
カスタム生データ取得ツールからのXMLファイル取得を自動化 #Python3

多くのアフィリエイトサイトでは API が導入され, 最新データの取得や検索といった操作を自動化できる仕組みが提供されています.
しかし, DTI アフィリエイト では作品情報を取得する API が提供されていないため, 日々更新され続ける膨大な作品データを自サイトに反映させるためには, DTI が提供している "カスタム生データ取得ツール" から手動で最新データをダウンロードする必要があります.
そこで今回は, この面倒な作業を Python3 を使って自動化する手順をまとめてみます. 今回作成するプログラムは, ほぼコピー&ペーストで使用できますので, プログラミング初心者の方も安心して読み進めてください.
1. はじめに
この記事は macOS での手順を紹介していますが, Windows でも大きな違いはないと思います.
※ 注記 ※
この記事は, 2018年12月時点での "カスタム生データ取得ツール" の仕様に基づいています.
"カスタム生データ取得ツール" に仕様変更があった場合, 掲載しているプログラムの修正が必要になる場合があります.
この記事は自動化ツールの作成方法を学ぶためのものであり, 自動化ツールの動作を保証するものではありません.
1.1. この記事を読むと出来るようになる事
DTI アフィリエイトの "カスタム生データ取得ツール" (要ログイン) から, XML 形式の作品データをコマンド一つでダウンロードすることが出来るようになります.
1.2. 環境概要
執筆時点での環境は以下の通りです.
インストールが必要なものについては, 順次説明していきます.
・OS
macOS Mojave Ver. 10.14.2
・開発環境
IDE : PyCharmCE Ver. 2018.3.1
Python Ver. 3.7.1 + selenium Ver. 3.141.0
ChromeDriver Ver. 2.45
・ブラウザ
Google Chrome Ver. 71.0.3578.98
1.3. 前提条件
DTI アフィリエイトの面倒な作業を自動化するのが今回の目的ですので, DTI アフィリエイトに登録していることが前提になります.
登録 (無料) は こちら から.
※ 注記 ※
DTI アフィリエイトを推奨する記事ではありませんので, アフィリエイトに興味のない方は, そっとブラウザを閉じてください.
アフィリエイト登録が済んだら, ログイン情報 (ID とパスワード) をメモしておきましょう.
2. 環境準備
まずは必要な環境を整えていきましょう. スクリーンショット付きで丁寧に説明していきますので, プログラミング初心者の方でも難しく考えずに進めてください.
2.1. Python3 のインストール
macOS には初めから Python がインストールされています. ただ, インストールされている Python は 2.x系 という一世代前のものなので, まずは最新の 3.x系 をインストールします.
Python3 のインストール方法は, 下記の記事を参照してください.

2.2. PyCharmCE のインストール
PyCharmCE とは
JetBrains社 が提供している Python に特化した統合開発環境 (PyCharm) のオープンソース版 (Community Edition) です.
誰でも無料で使用することができます.
今回の記事では, この PyCharmCE を使ってコーディングとプログラムの実行を行います.
PyCharmCE のインストール方法は, 下記の記事を参照してください.

2.3. ChromeDriver の入手
ChromeDriver とは
Chrome ブラウザをプログラムから制御するために必要なドライバソフトウェアです.
ChromeDriver は下記サイトからダウンロードできます. 特にインストール作業などは必要ありません.
ただし, お使いの Chrome ブラウザのバージョンに対応した ChromeDriver をダウンロードする必要がありますので, その点だけ注意しましょう.
http://chromedriver.chromium.org/downloads
ダウンロードした zip ファイルを解凍し, 生成された [chromedriver] ファイルを適当なディレクトリに保存してくだい.
この記事では, ChromeDriver を以下のディレクトリに配置したものとして説明します. [XXXX] は macOS のユーザー名に読み替えてください.
ディレクトリ : /Users/XXXX/BrowserDriver/
ファイル名 : chromedriver
3. 使用する外部パッケージ
今回は Python3 に予め用意されている組み込みパッケージ以外に, selenium (セレニウム) という外部パッケージを使用します.
selenium とは
WEB アプリケーションの動作テストを自動化するために開発された, オープンソースの "ブラウザ操作自動化ツール" です.
今回は Python 用のパッケージを使用しますが, PHP や Java など, 各種言語用のパッケージが用意されています.
4. 自動化ツールの作成
4.1. ツール構成
作成が必要なファイルは 2 つだけです.
ブラケット "[]" は PyCharmCE のプロジェクト用ディレクトリです.
[ AffiliateDti ]
├ config.ini
└ dti_xml.py
4.2. 新規プロジェクトの作成
PyCharmCE を起動し, [+ Create New Project] をクリックします.

[Location] 欄に [/Users/XXXX/PyCharmProjects/AffiliateDti] を入力し, 続けて [Create] ボタンをクリックします.
[XXXX] 部分は macOS のユーザー名に置き換えてください.

新規プロジェクトの作成が完了すると, 下記の画面が表示されます.

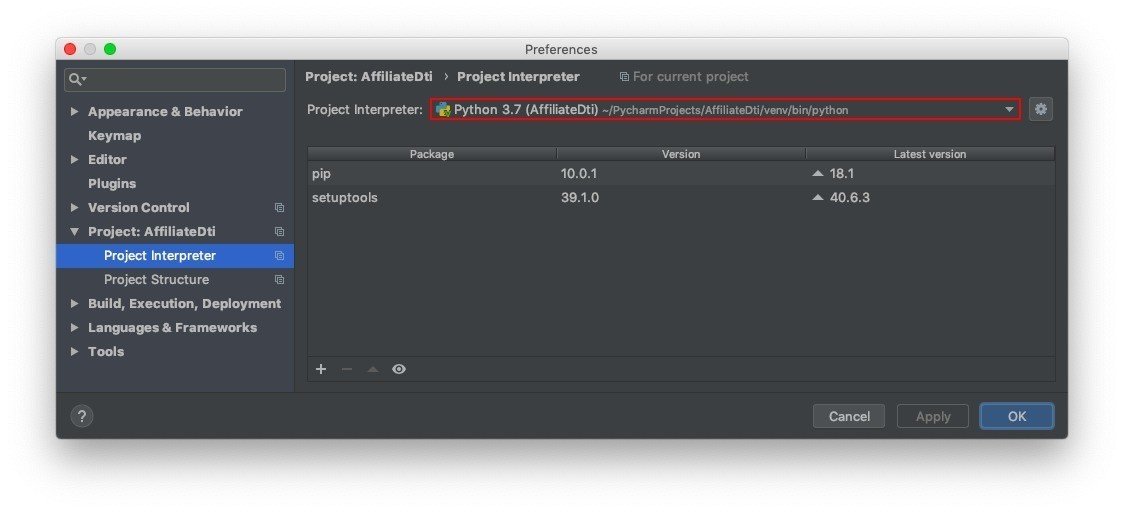
メニューバーから [PyCharm] -> [Preferences] ウィンドウを開き, 左サイドメニューで [Project Interpreter] を選択します.
[Preferences] ウィンドウは [command] + [,] で開くこともできます.
続けて [Project Interpreter] のドロップダウンリストから,
[Python 3.7 (AffiliateDti) ~/PycharmProjects/AffiliateDti/venv/bin/python]
を選択して [OK] ボタンをクリックします.
4.3. selenium のインストール
メニューバーから [PyCharm] -> [Preferences] ウィンドウを開き, 左サイドメニューで [Project Interpreter] を選択します.
[Preferences] ウィンドウは [command] + [,] で開くこともできます.
続けて [+] ボタンをクリックします.

[Available Packages] ウィンドウが開いたら, 検索ボックスに [selenium] と入力します.
検索ボックス下のリストで [selenium] が選択されていることを確認し, [Install Package] ボタンをクリックします.

次の画像のように, [Package 'selenium' installed successfully] と表示されればインストール完了です.

4.4. コンフィグファイルの作成
ここからプログラムの作成に入ります. まずは,プログラム内で使用する情報をまとめるコンフィグファイル [config.ini] を作成します.
メインウィンドウのサイドメニューで [AffiliateDti] を右クリックし, [New] -> [File] の順に選択します.

[New File] ウィンドウが開きますので, 作成するファイル名 [config.ini] を入力し, [OK] ボタンをクリックします.

新規作成した [config.ini] ファイルが自動的に開きます.
ここで [Plugins supporting *.ini files found.] と表示されるので, [Install plugins] をクリックします.

[Choose Plugins to Install or Enable] ウィンドウが開いたら, [Ini4Idea ***] にチェックがついていることを確認し, [OK] ボタンをクリックします.
[***] 部分はプラグインのバージョンナンバーです.

プラグインのインストールが完了すると, 自動的にメインウィンドウに戻ります. ここで PyCharmCE の再起動を促すメッセージが表示されるので, [Restart] をクリックします.

再起動が完了すると [Welcome to PyCharm] ウィンドウが表示されます.
ウィンドウ左部に, 先ほど作成したプロジェクト [AffiliateDti] が表示されていますので, クリックして開きます.

プロジェクトが開くと, 拡張子の再割り当てに関するメッセージが表示されますので, [Revert] をクリックします.

次に, 以下のソースコードを [config.ini] にコピー&ペーストして保存します.
ここで [XXXX] は macOS のユーザー名, [YYYY] は DTI アフィリエイトの ID, [ZZZZ] は DTI アフィリエイトのパスワードに置き換えてください.
[COMMON]
PATH_DRIVER = /Users/XXXX/BrowserDriver/chromedriver
PATH_BASE = /Users/XXXX/Downloads/
[DTI]
ID = YYYY
PASS = ZZZZ
URL_LOGIN = https://www.affiliate-dti.com/
URL_EXPORT = https://affstats.dtiserv2.com/cgi-bin/data_export.cgiPATH_DRIVER
ChromeDriver ファイルまでのフルパス
PATH_BASE
"カスタム生データ取得ツール" から取得した XML ファイルを保存するディレクトリ
ID
DTI アフィリエイトのアフィリエイト ID
PASS
DTI アフィリエイトのパスワード
URL_LOGIN
DTI アフィリエイトのログイン画面の URL
URL_EXPORT
"カスタム生データ取得ツール" の URL
4.5. 自動化ツール本体の作成
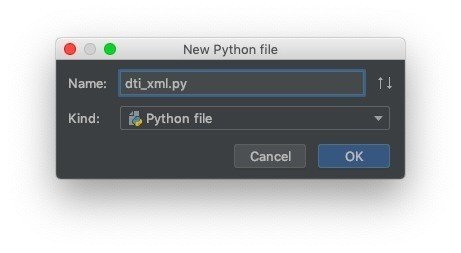
自動化ツールの本体となるプログラムファイル [dti_xml.py] を作成します.
メインウィンドウのサイドメニューで [AffiliateDti] を右クリックし, [New] -> [Python File] の順に選択します.

[New File] ウィンドウが開きますので, 作成するファイル名 [dti_xml.py] を入力し, [OK] ボタンをクリックします.
新規作成した [dti_xml.py] ファイルが自動的に開くので, 以下のソースコードをコピー&ペーストして保存します.
これで自動化ツールは完成です.
from configparser import ConfigParser
from selenium import webdriver
# コンフィグファイル読み込み
config = ConfigParser()
config.read('./config.ini')
# 定数定義
# 共通
PATH_DRIVER = config['COMMON']['PATH_DRIVER']
PATH_BASE = config['COMMON']['PATH_BASE']
FILE_NAME = "DTI_2018"
FILE_EXT = ".xml"
# DTI関連
DTI_ID = config['DTI']['ID']
DTI_PASS = config['DTI']['PASS']
URL_LOGIN_DTI = config['DTI']['URL_LOGIN']
URL_EXPORT = config['DTI']['URL_EXPORT']
# ドライバインスタンス生成
driver = webdriver.Chrome(PATH_DRIVER)
# DTI ログイン操作
driver.get(URL_LOGIN_DTI)
userid = driver.find_element_by_id("userid")
userid.send_keys(DTI_ID)
passwd = driver.find_element_by_id("passwd")
passwd.send_keys(DTI_PASS)
login_btn = driver.find_element_by_id("login")
login_btn.click()
# 表示サイト選択用リスト定義
LST_SITE_ID = [["2468", "2470", "2478", "2516", "2471", "2469"],
["2476", "2520", "2521", "2535", "2550", "2477"],
["2581", "2572", "2543", "2546", "2540", "2486"],
["2665", "2564", "2518", "2514", "2544", "2641"],
["2401", "2390", "2554"]]
# XMLデータ取得ループ
for i, lstSiteIds in enumerate(LST_SITE_ID):
# カスタム生データ取得ツールページ表示
driver.get(URL_EXPORT)
# データ形式選択
for radio in driver.find_elements_by_xpath("//*[@type='radio']"):
if radio.get_attribute("value") == "xml":
radio.click()
break
# サイト選択チェックボックスチェック
for checkbox in driver.find_elements_by_xpath("//*[@type='checkbox']"):
if checkbox.get_attribute("value") in lstSiteIds:
checkbox.click()
# ダウンロード開始ボタンクリック
download_btn = driver.find_element_by_class_name("downloadbtn")
download_btn.click()
# XMLデータ保存
xmlSrc = driver.execute_script('return document.getElementById("webkit-xml-viewer-source-xml").innerHTML')
with open(PATH_BASE + FILE_NAME + "_" + str(i) + FILE_EXT, mode='w') as f:
f.write(xmlSrc)
# ブラウザ終了
driver.quit()
5. 自動化ツールの実行
さあ, いよいよ自動化ツールを実行するときです.
メインウィンドウのサイドメニューから [dti_xml.py] を右クリックし, [Run 'dti_xml'] を選択してください.

プログラムに問題がなければ, Chrome が自動的に起動し, プログラムした処理が動き始めます. 処理が完了すると Chrome は自動的に終了します.
自動化ツールが終了したら, [config.ini] で指定したディレクトリに [DTI_2018_0.xml] ~ [DTI_2018_4.xml] の 5 ファイルが作成されていることを確認してください.
ちなみに, XML ファイルを 5 つに分割して保存しているのは, 一つにまとめるとファイルサイズが大きくなりすぎ, 各種エディタで XML ファイルを開くときに処理が緩慢になるのを避けるためです.
6. 自動化ツール本体の解説
ここからは理解を深めたい方向けの解説です. 今回のツールを応用すれば色々なことが自動化できるようになると思います.
では, プログラム本体を順を追って説明していきます.
6.1. パッケージのインポート
from configparser import ConfigParser
from selenium import webdriver最初の 2 行は "ここで指定する機能を使いますよ" という宣言みたいなもの (機能の取り込み = インポート) と考えてください.
1 行目では "configparser" (コンフィグパーサー) をインポートしています. これは "4.4. コンフィグファイルの作成" で作成した [config.ini] の情報をプログラムに取り込むために使用されます.
2 行目は "4.3. selenium のインストール" でインストールした外部パッケージ "selenium" (セレニウム) のインポートです. 今回作成した自動化ツールの基幹をなす機能群です.
6.2. コンフィグファイルの読み込み
# コンフィグファイル読み込み
config = ConfigParser()
config.read('./config.ini')
ここで実際に "configparser" の機能を呼び出して使用しています. 読み込みたい設定ファイルのファイル名を指定することで, その内容をマップ型というオブジェクト形式で返してくれます.
# 定数定義
# 共通
PATH_DRIVER = config['COMMON']['PATH_DRIVER']
PATH_BASE = config['COMMON']['PATH_BASE']
FILE_NAME = "DTI_2018"
FILE_EXT = ".xml"
# DTI関連
DTI_ID = config['DTI']['ID']
DTI_PASS = config['DTI']['PASS']
URL_LOGIN_DTI = config['DTI']['URL_LOGIN']
URL_EXPORT = config['DTI']['URL_EXPORT'][config.ini] から読み出した情報を定数に代入しています. Python には定数という概念はありませんが, 値を変更しない変数という意味で, あえて "定数" と表現しています.
ちなみに "FILE_NAME" (生成する XML ファイル名) と "FILE_EXT" (生成する XML ファイルの拡張子) は, 単に文字列を変数に代入しているだけです.
6.3. DTI へのログイン操作
# ドライバインスタンス生成
driver = webdriver.Chrome(PATH_DRIVER)
"selenium" の Chrome 用 "webdriver" 機能に, ChromeDriver ファイルまでのフルパスを渡すと同時に呼び出しています.
こうしておくことで, 以降のプログラム中で "driver" オブジェクトを使って Chrome を操作できるようになります.
# DTI ログイン操作
driver.get(URL_LOGIN_DTI)
ここからが Chrome を操作する部分です.
上記の 1 行だけで, "Chrome の起動" と "DTI アフィリエイトのログインページに遷移" という 2 つの操作を行います.
userid = driver.find_element_by_id("userid")
userid.send_keys(DTI_ID)
passwd = driver.find_element_by_id("passwd")
passwd.send_keys(DTI_PASS)
login_btn = driver.find_element_by_id("login")
login_btn.click()この 6 行は, 2 行ごとに 1 つの操作を担っています.
1 行目 : ログインページの ID 入力フォームを見つける
2 行目 : ID 入力フォームに ID を入力
3 行目 : ログインページのパスワード入力フォームを見つける
4 行目 : パスワード入力フォームにパスワードを入力
5 行目 : ログインページのログインボタンを見つける
6 行目 : ログインボタンをクリック
手動で DTI のログインページを開き, そのソース (HTML) の中から "userid" / "passwd" / "login" といったワードを検索してみると, 理解が早いと思います.
6.4. 表示サイト選択用リスト
# 表示サイト選択用リスト定義
LST_SITE_ID = [["2468", "2470", "2478", "2516", "2471", "2469"],
["2476", "2520", "2521", "2535", "2550", "2477"],
["2581", "2572", "2543", "2546", "2540", "2486"],
["2665", "2564", "2518", "2514", "2544", "2641"],
["2401", "2390", "2554"]]これはサイト ID を保持する二重リスト (リストを要素に持つリスト) の定義です. "カスタム生データ取得ツール" ページの HTML を確認してもらうと解ると思いますが, リストに保持しているナンバーはアフィリエイト対象サイトのサイト ID になっています.
もしアフィリエイト対象のサイトに増減があれば, ここを修正する必要が出てきますので覚えておいてください.
※ なぜリストを 5 つに分けているのか? ※
XML 形式で作品データをダウンロードする際に, どのサイトのデータを取得するかを選択することができます.
一度に全てのサイトのデータを取得すると XML ファイルのサイズが大きくなり, 開くときにエディタの動作が緩慢になってしまう場合があります.
ですので, あえてデータの取得とXML ファイルの保存を 5 回に分け, この問題を回避するようにしています.
6.5. XML データ取得ループ
# XMLデータ取得ループ
for i, lstSiteIds in enumerate(LST_SITE_ID):ここからが XML ファイルを取得するループ (繰り返し) 処理です.
上で説明した "LST_SITE_ID" リストから順番にインデックス番号 (i : 整数型) と要素 (lstSiteIds : リスト型) を取り出して処理します.
トータルで 5 回のループ処理が行われ, 1 回のループにつき 1 つの XML ファイルが生成&保存されます.
ソースコードの最終行 "driver.quit()" の直前までが, このループの処理になります.
# カスタム生データ取得ツールページ表示
driver.get(URL_EXPORT)これはログインページを表示するときにも使用した方法ですね. ここでは "カスタム生データ取得ツール" ページに遷移させています.
6.6. データ形式選択
# データ形式選択
for radio in driver.find_elements_by_xpath("//*[@type='radio']"):
if radio.get_attribute("value") == "xml":
radio.click()
breakダウンロードするデータ形式を選択しています.
"カスタム生データ取得ツール" では, CSV / XML 形式の 2 種類に対応していますが, プログラムで処理するには XML の方が便利なので, 今回は XML のラジをボタンを選択しています.
まず driver.find_elements_by_xpath("//*[@type='radio']") の部分で HTML の type 要素が "radio" のものを全て拾ってきます.
それを for ループで 1 つずつ取り出し, value 値が xml のものが見つかったら, そのラジオボタンをクリックし, break でループ処理を抜けます.
6.7. サイト選択チェックボックスチェック
# サイト選択チェックボックスチェック
for checkbox in driver.find_elements_by_xpath("//*[@type='checkbox']"):
if checkbox.get_attribute("value") in lstSiteIds:
checkbox.click()まず driver.find_elements_by_xpath("//*[@type='checkbox']") の部分で HTML の type 要素が "checkbox" のものを全て拾ってきます.
それを for ループで 1 つずつ取り出し, value 値が lstSiteIds リストに含まれている場合に, そのチェックボックスをクリック (チェックをつける) しています.
6.8. ダウンロード開始ボタンクリック
# ダウンロード開始ボタンクリック
download_btn = driver.find_element_by_class_name("downloadbtn")
download_btn.click()ダウンロード開始ボタンをクリックする処理です.
driver.find_element_by_class_name("downloadbtn") の部分でダウンロードボタンを探し出し, download_btn.click() でクリックしています.
6.9. XML データ保存
# XMLデータ保存
xmlSrc = driver.execute_script('return document.getElementById("webkit-xml-viewer-source-xml").innerHTML')
with open(PATH_BASE + FILE_NAME + "_" + str(i) + FILE_EXT, mode='w') as f:
f.write(xmlSrc)この 3 行で XML データの取得とファイルへの保存を行なっています.
表示中のページのソース (XML) を xmlSrc = driver.execute_script(~ の部分で取得し, その後の 2 行でファイルに保存します.
※ 注記 ※
ページのソースを取得する方法として driver.page_source もありますが, Chrome ブラウザで XML ファイルを表示している場合, この方法では純粋な XML を取得することができません.
6.10. Chrome の終了
# ブラウザ終了
driver.quit()最後に Chrome を終了させて自動化ツールの処理が終了します.
Chrome の終了方法として driver.close() が紹介されていることが多いですが, driver.quit() との違いは次の通りです.
driver.close()
現在開いているウィンドウを閉じる
Chrome ブラウザのプロセスは残る
driver.quit()
全てのウィンドウを閉じる
Chrome ブラウザのプロセスを終了させる
7. まとめ
DTI アフィリエイトで提供されている "カスタム生データ取得ツール" を例に, Python3 + selenium を使ってブラウザ操作を自動化する手法と, 具体的なツールの作成手順を紹介しました.
今回作成した自動化ツールをベースに, 色々なブラウザ操作を自動化してみるのも楽しいと思います. より理解を深めたい方は, ぜひチャレンジしてみてください.
著者へのご連絡は Twitter ( @slangsoft ) から!
スキとサポートは明日への活力! 誰かのためになっているという実感を与えてくれます!