
SkyWayで軽量なバーチャル背景を実現する方法

[2023/10/23 追記]
SkyWayでバーチャル背景を利用するためのJavaScriptのライブラリを公開しました。
https://support.skyway.ntt.com/hc/ja/articles/24229180565401
バーチャル背景や背景ぼかしの処理を、より簡単に実装できます。
今後バーチャル背景の処理を実装する際は、こちらのライブラリの利用も検討してみてください。
こんにちは、SkyWay WebRTC Researchチームのucchyです。
突然ですが、皆さんはバーチャル背景機能を使ったことがありますか?
リモート化の進展に伴い、バーチャル背景機能の重要性がより高まっています。
実際に、SkyWayを利用されているお客様からも「バーチャル背景機能が欲しい」「背景ぼかし機能を実装してみたがイマイチ精度が良くない、動作が重い」といったご要望やご意見をいただいています。
そこで、本記事では、2021年5月に公開されたMediaPipe Selfie Segmentationを用いて、SkyWayでバーチャル背景を実現する方法をご紹介します。
※今回ご紹介する方法の対象ブラウザはChromiumブラウザ(Chrome、Edge)になります。FirefoxやSafariでは正常に動作しないのでご注意ください。
この記事を読むとできるようになること
・バーチャル背景機能が付属したSkyWayのサンプルアプリを試すことができる
・MediaPipeとは何かを理解できるようになる
・MediaPipeとSkyWayを組み合わせたバーチャル背景機能の実装ノウハウを知ることができる
まずはサンプルアプリをお試しください
本記事で紹介するサンプルアプリを以下リポジトリに置いています。
以下の手順を実施していただくことで、上記サンプルアプリを動かすことができます。Chrome 89以降で動作します。
1. SkyWayダッシュボードにログインし、APIキーを発行する
2. ChromeのURL入力欄に chrome://flags/#enable-experimental-web-platform-features と入力し、Experimental Web Platform featuresフラグを有効化する
3. 上記リポジトリをCloneし、サンプルコードに発行したAPIキーをコードに埋め込み、ローカルで起動させる
また、2.の作業が不要なサンプルコードも用意しております。
こちらはChromeからフラグを設定しなくても動作します。
https://github.com/yuki-uchida/virtual_background_SkyWay/tree/use_requestAnimationFrame
MediaPipeとは
MediaPipeは、Googleが開発したライブメディア向けの機械学習パイプラインを構築できるフレームワークです。
https://google.github.io/mediapipe/
顔検出や物体検出などに必要な前処理・推論・後処理などをグラフとして表現し、WebからIoTまで、様々な環境で動く様にコンパイルができます。
プラットフォームごとに別々に機械学習ライブラリを用意する必要が無くなるのは魅力的ですね。
また、MediaPipeの特徴として、「WebAssembly」を利用していることも挙げられます。
WebAssemblyはRustやC++などで記述された高速なコードを実行させることができます。
TensorFlow.jsのBodyPixなど、従来のJavaScriptによる実装でもバーチャル背景は実現可能ですが、WebAssemblyを利用しているMediaPipeを使った方が軽快な動作を期待できます。
MediaPipe Selfie Segmentation
今回は、このMediaPipeを使って構築されたMediaPipe Selfie Segmentationを利用します。
https://google.github.io/mediapipe/solutions/selfie_segmentation
このMediaPipe Selfie Segmentationは、下図のように画像の中から人物をセグメンテーションしてくれるライブラリです。このセグメンテーションされた画像を利用することで、「バーチャル背景」や「背景ぼかし」を実現可能です。
また、このライブラリを自身でコンパイルする必要はありません。
コンパイル済みのものがnpmで公開されています。
MediaPipe Selfie Segmentationを動かすサンプル
以下の様に、HTMLでselfie_segmentationライブラリを読み込みます。
<script
src="https://cdn.jsdelivr.net/npm/@mediapipe/selfie_segmentation/selfie_segmentation.js"
crossorigin="anonymous">
</script>JS側では以下の様にSelfieSegmentationを初期化します。
setOptions()では、以下の2つのモデルから選ぶことができます。セグメンテーションはかなり高負荷な処理であるため、まずは軽いモデルである1を選択することをお勧めします。
0 : 一般モデル
1 : 景観モデル(軽量)
function onResults(results) {
// セグメンテーションされた画像をresultsとして受け取る
// canvasへの描画
}
const selfieSegmentation = new SelfieSegmentation({
locateFile: (file) => {
return `https://cdn.jsdelivr.net/npm/@mediapipe/selfie_segmentation/${file}`;
},
});
selfieSegmentation.setOptions({
modelSelection: 1, // モデルの選択
});
selfieSegmentation.onResults(onResults);初期設定が完了した後は、SelfieSegmentationに画像データを送り、セグメンテーションしてもらうための処理を書いていきます。
セグメンテーションを指示する処理自体は以下の様な形で行うことができます。
await selfieSegmentation.send({ image: imageBitmap });ここで注意が必要なのは、imageBitMapという型で渡す必要があるということです。
WebRTCでは、カメラの映像をgetUserMedia()で取得するのが基本ですが、getUserMedia()で取得できるのはMediaStream及びMediaStreamTrackという型であるため、少し工夫が必要です。
そこで、今回はMediaStreamTrackProcessorという新しいブラウザAPIを使ってMediaStreamTrackからVideoFrameを取得し、WritableStreamに流し、createImageBitmap()によってImageBitMapという型に変換します。
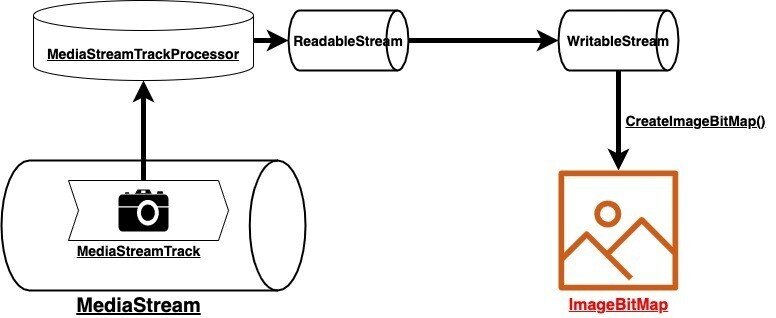
const localMediaStream = await navigator.mediaDevices.getUserMedia({
video: {
width: 1080,
height: 720,
frameRate: 15,
},
audio: false,
});
const processor = new MediaStreamTrackProcessor(
localMediaStream.getVideoTracks()[0]
);
const writable = new WritableStream({
start() {
console.log("WritableStream started.");
},
async write(videoFrame) {
const imageBitmap = await createImageBitmap(videoFrame);
await selfieSegmentation.send({ image: imageBitmap });
imageBitmap.close();
videoFrame.close();
},
stop() {
console.log("WritableStream stopped.");
},
});
processor.readable.pipeTo(writable);await selfieSegmentation.send({ image: imageBitmap });
により、セグメンテーションされた画像は
selfieSegmentation.onResults(onResults);
で設定していた、onResults()関数に渡され、処理されます。
上記ではまだonResults()関数の処理を書いていなかったので、処理を記述して、canvasへ描画していきましょう。
MediaStreamTrackProcessorについて
MediaStreamTrackProcessorは、まだGoogle Chromeでしか実装されていない、新しいブラウザAPIです。
https://w3c.github.io/mediacapture-transform/#track-processor
このMediaStreamTrackProcessorは、WebCodecsいう技術仕様の一部として実装されました。
利用するにあたって、
chrome://flags/#enable-experimental-web-platform-features
から機能を有効にする必要があります。
この機能を使わない場合、requestAnimationFrameを使うこともできますが、MediaStreamTrackProcessorはStreams APIの仕様に沿っており、「映像(フレーム)が流れてきた時に適切に処理してくれる」という利点があります。
一方、requestAnimationFrameは定期的に実行されます。
そのため「新しい映像(フレーム)が来ていないのに実行してしまい、無駄な処理が走ってしまう」という欠点があります。
また、「ブラウザのタブやウィンドウが画面に表示されていないと停止してしまう」という欠点もあります。
無駄に処理が走らないように、ウィンドウが隠れた時には停止する様な制約が入っているわけですが、今回の様なユースケースの場合には少し厄介な制約になります。
MediaStreamTrackProcessorはこういった欠点も踏まえて検討された技術ですが、W3Cでも非公式なドラフトとして提案されており、公式な仕様ではありません。
今後フィールドトライアルではなく正式な仕様として入ることに期待しています。
【補足】
Google Chrome M91以前では、VideoTrackReaderというAPIが用意されていましたが、MediaStreamTrackProcessorへ移行していくということで廃止となりました。
requestAnimationFrameはブラウザが隠れてしまうと停止してしまうという欠点が許容できない場合、Google Chrome M90までという制約がついてしまいますが、VideoTrackReaderを利用することで回避できます。
mganeko様の以下の記事が非常に参考になります。
requestAnimationFrameの泣き所をVideoTrackReader +αで解決する
今後もAPIの仕様が大きく変わっていく可能性がありますので、本記事のコードが動かなかった場合はMediaStreamTrackProcessorの最新ドラフトを確認していただくようお願い致します。
WebCodecsについて詳しく知りたい方は以下の記事を参照ください。
WritableStreamについて
WritableStreamは、Streams APIと呼ばれる技術仕様の一部です。
「大きなデータがあったときに、それを細かく読み込み・変換し・書き込むことができる」というのが、Streams APIの特徴です。
例えば、50MBのデータがあったときに、全て読み込んでから処理するよりも、読み込みながら処理した方が無駄な時間がありません。
特にWebRTCのようにリアルタイムなデータ処理が必要となる場合、このStreamという概念は必須になります。
今回は、「MediaStreamTrackProcessorを使って映像のReadableStreamを受け取った後、WritableStreamに渡してSelfieSegmentationに書き込んだ」ということになります。
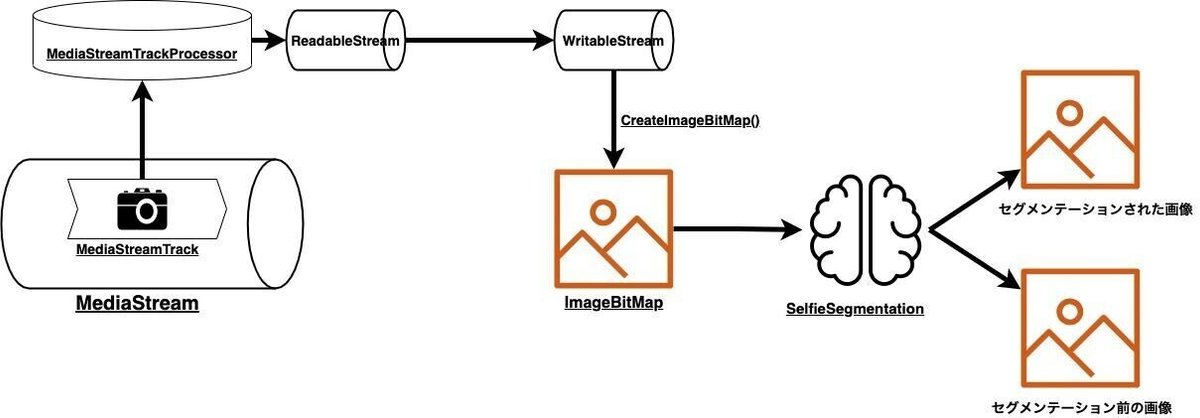
セグメンテーションされた画像の確認
まず、await selfieSegmentation.send({ image: imageBitmap }); によってセグメンテーションされた画像の確認からしていきましょう。
resultsには、results.image、results.segmentationMaskが入っているため、まずはこれを描画して確認してみましょう。
imageはセグメンテーションされる前の画像が入っており、segmentationMaskはセグメンテーションされた画像が入っているので、それぞれ描画して確認してみます。
const canvasElement = document.getElementById("output_canvas");
const canvasCtx = canvasElement.getContext("2d");
function onResults(results) {
canvasCtx.save();
canvasCtx.clearRect(0, 0, canvasElement.width, canvasElement.height);
// セグメンテーションされた画像の描画
canvasCtx.drawImage(
results.segmentationMask,
0,
0,
canvasElement.width,
canvasElement.height
);
// セグメンテーションされる前の画像の描画
//canvasCtx.drawImage(
// results.image,
// 0,
// 0,
// canvasElement.width,
// canvasElement.height
//);
results.segmentationMask.close();
results.image.close();
}
~~~~~~省略~~~~~~
selfieSegmentation.onResults(onResults);
(async function () {
~~~~~~省略~~~~~~
await selfieSegmentation.send({ image: imageBitmap });
~~~~~~省略~~~~~~
})();
こうすると、上記のようにセグメンテーションされていることがわかります。
canvasで合成して背景切り抜きを行う
元画像とセグメンテーションされた画像を組み合わせることで「背景切り抜き」を行います。
合成する際には、canvasのglobalCompositeOperationをうまく使うことで画像の重ね方を選ぶことができます。
少し複雑になるので、こちらのcanvasリファレンスを読みながら進めることをお勧めします。
今回は、globalCompositeOperationのsource-inというオプションを使って、元画像とセグメンテーションされた画像の重なっている部分のみ描画します。
先にセグメンテーションされた画像を描画した後、セグメンテーション前の画像をsource-inで描画すると下記の様なコードになります。
source-inでは、「前に描画された画像と重なっている部分のみ今回の画像を描画する」という意味になるので、順番を間違えると意図しない描画方法となることに注意してください。
function onResults(results) {
canvasCtx.save();
canvasCtx.clearRect(0, 0, canvasElement.width, canvasElement.height);
canvasCtx.drawImage(
results.segmentationMask,
0,
0,
canvasElement.width,
canvasElement.height
);
canvasCtx.globalCompositeOperation = "source-in";
canvasCtx.drawImage(
results.image,
0,
0,
canvasElement.width,
canvasElement.height
);
results.segmentationMask.close();
results.image.close();
}
これによって、右側の「背景切り抜きされた画像」を描画可能になります。
背景切り抜きするのではなく、間にぼかしフィルターなどを用いることで、背景ぼかし機能の実装も可能でしょう。
背景が切り抜かれた画像にバーチャル背景を合成する
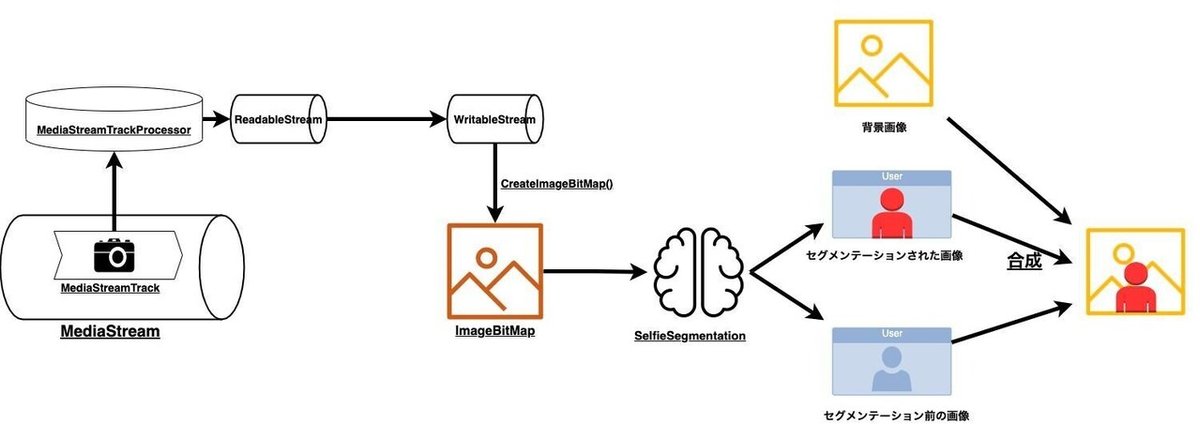
背景を切り抜いた画像と背景画像として設定したい画像を、再度canvasで合成することでバーチャル背景機能を実装することができます。
まず、1080×720の画像を用意しましょう。
違うサイズの画像をリサイズしてバーチャル背景に設定する機能なども、canvasなどの機能を使えば実装可能ですが、今回は割愛します。
下記のコードの様に、 背景に設定したい画像を読み込んでおき、 destionation-atopで描画します。
destination-atopは、「元々描画されている画像はそのまま描画し、上から描画する画像は重なっていない部分のみ描画する」というものです。

上記画像においては、赤画像が元々描画されている画像であり、青画像が上から描画する画像です。(上記画像はCanvasリファレンスより引用)
~~~~~~~ 追加 ~~~~~~~~~
const chara = new Image();
chara.src = "./sample.jpeg";
~~~~~~~ここまで~~~~~~~~
function onResults(results) {
canvasCtx.save();
canvasCtx.clearRect(0, 0, canvasElement.width, canvasElement.height);
canvasCtx.drawImage(
results.segmentationMask,
0,
0,
canvasElement.width,
canvasElement.height
);
canvasCtx.globalCompositeOperation = "source-in";
canvasCtx.drawImage(
results.image,
0,
0,
canvasElement.width,
canvasElement.height
);
~~~~~~~ 追加 ~~~~~~~~~
canvasCtx.globalCompositeOperation = "destination-atop";
canvasCtx.drawImage(chara, 0, 0, canvasElement.width, canvasElement.height);
~~~~~~~ここまで~~~~~~~~
canvasCtx.restore();
results.segmentationMask.close();
results.image.close();
}
これで、背景画像の合成は完了しました。
同様のことを行えばSkyWay以外のWebRTCアプリケーションにも応用可能ですので、ぜひお試しください。
canvasからMediaStreamを取得し、SkyWayのMediaConnectionに渡す
SkyWayを動かすコードに関しては、こちらのチュートリアルの内容をそのまま利用します。
WebRTC及びSkyWayでは、送信したい映像をMediaStreamとして渡す必要があるので、canvasのcaptureStream()という機能を使ってMediaStreamとして取り出します。
const canvasElement = document.getElementById("output_canvas");
~~~~~~~~~~~~~~~~
// ストリームの取得
const segmentedLocalMediaStream = canvasElement.captureStream();そして、下記の様にSkyWayのPeerにセグメンテーションされたMediaStreamであるsegmentedLocalMediaStreamを渡してあげます。
const peer = new Peer({
key: "<あなたのAPIキー>",
debug: 3,
});
peer.on("open", () => {
document.getElementById("my-id").textContent = peer.id;
});
peer.on("call", (mediaConnection) => {
mediaConnection.answer(segmentedLocalMediaStream);
setEventListener(mediaConnection);
});
// 発信処理
document.getElementById("make-call").onclick = () => {
const theirID = document.getElementById("their-id").value;
const mediaConnection = peer.call(theirID, segmentedLocalMediaStream);
setEventListener(mediaConnection);
};
// イベントリスナを設置する関数
const setEventListener = (mediaConnection) => {
mediaConnection.on("stream", (stream) => {
// video要素にカメラ映像をセットして再生
const videoElm = document.getElementById("their-video");
videoElm.srcObject = stream;
videoElm.play();
});
};発信処理
SkyWayでは、通話したい相手のPeerIDを使って発信するだけで映像をやりとりすることができます。
下記画像の様に、通話したい相手のPeerIDを入力して発信ボタンを押すと相手の映像を受け取ることができます。

筆者のPCのスペックは以下の通りですが、タブを2つ開いて通話する(=2倍負荷がかかる)状態でも、1コア程度のCPU使用率しか消費していませんでした。
セグメンテーションの負荷はもっと大きいと思っていましたが、1処理あたり30%~50%程度であるならばかなり実用的になってきたと感じます。
・MacBook Pro (15-inch, 2018)
・2.9 GHz 6コアIntel Core i9
・32 GB 2400 MHz DDR4
・Radeon Pro 560X 4 GB
・Intel UHD Graphics 630 1536 MB
今回は1080×720の解像度、15FPSの映像をやりとりしていますので、かなり負荷が小さく済んでいることがわかります。
フルHD 60fpsとなると難しそうですが、そこまで高解像度・高フレームレートでなくても良い通話であれば試してみると良いのではないでしょうか。
本記事で書いたコードは以下のリポジトリに完成品がありますので、こちらもご覧ください。
フラグを有効にせずChromeでバーチャル背景を実現する方法
今回の記事では、MediaStreamTrackProcessorを利用するため、以下の設定が有効になっていることを前提としています。
chrome://flags/#enable-experimental-web-platform-features
しかし、実際にはエンドユーザにフラグを有効にしてもらうのは大変です。
そこで、今回、 MediaStreamTrackProcessorを使わなくてもバーチャル背景できるSkyWayのサンプルコードも用意しました。
下記のリポジトリのuse_requestAnimationFrameブランチを参照ください。
https://github.com/yuki-uchida/virtual_background_SkyWay/tree/use_requestAnimationFrame
requestAnimationFrameを使った仕組みとなっており、フィールドトライアルを有効にしていなくても、Google Chromeや Microsoft Edgeで動く様になっています。
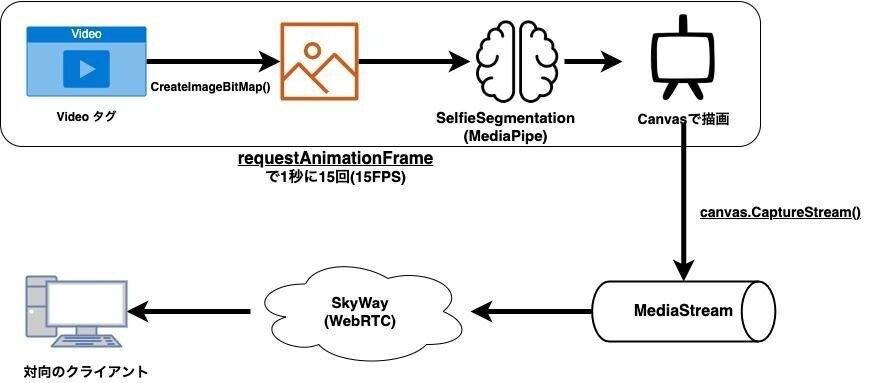
【補足】
requestAnimationFrame を利用する際に「ウィンドウが隠れてしまうと停止する」「映像のフレームとrequestAnimationFrameのタイミングは厳密には一致しない」という欠点があるため、こちらにはご注意ください。
※FireFoxとSafariに関しては、Selfie Segmentationライブラリが使用するImageBitMapのオプションサポートをしていないため、当分は使用できないと思われます。
---
SkyWayでは引き続きサポート状況やバグ情報のチェックを行い、最新情報の発信を行っていきます。
本記事がお役に立ちましたら、コメントやスキを頂けますと幸いです。
参考にさせていただいた記事
https://github.com/google/mediapipe
https://google.github.io/mediapipe/
https://google.github.io/mediapipe/solutions/selfie_segmentation#models
https://codepen.io/mediapipe/full/wvJyQpq
https://www.w3.org/TR/webcodecs/
https://w3c.github.io/mediacapture-transform/#track-processor
https://developer.mozilla.org/ja/docs/Web/API/Streams_API
https://developer.mozilla.org/ja/docs/Web/API/WritableStream
https://zenn.dev/mganeko/articles/mediastreamtrackprocessor
https://zenn.dev/mganeko/articles/videotrackreader
https://qiita.com/y-i/items/872d00848caa605b3cd8
http://www.htmq.com/canvas/globalCompositeOperation.shtml
https://note.affi-sapo-sv.com/js-globalcompositeoperation.php
▼SkyWayサービスサイトはこちら▼
https://webrtc.ecl.ntt.com/
この記事が気に入ったらサポートをしてみませんか?