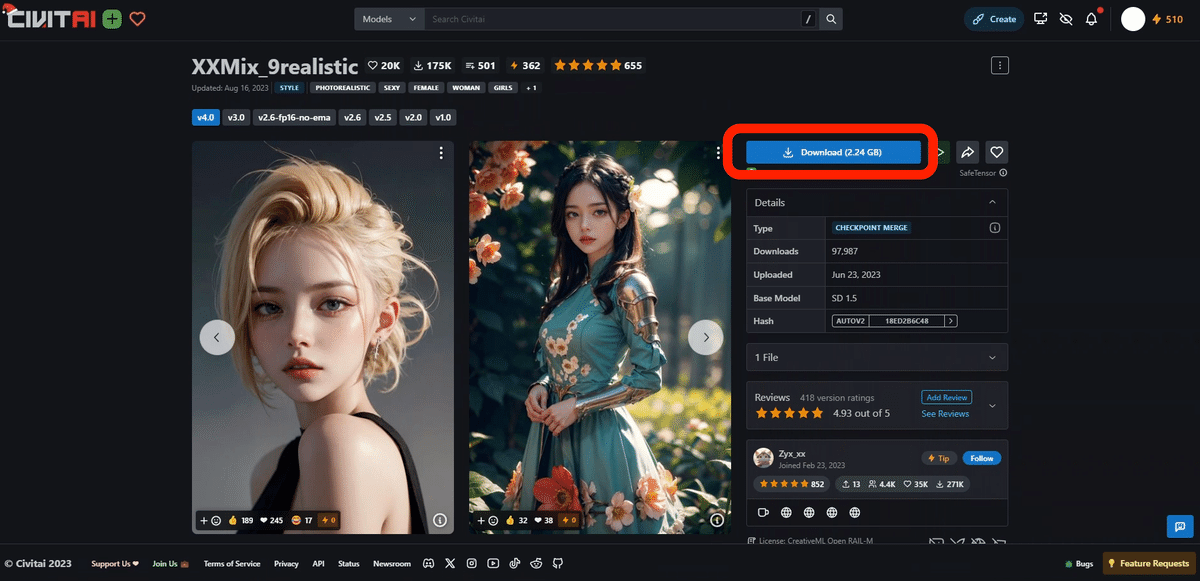
モデルは、気に入ったものをインストールしていただければ大丈夫です。
・最新版のSDXL
・最も普及しているSD1.5
の両方を使ってみたい方は、以下のように、同じ作者が作成したモデルを選ぶと、効率的に比較検証が行えます。
✓ リアル風のモデル
・XXMix_9realisticSDXL
・XXMix_9realistic
・nagatsuki_mix
・yayoi_mix
✓ イラスト風のモデル
・SakuraMix-XL./Anime-like
・SakuraMix
・CounterfeitXL
・Counterfeit-V3.0
次は、Civitaiでのインストール方法について解説します。上記の、ダウンロードをクリックしてください。
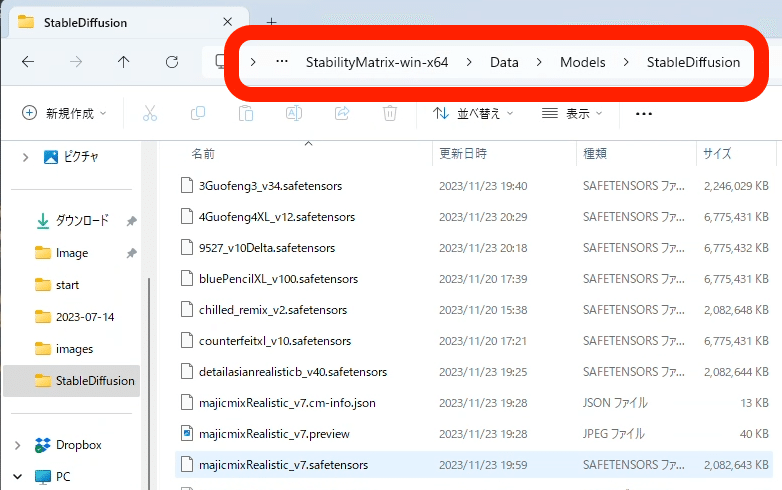
モデルの保存場所は、StabilityMatrix → Data → Models → StableDiffusion です。間違えると、モデルが使えなかったりエラーが出るので、注意してください。
(StabilityMatrixを使っていないローカル環境の方は、「stable-diffusion-webui」→「models」→「Stable-diffusion」の中に保存してください。)
モデルの容量はとても大きいです。不要なものは削除や移動して整理するか、ストレージを追加購入してください。
他のモデルも同じやり方でダウンロードできます。
Stable Diffusionを起動すると、モデルは自動でインストールされます。
Stable Diffusion起動中にモデルをインストールする場合は、チェックポイント欄の右にある、再読み込みアイコンをクリックしてください。
以上の操作は、新しいモデルを追加するときだけで大丈夫です。2回目からは、Stable Diffusionにモデルは読み込まれた状態で使用できます。
最後に、Stable Diffusionの公式モデルをインストールします。ベースモデルや初期モデルとも呼ばれています。
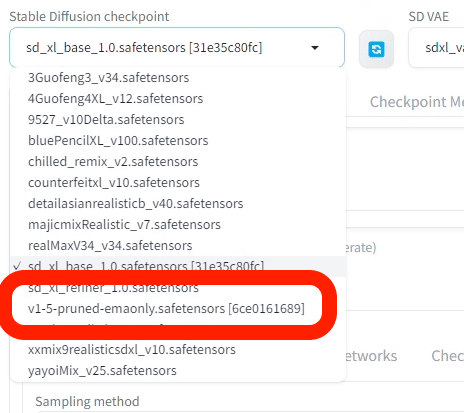
Stable Diffusionをインストールすると、自動的に、v1-5-prunedという公式モデルがインストールされます。これは、SD1.5版の公式のモデルです。
SDXL版は、インストールされていないので、自分でインストールする必要があります。
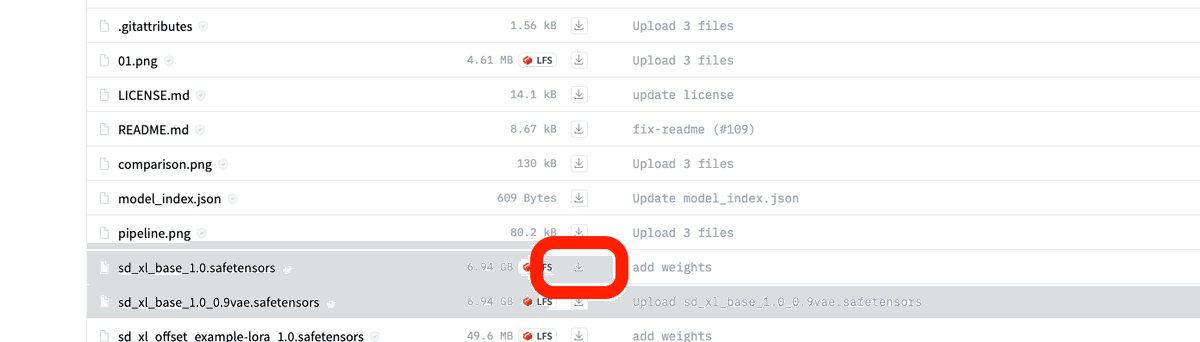
stabilityai/stable-diffusion-xl-base-1.0 この公式サイトから、ダウンロードしてください。保存する場所は、先ほどと同じです。
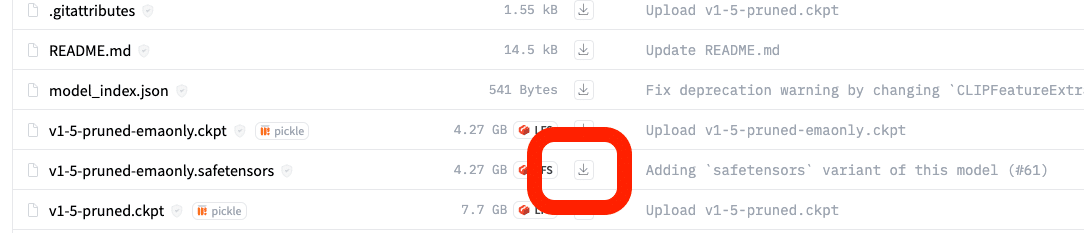
SD1.5版のベースモデルが無い場合は、runwayml/stable-diffusion-v1-5 こちらからダウンロードしてください。初期モデルでは、クオリティが高い画像はあまり出せないので、ほぼ使いません。そのため、インストールする必要はないのですが、今回はSDXLと比較したい方も居ると思うので、あえてインストールします。
ただし、SDXLの公式モデルは、けっこうクオリティが高いです。使い方によっては、これだけでも大丈夫です。
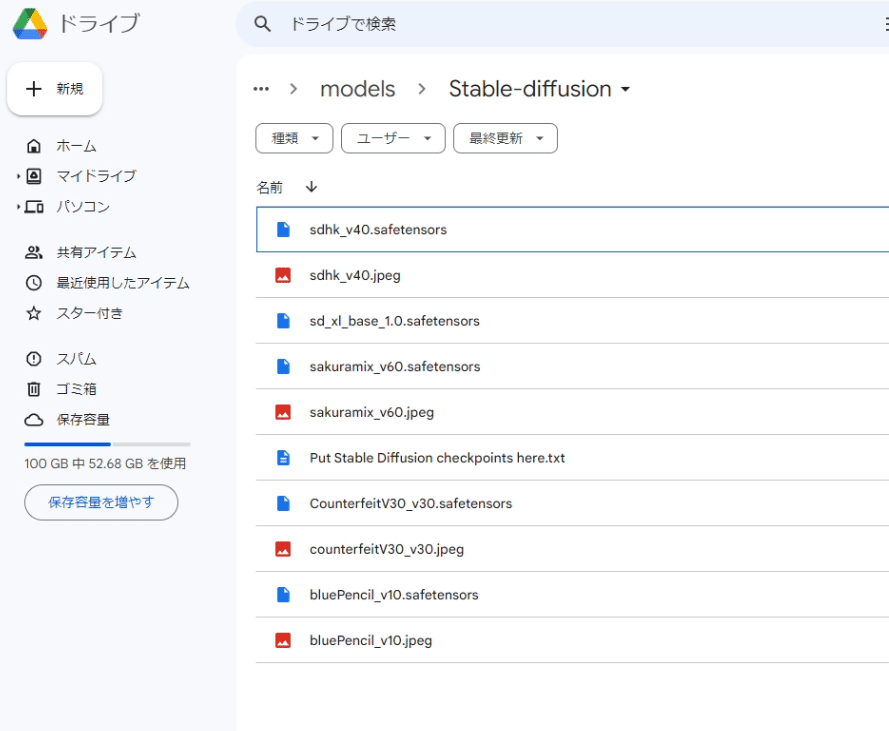
□ サムネイルを表示させる方法
モデルをたくさんインストールすると、どれがどれだか分かりにくくなります。
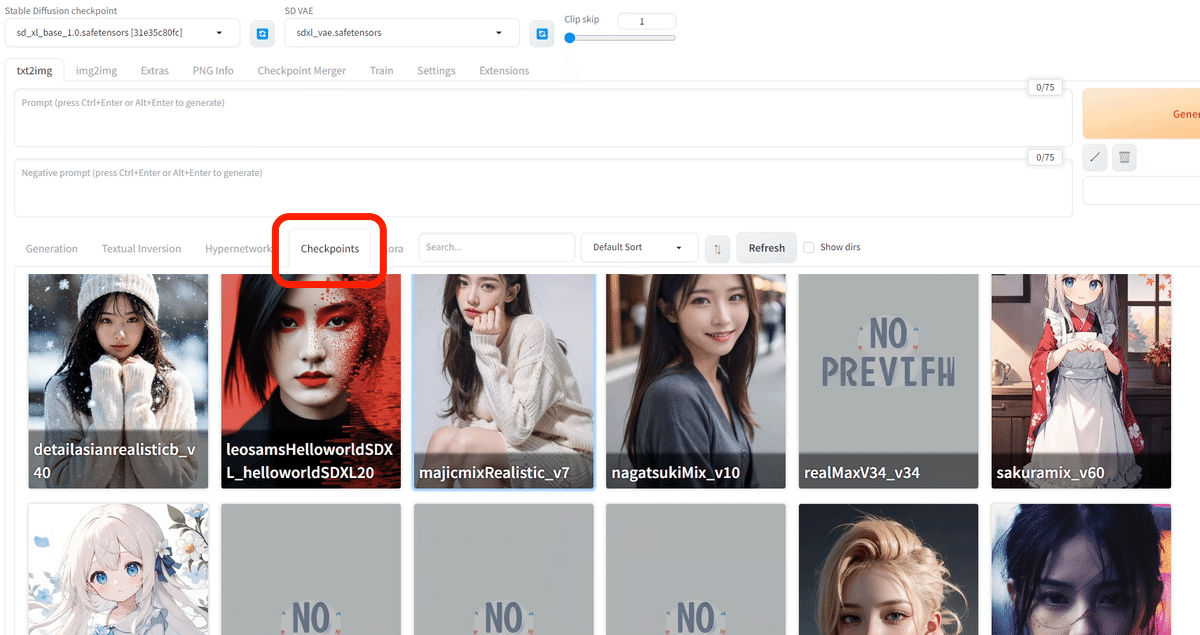
そこで、中央あたりのCheckpoints欄から、モデルをサムネイル付きで見ることができます。しかし、Civitaiなどで自分でインストールした場合は、サムネイルは付きません。(StabilityMatrixでインストールすると自動的に付けてくれます)
そこで、自分でサムネイルを設定する方法を紹介します。
やり方は、簡単で、このように
・モデルファイル名(例:abc.safetensors)
・画像のファイル名(例:abc.jpeg)
を同じにするだけです。画像の拡張子は、pngでもOKです。
画像は、Civitaiなどからダウンロードしてください。
□ VAEの説明と、必要性
VAEとは、画質を良くするために使われるツールです。
VAE(Variable Auto Encoder)は、とても難しい技術です。詳しく知りたい方だけ「VAE(Stability AI)」を読んでください。
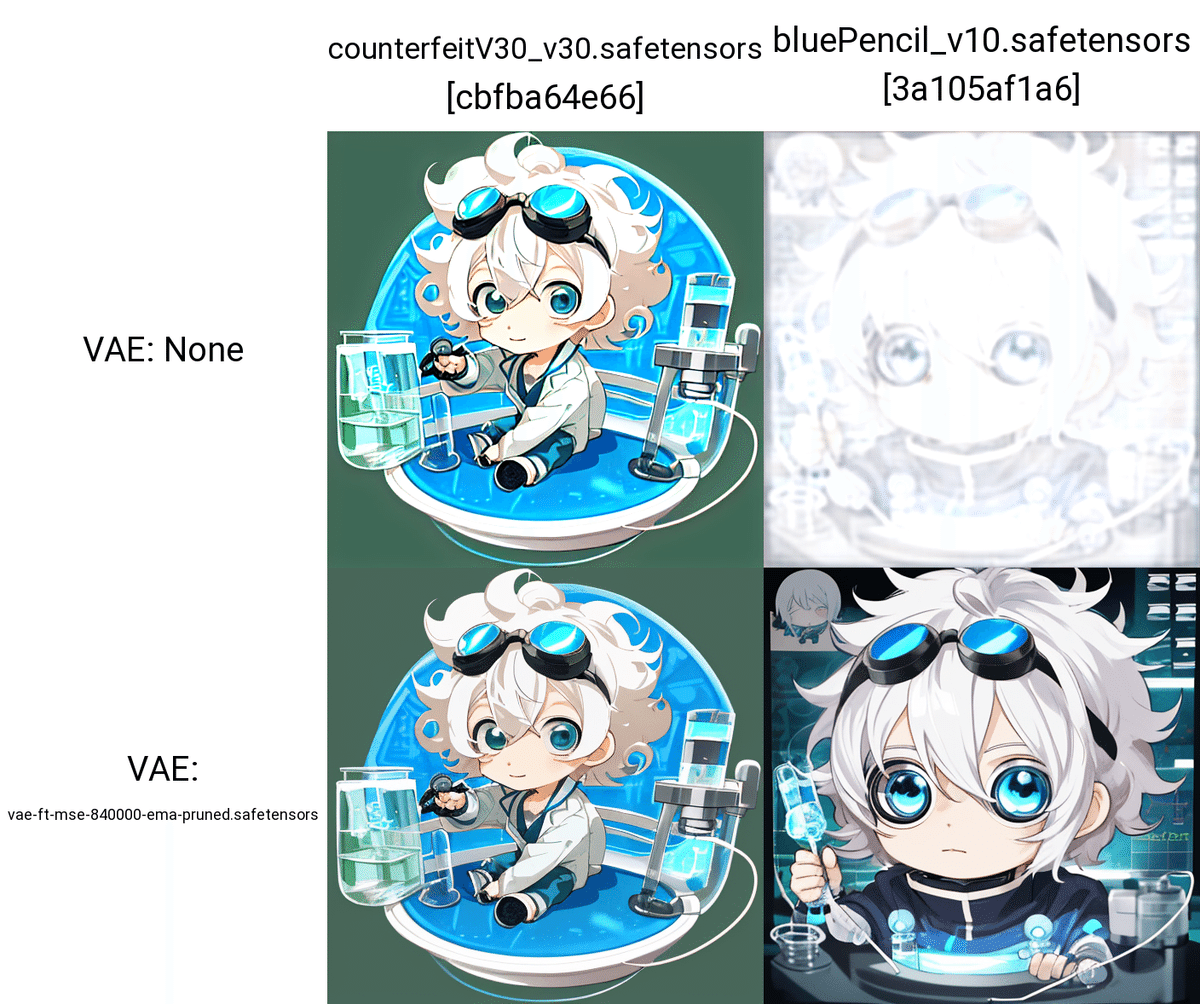
VAEなしで画像生成をすると、生成した画像の色が薄くなることがあります。また、エラーになるモデルもあります。そのため特にSD1.5において、VAEは設定してください。



一方で、SDXLは、VAEの有無で、画質の差はほとんど出ません。そのため、VAEの重要度は下がり、無くても良い状況です。いちおうSDXLのVAEが用意されているので、私は使っています。
注意点として、SD1.5で最も使われいたVAEであるvae-ft-mse-840000-ema-prunedは、SDXLと互換性がありません。ちなみに、使うと画質がとても粗くなります。
VAEだけでなく、モデル、ControlNet、LoRAも、SD1.5とSDXLは互換性がありません。SDXL専用のものが必要になります。これが、SDXLがあまり普及していない原因の1つですが、最近はSDXL用のものは増えてきています。
何かダウンロードするときは、SDXL用かSD1.5用なのか、確認お願いします。
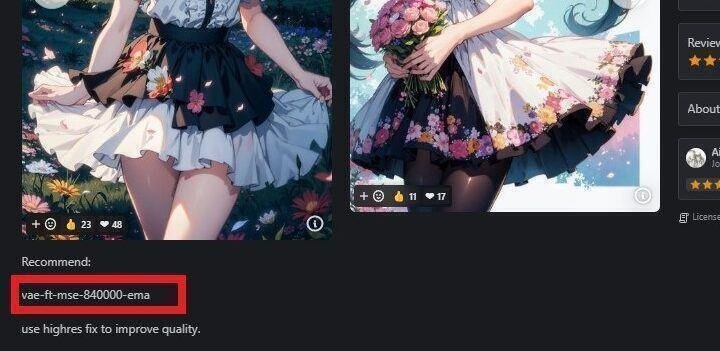
VAEを使うことで、画質が必ず良くなるわけではありません。また、VAEが元からモデルに内蔵されていて、VAEが不要なモデルもあります。そのため、モデルをダウンロードするときは、説明欄もよく読んで、VAEが推奨されているかどうか確認してください。
例えば、「Dark Sushi Mix」モデルでは、上の画像のように、説明欄に「VAE推奨」と書かれています。VAEについて言及がないモデルは、自分で試してみて、画像のクオリティが変わるかどうか確かめてみてください。
□ VAEをインストールしよう
SDXL公式のVAEが、sdxl_vae.safetensorsです。
SD1.5用のVAEは、「vae-ft-mse-840000-ema-pruned」が有名です。
こちらも、Stable Diffusionの開発元でもあるStability AIが作成したものです。このVAEは、リアル系のモデルにも、イラスト系のモデルにも効果があります。
この2種類のVAEファイルのどちらでも問題ありませんが、最近は「safetensors」のファイルがよく使われています。こちらの方がセキュリティ的に安全らしいので、safetensorsをダウンロードしてください。
ダウンロードしたVAEファイルは、StabilityMatrixのCheckpointsのVAE欄に、ドロップしてください。VAEカテゴリが無ければ、右上のカテゴリから追加してください。
あるいは、StabilityMatrix → Data → Models → VAE に保存してください。
StabilityMatrixを使っていないローカル環境の方は、「stable-diffusion-webui」→「models」→「VAE」の中に入れてください。
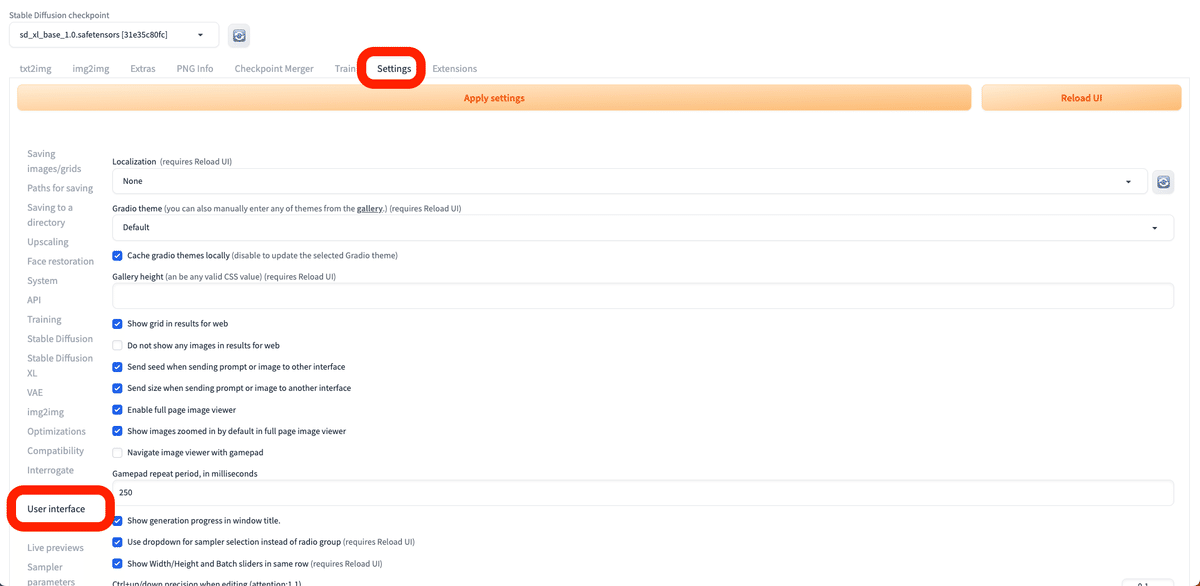
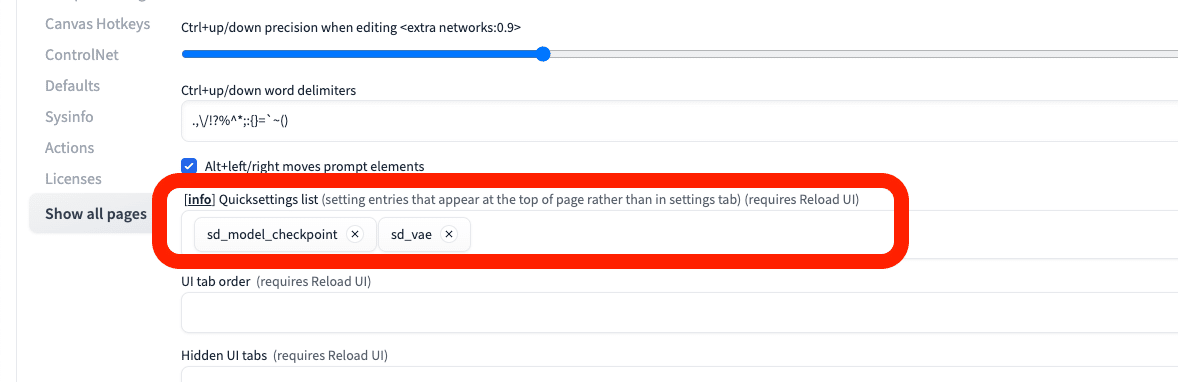
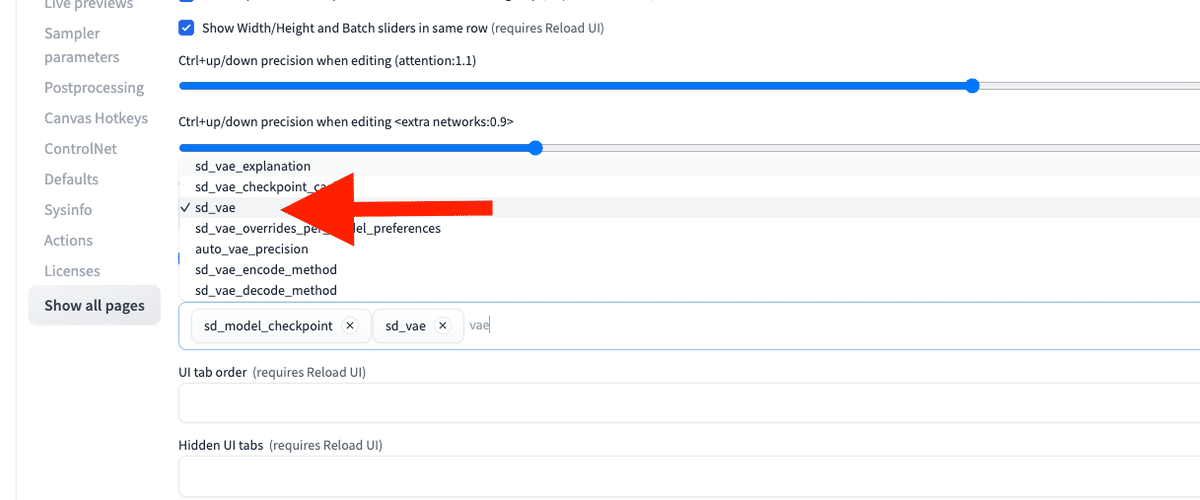
次に、「Settings」→「User Interface」を開いてください。「[info] Quicksettings list」で「sd_vae」と入力するか選択してください。
設定を変更したら、最後に「Apply settings」をクリックし、「Reload UI」をクリックしてください。
これで「VAEタブ」が表示されたはずです。
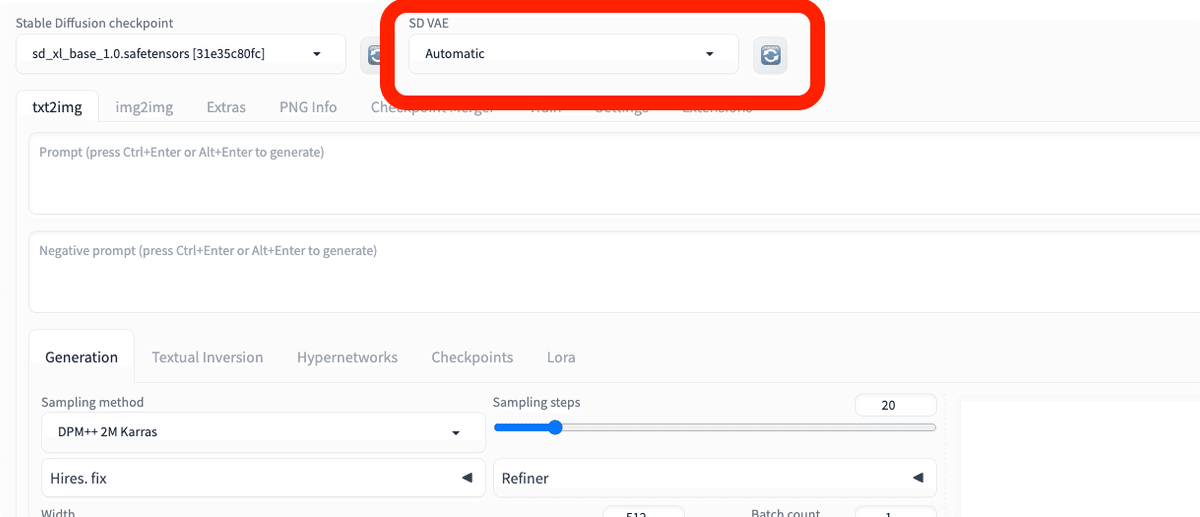
モデルと同じように、「SD VAE」の欄で、VAEを切り替えることができます。インストールしたVAEがない場合は、読み込みマークをクリックするか、Stable Diffusionを再起動させてください。
まとめ
・SDXL系のモデルを使う場合 → sdxl_vae.safetensors を使う。
・SD1.5系のモデルを使う場合 → vae-ft-mse-840000-ema-pruned を使う。あるいは、モデルごとに推奨されているVAEがあれば、それを使う。
□ 画像の保存方法
画像の保存は、生成された画像を右クリック → 名前を付けて保存 で可能ですが、Stable Diffusionでは自動で保存されていきます。
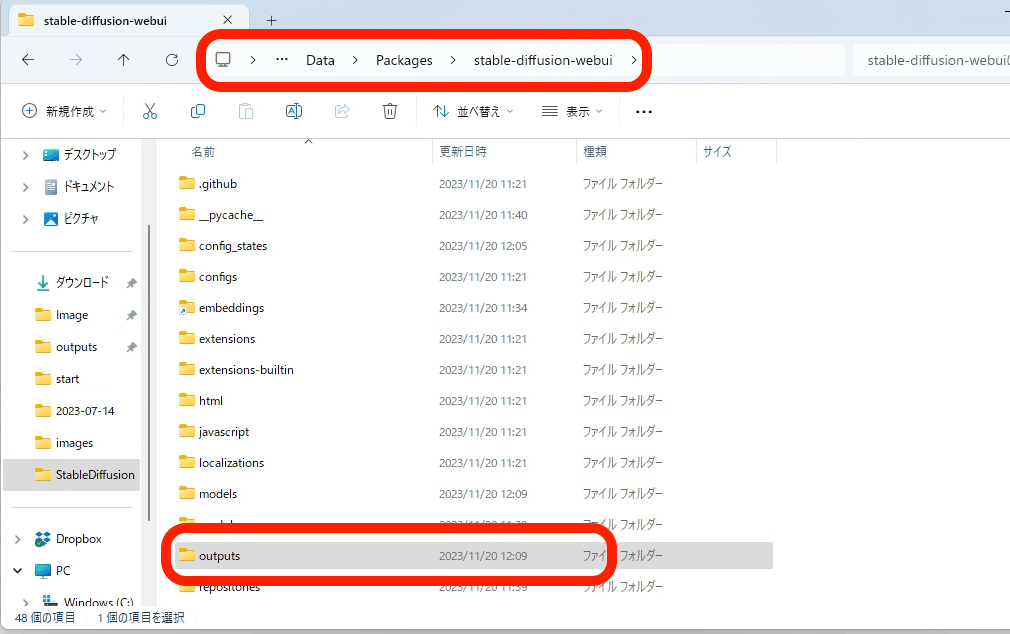
StabilityMatrixを使っている方は、StabilityMatrix → Data → packages → stable-diffusion-webui → outputs の中に、自動で保存されていきます。
それ以外のローカル環境の方も、stable-diffusion-webui → outputsに保存されていきます。
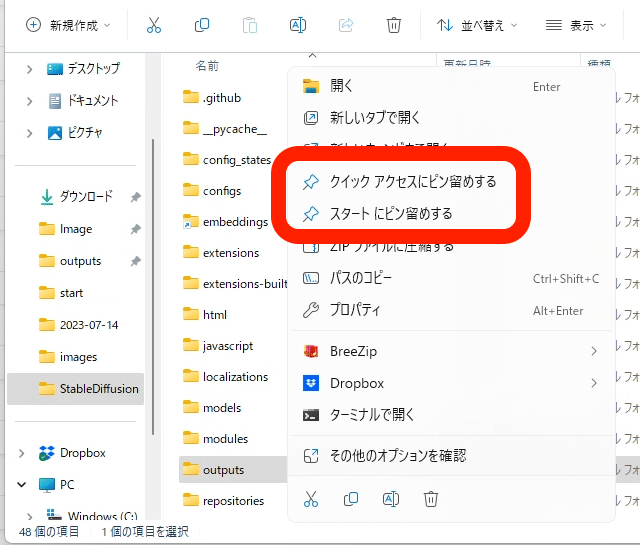
outputsフォルダはよく使うので、フォルダを右クリックし、ピン留めをしておくのをオススメします。
画像は容量がやや大きいので、定期的に削除したり移動して整理するか、容量を追加で購入してください。
■ クラウド環境で、Stable Diffusionを始める方法① (Google ドライブと連携するColab)
ここでは、Colabを使い、クラウド環境でStable Diffusionを始める方法を解説します。(ローカル、クラウド環境などの比較はこちら)
ColabでStable Diffusionを使うなら、初心者ほど、Googleドライブと連携する方法がおすすめです。
特に、TheLastBenさんが開発したテンプレートを使うと、プログラミング不要でStable Diffusionを使うことができます。また、生成した画像は、自動でGoogleドライブに保存されるので、わざわざ自分で保存する手間もありません。クラウド環境では、ふつう、画像は自動で保存されません。
さらに、このテンプレートを使う場合、ローカル環境と設定方法がほとんど同じなこともメリットです。拡張機能を追加したいときに色々調べると、ローカル環境の情報がよく出てきますが、それと同じ手順で解決できることが多いです。
他のColabでStable Diffusionを使うとなると、プログラミングコードを自分で編集しなければならず、Webエンジニアの方じゃないと、けっこう大変です。生成した画像も、自分で1つ1つ保存する必要もあり、面倒です。いちおう後で紹介しますが、私がサポートできる範囲は限られるので、ご了承ください。
□ Google Colabとは
始める前に、そもそもGoogle Colabとは何か説明します。
Google Colabとは、正式名称はGoogle Colaboratoryで、Googleのリソースを使いWeb画面上でPythonを動かすことができるサービスです。GPUなどのリソースが提供されるので、自分のPCの性能が低くても作業できます。
Colabは主に機械学習などに使われています。Stable DiffusionはPythonというプログラミング言語で作られているので、Stable DiffusionもColabを使って動かすことができます。
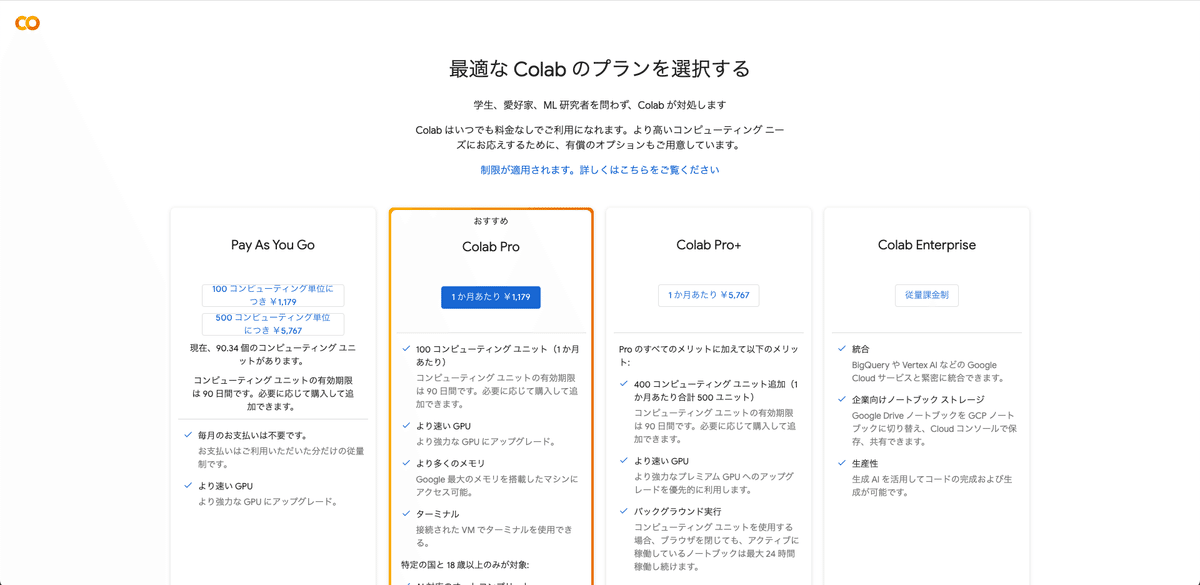
□ Colabの料金比較
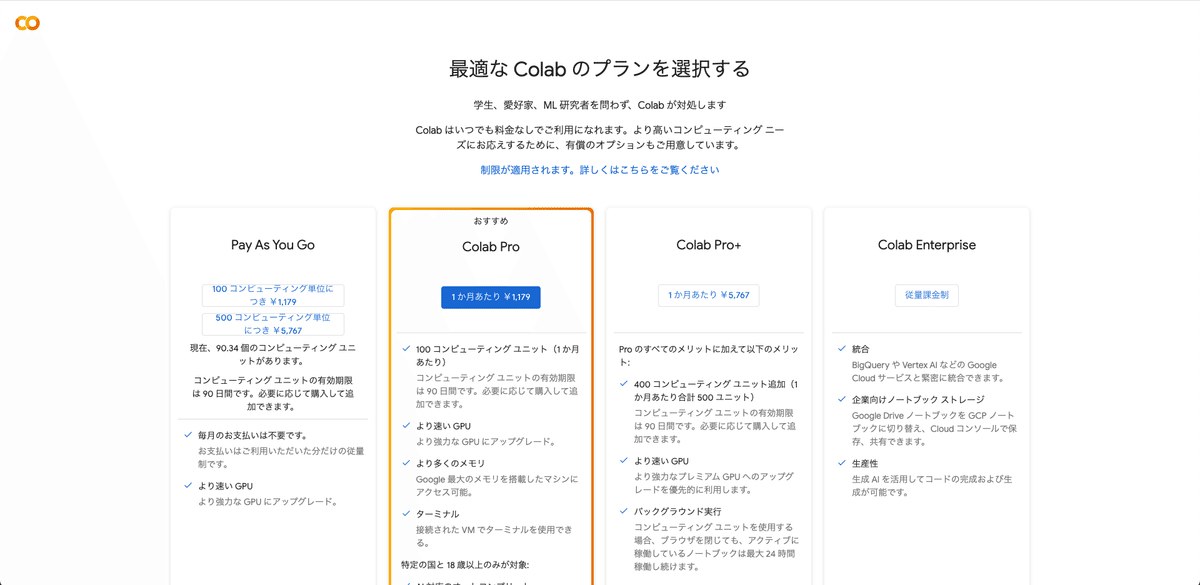
Stable Diffusionを使うときに、Colabの有料プランに入っていないと、エラーが出てしまいます。そのため、支払いは最初に済ませておく必要があります。
Colabのプランは主に3つあり、以下のとおりです。
・Pay As You Go:1179円 または 5767円(買い切り)
・Colab Pro:1179円 / 月 (定額の使い放題ではない)
・Colab Pro+:5767円 / 月 (定額の使い放題ではない)
Colab Proは使い放題ではなく、100コンピューティングユニット分を毎月もらえる感じです。次月が来る前に使い切った場合、足りない分はPay As You Goで追加購入する必要があります。
使っている時間分だけ、コンピューティングユニットが消費される仕組みです。生成できる枚数は無制限なので、ここが生成AI GOとの違いの1つです。
初心者の方は、Pay As You Goがおすすめです。Pay As You Goは買い切りなので、解約する必要はありません。お試しにちょうどいいです。
Proプラン以上とPay As You Goプランでは
・より多くのメモリ(RAM)
・ターミナル
などの違いもありますが、Pay As You Goでも十分なメモリが割り当てられるので問題ありません。また、ターミナルも不要です。
Stable Diffusionで画像生成するときに使うGPUは、3種類から選べます。
1番性能が低いものだと、1時間あたり約2ユニットを消費します。1日3時間Stable Diffusionを使うなら、1ヶ月で180ユニットの消費となり、およそ2000円かかる計算です。1日5時間使用なら、月3500円くらいです。
1番性能が低いGPUであっても、生成スピードなどは問題なく、快適に使えています。
ちなみに、性能が高いPCが必要なローカル環境の場合、PC代金で少なくとも15万円くらいかかります。
4年間PCを使うとしたら、1年あたり4万円、1ヶ月あたり3000円くらいかかる計算です。3年間使うとしたら、1年あたり5万、1ヶ月あたり4000円くらいかかる計算です。
Stable Diffusionでは、イラストも写真風の画像も生成できます。
ふつうはソフト代金だけで、以下の費用がかかります。
・イラスト系なら、月に数千円
・写真風の人物画像を3DCGで作るなら、月に数万円
・画像素材サイトなら、有名なサイトは月に5000円以上
これらを踏まえると、画像生成AIにかかる費用は、高すぎることはないと思います。
無料の画像生成AIサービスもいくつかあります。ただし、運営してる企業もボランティアでやっている訳ではない上に、コンピュータの代金も相当かかっているはずです。そのため、Midjourneyのように有料になったり、途中から画像枚数などの制限が厳しくなると思っておいた方が良いです。
ちなみにStable Diffusionは、投資家から何百億円という大規模な投資を受けているので、現状はオープンソースで運営できています。
□ Googleドライブと連携したColabで始める方法
これから始めていきますが、最初にColabの購入を済ませてください。無料版で利用すると規約違反なので、エラーが出てしまいます。
Googleアカウントは、Googleドライブの容量に空きがあるアカウントを使うのがオススメです。Googleドライブとは、ネット上にデータを保存できるサービスのことで、DropboxやiCloudと同じようなものです。
Stable Diffusionを本格的に使うとなると、けっこう容量が必要になります。
後で説明しますが、特にモデルとControlNetの容量が大きく、50GBくらいは必要です。そのため、Googleドライブの無料容量15GBでは足りなくなります。対処するには、定期的にデータを削除したり移動するのもいいですが、容量の追加購入がオススメです。Googleドライブの容量については、後から追加購入できるので、足りなくなったときに買ってください。月に数百円です。
購入が済んだら、Colabのこの画面を開きます。
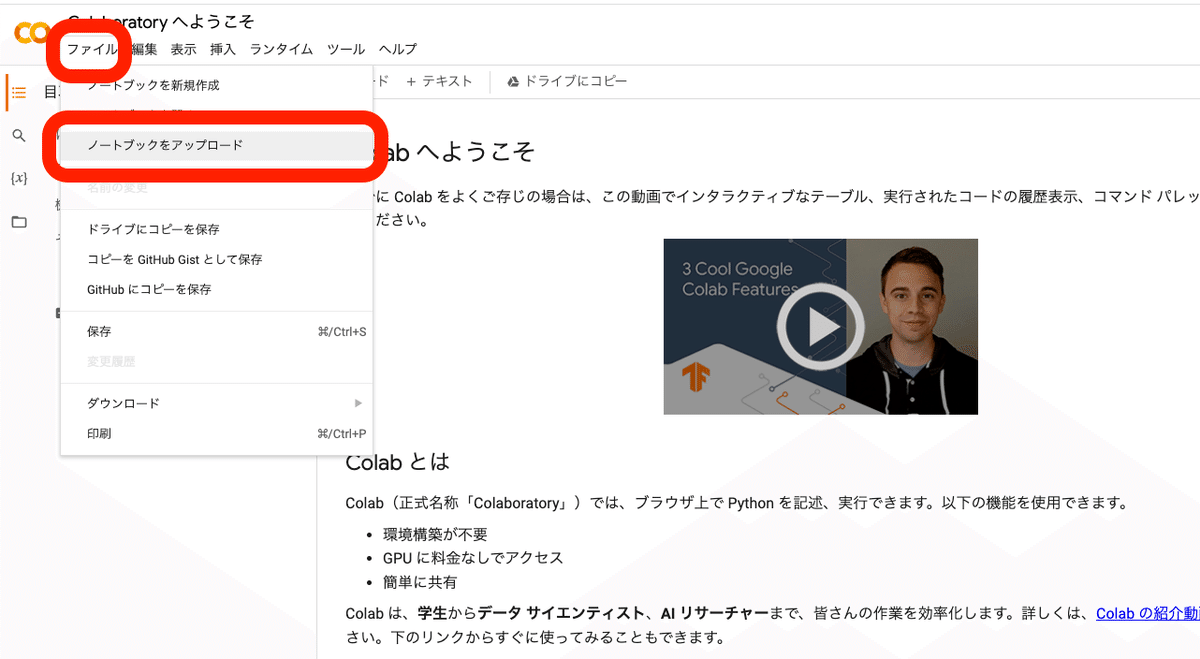
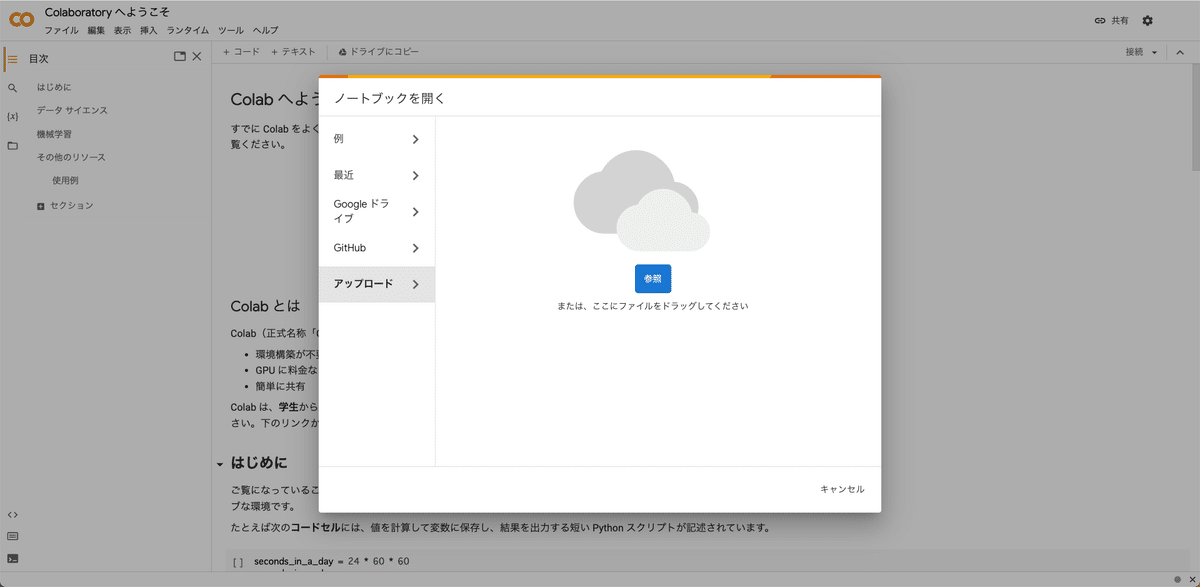
四角い画面が表示されますが、閉じてしまった場合は、画面左上のファイル →「ノートブックをアップロード」をクリックしてください。
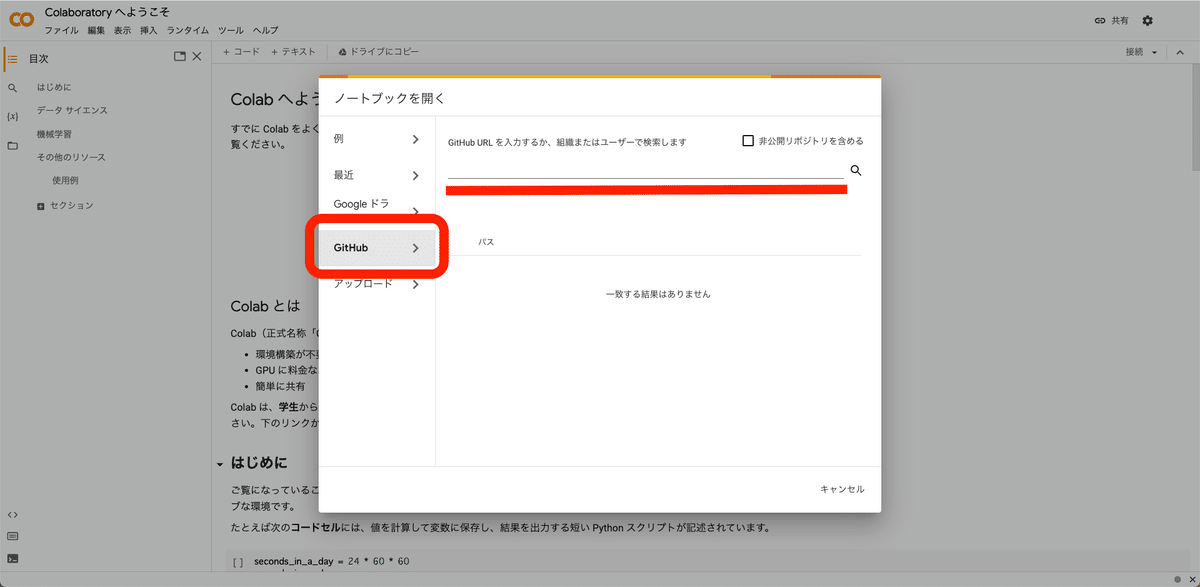
次に、ここにGitHubのURLを入力するために、GitHubのサイトを開きます。
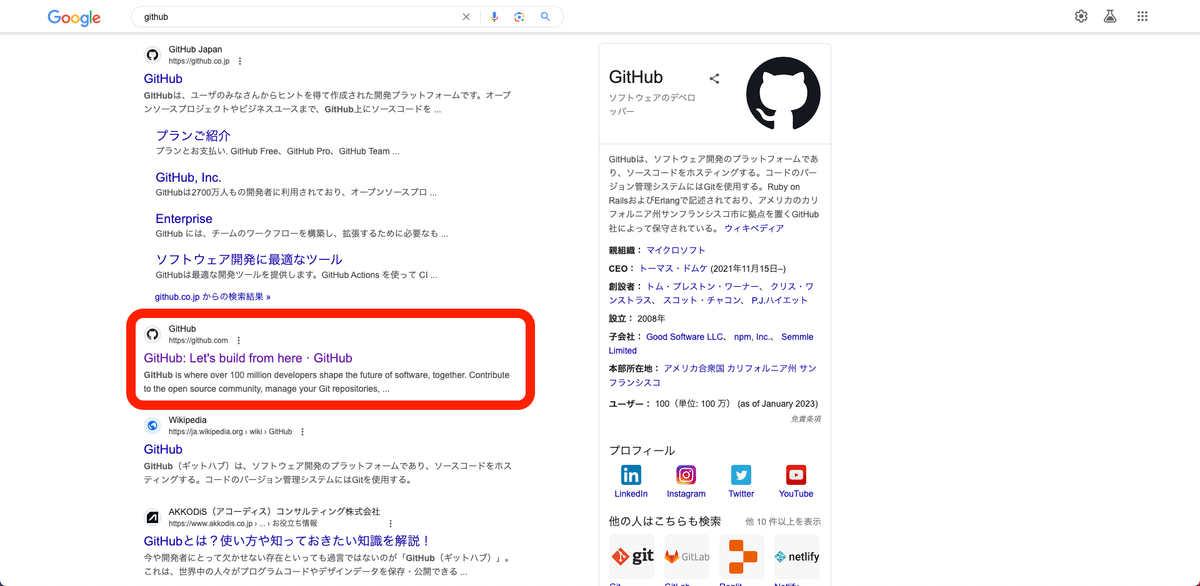
「GitHub」で検索すると公式サイトが2つ現れますが、2つ目のGitHub.comを開きます。
画面右上の検索欄に「Stable Diffusion」と入力し、検索してください。
少し下の方にある「TheLastBen/fast-stable-diffusion」をクリックして開いてください。
この画面になります。緑色の「コード」ボタンをクリックして開き、URLをコピーしてください。
コピーしたURLを、先ほどのこの欄に貼り付けて、エンターキーを押してください。
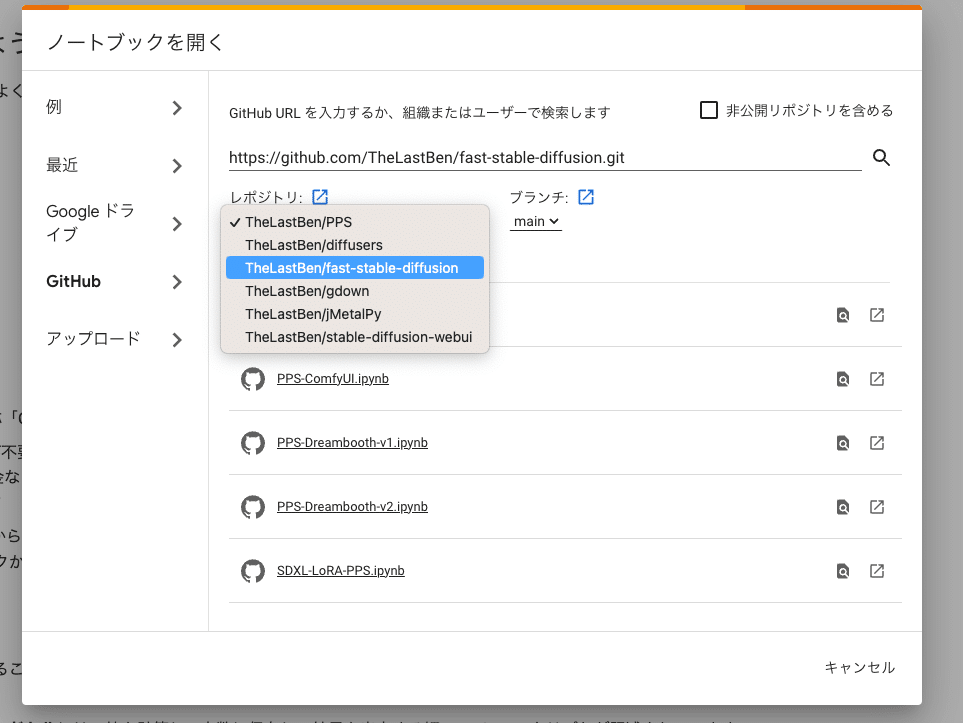
次に、レポジトリを「TheLastBen/fast-stable-diffusion」に変更してください。
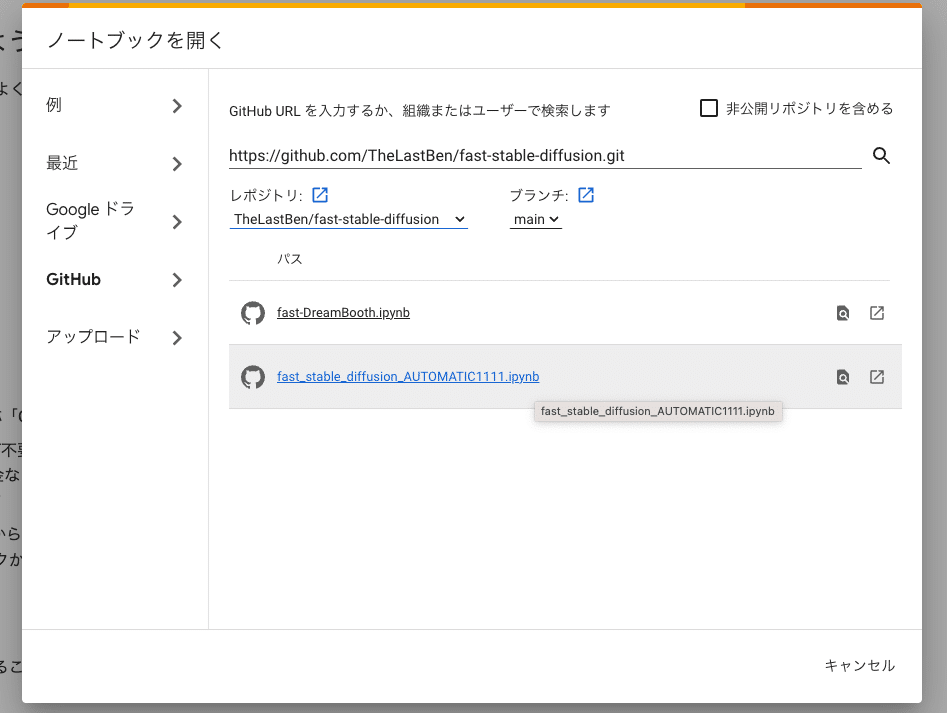
次に、2番目のこれをクリックしてください。
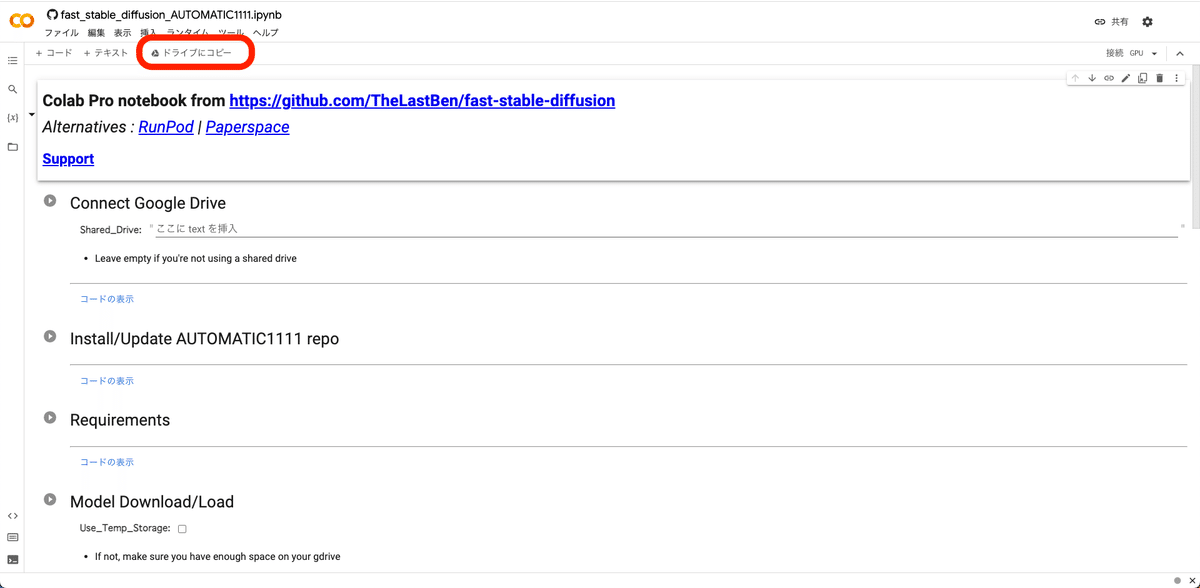
このような画面になります。
次に画面左上の「ドライブにコピーを保存」をクリックしてください。これで、このページのコピーが、Googleドライブに保存されます。
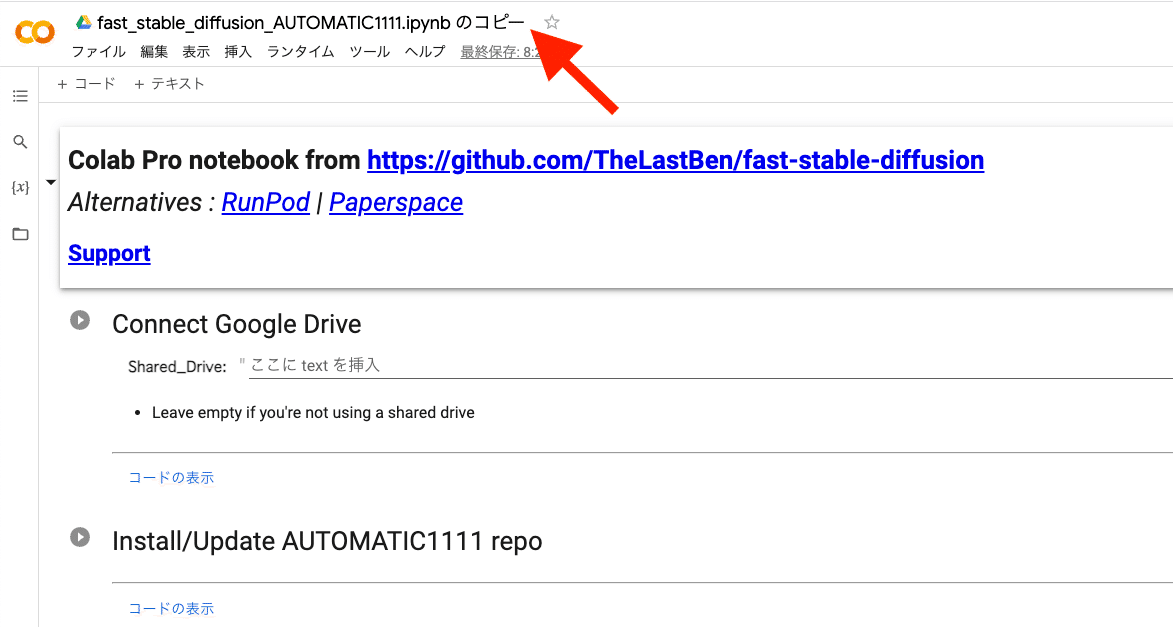
これ以降は全て「コピー」の方で操作するので、注意してください。先ほどの「コピーじゃない方」のページ↓は閉じてください。
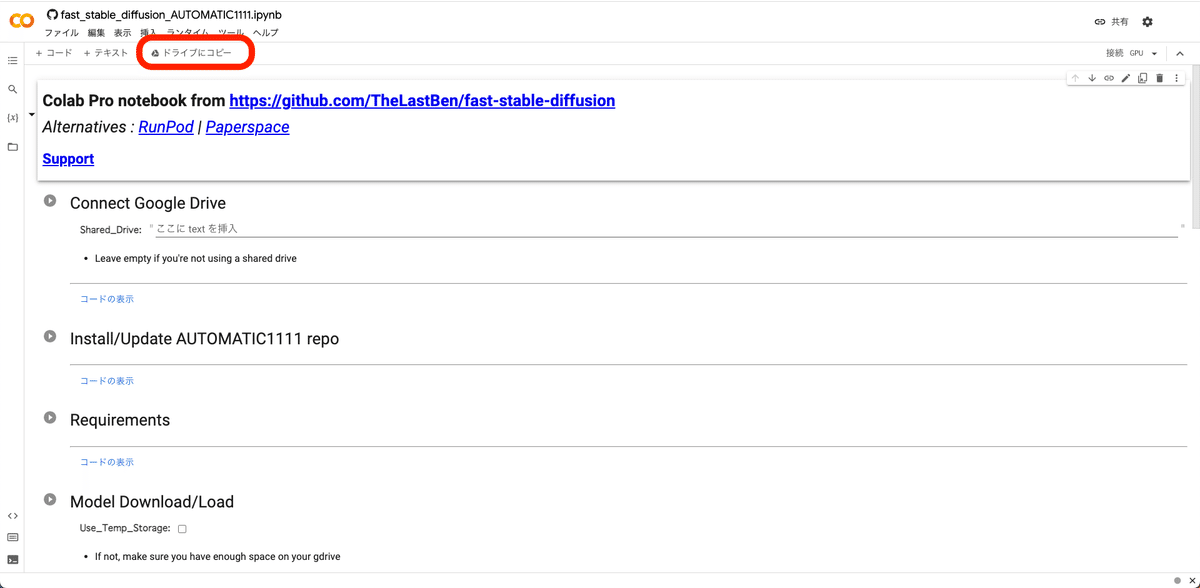
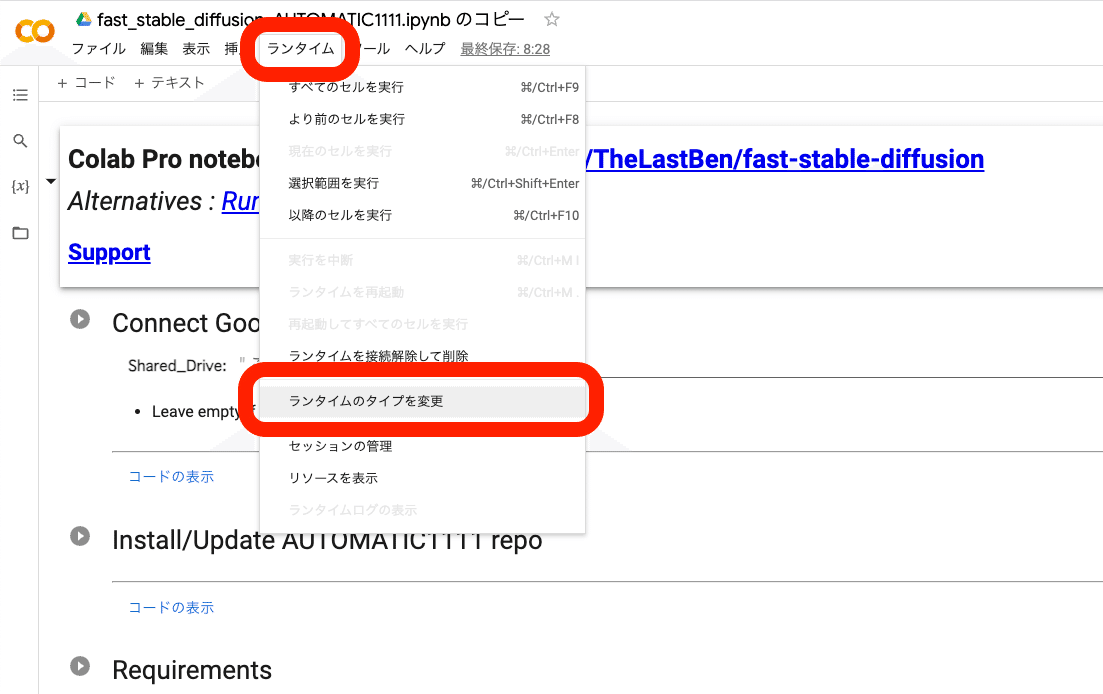
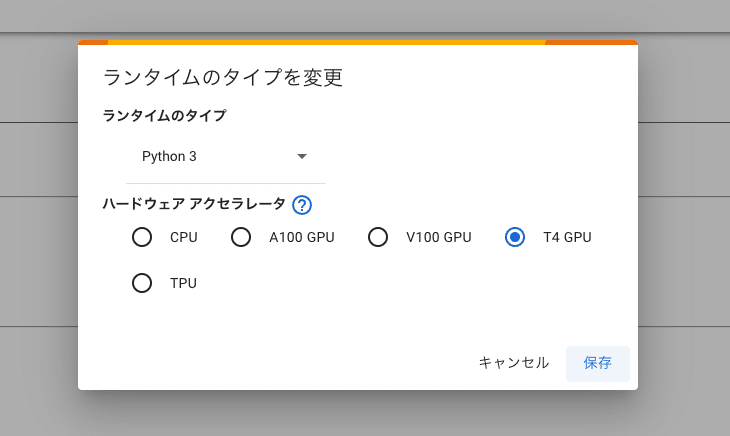
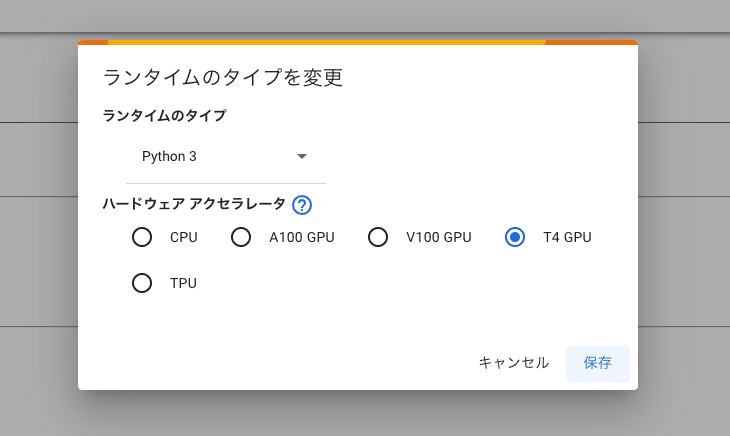
「ランタイム」→「ランタイムのタイプを変更」から、「ハードウェア アクセラレータ」がGPUになっていることを確認してください。
・A100 GPU
・V100 GPU
・T4 GPU
のいずれかです。
GPUのタイプは3つあり、どれを選んでも大丈夫です。A100が1番性能が高く、T4の性能が1番低いです。性能が高いほど、画像生成の時間が速くなりますが、コンピューティングユニットの消費も多くなります。
T4でも生成スピードは十分に速いです。大量かつ大きめの画像を生成する場合でなければ、T4をおすすめします。
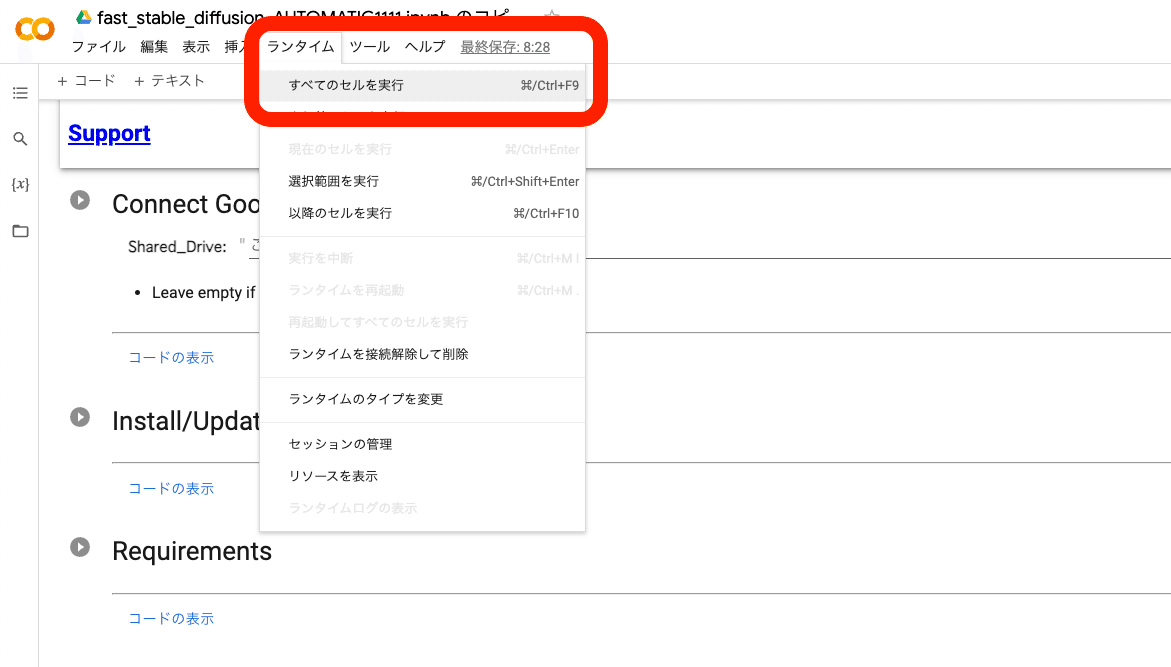
これからStable Diffusionを起動します。ランタイム → すべてのセルを実行 をクリックしてください。
すぐにこれが表示されるので、「Googleドライブに接続」をクリックしてください。Googleアカウントへのアクセスリクエスト画面が表示されるので、「許可」をクリックしてください。
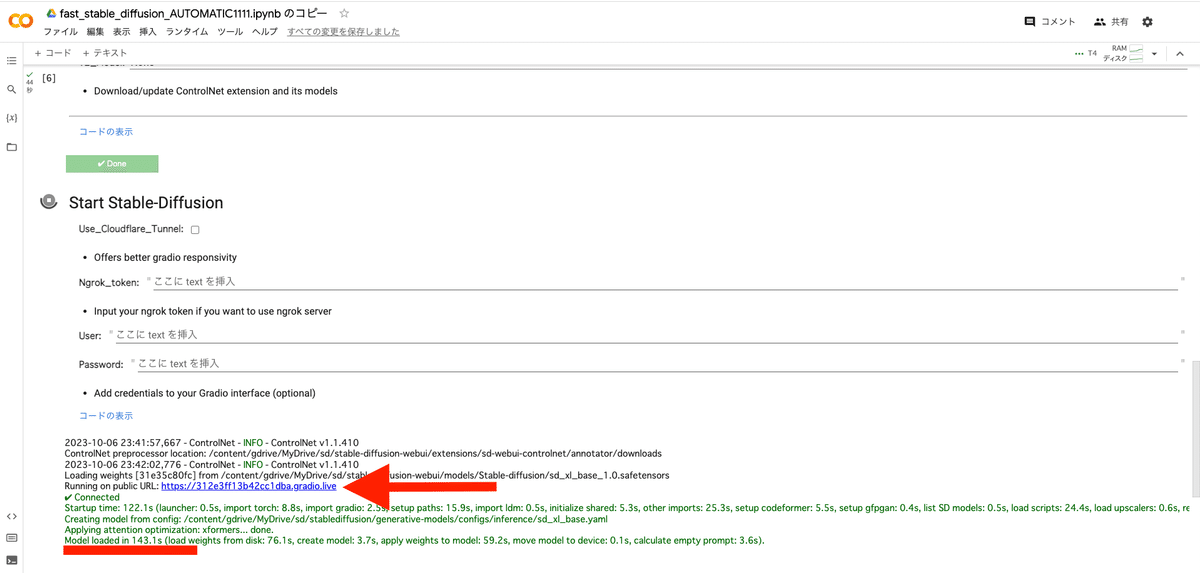
起動は、毎回5〜10分くらい待つ必要があります。「Model loaded in …」が表示されたら完了です。URLをクリックしてStable Diffusionを開いてください。
「Model loaded in …」が表示される前にURLは表示されますが、すぐにクリックしても読み込みに時間がかかったり、エラーが出ます。「Model loaded in …」が表示されるまで待ってください。
また、エラーなどが出ると、そのコードはこの欄に表示されます。
お疲れさまでした!これがStable Diffusion WebUIの画面です。
※ DeepL翻訳が起動すると、なぜか不具合が生じることがあります。そのときは「元の言語を表示する」をクリックし、翻訳されないようにしてください。もし不具合が生じた場合は、この画面を一旦閉じて、先ほどのURLをクリックしてもう1度開いてください。
エラーが出てしまったり、うまく行かなかった場合の対処法については、次のリンク↓を確認してください。
□ エラーが出たり、うまく行かなかった場合
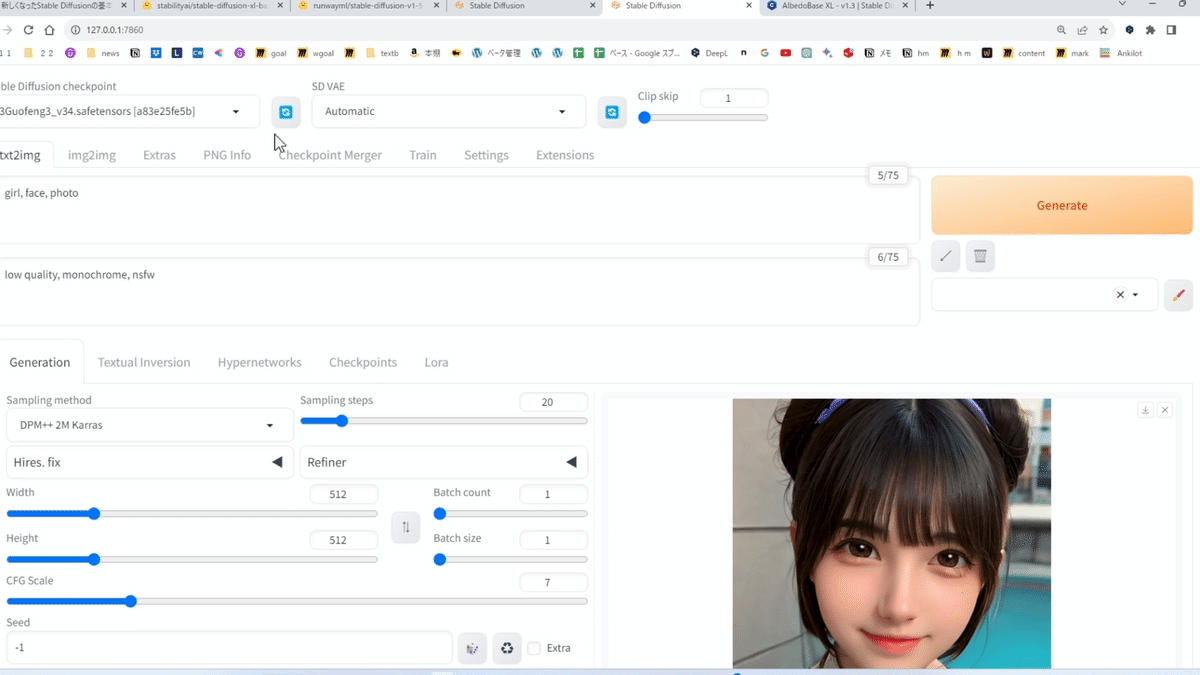
□ 基本操作
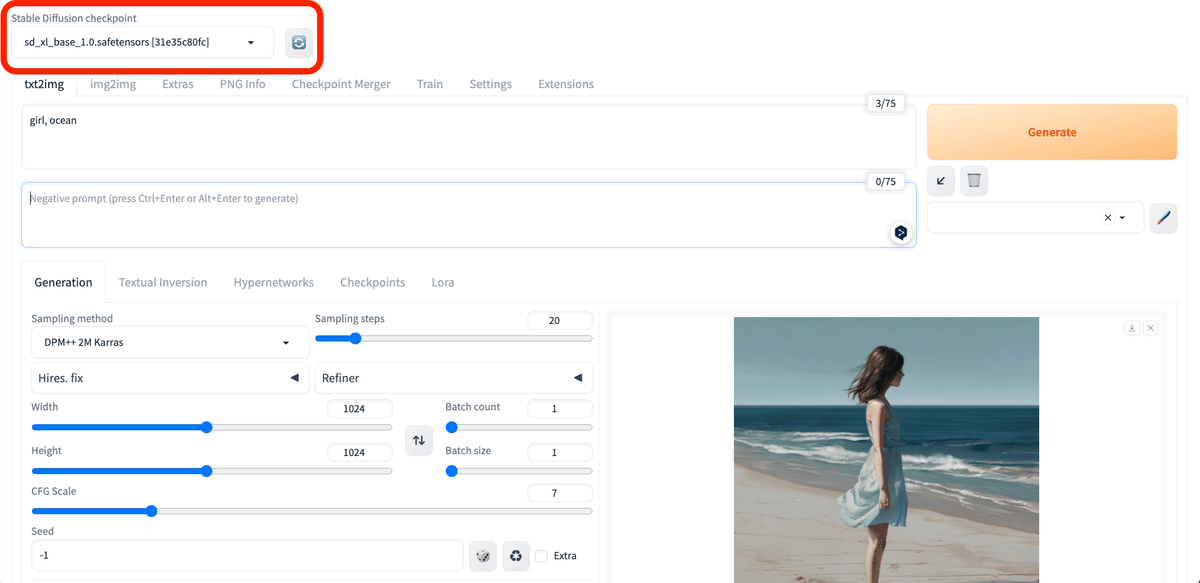
画像生成するには、まず「Stable Diffusion Checkpoint」でチェックポイントを選択してください。チェックポイントは「モデル」と呼ばれることが多いですが、同じ意味です。モデルとチェックポイントという言葉は、覚えてください。
初期モデルが1つ入っているので、それを選択してください。Stable Diffusionの公式モデル(ベースモデル)では、あまり高品質な画像は生成できないので、後でモデルを自分で追加します。とりあえずは、これで画像生成を試してみます。
まず、生成したい画像の説明文を入力します。
・上の段(プロンプト):生成したい画像の特徴
・下の段(ネガティブプロンプト):生成したくない画像の特徴
を入力してください。
入力するテキストは、英語で、カンマで区切って入力します。文章でも生成できますが、「可愛いネコを書いてください」のような命令文や会話文ではなく、「可愛いネコ」のように書いてください。
ちなみにChatGPTやBing AIに搭載されているDALL-E3では、命令文や会話文、日本語でも画像生成できます。DALL-Eの強みです。
以下は、プロンプトの例です。
・プロンプト:girl, face, smile, photo
・プロンプト:girl, ocean, standing, anime style
・ネガティブプロンプト:worst quality, bad quality, low quality, ugly, monochrome, dark
画像を生成するには、右側の「Generate」ボタンをクリックします。その前に、以下で画像のサイズを変更してください。
クリックするごとに、違う画像が生成されます。同じ画像や似た画像を生成する方法は、別の記事で解説します。
画像生成中に「Interrupt」をクリックすると、画像生成を途中でストップできて、途中結果のまま表示されます。
Width / Heightでは、画像サイズを変えられます。後で詳しく説明しますが、今使っているモデルは、SDXLバージョンのモデルです。
SDXLは、1024サイズ周辺で多く学習されたので、1024サイズから離れるほど、絵が崩れた画像が出やすくなります。そのため、
・正方形:1024*1024
・縦長(9:16):768*1344
・横長(16:9):1344*768
サイズがオススメです。例えば、Width / Heightで、512×512などの小さめの画像を生成しても良いですが、絵が崩れやすくなります。
拡大方法については、別の記事で解説します。
注意点として、1500×1500サイズくらいの画像になると、GPUにかかる負担が大きくなり、エラーが出やすくなります。特に性能が低いGPUを使っている方は、注意してください。
□ パラメータを初期設定に戻す方法
色々と設定を変えた後で、初期設定(デフォルト)に戻したい場合は、Webページを再読み込みしてください。
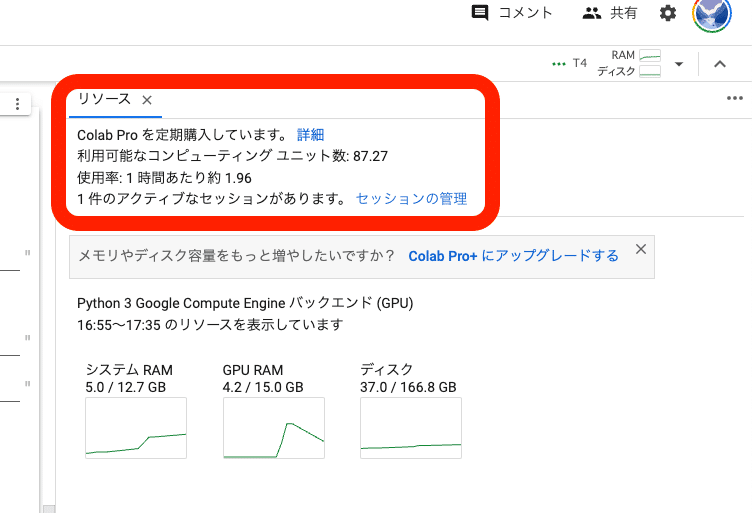
□ Colabの使用状況の確認
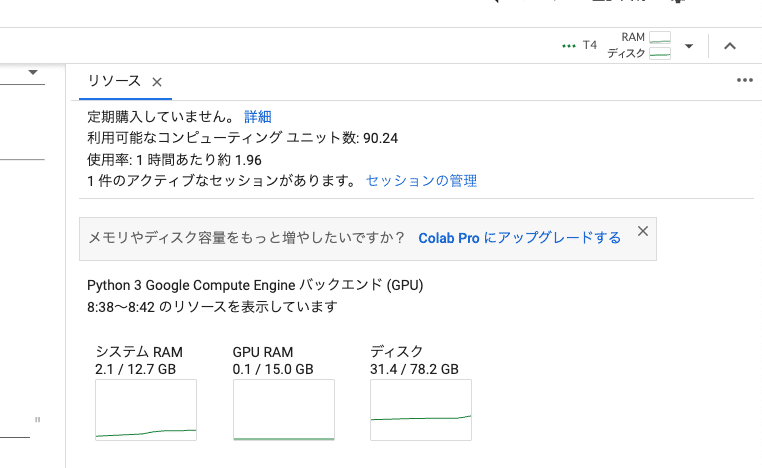
この画面に戻り、画面右上の「RAM ディスク」をクリックすると、Colabの使用状況が表示されます。もう1回おすと閉じます。
利用可能なコンピューティングユニット数:残りのコンピューティングユニットです。0になったら、追加で購入する必要があります。
使用率:1時間あたり、どれくらいコンピューティングユニットを消費するかの目安です。画像を生成していなくても、Stable Diffusionを起動しているとユニットが消費されるので、注意してください。
1件のアクティブなセッションがあります:コンピューティングユニットを使っているときは「1件」と表示されます。Stable Diffusionの起動を終了すると、「0件」と表示されます。
□ ColabでのStable Diffusionの終了方法
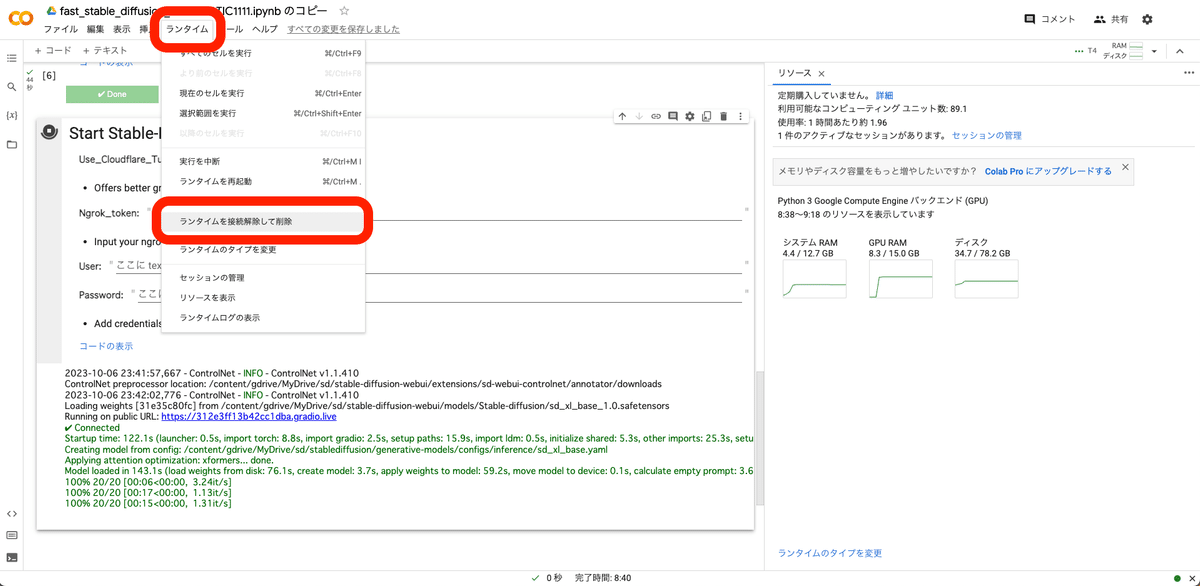
ランタイム → ランタイムを接続解除して削除 をクリックすると、終了できます。
・接続 or 再接続
・0件のアクティブなセッションがあります
となっていれば、終了できています。
また、最長で12時間たつと、勝手に終了になります。(Pro+プランは最長で24時間)あと、起動中でも操作せずに放置していると、ランタイム接続解除されて終了されます。
□ Colab解約方法(参考:Colab公式サイト)
Colab Pro/Pro+プランを定期購入した方は、 Colab から解約可能です。解約した場合でも、Colab Pro/Pro+は最後の支払いから1ヶ月間利用できます。
Pay As You Goプランは買い切りであり、定期購入ではないので、解約する必要はありません。
□ 2回目以降の起動方法
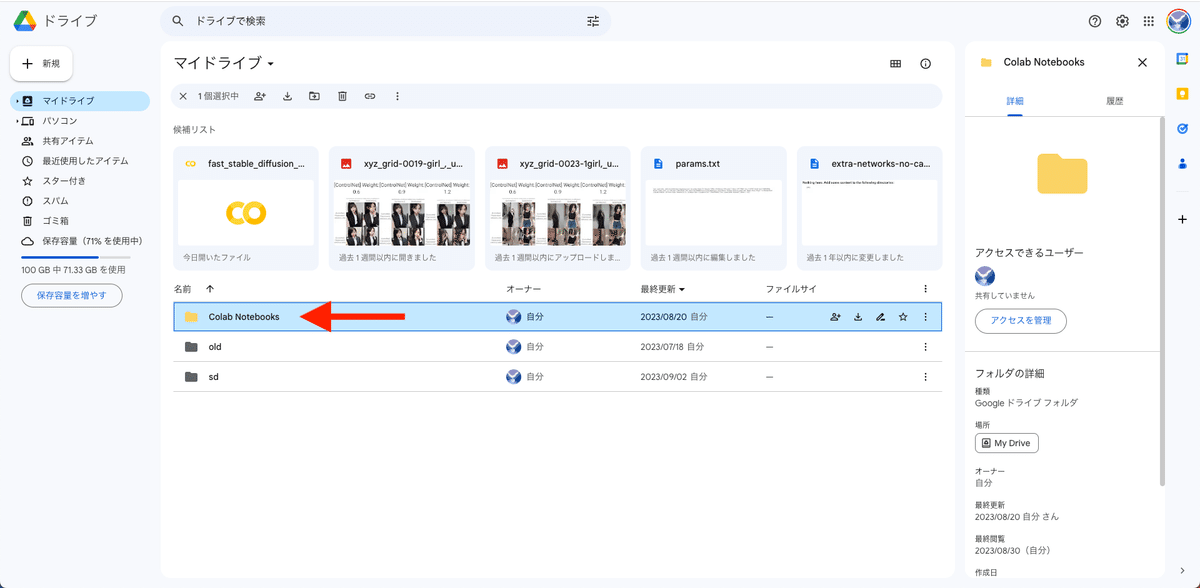
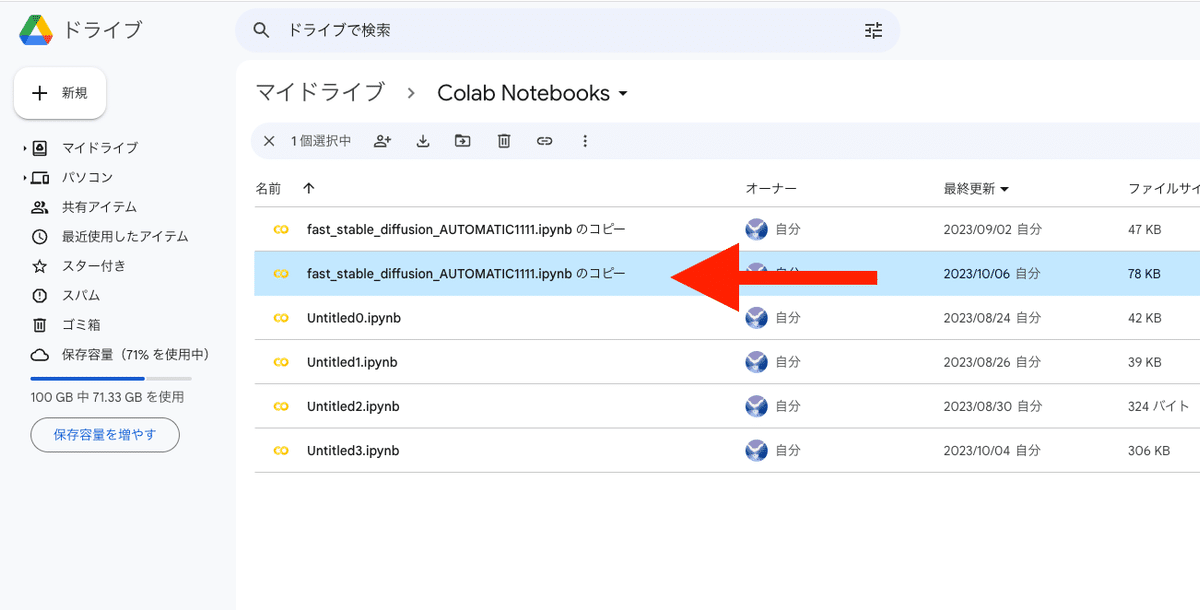
Googleドライブを開き、「fast_stable_diffusion_AUTOMATIC1111.ipynb のコピー」をクリックしてColabを開きます。
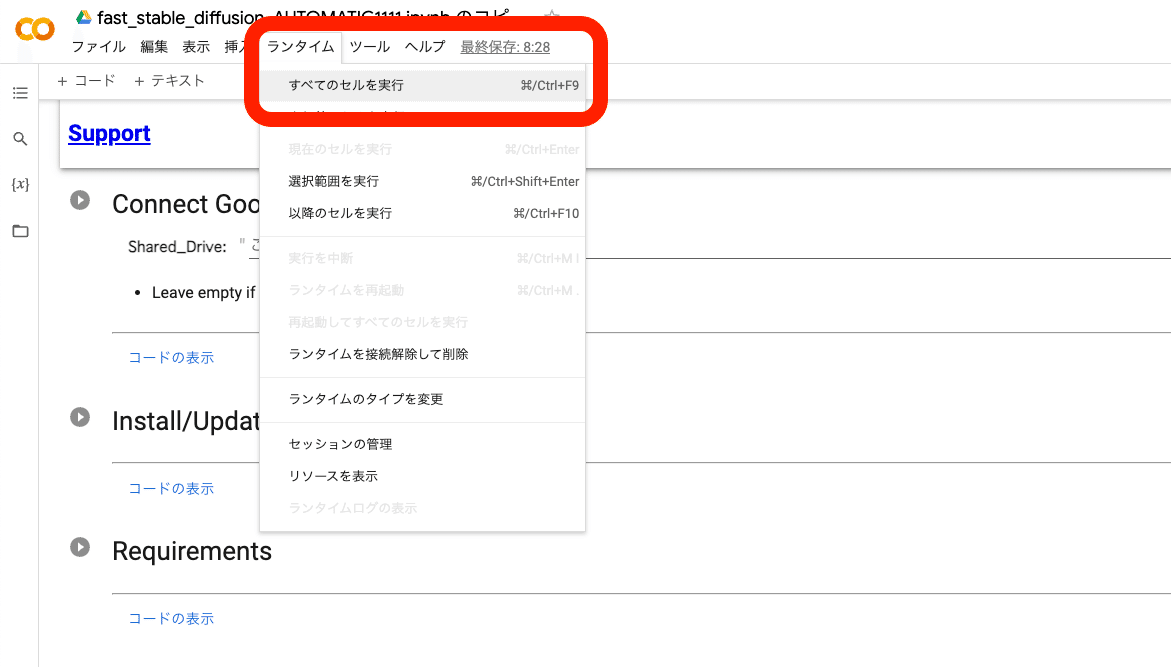
後は、初めて起動したときと同じです。「ランタイム」→「すべてのセルを実行」をクリックしてください。
□ Stable Diffusionで生成した画像の保存場所
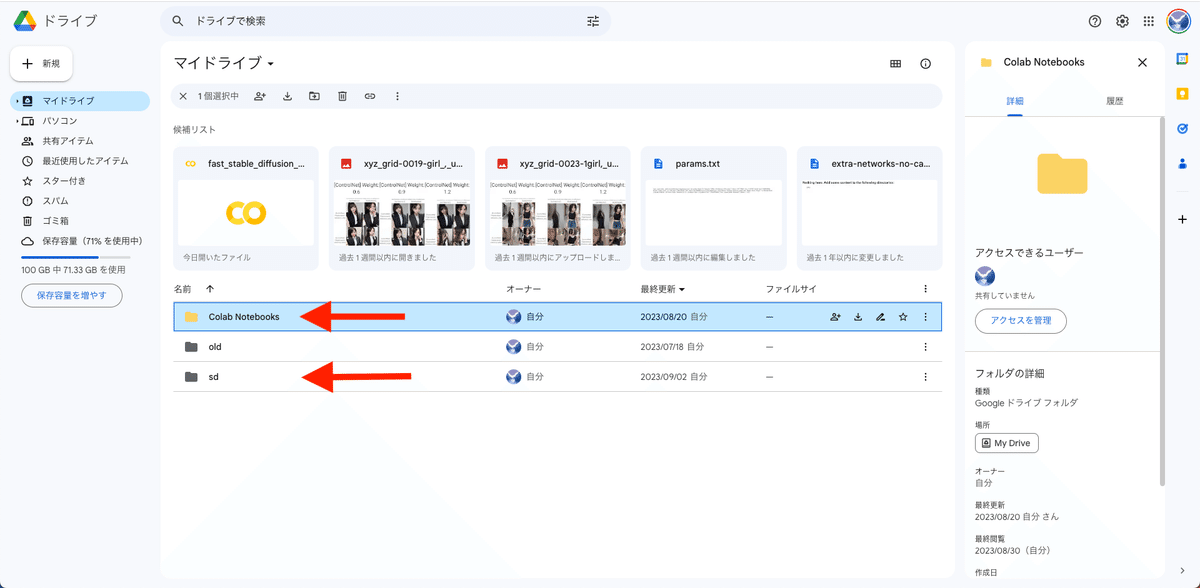
ColabでStable Diffusionを使えるようにすると、Google Driveに「Colab Notebooks」と「sd」というフォルダが追加されます。いま使うのは「sd」の方です。
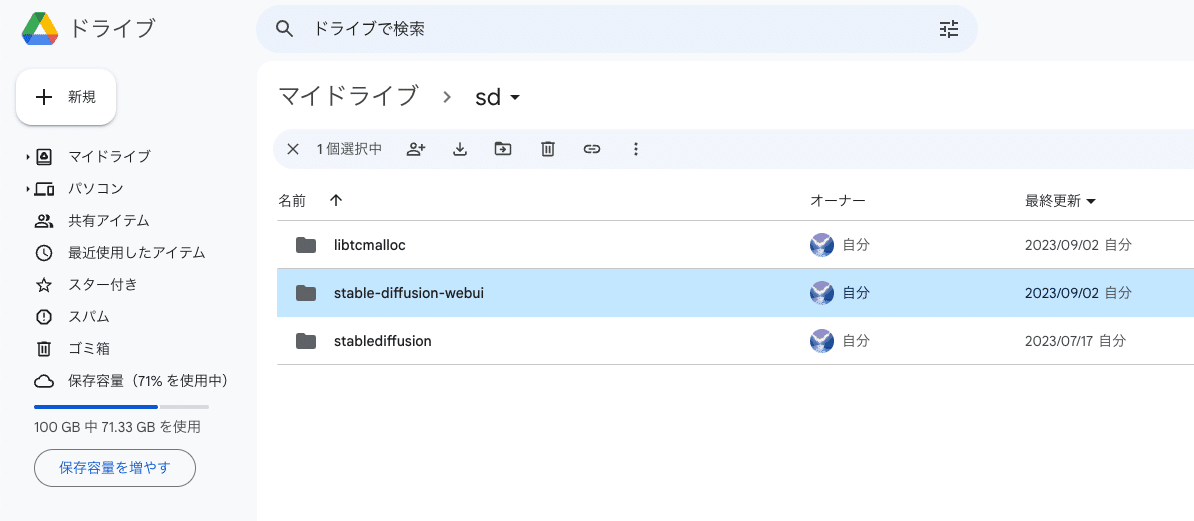
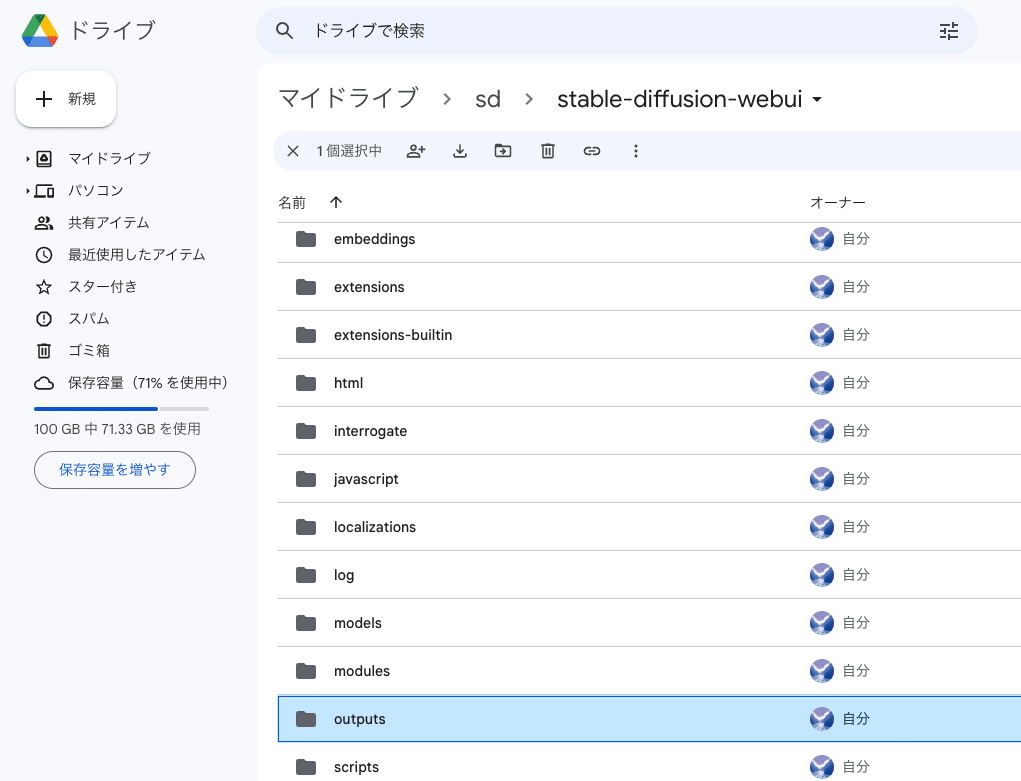
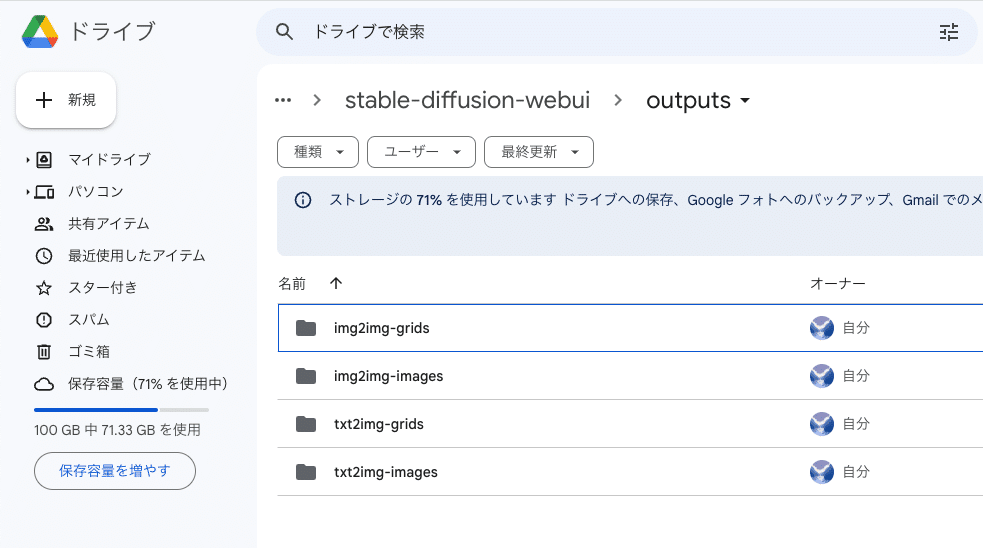
「sd」→「stable-diffusion-webui」→「outputs」の中に、生成した画像が自動で保存されていきます。
画像は容量がやや大きいので、容量を節約したい場合は、定期的に削除してください。
□ モデルの説明
モデルとは「学習済みのデータ」のことで、「チェックポイント」とも呼ばれています。
Stable Diffusionをインストールした時点では、SDXL版の公式モデルしかインストールされていません。
SDXL版の公式モデルは、クオリティが高い画像はあまり出すことができないので、自分でモデルを追加する必要があります。
・写真のようなリアルな画像を生成したいときは、リアル用のモデル
・イラスト風の画像を生成したいときは、イラスト用のモデル
を使う方が、目的に近い画像を生成しやすいです。そのため、モデルは自分の目的に合ったものを選んでインストールします。
Stable Diffusionは起動していても、停止していても、どちらでも大丈夫です。
モデル(チェックポイント)を変えるときは、Stable Diffusion画面の以下のどちらかから、変更できます。
・左上のStable Diffusion checkpoint
・中央あたりのCheckpoints
モデルを入手できるサイトは、「Civitai」と「hugging face」が有名です。Civitaiは画像生成AIに特化していますが、hugging faceは画像生成AI以外にも自然言語処理や音声処理など、様々な学習済みのデータが共有されています。
hugging faceは、Civitaiのサイトと違い画像が少なく文字がメインで、上級者向けのサイトです。どちらの使い方も紹介しますが、Civitaiがオススメです。
□ Civitaiとは?
Civitaiは、Stable Diffusionのような画像生成AIサービスで使うモデルが共有されているサイトです。モデルはチェックポイントとも言います。
様々なモデルを閲覧したりダウンロードすることができます。
サイトを見てもらえれば、モデルごとにどんな画像が生成できるか、だいたい分かると思います。モザイクがかかっているのは主にアダルト系のモデルです。ログインすると、すべて見れるようになります。
モザイクを解除するには、「18+」などの部分をクリックしたり、画面右上の目のマークから、モザイクの設定を変更してください。
□ Civitaiの使い方、インストール方法
試しに1つモデルをダウンロードしてみましょう。好みのモデルを選んでください。
左上の「Models」をクリックしてモデルだけを表示させます。チェックポイントと書かれているのが、モデルです。
・チェックポイント:SD1.5版のモデル
・チェックポイントXL:SDXL版のモデル
SD1.5とSDXLの比較は、後ほど解説します。簡単に説明すると以下のとおりです。
・SD1.5:有名で使用者が多い、まだ現役のモデル。拡張機能と相性が良い。
・SDXL:最新版のモデル。手軽に高品質な画像が作れる。
比較のために、両方インストールするのがオススメですが、PC性能が高くない方はSD1.5だけでも大丈夫です。
初期設定では、評価順に並んでいるので、上に位置するモデルが高評価されているモデルです。並びの設定は、上の画像のように変えることができます。
画面右上にある設定から、期間も指定可能です。
モデルは、気に入ったものをインストールしていただければ大丈夫です。
・最新版のSDXL
・最も普及しているSD1.5
の両方を使ってみたい方は、以下のように、同じ作者が作成したモデルを選ぶと、効率的に比較検証が行えます。
✓ リアル風のモデル
・XXMix_9realisticSDXL
・XXMix_9realistic
・nagatsuki_mix
・yayoi_mix
✓ イラスト風のモデル
・SakuraMix-XL./Anime-like
・SakuraMix
・CounterfeitXL
・Counterfeit-V3.0
次は、Civitaiでのインストール方法について解説します。上記の、ダウンロードをクリックしてください。とりあえず、どこでもいいので保存してください。
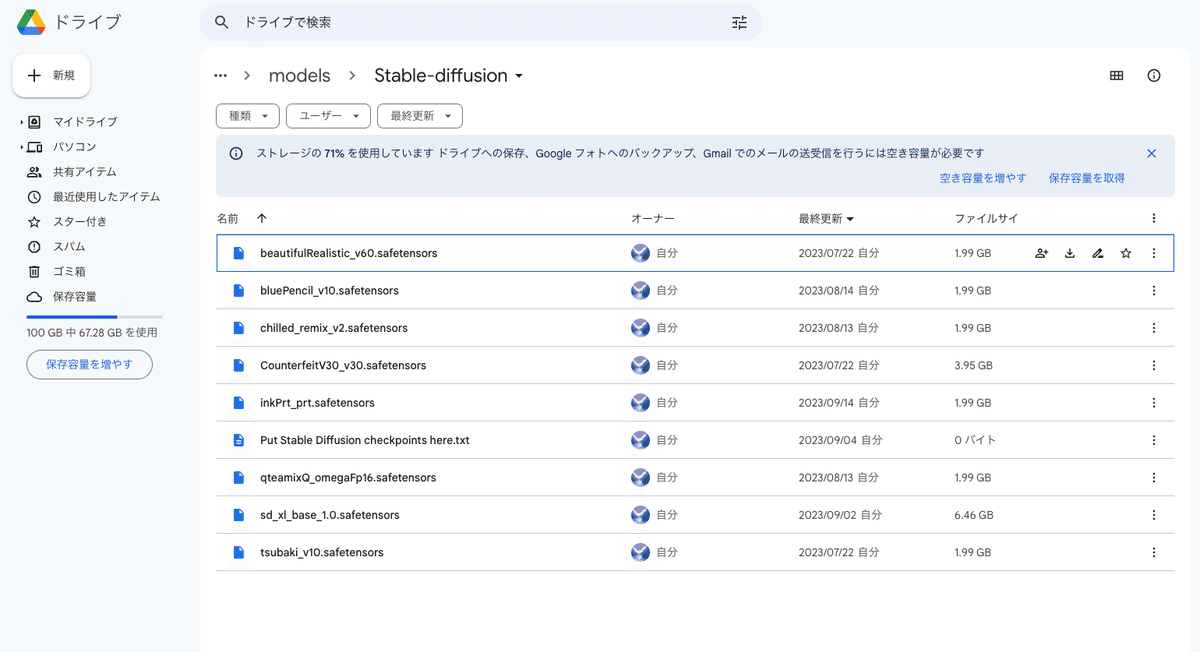
先ほど保存したモデルファイルを、「sd」→「stable-diffusion-webui」→「models」→「Stable-diffusion」の中に入れてください。
モデルの容量はとても大きいです。不要なものは削除や移動して整理するか、ストレージを追加購入してください。
他のモデルも同じやり方でダウンロードできます。
Stable Diffusionを起動すると、モデルは自動でインストールされます。
Stable Diffusion起動中にモデルをインストールする場合は、チェックポイント欄の右にある、再読み込みアイコンをクリックしてください。
以上の操作は、新しいモデルを追加するときだけで大丈夫です。2回目からは、Stable Diffusionにモデルは読み込まれた状態で使用できます。
Stable Diffusionをインストールすると、自動的に、sd_xl_baseという公式モデルがインストールされます。これは、SDXL版の公式のモデルです。
SD1.5版は、インストールされていないので、自分でインストールする必要があります。
SDXLの公式モデルがインストールされていない方は、こちら stabilityai/stable-diffusion-xl-base-1.0 をダウンロードしてください。保存する場所は、先ほどと同じです。
SD1.5版の公式モデルは、runwayml/stable-diffusion-v1-5 こちらからダウンロードしてください。初期モデルでは、クオリティが高い画像はあまり出せないので、ほぼ使いません。そのため、インストールする必要はないのですが、今回はSDXLと比較したい方も居ると思うので、あえてインストールします。
SDXLの公式モデルは、けっこうクオリティが高いです。使い方によっては、これだけでも大丈夫です。
□ サムネイルを表示させる方法
モデルをたくさんインストールすると、どれがどれだか分かりにくくなります。
そこで、中央あたりのCheckpoints欄から、モデルをサムネイル付きで見ることができます。しかし、普通にインストールした場合は、サムネイルは付きません。
そこで、自分でサムネイルを設定する方法を紹介します。
やり方は、簡単で、このように
・モデルファイル名(例:abc.safetensors)
・画像のファイル名(例:abc.jpeg)
を同じにするだけです。画像の拡張子は、pngでもOKです。
画像は、Civitaiなどからダウンロードしてください。
□ VAEの説明と、必要性
VAEとは、画質を良くするために使われるツールです。
VAE(Variable Auto Encoder)は、とても難しい技術です。詳しく知りたい方だけ「VAE(Stability AI)」を読んでください。
VAEなしで画像生成をすると、生成した画像の色が薄くなることがあります。また、エラーになるモデルもあります。そのため特にSD1.5において、VAEは設定してください。
一方で、SDXLは、VAEの有無で、画質の差はほとんど出ません。そのため、VAEの重要度は下がり、無くても良い状況です。いちおうSDXLのVAEが用意されているので、私は使っています。
注意点として、SD1.5で最も使われいたVAEであるvae-ft-mse-840000-ema-prunedは、SDXLと互換性がありません。ちなみに、使うと画質がとても粗くなります。
VAEだけでなく、モデル、ControlNet、LoRAも、SD1.5とSDXLは互換性がありません。SDXL専用のものが必要になります。これが、SDXLがあまり普及していない原因の1つですが、最近はSDXL用のものは増えてきています。
何かダウンロードするときは、SDXL用かSD1.5用なのか、確認お願いします。
VAEを使うことで、画質が必ず良くなるわけではありません。また、VAEが元からモデルに内蔵されていて、VAEが不要なモデルもあります。そのため、モデルをダウンロードするときは、説明欄もよく読んで、VAEが推奨されているかどうか確認してください。
例えば、「Dark Sushi Mix」モデルでは、上の画像のように、説明欄に「VAE推奨」と書かれています。VAEについて言及がないモデルは、自分で試してみて、画像のクオリティが変わるかどうか確かめてみてください。
□ VAEをインストールしよう
SDXL公式のVAEが、sdxl_vae.safetensorsです。
SD1.5用のVAEは、「vae-ft-mse-840000-ema-pruned」が有名です。
こちらも、Stable Diffusionの開発元でもあるStability AIが作成したものです。このVAEは、リアル系のモデルにも、イラスト系のモデルにも効果があります。
この2種類のVAEファイルのどちらでも問題ありませんが、最近は「safetensors」のファイルがよく使われています。こちらの方がセキュリティ的に安全らしいので、safetensorsをダウンロードしてください。
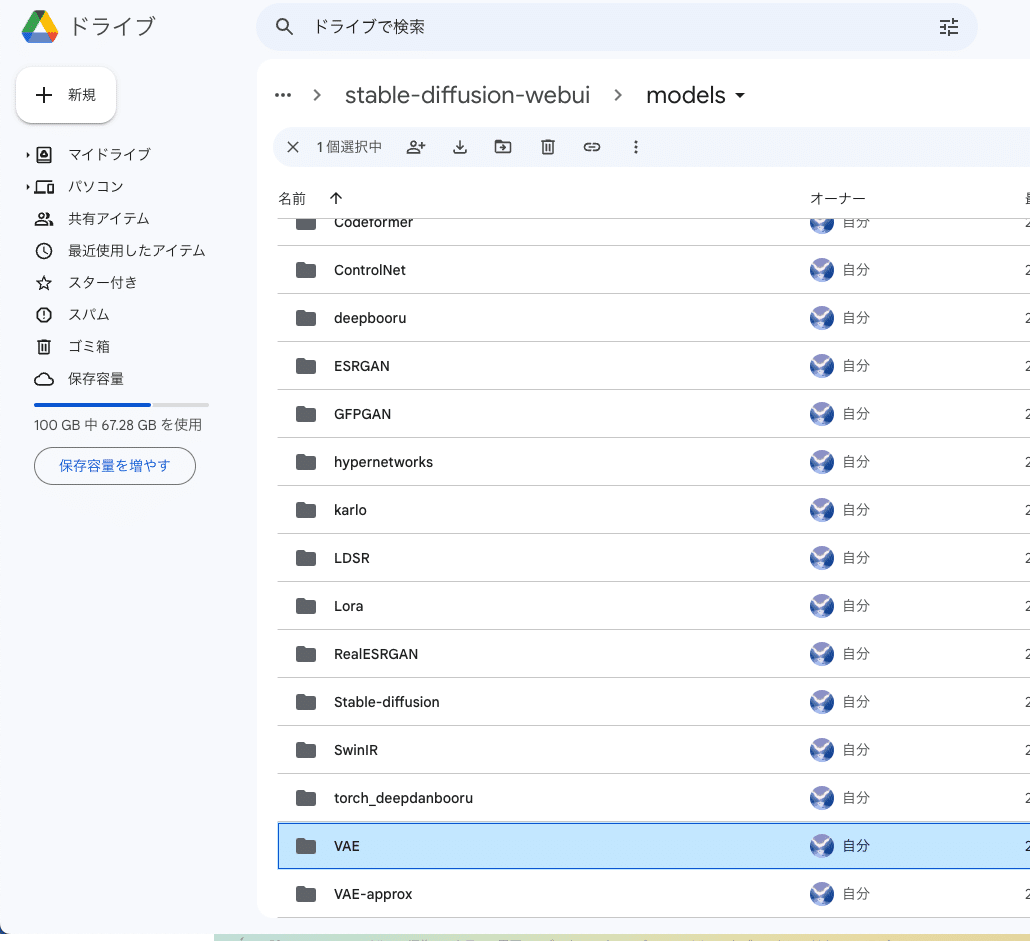
ダウンロードしたVAEファイルは、「sd」→「stable-diffusion-webui」→「models」→「VAE」の中に入れてください。
次に、「Settings」→「User Interface」を開いてください。「[info] Quicksettings list」で「sd_vae」と入力するか選択してください。
設定を変更したら、最後に「Apply settings」をクリックし、「Reload UI」をクリックしてください。
Stable Diffusionを再起動すると、「VAEタブ」が表示されます。
モデルと同じように、「SD VAE」の欄で、VAEを切り替えることができます。インストールしたVAEがない場合は、読み込みマークをクリックするか、Stable Diffusionを再起動させてください。
まとめ
・SDXL系のモデルを使う場合 → sdxl_vae.safetensors を使う。
・SD1.5系のモデルを使う場合 → vae-ft-mse-840000-ema-pruned を使う。あるいは、モデルごとに推奨されているVAEがあれば、それを使う。
□ 画像の保存方法
画像の保存は、生成された画像を右クリック → 名前を付けて保存 で可能ですが、Stable Diffusionでは自動で保存されていきます。
sd → stable-diffusion-webui → outputsに保存されていきます。
画像は容量がやや大きいので、定期的に削除したり移動して整理するか、容量を追加で購入してください。
□ SD1.5系のモデルを使う場合の、画像の拡大方法
Width / Heightでは、画像サイズを変えられます。後で詳しく説明しますが、今使っているモデルは、バージョンがSD1.5のモデルです。
SD1.5は、512サイズの正方形の画像で多く学習されたので、512サイズから離れるほど、崩れた画像が出やすくなります。そのため、
・512×512
・400×600
・600×400
サイズがオススメです。例えば、Width / Heightで、1024×1024などの大きめの画像を、最初から生成しても良いですが、崩れやすくなります。
そのため、大きな画像を作るときは、Hires.fixを使うのがオススメです。これは2段階で画像を拡大する機能です。最初に512×512などの小さめのサイズで生成し、画質を改善しつつ画像の拡大をしてくれます。
他の拡大方法については、操作が多いので、別の記事で解説します。
注意点として
・Width / Height
・Hires.fix
どちらに関しても、1500×1500サイズを超える画像になると、GPUにかかる負担が大きくなり、エラーが出やすくなります。特に性能が低いGPUを使っている方は、注意してください。
■ クラウド環境で、Stable Diffusionを始める方法② (Google ドライブと連携しないColab)
□ メリット
Googleドライブと連携すると、アダルト画像が生成できないわけではありません。ただし、画像が児童ポルノだと判定されると、GoogleにアカウントBANされる可能性があります。
そのため、Googleドライブと連携しない方法では、アダルト画像を生成したいときなどに有効な方法です。この方法でGoogleアカウントがBANされた事例は、聞いたことはないですが、いちおう自己責任でお願いします。
□ デメリット
Googleドライブと連携しない方法では、生成した画像を、手動でダウンロードする必要があります。
また、使いたいモデルや拡張機能が、後で紹介するテンプレートに入っていない場合、自分でプログラミングコードを書く必要が出てきます。非エンジニアの方にとっては、やや難易度が高いです。
□ 始め方
非エンジニア向けに、自分でコードを書かなくてもStable Diffusionを実行できるテンプレートが、色々公開されています。
その中でも、safa-dayoさんが開発した「Colabコマンドのテンプレート」が分かりやすいので、これを使ってStable Diffusionを始めます。

「Raw」をクリックし、開いたページで、「command + Aキー」(またはcontrol + Aキー)で全選択をし、コピーしてください。
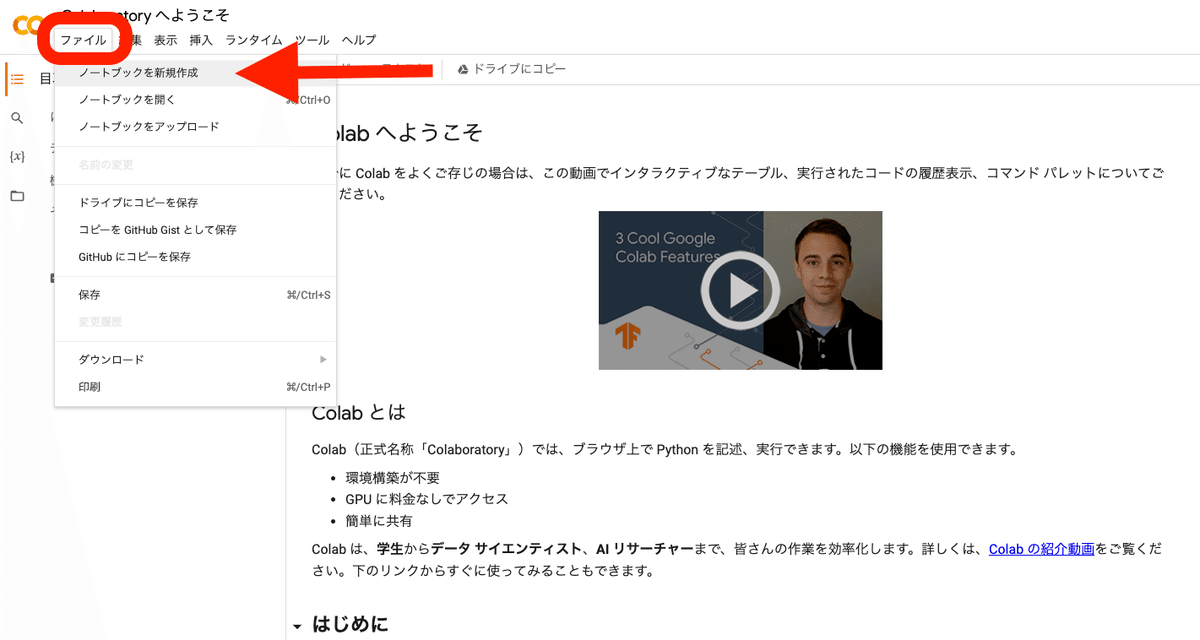
Colabのサイトを開き、「ノートブックを新規作成」をクリックしてください。
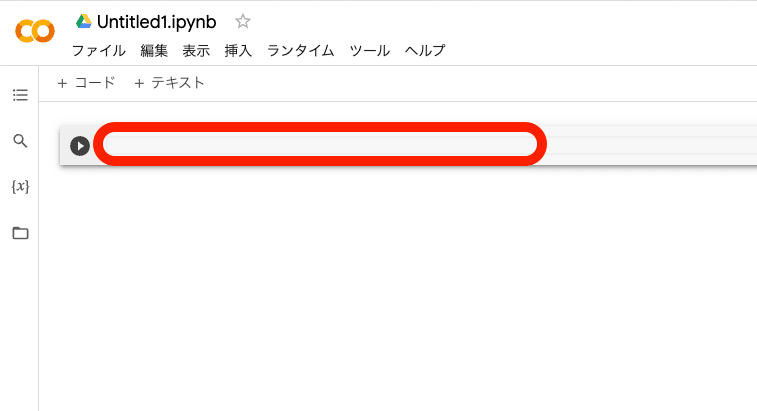
先ほどコピーしたものを、ここに貼り付けてください。
ちなみに、ここでの内容も、課金が必要です。購入方法は、前の方で開設したので、そちらを確認してください。
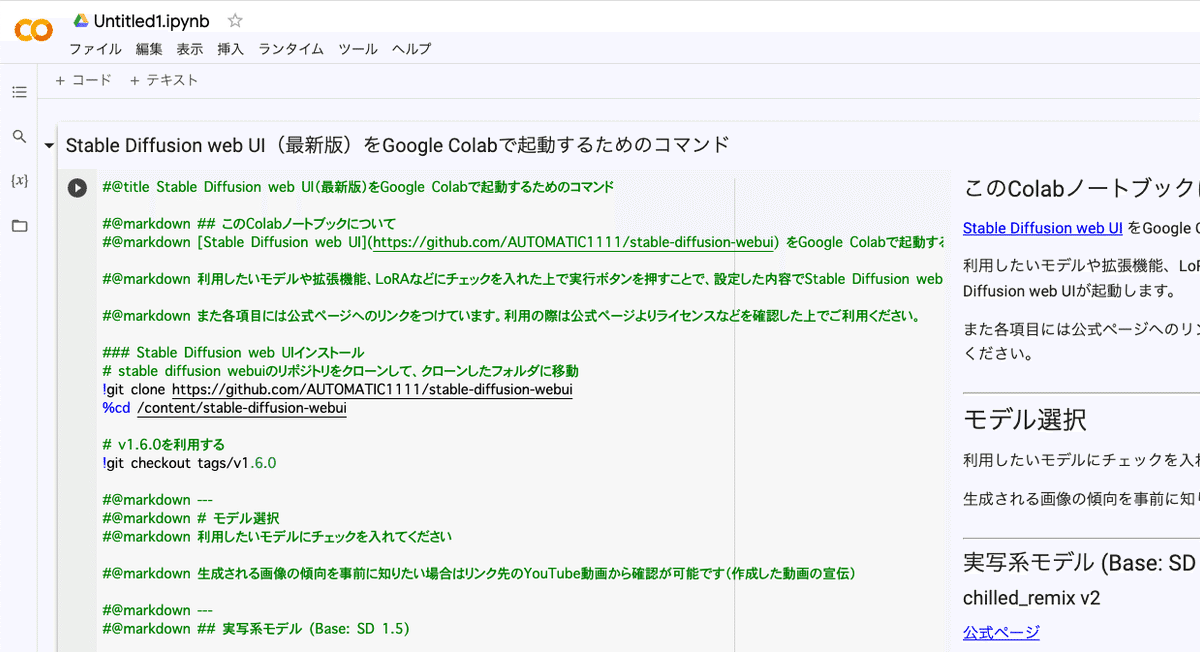
すると、このようになります。あとは、使いたいモデルにチェックを入れて、始めるだけです。
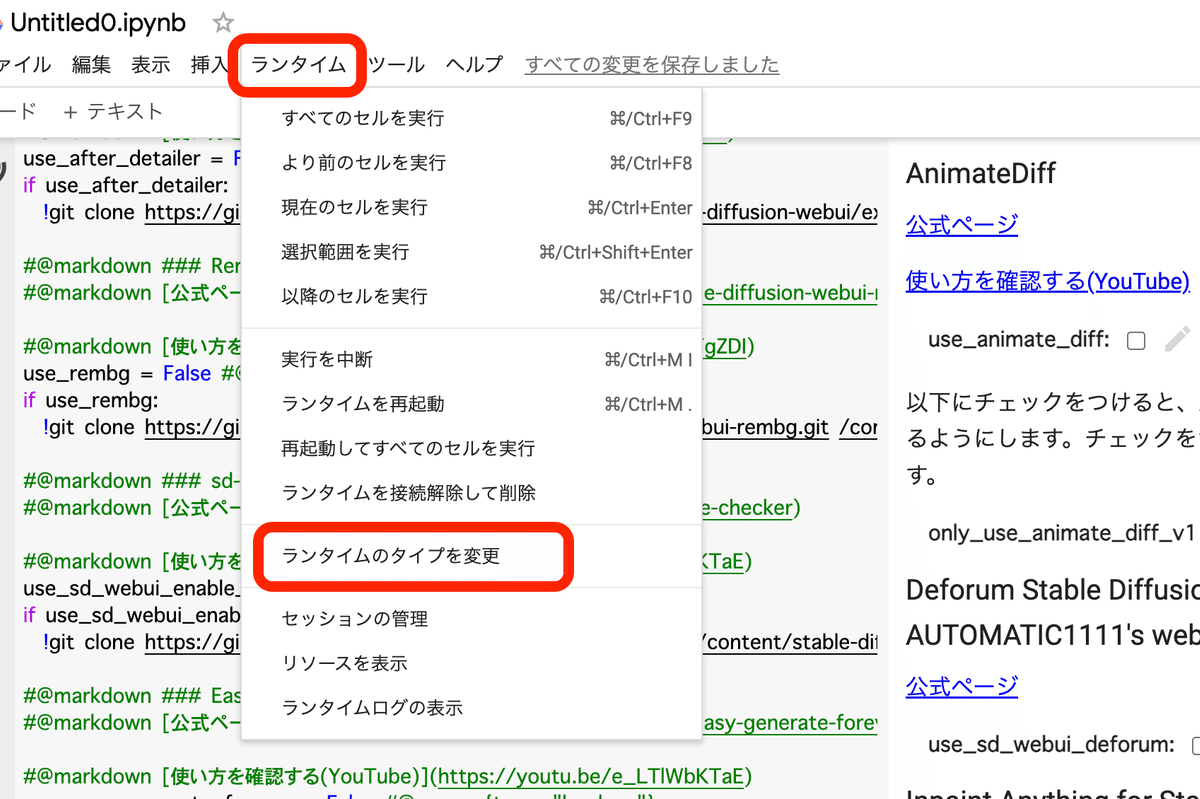
「ランタイム」→「ランタイムのタイプを変更」から、「ハードウェア アクセラレータ」がGPUになっていることを確認してください。
・A100 GPU
・V100 GPU
・T4 GPU
のいずれかですが、T4で十分です。
✓ リアル風の画像を作りたい方は
・chilled_remix v2
・BRA v7
・SDXL base 1.0
にチェックを入れて始めてください。今回は、お試しなので、私がオススメするモデルです。
また、2つのVAEにチェックを入れてください。
✓ イラスト風の画像を作りたい方は
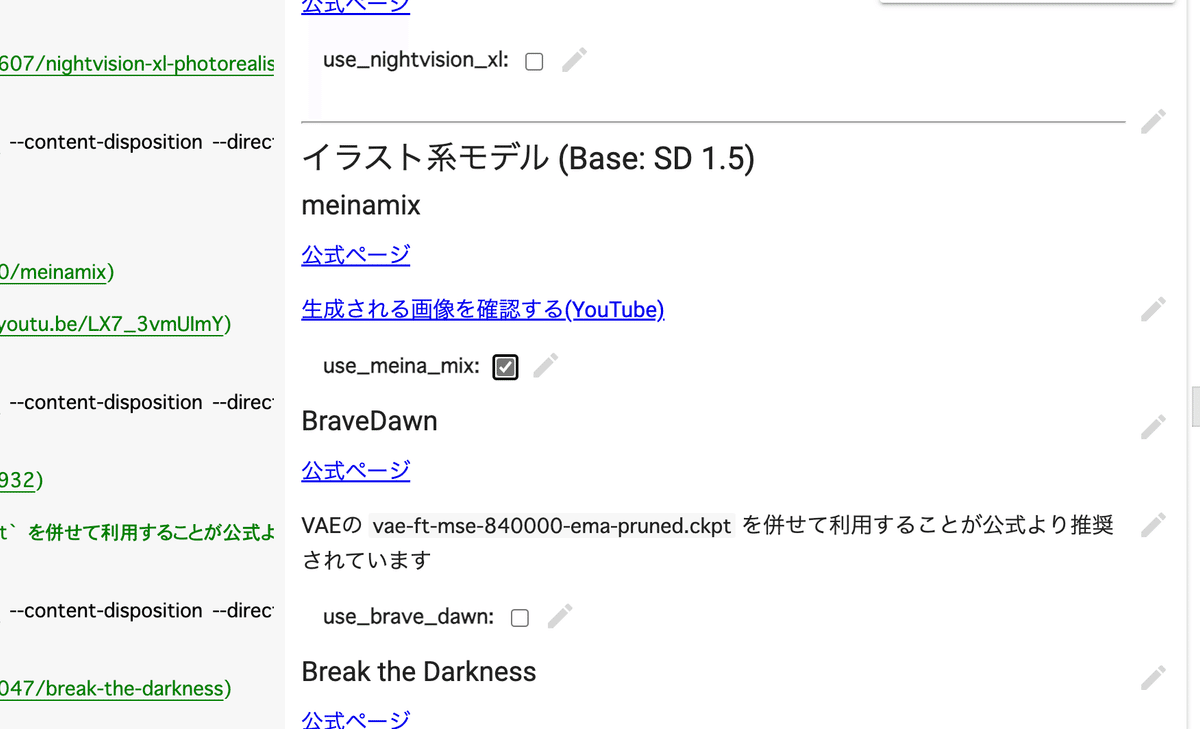

・meinamix
・blue_pencil-XL
・SDXL base 1.0
にチェックを入れて始めてください。
また、2つのVAEにチェックを入れてください。
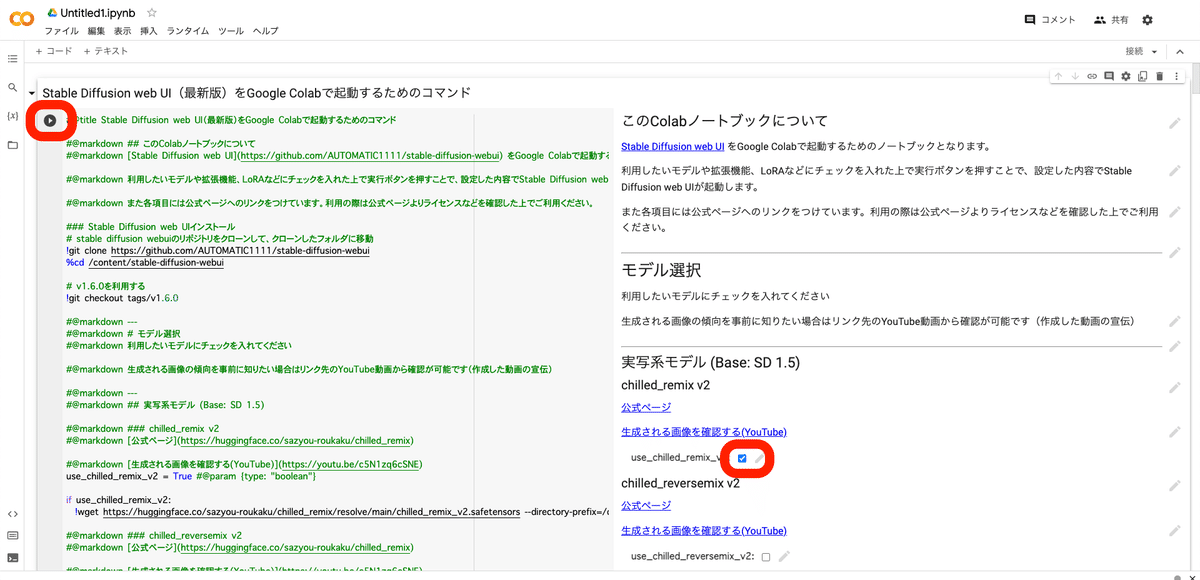
後は、使いたいモデルにチェックを入れて、再生マークをクリックするだけです。
こちらのGoogleドライブと連携しないColab版は、設定が毎回初めからになるので、開始するまでの時間は、先ほどのColab版よりかかります。何個チェックしたかによりますが、数分〜数十分かかると思ってください。
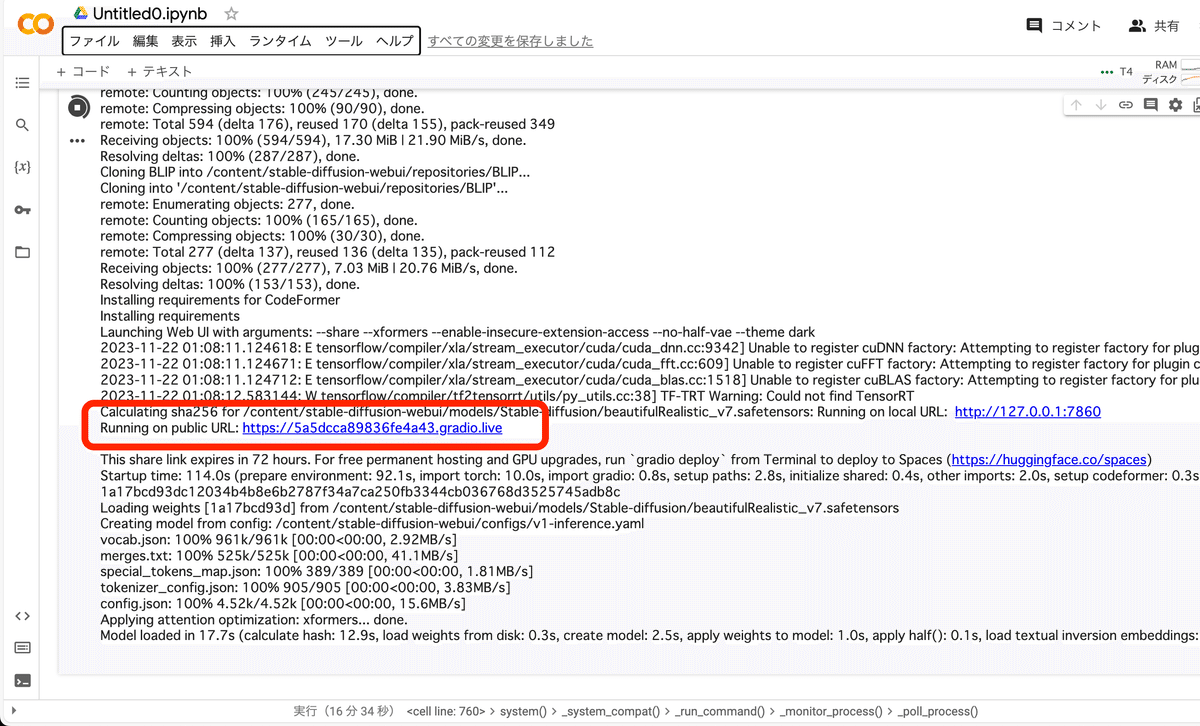
少し待つと、URLが表示されるので、それをクリックするとStable Diffusionを始められます。
□ モデルの追加方法
✓ Civitaiの場合
Googleドライブと連携しないColabであっても、好きなモデルを使うことができます。
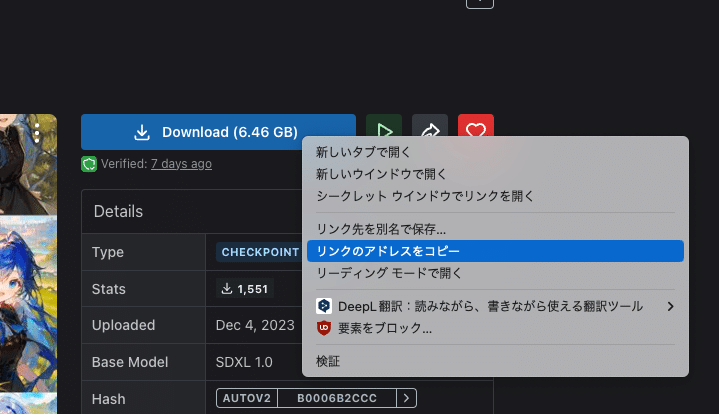
ダウンロードボタンを右クリックし、リンクのアドレスをコピーしてください。あるいは、
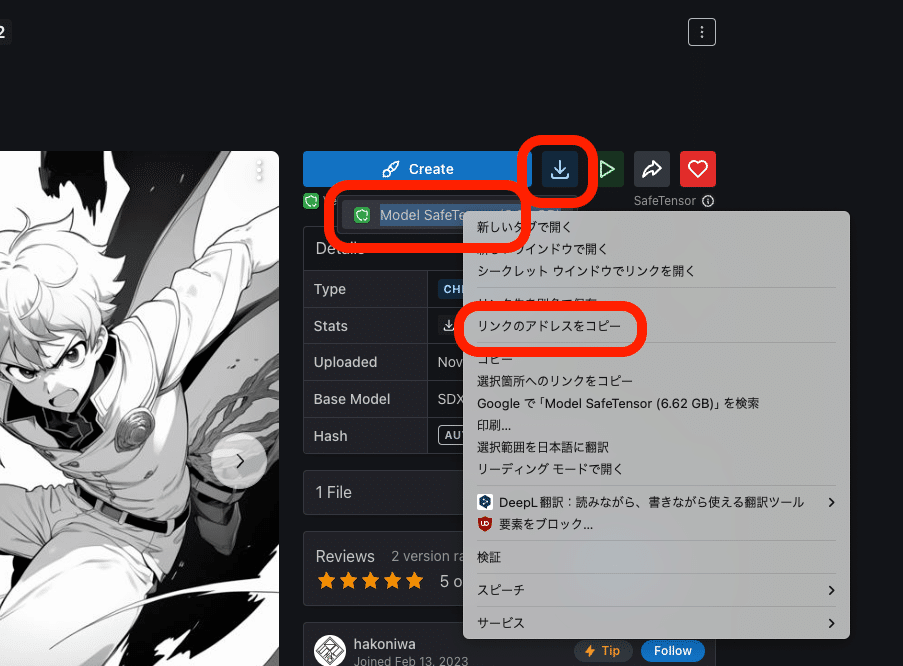
ダウンロードボタンをクリックし、表示された部分を右クリックし、「リンクのアドレスをコピー」をクリックしてください。
WebサイトのURLとは違うので、注意してください。
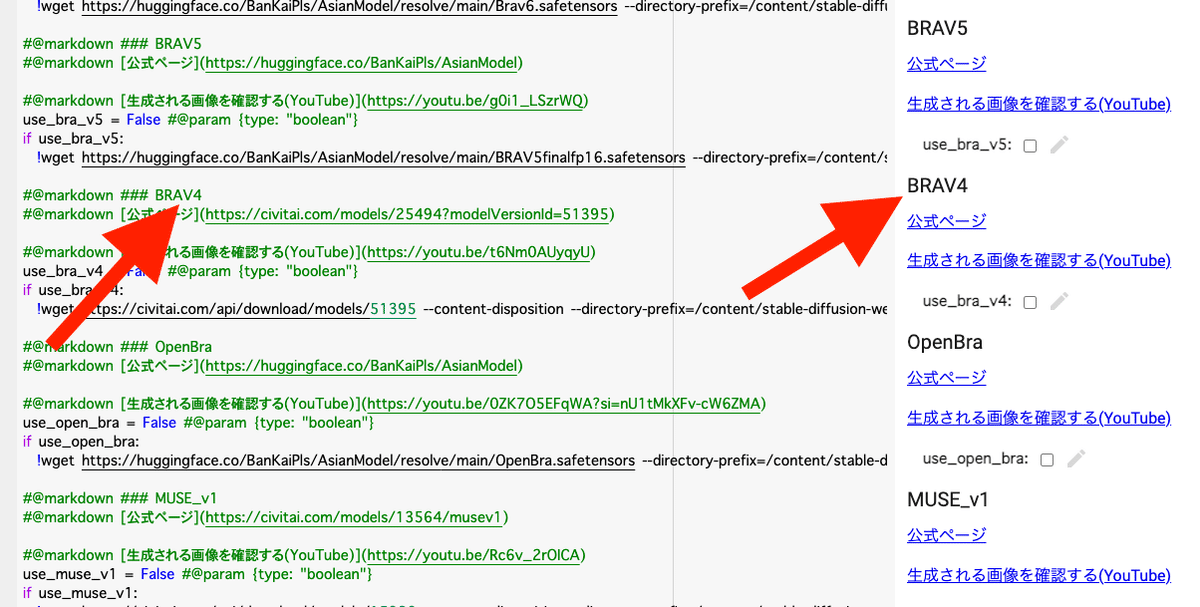
そして、使っていないモデルの部分を編集します。

先ほどコピーしたアドレスの数字の部分だけ、画像のように貼り付けてください。これで起動すると、モデルがインストールされます。
「###」の右にある名前を変えると、右側のモデル名も変わるので、わかりやすいです。
✓ hugging faceの場合
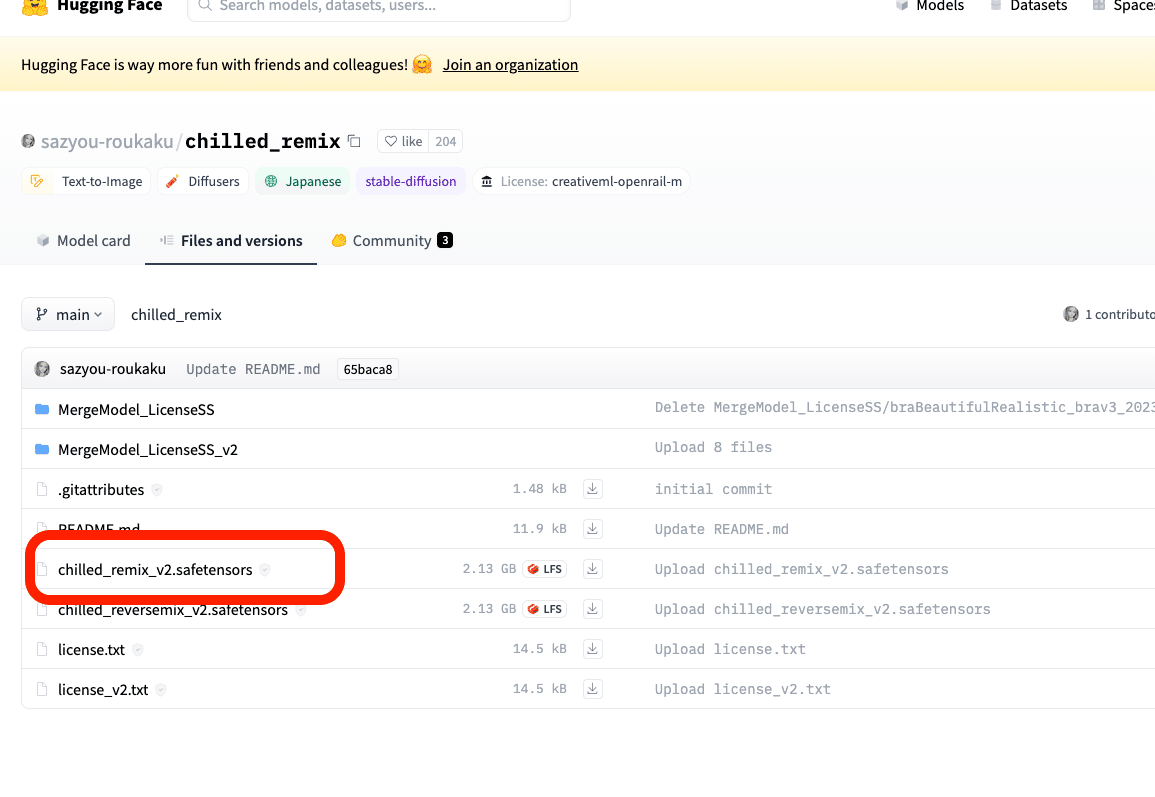
まず、モデルファイルをクリックし、
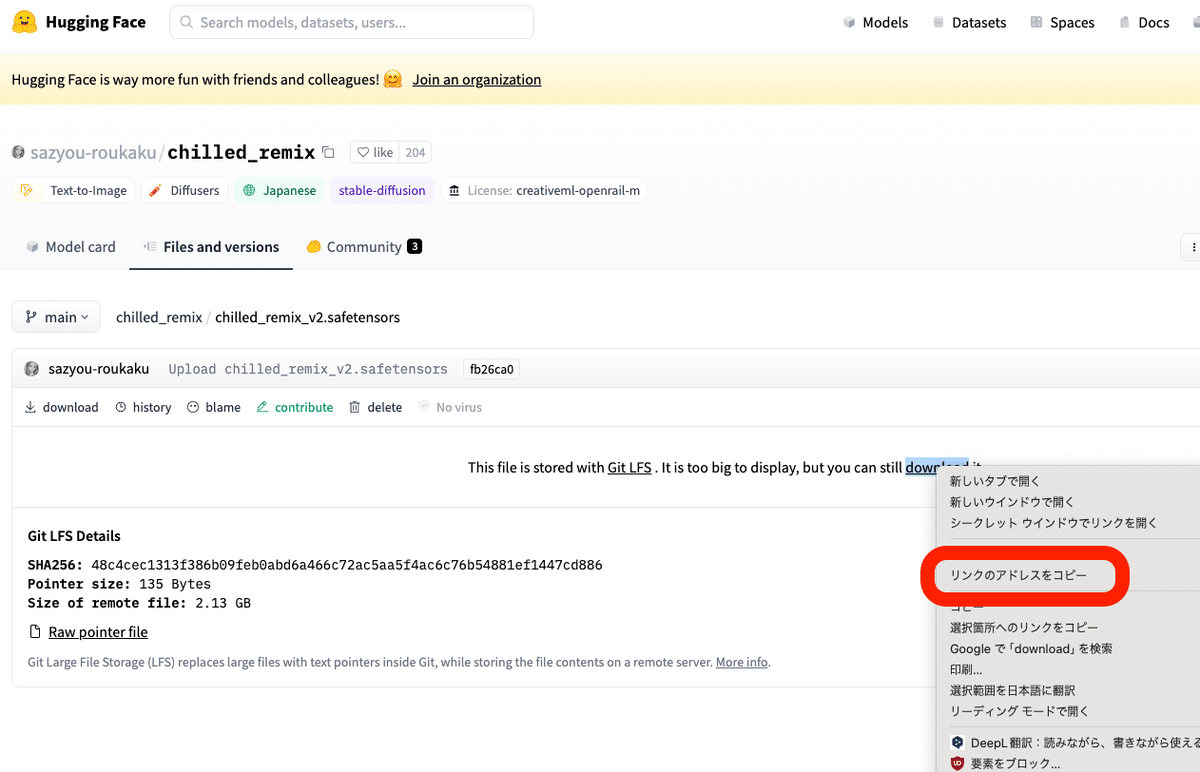
開いたページの「download」を右クリックし、リンクのアドレスをコピーしてください。
https://huggingface.co/sazyou-roukaku/chilled_remix/resolve/main/chilled_remix_v2.safetensorsこのようなアドレスです。


そして、赤線部分のアドレスを、自分でコピーしたものに変更します。あとは、起動するとモデルがインストールされます。
■ 無料&日本語サポートありの、生成AI GOで始める方法
生成AI GOは、Webブラウザ上で使えるStable Diffusionサービスです。この記事で紹介する4つの始め方のうち、最も簡単なのが生成AI GOです。
日本の企業が運営していて、日本語&数クリックで始めることができます。
生成AI GOは、クラウド環境版Stable Diffusionと似ていますが、始めるまでの面倒な設定は一通り済んでいる状態です。例えばGPUの設定は不要であり、主要なモデルや拡張機能も最初から搭載されているので、すぐにStable Diffusionを使えます。
Stable Diffusion WebUIが使われているので、操作方法は基本的に同じです。
□ 生成AI GOの特徴とメリット
・ローカル環境やクラウド環境よりも、設定が簡単
・サイトの説明が日本語
・日本語でお問い合わせ可能
・GPU、モデルや拡張機能の設定が済んでいて、すぐに開始可能
・無料のお試しもあり
・ポイント制なので、時間を気にせず使える
・SDXLに対応
・高性能なGPUが使われているので、生成がとても速い
□ 生成AI GOのデメリット
・Web版よりは、始め方や使い方が、少しだけ面倒
・ポイント制なので、たくさん生成しづらい
・拡張機能を自分で追加できない
・最新版の機能が搭載されるまで、タイムラグがある
□ 料金プラン

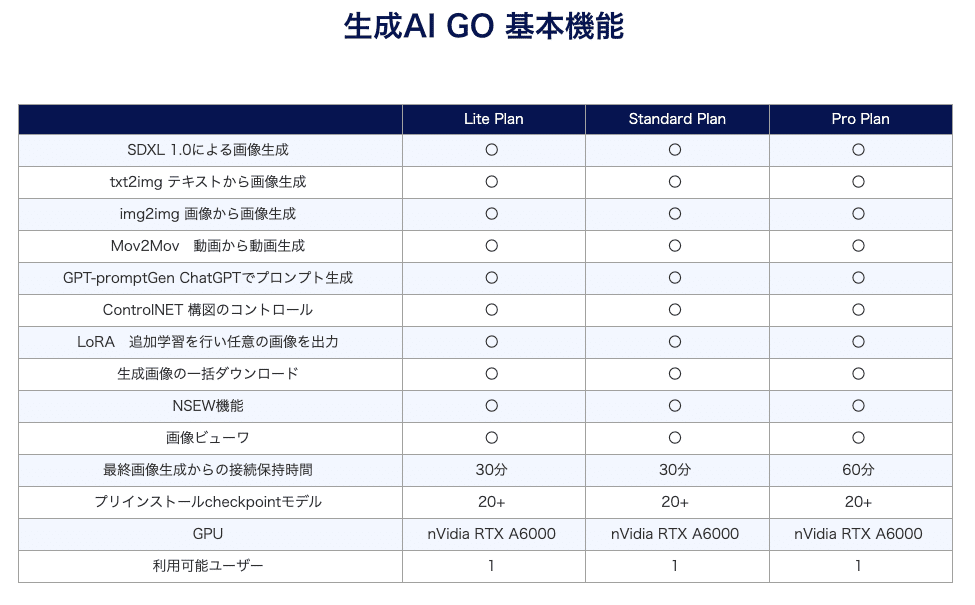
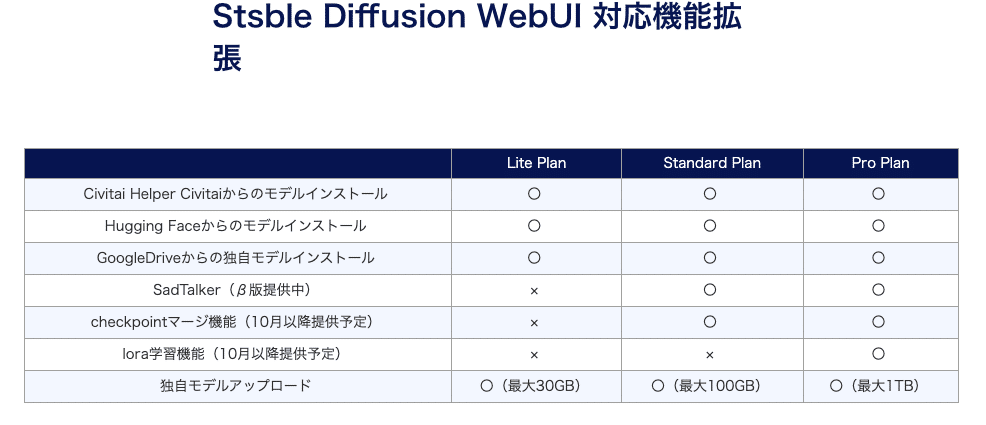
プランは上記のとおり。変わる可能性があるので、公式サイトを確認してください。
512×512サイズの画像1枚で1ポイントが消費されるので、ライトプランでは最大1000枚くらい生成できる計算です。
注意点として、消費されなかったポイントは、翌月に持ち越しはできません。
□ 生成AI GOの始め方
まずは生成AI GOのサイトに行き、「申込みはコチラ」をクリックしてください。
この画面になるので、プランを選びます。初めての方は、Lite Planで大丈夫です。
全てのプランで、無料体験できます。2週間後に自動で支払いが行われるので、無料体験だけ使いたい方は、無料期間中にキャンセルしてください。
キャンセルは、マイサブスクリプションからできます。購入していると、この画面になります。
「無料お試し期間を始める」をクリックすると、この画面になります。「新規登録」をクリックしてください。
ここで入力するメールアドレスとパスワードは、後で使うので忘れないようにしてください。
「公開プロフィールで〜」のところは、チェックしないと、なぜかログインできませんでした。現時点では、チェックしておいてください。
生成AI GOを使うには、「生成画面ログイン」をクリックします。登録に使ったメールアドレスとパスワードを入力してください。メアドは、@の後も必要です。
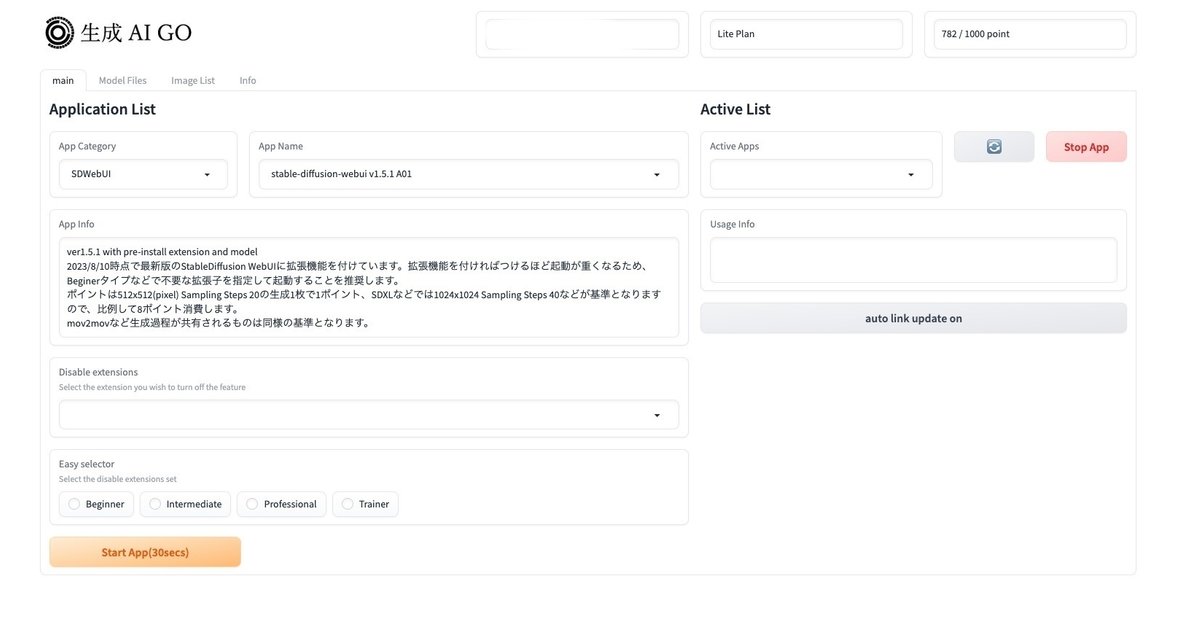
このような画面になります。
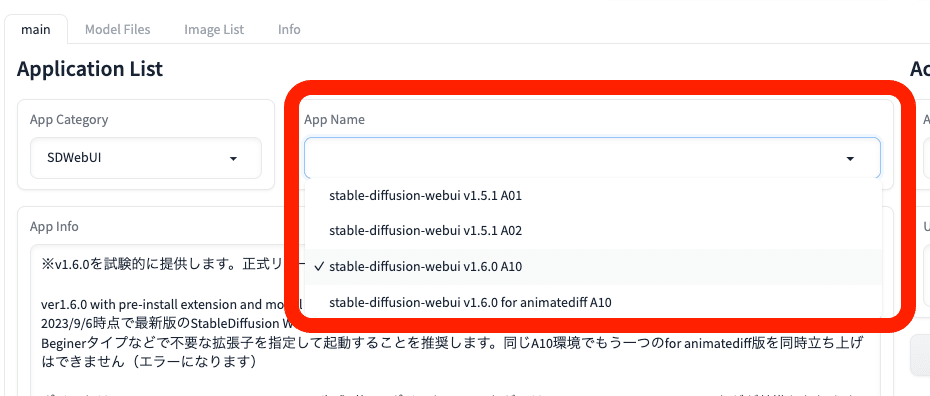
Stable Diffusionのバージョンは、SDXLを使うなら v1.6.0 以降を選んでください。私は現在、v1.6.0 A10を使っています。
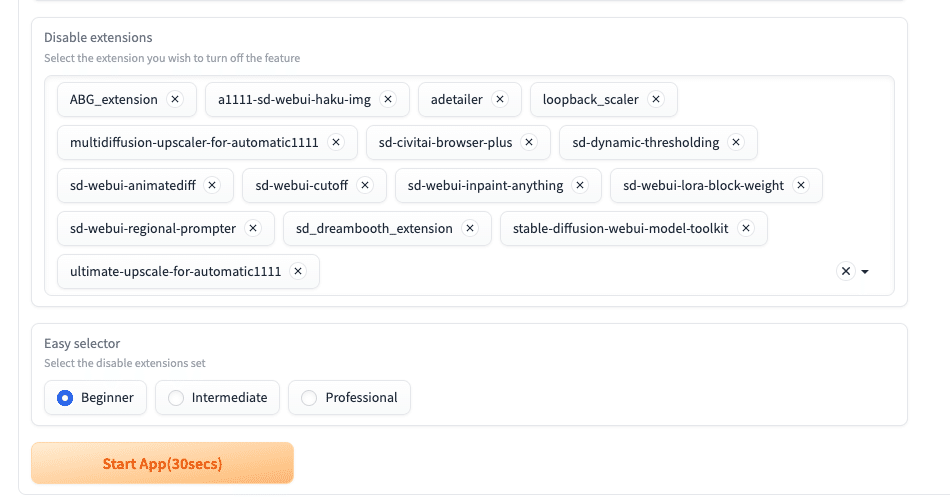
その下の、Disable extensionsでは、不要な拡張機能を削除できます。Easy selectorで、初心者向けやプロ向けごとに、拡張機能が停止されます。✗ボタンを押すと、停止をキャンセルできます。
ただし、初期設定のままでも起動は重くないので、必ずしも停止する必要はありません。そのままで大丈夫です。
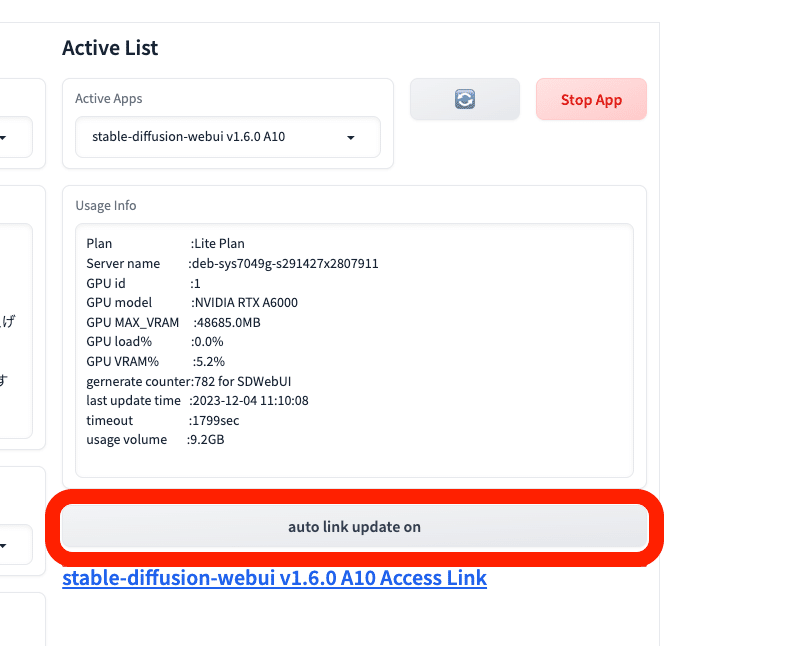
起動するには、「Start App」をクリックします。「auto link update on」もクリックしておいてください。自動でリンクが表示されるので、それをクリックしてください。
起動にかかる時間について、以下のとおりです。
・ローカル環境:数秒〜十数秒
・クラウド環境:数分〜十数分
・生成AI GO:30秒前後
これがStable Diffusionの画面です。
□ 生成AI GO画面の見方・使い方
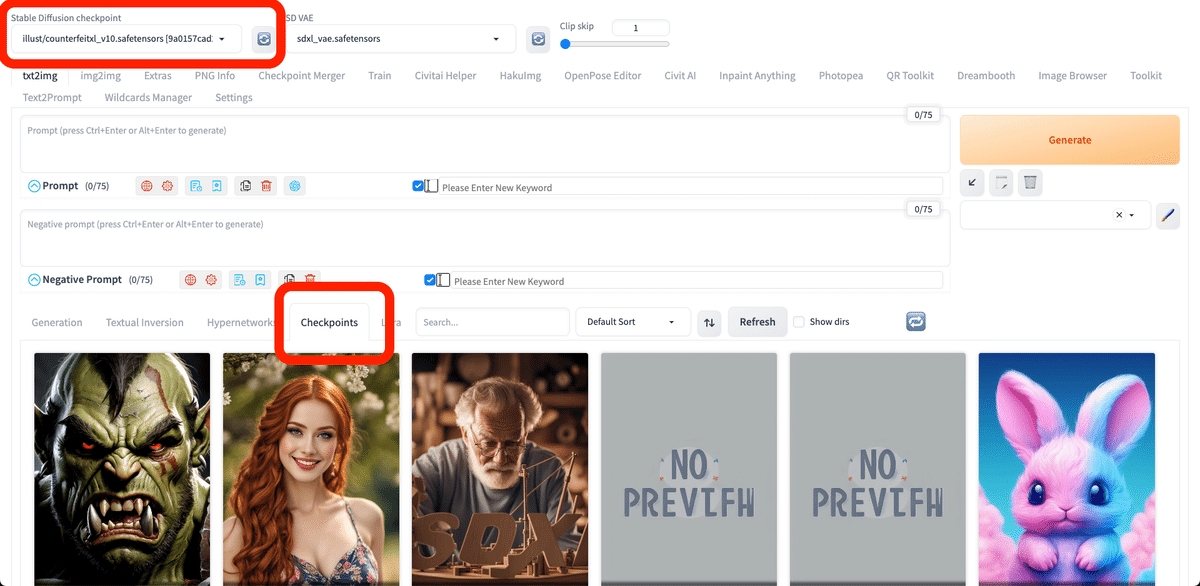
画像生成するには、まず画風を選びます。画風は、モデルを選ぶことによって変更可能です。モデルはチェックポイントと呼ばれることがありますが、同じ意味です。モデルとチェックポイントという言葉は、覚えてください。
真ん中あたりの「Checkpoints」でモデルを変更できます。「Stable Diffusion Checkpoint」でも、モデルを変更できます。
サムネイルに、表現できる画風が表示されています。サムネイル以外の画風も作ることはできますが、
・イラスト風の絵を作りたいなら、イラスト系のモデル
・リアル風の絵を作りたいなら、リアル系のモデル
を選ぶと、上手く行きやすいです。生成AI GOでは、イラスト系のモデルは、名前にanimeやillustが入っています。リアル系のモデルには、realisticと入っています。
このモデルは、ふつうは自分でインストールする必要があります。しかし生成AI GOでは、有名なモデルをあらかじめインストールしてくれています。
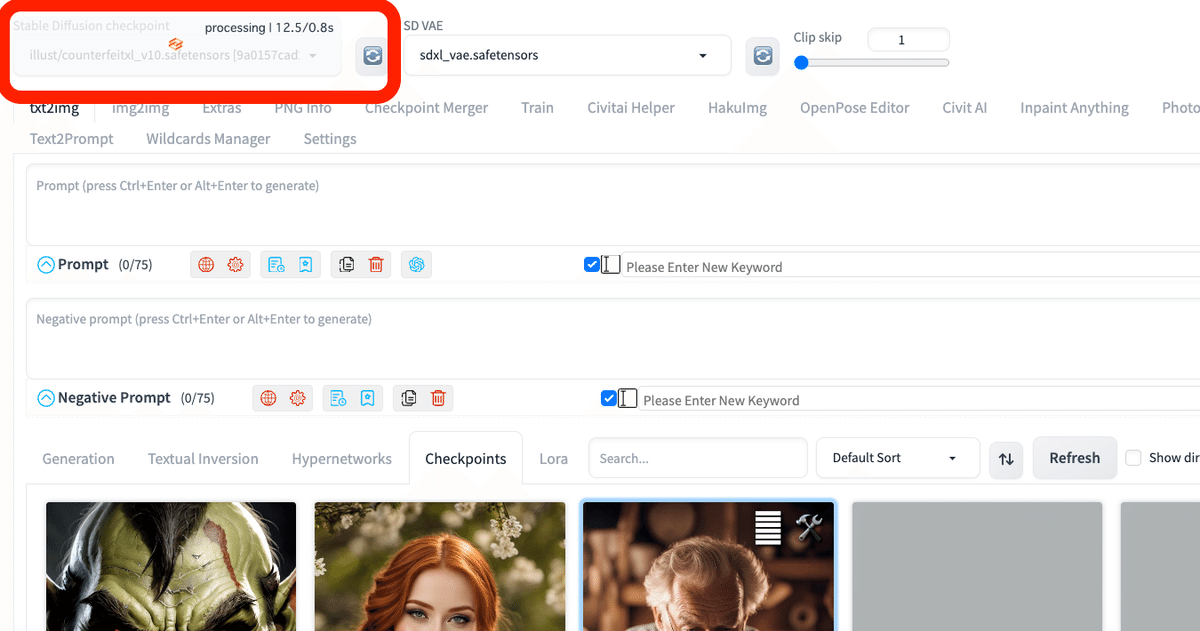
モデルを切り替えるたびに、読み込みに数十秒かかります。読み込み中は、他の操作はしないようにしてください。
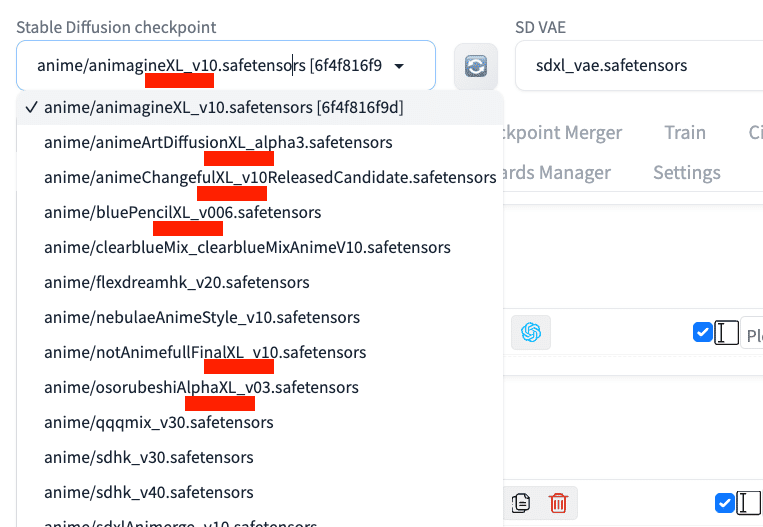
注意点として、XLという文字が入っているモデル(チェックポイント)は、最新版のStable Diffusion用のモデルです(SDXL)。画像サイズが1024×1024サイズあたりで生成するので、ポイントが多く消費されます。
XLという文字が入っていないモデルは、まだ現役のStable Diffusion1.5用のモデルです(SD1.5)。こちらは、画像サイズが512×512サイズあたりで生成するので、ポイントの消費は少なめです。
どちらを選んでも大丈夫です。簡単に高品質な画像を作りたいなら、SDXL用のモデルを選んでください。
次に、生成したい画像の説明文を入力します。
・上の段(プロンプト):生成したい画像の特徴
・下の段(ネガティブプロンプト):生成したくない画像の特徴
を入力してください。
入力するテキストは、英語で、カンマで区切って入力します。文章でも生成できますが、「可愛いネコを書いてください」のような命令文や会話文ではなく、「可愛いネコ」のように書いてください。
ちなみにChatGPTやBing AIに搭載されたDALL-E3では、命令文や会話文、日本語でも画像生成できます。ChatGPTの強みです。
以下は、プロンプトの例です。
・プロンプト:girl, face, smile, photo
・プロンプト:girl, ocean, standing, anime style
・ネガティブプロンプト:worst quality, bad quality, low quality, ugly, monochrome, dark
Width / Heightで、画像のサイズを設定できます。SDXL用のモデルを使う方は、1024あたりに設定してください。SD1.5用のモデルを使う方は、512あたりに設定してください。
・SD1.5は512*512サイズ
・SDXLは1024*1024サイズ
の画像で主に学習されたため、これらのサイズから離れるほど、絵の崩れが多くなります。オススメのサイズは、以下のとおりです。
✓ SD1.5
・正方形:512*512
・縦長(2:3):400*600
・横長(3:2):600*400
✓ SDXL
・正方形:1024*1024
・縦長(9:16):768*1344
・横長(16:9):1344*768
1500*1500サイズを超える画像になると、GPUにかかる負担が大きくなり、エラーが出やすくなります。
右側の「Generate」ボタンをクリックしてください。すると、画像が生成されます。
クリックするごとに、違う画像が生成されます。同じ画像や似た画像を生成する方法は、別の記事で解説します。
画像生成中に「Interrupt」をクリックすると、画像生成を途中でストップできて、途中結果のまま表示されます。

これが出て、画像生成ができなかった場合は、
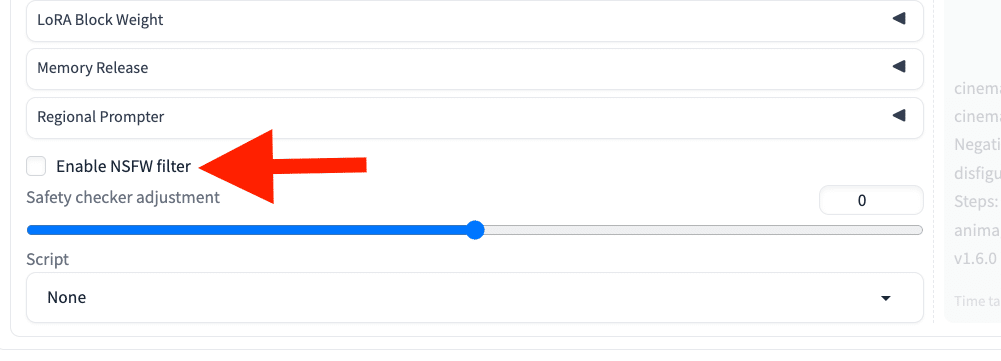
「Enable NSFW filter」のチェックを外してください。NSFW(not safe for work)は、主にアダルト画像のことです。
□ パラメータを初期設定に戻す方法
色々と設定を変えた後で、初期設定(デフォルト)に戻したい場合は、Webページを再読み込みしてください。
□ 画像の保存方法
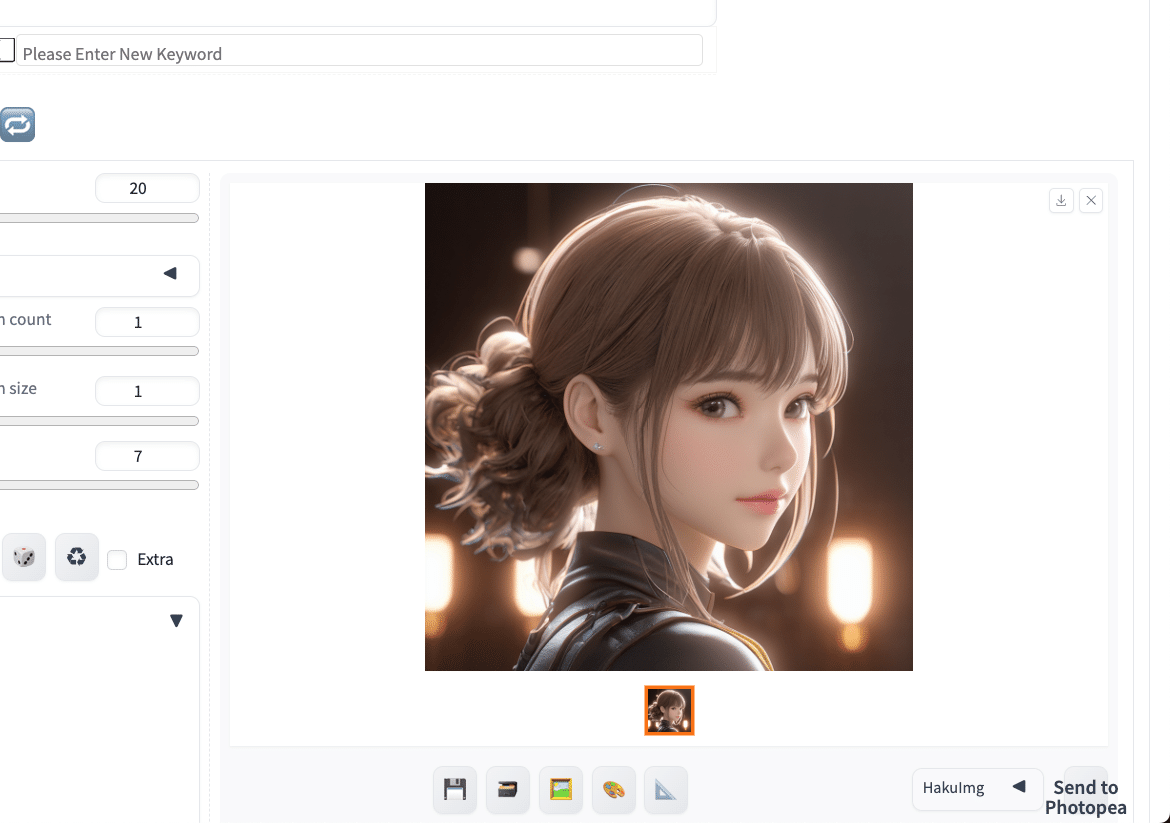
生成した画像を、右クリックで保存可能です。また、以下の方法もあります。
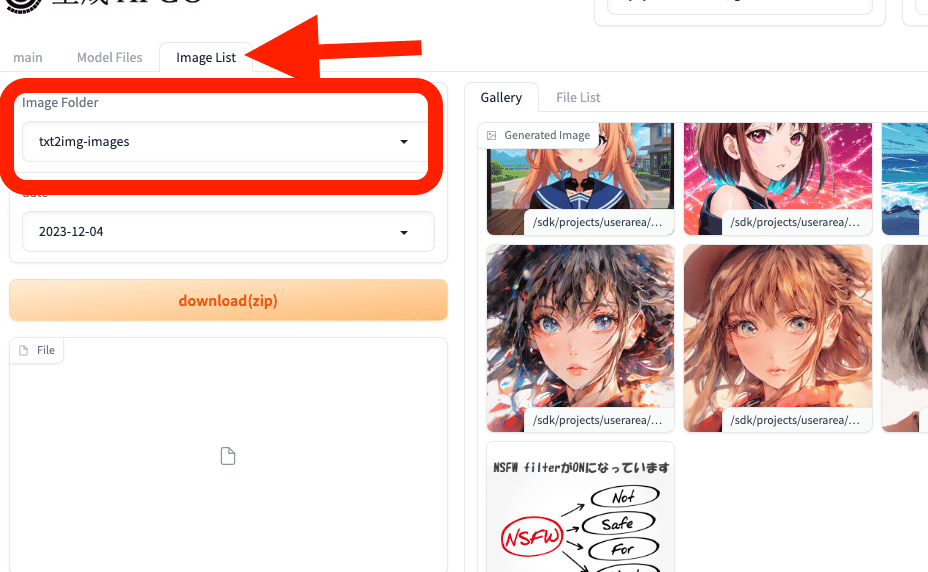
この画面に戻り、mainからImage List欄に移ります。Image Folderでtxt2img-imagesを選択すると、生成した画像が表示されます。
txt2img-imagesは、テキストから生成した画像を意味しています。画像から画像を生成した場合は、img2img-imagesを選択すると、画像が表示されます。
download(zip)から、まとめて保存できますし、画像を1つずつ右クリックで保存することもできます。
生成した画像は、このように自動保存されていきますが、契約を解除すると消去されるかもしれません。取っておきたい画像は、忘れずに保存してください。
□ 生成AI GOの終了方法
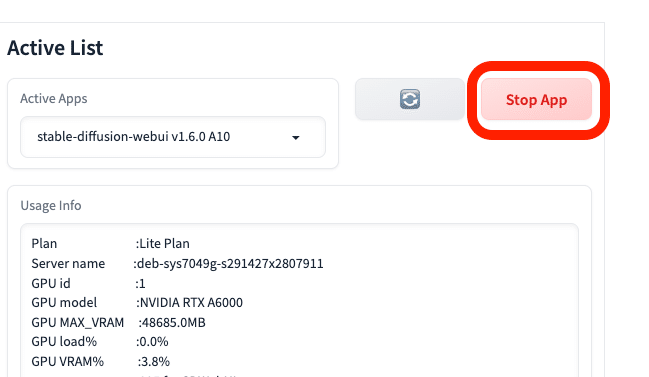
終了するには、Stop Appをクリックするだけです。
ただし放置していても、30分で接続解除されるみたいです。
□ 2回目以降の起動方法
2回目以降の起動は、まず公式サイトの「生成画面ログイン」をクリックします。
次に、この画面になるので、「Start App」と「auto link update on」をクリックしてください。しばらくすると、リンクが表示されるので、クリックするとStable Diffusionを開始できます。
終わったら、Stop Appをクリックすると終了できます。
□ 生成AI GOなら、画風や絵柄をワンクリックで変えられる
生成AI GOには、「SDXL Styles」という拡張機能が標準搭載されています。
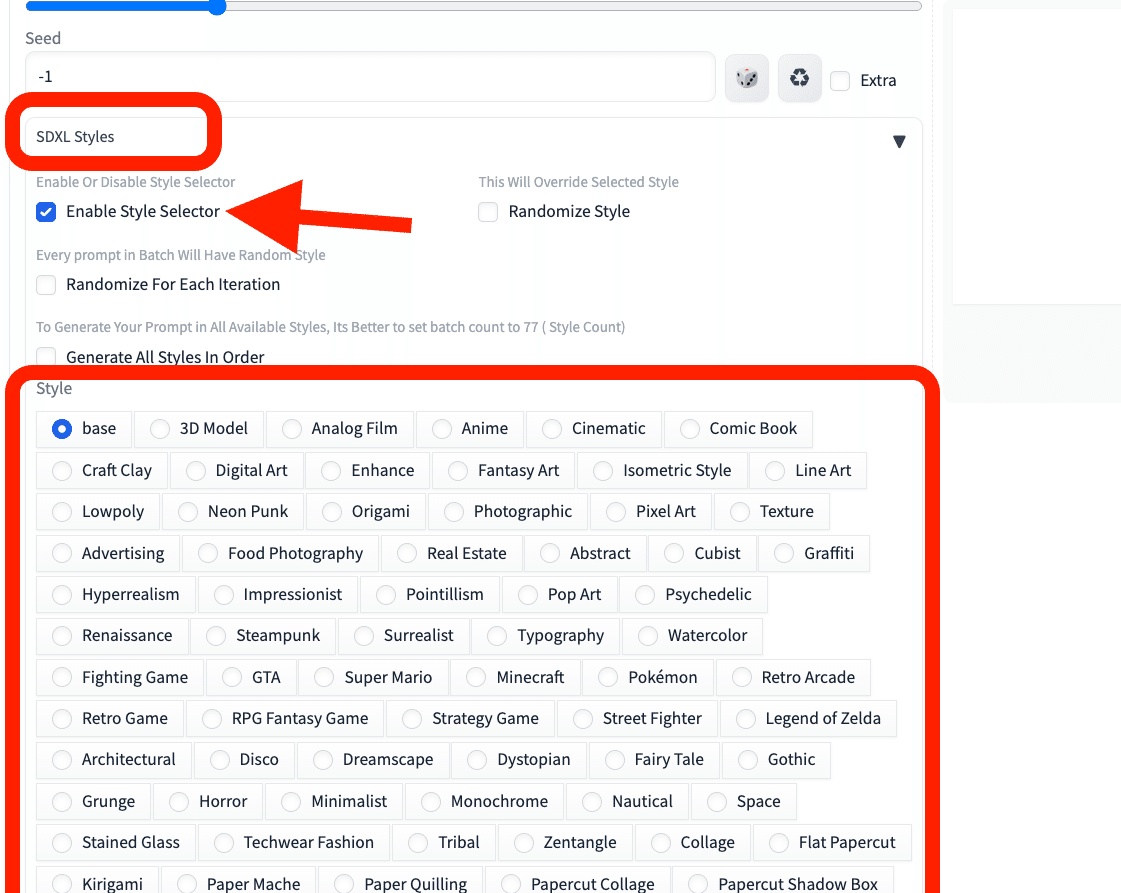
下のいずれかにチェックを入れると、プロンプトを入力しなくても、特定の画風/絵柄に簡単にしてくれます。
使っているモデルも影響するので、効果が薄いなと感じたら、モデルを変えてみてください。ちなみに、SD1.5のモデルでも、拡張機能の効果はありました。
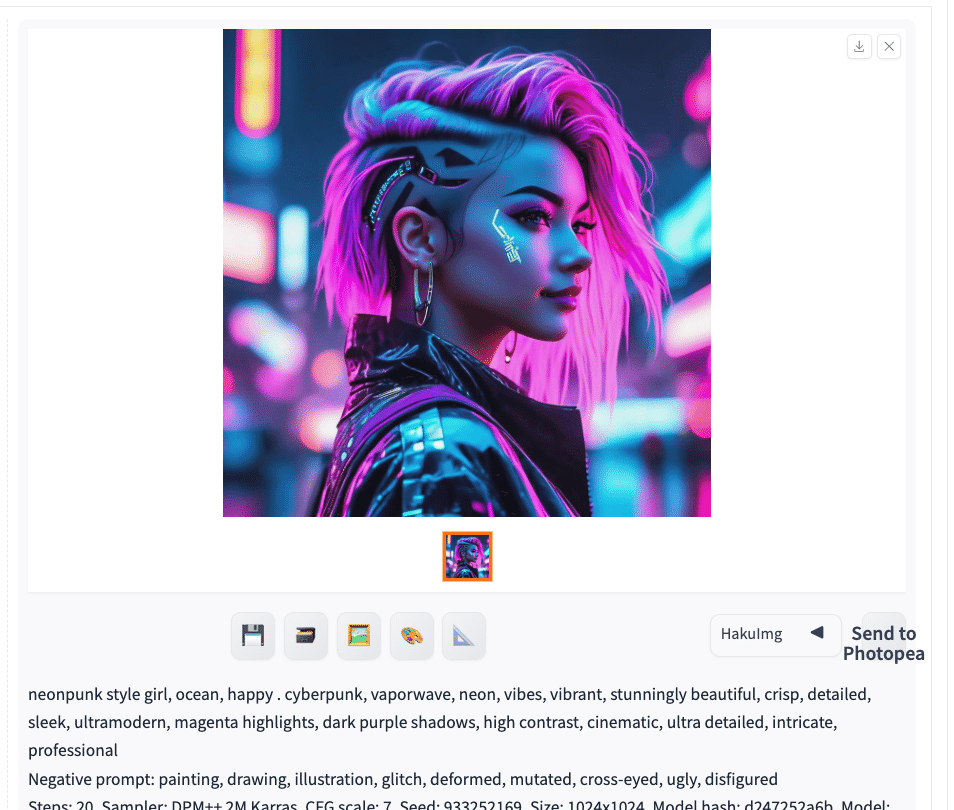
試しに、Neon Punkにチェックを入れて生成してみました。
私が入力したプロンプトは「girl, ocean, happy」だけです。しかし、生成結果を見ると、プロンプトやネガティブがたくさん追加されています。これが「SDXL Styles」の効果です。
プロンプトの参考にもなるので、試してみてください。
baseにチェックが入っていると、プロンプトが勝手に追加されることはありませんが、Enableのチェックを外すと拡張機能が無効になります。また、右上の▼マークで、開閉できます。
□ モデルの説明
画風や絵柄を変えるには、プロンプトを変えることでもできますが、モデルごとにも得意不得意があります。
モデルとは「学習済みのデータ」のことで、「チェックポイント」とも呼ばれています。
・写真のようなリアルな画像を生成したいときは、リアル用のモデル
・イラスト風の画像を生成したいときは、イラスト用のモデル
を使う方が、目的に近い画像を生成しやすいです。
生成AI GOに入っているモデルは、
・Checkpoints
・Stable Diffusion checkpoint
から確認可能です。
生成AI GOでは、何十個も最初からインストールされているので、自分で設定する必要はありません。ただし、モデルの新しいバージョンを使いたかったり、好きなモデルを使いたい方向けに、自分で設定する方法もあります。
モデルを入手できるサイトは、「Civitai」と「hugging face」が有名です。Civitaiは画像生成AIに特化していますが、hugging faceは画像生成AI以外にも自然言語処理や音声処理など、様々な学習済みのデータが共有されています。
hugging faceは、Civitaiのサイトと違い画像が少なく文字がメインで、上級者向けのサイトです。どちらの使い方も紹介しますが、Civitaiがオススメです。
□ Civitaiとは?
Civitaiは、Stable Diffusionのような画像生成AIサービスで使うモデルが共有されているサイトです。モデルはチェックポイントとも言います。
様々なモデルを閲覧したりダウンロード可能です。
サイトを見てもらえれば、どんな画像が生成できるか、だいたい分かると思います。モザイクがかかっているのは主にアダルト系のモデルです。ログインすると、すべて見れるようになります。
モザイクを解除するには、「18+」などの部分をクリックしたり、画面右上の目のマークから、モザイクの設定を変更してください。
□ Civitaiの使い方、インストール方法
試しに1つモデルをダウンロードしてみましょう。好みのモデルを選んでください。
左上の「Models」をクリックしてモデルだけを表示させます。チェックポイントと書かれているのが、モデルです。
・チェックポイント:SD1.5版のモデル
・チェックポイントXL:SDXL版のモデル
SD1.5とSDXLの比較は、後ほど解説します。簡単に説明すると以下のとおりです。
・SD1.5:有名で使用者が多い、まだ現役のモデル。拡張機能と相性が良い。
・SDXL:最新版のモデル。手軽に高品質な画像が作れる。高性能なPCが必要。
比較のために、両方インストールするのがオススメですが、消費ポイントを抑えたい方はSD1.5だけでも大丈夫です。
初期設定では、評価順に並んでいるので、上に位置するモデルが高評価されているモデルです。並びの設定は、上の画像のように変えることができます。
画面右上にある設定から、期間も指定可能です。
モデルは、気に入ったものをインストールしていただければ大丈夫です。
・最新版のSDXL
・最も普及しているSD1.5
の両方を使ってみたい方は、以下のように、同じ作者が作成したモデルを選ぶと、効率的に比較検証が行えます。
✓ リアル風のモデル
・XXMix_9realisticSDXL
・XXMix_9realistic
・nagatsuki_mix
・yayoi_mix
✓ イラスト風のモデル
・SakuraMix-XL./Anime-like
・SakuraMix
・CounterfeitXL
・Counterfeit-V3.0
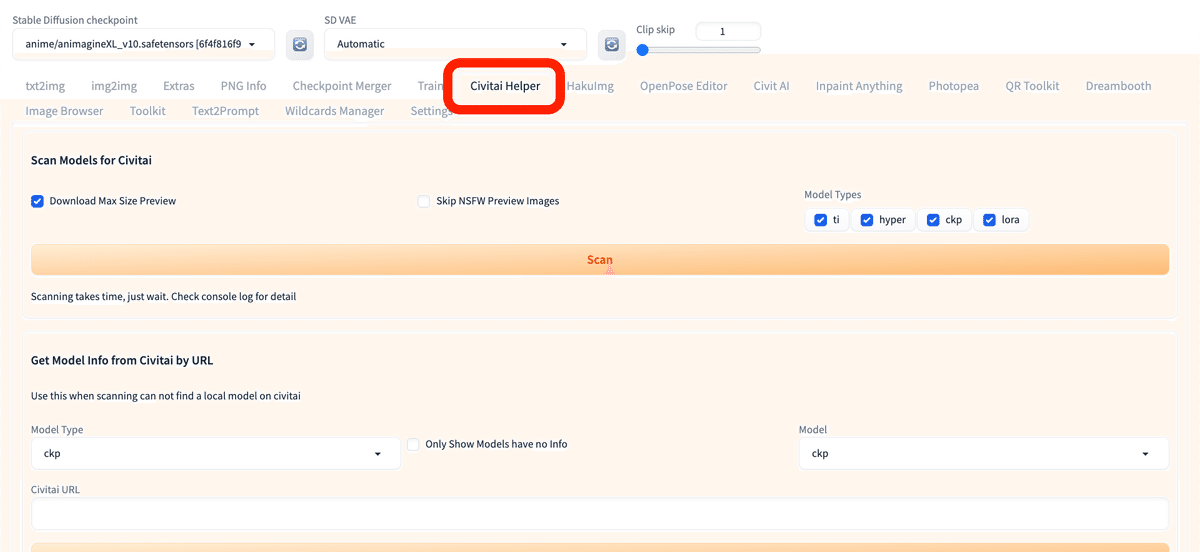
生成AI GOで、モデルをインストールするには、Stable Diffusion画面の「Civitai Helper」を開いてください。
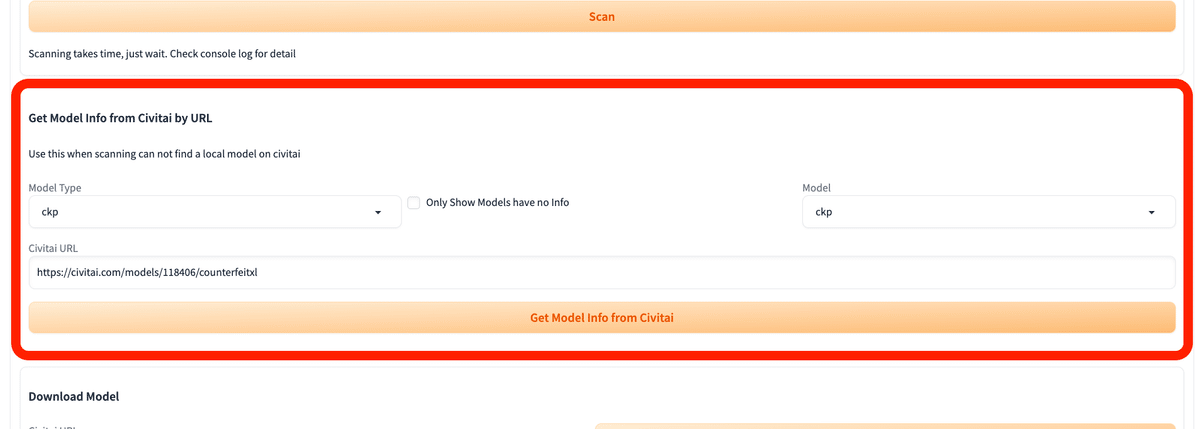
ここの、Download Modelを使います。
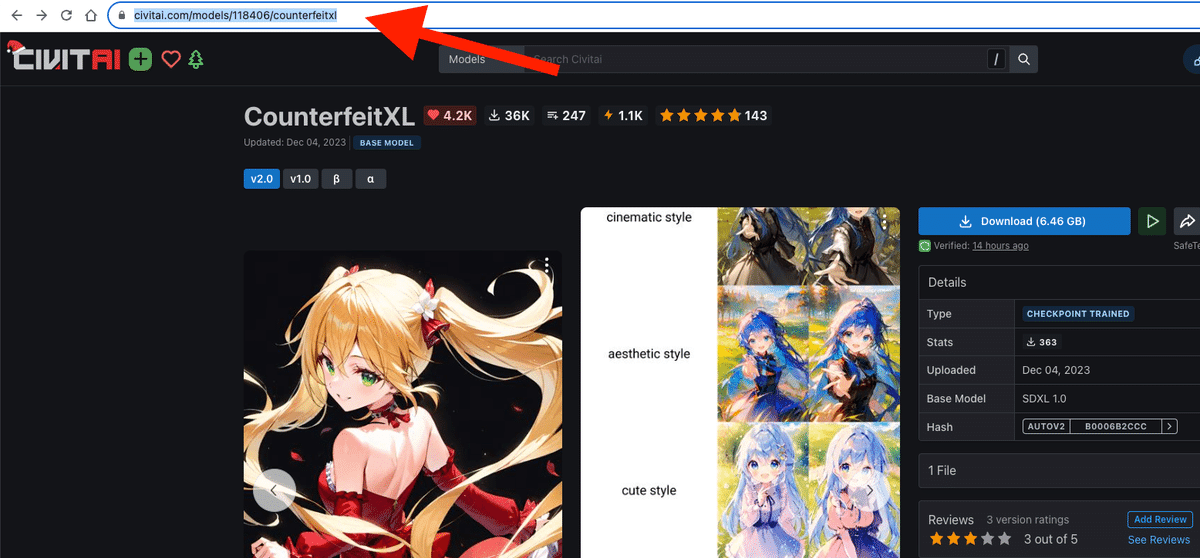
URLをコピーし、
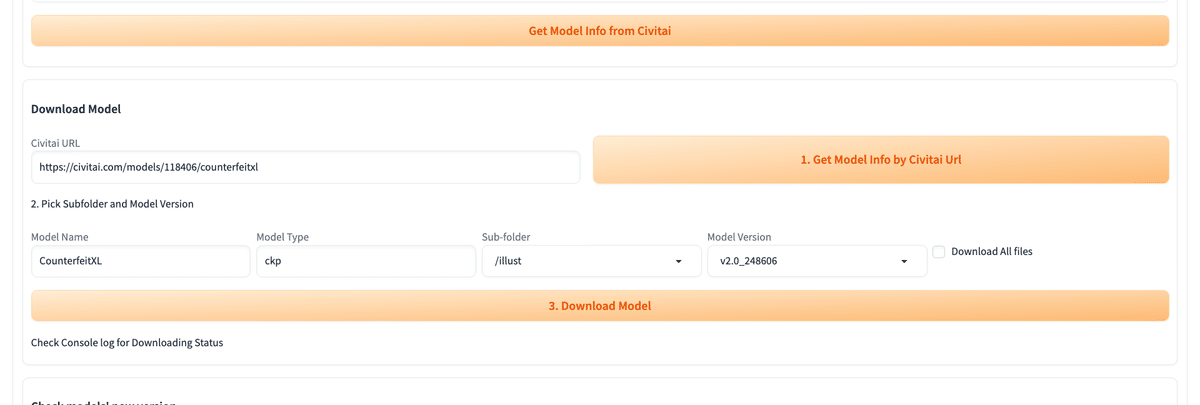
Civitai URLに貼り付けて、「1. Get Model Info by Civitai Url」をクリックしてください。
次に、「2. Pick Subfolder and Model Version」で、特にSub-folderを「/illust」などに設定します。リアル系のモデルをインストールするなら、「/realistic」などを選択してください。
最後に、「3. Download Model」をクリックし、数分待つと完了します。
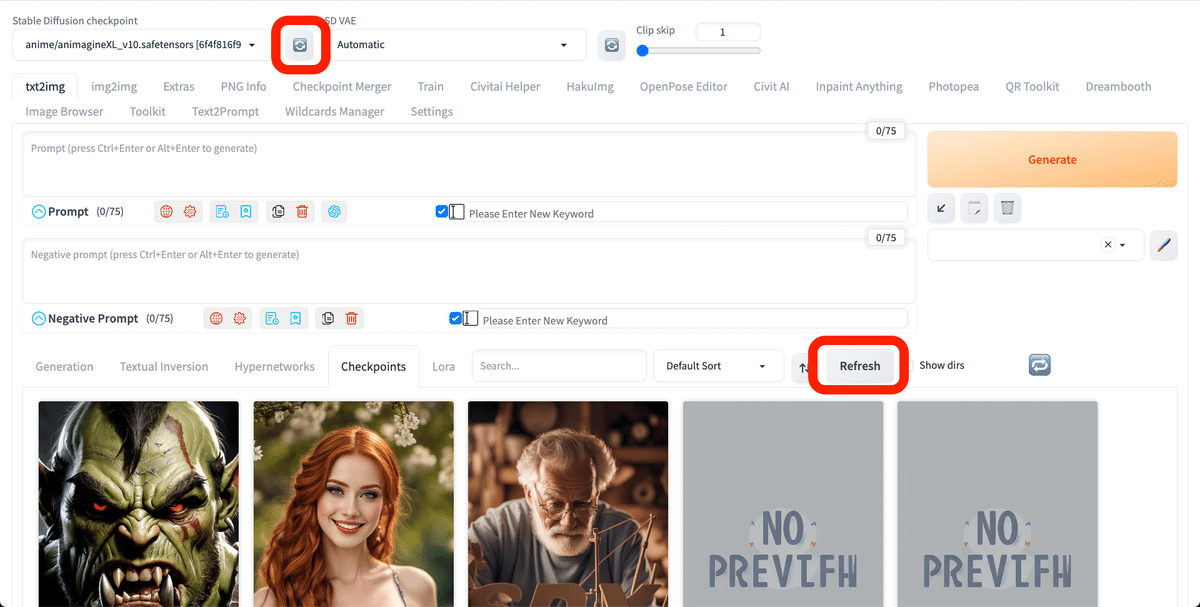
Stable Diffusionを再起動するか、リフレッシュボタンをクリックすると、モデルのインストールが完了します。
Lite Planでは、使える容量が30GBまでです。モデルは1つ数GBもあるので、追加できるのは4〜10個くらいです。
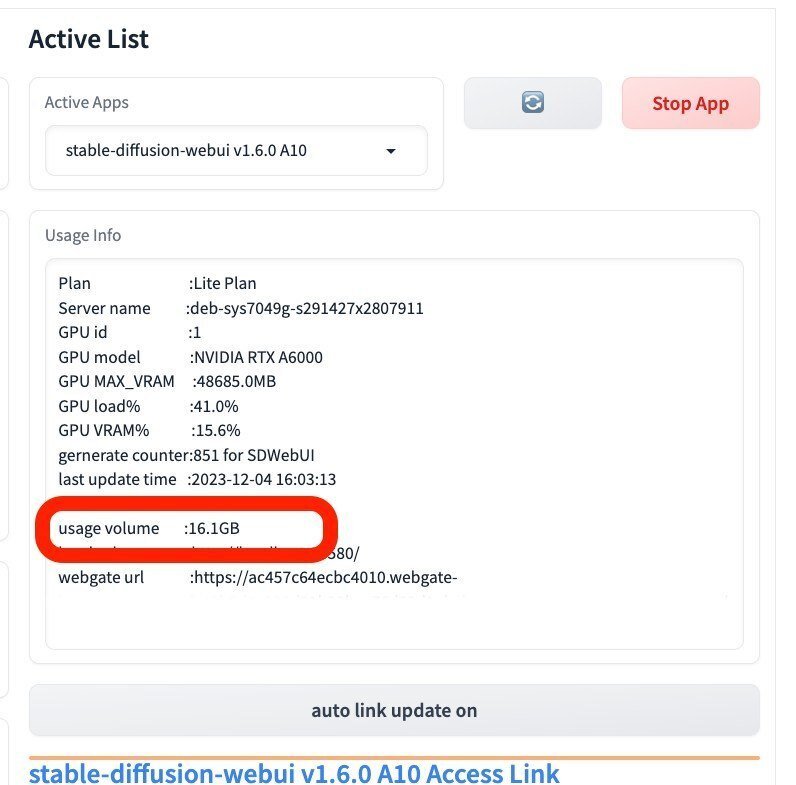
この画面から、自分が使っている容量を確認できます。
□ Hugging Faceからモデルをインストールする方法
次に、Hugging Faceからモデルをインストールする方法を解説します。Hugging Faceにしかないモデルをインストールしたいときに使います。必須ではないので、必要な方だけ読んでください。
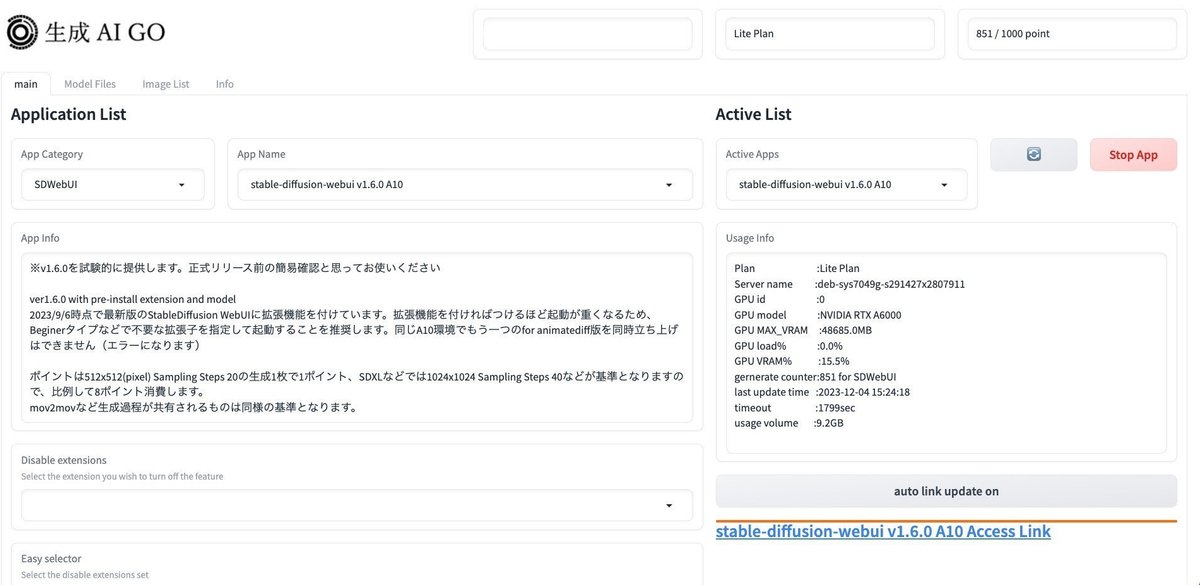
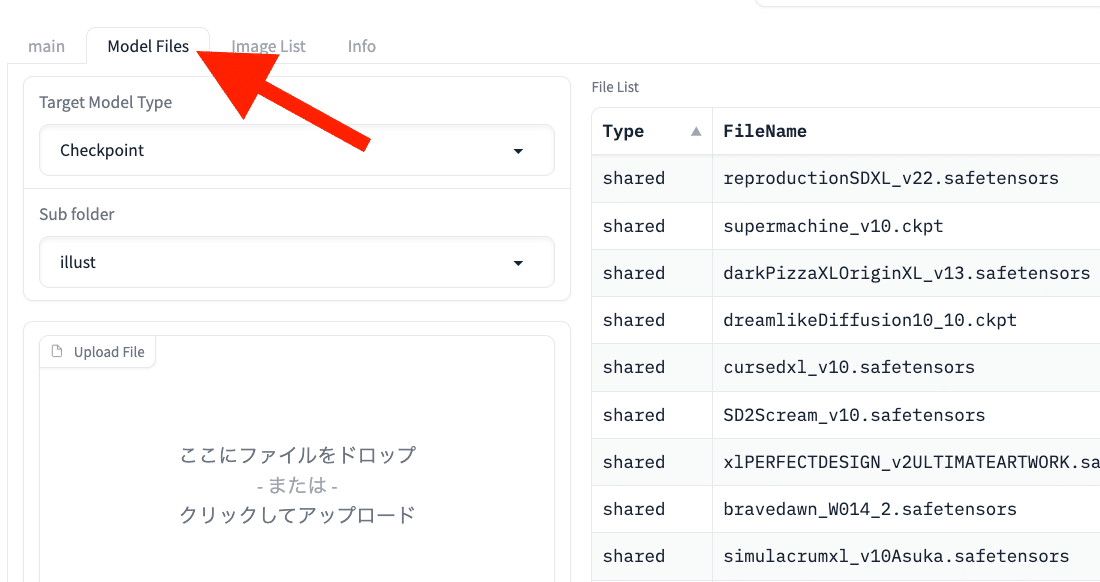
この画面の、Model Files欄を開いてください。
左側で、Target Model TypeをCheckpoint、Sub folderをillustにすると、イラスト系のモデル一覧が表示されます。
真ん中あたりで、Typeがsharedになっているものは、生成AI GOに標準搭載されているモデルです。これらは、削除できません。自分でインストールしたものは、privateと表示されます。これらは、削除可能です。
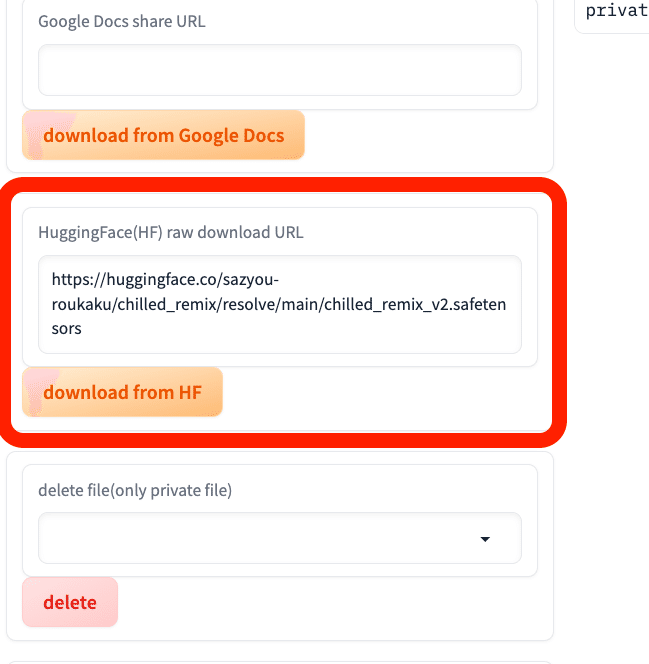
少し下に、Hugging Face用の欄があるので、そこにアドレスを貼り付けます。これは、サイトのURLではないので注意してください。
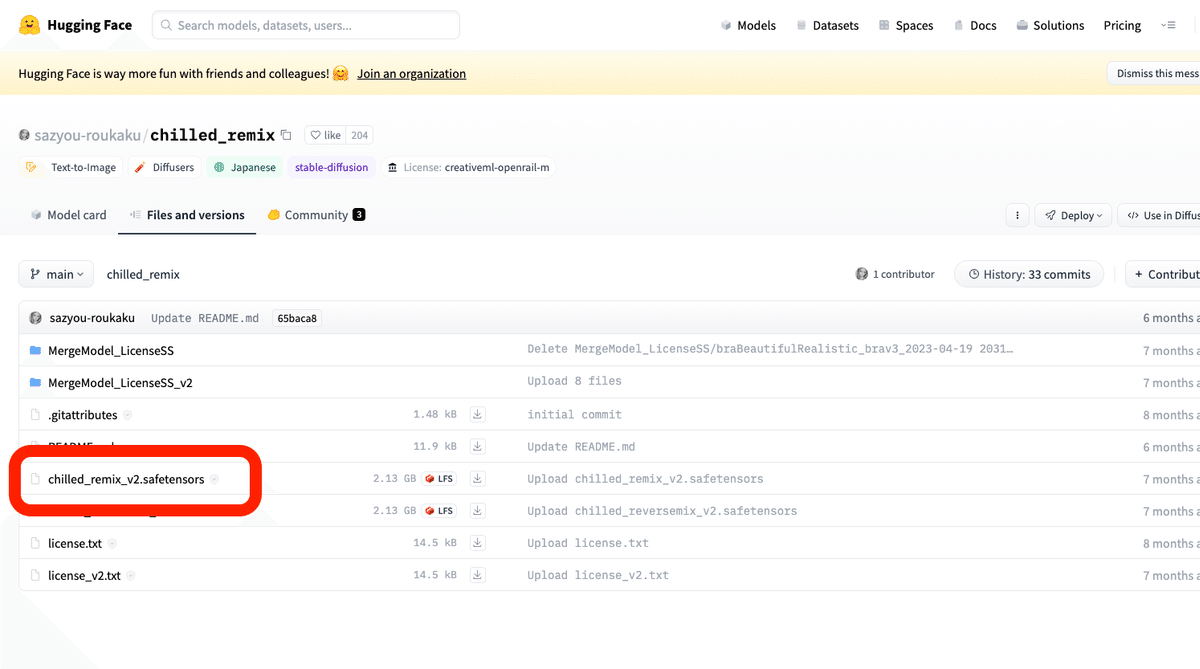
拡張子が「saffetensors」となっているのが、モデルです。まず、ファイル名をクリックします。
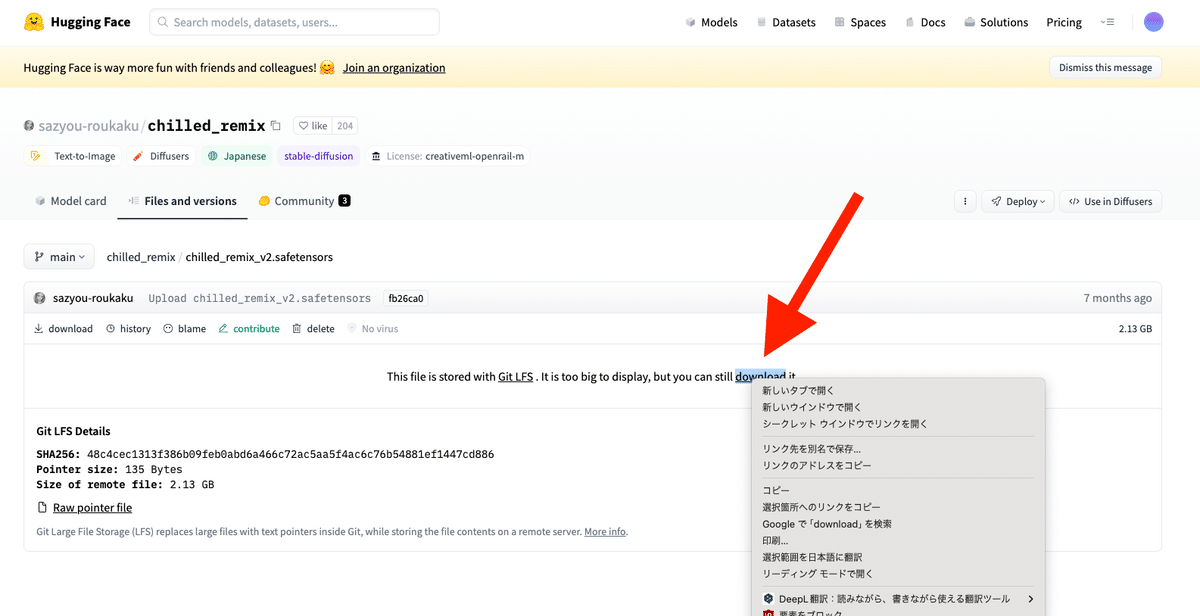
次に、ここのDownloadボタンを右クリックし、リンクのアドレスをコピーをクリックしてください。
ここに貼り付けて、downloadボタンを押すだけです。
□ 追加したモデルを削除する方法
削除は、「delete file」からできます。
■ SDXLとSD1.5 ■
■ SDXLって何?SD1.5との違い

Stable Diffusion XL(SDXL)というのは、Stable Diffusionの最新バージョンのことです。開発元であるStability AIという会社が、2023年の7月頃にSDXL1.0を公開しました。
Stable Diffusionの他のバージョンとしては、Stable Diffusion 1.5(SD1.5)がよく使われています。
Stable Diffusionはよく「SD」と略されるので、SDXLやSD1.5といったらStable Diffusionのことだと思ってください。
紛らわしいですが、「Stable Diffusion WebUI」のバージョンではなく、WebUIの中身のStable Diffusionのバージョンの事を言っています。
既にStable Diffusionを使ったことがある方は、自分がどっちのStable Diffusionを使っているか、分からない方もいるかもしれませんが、ほとんどの方はSD1.5を使っていると思って大丈夫です。
「Stable Diffusion WebUI」は、SDXLにもSD1.5にも対応しているので、実際は同じStable Diffusion画面で、どちらのバージョンも使えます。つまり、これから始めるStable Diffusionを使えば、特別なことは何もせずに
・有名な方のSD1.5
・最新の方のSDXL
を使うことができます。
□ SDXLの特徴

SDXLの特徴は、以下のとおりです。
・あらゆるジャンルにおいて高品質。特にリアル風の画像が得意
・1024×1024サイズが標準
・コントラスト、照明、陰影の表現が、前モデルより向上
・手や文字、空間の位置などの、改善
・少ないプロンプトで、高品質な画像の生成が可能
・プロンプトの汲み取り能力の向上
□ 公式モデルの比較と、注意点
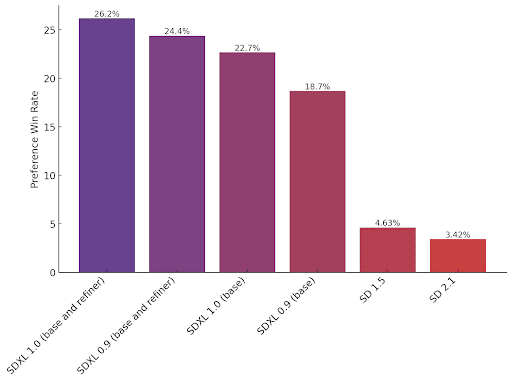
これは、Stability AIが公開している画像です。最新バージョンであるSDXLと、以前のバージョンのStable Diffusionで生成した画像の、どちらの画像が良かったかを調査した結果です。SD1.5よりも、はるかにSDXLが好まれているのが分かります。
ただしこれは、Stable Diffusionの公式モデルで比較した結果のはずです。
モデル(チェックポイント)と言われるものは、次の4種類に大別することができます。
SDXLの公式モデル(初期モデルとも言われている。基本的に1つ)
SD1.5の公式モデル(初期モデルとも言われている。基本的に1つ)
SDXLをベースにしたモデル(チェックポイントとも呼ばれている。無数にある)
SD1.5をベースにしたモデル(チェックポイントとも呼ばれている。無数にある)
私たちが普段よく見ていて使っているのは、4つのうちの後半2つです。それらのモデル(チェックポイント)は、公式モデルをベースに追加学習(fine-tuning)を行っていて、特定の絵柄に特化したモデルになっています。
オールラウンダーである公式モデルのみよりも、特化学習させたモデルの方が、望み通りの画像が出てくれてクオリティが高くなりやすいです。例えば、日本人に特化させて学習させたモデルの方が、人種まんべんなく学習させたモデルよりも、高品質に日本人を描いてくれます。
(基本的に、SD1.5系のチェックポイントよりも、最新のSDXL系のチェックポイントの方が、クオリティは高いです。しかし、チェックポイントごとにも絵柄の得意不得意があります。そのため、毎回必ずSDXL系の方がクオリティが高いわけではないので、注意してください。例えば、SD1.5系は、今まで使われてきて情報が豊富なので、高品質な画像を作るためのプロンプトが多く集まっているという利点があります。)
□ SDXLとSD1.5の比較
✓ SDXLのメリット
・手軽に高品質
・絵の崩れの減少
・画像のサイズが最初から大きい
・プロンプトのくみ取り能力の向上

SDXLでは、プロンプトの工夫を頑張らなくても、手軽に高品質な画像を生成できます。例えば、「最高傑作、最高品質、詳細」などの品質系のプロンプトは、ありなしで画像の品質はほとんど変わりません。基本的には、絵に描きたい内容だけ記述すれば、大丈夫です。Midjourneyもそうなので、Midjourneyのプロンプトの書き方に近くなりました。
また、絵の崩れがとても減りました。SD1.5では絵の崩れが多く、何回も画像生成を行う必要がありました。SDXLであっても手指などの崩れは、まだ多いですが、SD1.5より絵の完成度が上がっています。
また、主に1024×1024あたりのサイズでAIの学習がされたこともあり、最初からそのサイズ周辺で画像生成ができます。SD1.5では、主に512×512あたりのサイズでAIの学習がされているので、最初はそのサイズ周辺で画像生成をし、Hires.fixなどを使う必要がありました。Hires.fixでは元画像と絵が変わってしまうデメリットがあり、それを避けるにはControlNetなどの拡張機能を入れる必要があり、面倒でした。
加えて、プロンプトのくみ取り能力も向上しています。SDXLでは、SD1.5よりもさらに多くの学習がされたので、その分だけ生成できる物事が増えています。
✓ SDXLのデメリット
・生成に時間がかかる(要求されるPCスペックが上がった)
・ランダム性が減った
・絵が硬い気がする

画像サイズが大きくなったこともあり、生成に時間がかかるようになりました。
また、絵の表現幅が狭まった気がします。別で解説予定のControlNetやLoRAを使っているんじゃないかと思うくらい、似たキャラクターやポーズが出てきます。SD1.5は、暴れ馬みたいな感じで絵の崩れも多いですが、その分ランダム性はあります。
また、SDXLは絵が硬くなったと感じます。特に髪の毛が分かりやすくて、ふわふわ感が減った気がします。プロンプトを変えてもポーズや絵が中々変わらず、操作感も硬い印象です。
また、Stable Diffusion自体の欠点ではありますが、画像生成の能力、例えばプロンプトのくみ取り能力は、他の画像生成AIサービスと比べると少し低いです。例えば
・アイテム
・ポーズ
・色
など、なかなか思った通りには出てくれません。ちなみに最もプロンプト通りに画像生成できるのは、現状DALL-Eです。
サービスごとに、それぞれ得意不得意はあるので一概には言えませんが、DALL-EとMidjourneyでは、Stable Diffusionよりも手軽に高品質な画像を作れます。とはいえ、Stable Diffusionはオープンソースであり、拡張機能が豊富だったり、何でも生成できて自由だったり利点も大きいです。
✓ SD1.5のメリット
・生成が速い
・ランダム性がある
・情報が多い

SD1.5では、基本の画像サイズが512×512あたりなので、生成のスピードは速いです。ただし、Hires.fixなどで拡大するとなると、SDXLと生成時間はあまり変わらないです。
SD1.5では、SDXLよりもランダム性がある気がします。1.5では生成される画像が、暴れ馬みたいな感じで絵の崩れはありますが、その分いちおう色々なキャラが出てきます。
また、現時点では、SDXLよりもSD1.5の情報が多いです。SD1.5は1年以上使われてきて、今でもまだ現役だからです。チャックポイントやLoRAモデルも、SD1.5の方が多いと思います。
✓ SD1.5のデメリット
・絵の崩れが多い
・プロンプトの工夫が必要

SD1.5は、とにかく絵の崩れが多いです。そのため、何回も生成したり、修正したりすることになります。
また、SD1.5では、品質系のプロンプトはほぼ必須です。上手い人のプロンプトを参考にしたり、自分で何回も試す必要があり、初心者向きではないなと感じます。
□ どっちを使えばいい?
初心者には、SDXLがオススメです。手軽に高品質な画像を作れるのが、SDXLだからです。できれば、比較するために、両方インストールして使ってください。
SDXLは、SD1.5と比べると、プロンプトの工夫はそこまで必要なく、絵の崩れも少ないので、初心者にはSDXLが合っていると思います。
おそらく今後は、XLシリーズが標準になり、アップデートされていくはずなので、今から慣れておくのが得策です。
この記事が気に入ったらサポートをしてみませんか?