
【Python】csvファイルを比較して差分を抽出・保存するプログラムを作ってみた

csvを比較して差分を抽出したい!
Pythonなら簡単にできますよ(^^)
プログラミング副業挑戦中の そばごろう です。
twitter ☛https://twitter.com/sobagoro1
今回はChatGPTにPythonで2つのcsvファイルを比較して差分を抽出・保存するプログラムを書いてもらう手順をまとめます。
1.ChatGPTを起動
2.以下のプロンプトを入力
以下のプログラムをPythonで作成して
1.指定したフォルダのCSVファイルを確認する
2.更新日時が最も新しい2件を比較する
3.差分があればその部分だけ抜粋したcsvを保存する
※差分のcsvは最初に指定したパスに保管する
【実際の対話記録】
今回は「更新日時が最も新しい2件を比較」したかったのでそのように作成しました。
任意の2つのcsvファイルを比較したい場合はポップアップから指定する形に変更すれば良いと思います(ChatGPTに頼めば書き直してくれます)。
3.ChatGPTの返事を確認する
すぐに返答が表示されました。
何回かやり取りし、少し書き直して使い勝手が良いプログラムに修正しました。
最終的なソース
import os
import pandas as pd
import datetime
# 指定したフォルダのパス
folder_path = "比較したいパスを記述"
# フォルダ内のCSVファイルを取得
csv_files = [file for file in os.listdir(folder_path) if file.endswith(".csv")]
# ファイルを更新日時でソート
csv_files.sort(key=lambda x: os.path.getmtime(os.path.join(folder_path, x)), reverse=True)
# 更新日時が最も新しい2つのCSVファイルを選択
if len(csv_files) < 2:
print("フォルダ内に2つ以上のCSVファイルが必要です。")
else:
newest_file = csv_files[0]
second_newest_file = csv_files[1]
# CSVファイルを読み込み
try:
#2バイト文字を含まないCSVが対象
df_newest = pd.read_csv(os.path.join(folder_path, newest_file))
except UnicodeDecodeError:
#2バイト文字を含むCSVが対象
df_newest = pd.read_csv(os.path.join(folder_path, newest_file), encoding='shift-jis')
try:
#2バイト文字を含まないCSVが対象
df_second_newest = pd.read_csv(os.path.join(folder_path, second_newest_file))
except UnicodeDecodeError:
#2バイト文字を含むCSVが対象
df_second_newest = pd.read_csv(os.path.join(folder_path, second_newest_file), encoding='shift-jis')
# 差分を抽出
diff = pd.concat([df_newest, df_second_newest]).drop_duplicates(keep=False)
# 差分CSVファイルを指定したパスに保存
timestamp = datetime.datetime.now().strftime("%Y%m%d%H%M%S") # 現在の日時を取得
diff_path = folder_path + f"\差分ファイル_{timestamp}.csv"
if not diff.empty:
diff.to_csv(diff_path, index=False, encoding='shift-jis')
print(f"差分が見つかりました。差分ファイルを {diff_path} に保存しました。")
else:
print("差分は見つかりませんでした。")※「folder_path = "比較したいパスを記述"」の部分だけ修正すればお使いの環境で動作すると思います。
4.作成したプログラムの動作確認
作成したソースをVS Codeで動作確認します。
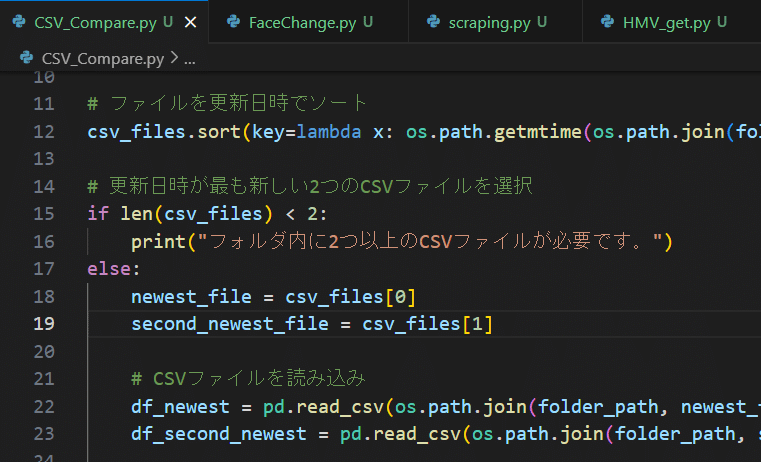
事前準備
比較対象のパスに以下3つのcsvを保管しました。
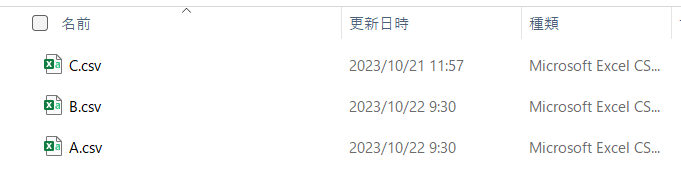
更新日時の新しい2つ(AとB)が比較され、Cは無視される予定です。
【Aの中身】

【Bの中身】

タイトルがDの行が差分として抽出される予定です。
動作確認の実施
デバッグ実行ボタンを押すと処理はエラーなく終了しました。
そして、指定したフォルダに差分ファイルが作成されました。

【差分ファイルの中身】

AとBが比較されて差分の行のみが出力されています。
以上で動作確認は完了です。
5.2バイト文字を含むCSVへの対応
2バイト文字を含むCSVを処理したところ「差分ファイルのcsvをexcelで開くと文字化けする(メモ帳で開くとしない)」という症状が出ました。
以下の記事を参考にエンコーディングにshift-jisを指定することで解消しました。
【koji/メガネ男の日誌様の記事を引用m(__)m】
具体的にはソースの以下の部分で対応しています。
# CSVファイルを読み込み
try:
#2バイト文字を含まないCSVが対象
df_newest = pd.read_csv(os.path.join(folder_path, newest_file))
except UnicodeDecodeError:
#2バイト文字を含むCSVが対象
df_newest = pd.read_csv(os.path.join(folder_path, newest_file), encoding='shift-jis')
try:
#2バイト文字を含まないCSVが対象
df_second_newest = pd.read_csv(os.path.join(folder_path, second_newest_file))
except UnicodeDecodeError:
#2バイト文字を含むCSVが対象
df_second_newest = pd.read_csv(os.path.join(folder_path, second_newest_file), encoding='shift-jis')
まとめ
ChatGPTにcsvファイルを比較して差分を抽出・保存するプログラムを書いてもらう手順をまとめました。
同じように勉強中の方の参考になればうれしいです。
私のプロフィール↓
勉強メモ シリーズ↓
ChatGPTを使ったプログラミング↓
最後まで閲覧ありがとうございましたm(__)m