
【Python】指定したURLの見出しを抽出してテキスト出力するプログラムを作ってみた【スクレイピング】

サイトの見出し情報を取得したい!
Pythonなら簡単にできますよ(^^)
プログラミング副業挑戦中の そばごろう です。
twitter ☛https://twitter.com/sobagoro1
今回はChatGPTにPythonで指定したURLの見出しを抽出してテキストに出力するプログラムを書いてもらう手順をまとめます。
1.ChatGPTを起動
2.以下のプロンプトを入力
Pythonで以下のプログラムを書いて
1.ポップアップでURLを指定
2.指定したURLの見出し情報(h1~h6)を取得
3.取得した情報を指定してパスにtxtファイルで保存
※処理完了後に入力したURLはクリアして
※txtファイル名は「output_タイムスタンプ.txt」として
※最初のポップアップにスプレイピングについての注意書きを記載して
3.ChatGPTの返事を確認する
すぐに返答が表示されました。
何回かやり取りして使い勝手が良いプログラムに修正しました。
最終的なソース
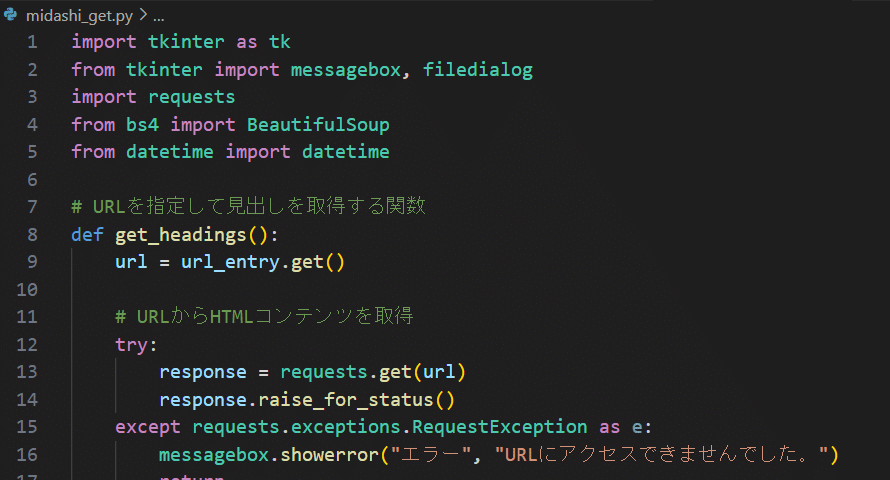
import tkinter as tk
from tkinter import messagebox, filedialog
import requests
from bs4 import BeautifulSoup
from datetime import datetime
# URLを指定して見出しを取得する関数
def get_headings():
url = url_entry.get()
# URLからHTMLコンテンツを取得
try:
response = requests.get(url)
response.raise_for_status()
except requests.exceptions.RequestException as e:
messagebox.showerror("エラー", "URLにアクセスできませんでした。")
return
soup = BeautifulSoup(response.text, 'html.parser')
# h1〜h6タグの見出しを取得
headings = [(heading.name, heading.text) for heading in soup.find_all(['h1', 'h2', 'h3', 'h4', 'h5', 'h6'])]
# タイムスタンプを取得
timestamp = datetime.now().strftime("%Y%m%d%H%M%S")
# ファイルの保存先をユーザーに選択させる
file_path = filedialog.asksaveasfilename(defaultextension=".txt", filetypes=[("テキストファイル", "*.txt")], initialfile=f"midashiList_{timestamp}")
if file_path:
with open(file_path, 'w', encoding='utf-8') as file:
for tag, text in headings:
file.write(f'[{tag}] {text}\n')
messagebox.showinfo("完了", "見出しをファイルに保存しました。")
# URL入力フィールドをクリア
url_entry.delete(0, tk.END)
# GUIを作成
app = tk.Tk()
app.title("Webページの見出し取得")
# 注意文言を表示するラベル
note_text = "注意: ウェブスクレイピングはウェブサイトの利用規約に従う必要があり、許可されている場合のみ行うべきです。\nまた、スクレイピングの頻度を過度に高く設定しないように注意してください。"
note_label = tk.Label(app, text=note_text)
note_label.pack()
url_label = tk.Label(app, text="URLを入力してください:")
url_label.pack()
url_entry = tk.Entry(app, width=50)
url_entry.pack()
get_button = tk.Button(app, text="見出しを取得", command=get_headings)
get_button.pack()
app.mainloop()
4.作成したプログラムの動作確認
作成したソースをVS Codeで動作確認します。
デバッグ実行ボタンを押すとフォルダ選択のポップアップが表示されました。
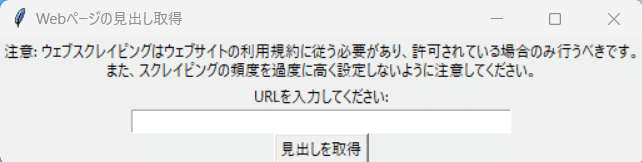
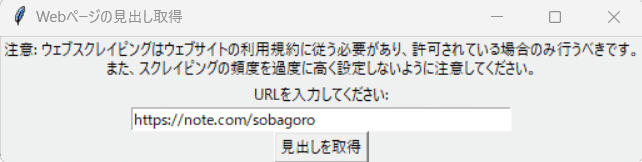
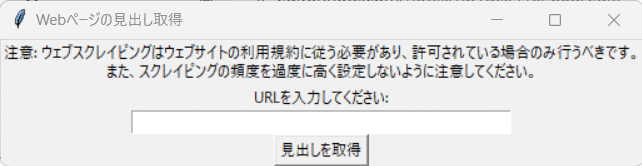
見出し情報を取得したいURLを入力します。
注意: ウェブスクレイピングはウェブサイトの利用規約に従う必要があり、許可されている場合のみ行うべきです。また、スクレイピングの頻度を過度に高く設定しないように注意してください。
noteの自分のクリエイターページを指定しました。
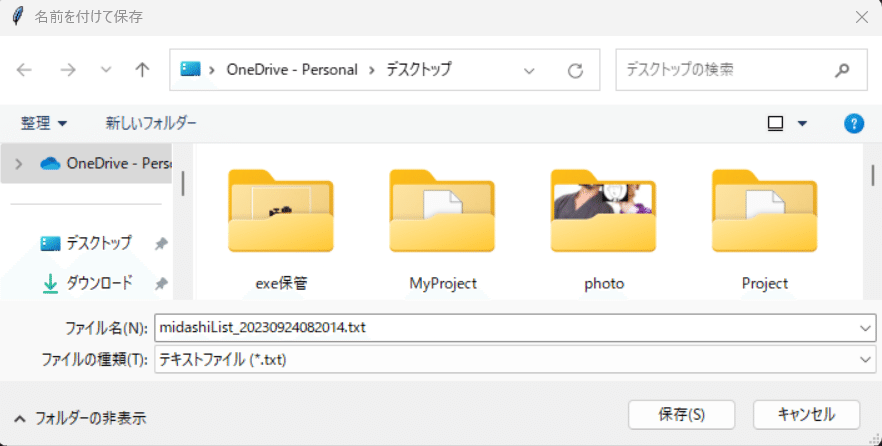
ポップアップから保管先をフォルダを指定します。
初期ファイル名は「midashiList_タイムスタンプ.txt」で設定されています。
「保存」を押すと、完了メッセージが表示されます。
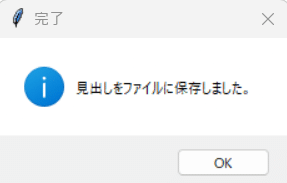
指定したパスにtxtファイルが保存されました。

中を開くと見出しの情報が保管されていました。

重複して出ている行があるので不要な場合はその分を削除する処理を追加するのも良いでしょう。
最初のポップアップのURLがクリアされました。
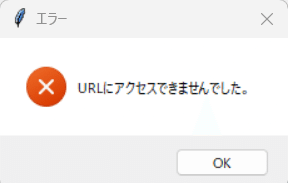
存在しないURLを入力するとエラーのポップアップが表示されました。
以上で動作確認は完了です。
5.作成したプログラムのexe化
以前解説した手順で作成したプログラムのexe化します。
今回は4つのライブラリをインストールしました。
pip install requests
pip install datetime
pip install beautifulsoup4
pip install pyinstaller
アイコンを指定してexe化するコマンドを実行
pyinstaller -F -w --icon=midashi.ico midashiGet.py
exeファイルができました(^^)/

exeを実行して動作確認できたら完了です。
6.今回できなかったこと
6-1.出力ファイルが文字化けすることがある
一部のサイトで出力した見出しが文字化けしている事がありました(大体のサイトは問題なく稼働)。
出力の前処理でエンコーディングなどを指定すれば回避できるかも知れませんが、今回は解決できませんでしたm(__)m
まとめ
ChatGPTにPythonで指定したURLの見出しを抽出してテキスト出力するプログラムを書いてもらう手順をまとめました。
同じように勉強中の方の参考になればうれしいです。
私のプロフィール↓
勉強メモ シリーズ↓
ChatGPTを使ったプログラミング↓
最後まで閲覧ありがとうございましたm(__)m