
vocal-removerをGoogle Colabで試す

ボーカルとインストルメンタル(楽器のみ)をそれぞれ抽出するツール
Google Colabで試す
1. インストール
セルの実行ボタンを押し、使うものをインストール
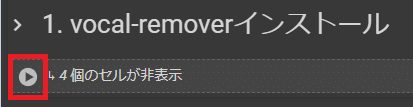
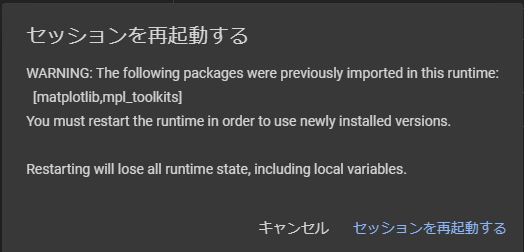
実行中に警告が出ますキャンセルを押してください
2. ファイルアップロード
サイドメニューのフォルダアイコンをクリックし開きます
ここに抽出したいファイルをアップロードします
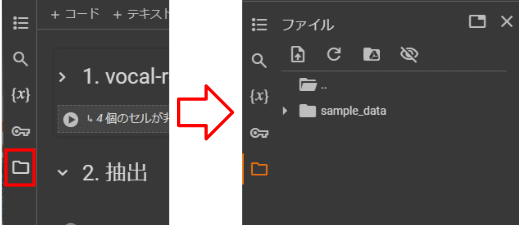
サイドメニューの下に表示された
アップロードしたファイルがアップロード完了するまで待つ

3. 抽出
アップロードしたファイルにカーソルを合わせ、右クリックしパスのコピーをクリック
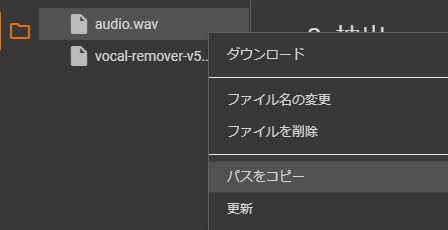
ファイルパスをaudioフォームにペーストして実行
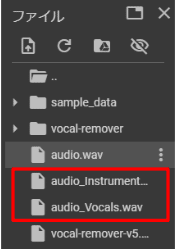
アップロードしたファイル名の後ろにInstrumentsとVocalsがついたファイルが作成されます
4. 試聴
出力されたファイルパスをコピペして実行すると聞けます
コード
githubから必要なものをインストール&解凍
!wget https://github.com/tsurumeso/vocal-remover/releases/download/v5.1.0/vocal-remover-v5.1.0.zip
!unzip vocal-remover-v5.1.0.zipvocal-removerディレクトリに移動し必要なライブラリのインストール
%cd vocal-remover
!pip install -r requirements.txt再生用のライブラリのインストール
!pip install pydubPythonファイルの実行
--input:音声ファイルパス
--gpu:GPUで実行するか
--output_dir:保存先
--tta:分離品質を向上
!python inference.py --input {audio} --gpu {num} --output_dir '/content' --ttaAIにコードを読ませて出力した、ほかのオプション
-g / --gpu: GPU ID を指定します。CPU を使用する場合は -1 を指定します。
-P / --pretrained_model: トレーニング済みのモデルファイルを指定します。
-i / --input: 入力オーディオファイルを指定します。
-r / --sr: サンプルレートを指定します (デフォルト: 44100 Hz)。
-f / --n_fft: FFT 窓の長さを指定します (デフォルト: 2048)。
-H / --hop_length: ホップの長さを指定します (デフォルト: 1024)。
-B / --batchsize: バッチサイズを指定します (デフォルト: 4)。
-c / --cropsize: 切り出しサイズを指定します (デフォルト: 256)。
-I / --output_image: 分離オーディオのスペクトログラムを画像として保存します。
-t / --tta: テストタイムデータ拡張(tta)を実行します。
-p / --postprocess: 分離オーディオに対して後処理を実行します。
-o / --output_dir: 分離オーディオとスペクトログラムの出力ディレクトリを指定します。