
Difyで自分専用の複数モデル(DALL-E 3, Stable Diffusion 3, FLUX.1, ideogram 2.0)画像生成アプリをつくる

前回は、Difyで自分専用のマルチLLMチャットボットをつくりましたが、今回は、最近話題の高性能な画像生成AI「FLUX.1」や「Ideogram 2.0」など、複数モデル対応の画像生成アプリを作ります。
これら複数の画像生成AIを使おうと思うと、それぞれのWebサイトに行って作業する必要があるので面倒です。また、個別にアカウント登録やサブスク登録などを行う必要があり、毎日ガッツリ使わないと元が取れません。
その点、API経由で使用すれば、従量制のものが多いので、それほどガッツリ使うわけではない場合は安上がりですし、一つのアプリの中で、各種画像生成AIを気軽に試すことができるのではないかと思います。
ワークフローの全体像
作成したワークフローの全体像です。「DALL-E 3」と「Stable Diffusion 3」は、Difyに標準で各画像生成モデルに対応したブロックが用意されているので簡単ですが、「FLUX.1」と「Igeogram 2.0」のAPI呼び出しは「HTTPリクエスト」ブロックを使用して、自前で用意する必要があります。

FLUX.1[pro](fal.ai)の場合
FLUX.1[pro]は、fal.aiが提供するAPIを利用して生成することにします。APIのドキュメントは以下のWebサイトにあります。
APIの仕様通り、「HTTPリクエスト」に画像生成に必要な設定を行います。事前にfal.aiでアカウント登録やクレジット購入、APIキーの取得などをしておく必要があります。

リクエストBodyには、画像生成の方法を、以下のようなJSON形式で指定します。
{
"prompt": "cat and dog",
"image_size": "square_hd",
"num_inference_steps": 28,
"seed": 0,
"guidance_scale": 3.5,
"num_images": 1,
"sync_modeboolean": true,
"safety_tolerance": "2"
}他にも、ReplicateなどがFLUX.1[pro]のAPIを提供していますが、ReplicateのAPIは、画像生成をリクエストした後、生成状況を確認・画像取得する2段階のプロセスが必要です。
現状のDifyでこのような処理を行うのは難しく、一応、実装はしてみましたが、かなりの力業なので、今回は紹介しないことにしておきます。
Ideogram 2.0の場合
IdeogramのAPIはベータ版とのことですが、ドキュメントは以下のWebサイトにあります。
ただし、APIキーを取得するために、事前に$40分のクレジットを購入する必要があるなど、気軽に試すにはちょっとハードルが高いです。
しかし、高精度な画像生成能力はかなり魅力的なので、最低、$40分は使うぞと自分に言い聞かせてw 購入しました。
APIの仕様通り、「HTTPリクエスト」に画像生成に必要な設定を行います。
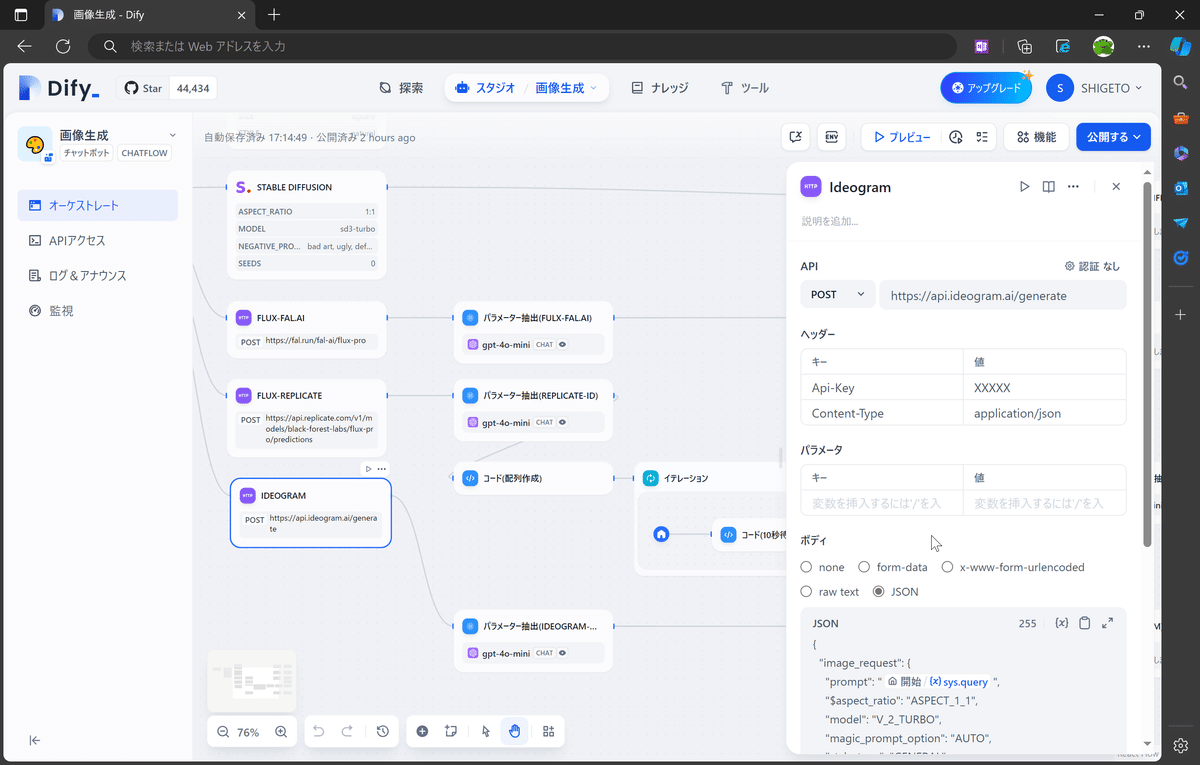
FLUX.1[pro]と同等、リクエストBodyには、画像生成の方法を、以下のようなJSON形式で指定します。
{
"image_request": {
"prompt": "cat and dog",
"aspect_ratio": "ASPECT_1_1",
"model": "V_2_TURBO",
"magic_prompt_option": "AUTO",
"style_type": "GENERAL",
"negative_prompt": "",
"resolution": "RESOLUTION_1024_1024"
}
}生成画像のインライン表示
標準で用意されている「DALL-E 3」や「Stable Diffusion 3」では、「回答」でブロックで出力変数「files」を回答として指定します。
今回、自前で作成した「FLUX.1[pro]」や「Ideogram 2.0」では、生成する画像を一つに限定しているので、HTTPリクエストの結果取得した生成画像のURLを、「回答」ブロックで以下のように指定すると、Webアプリ上でインライン表示できます。
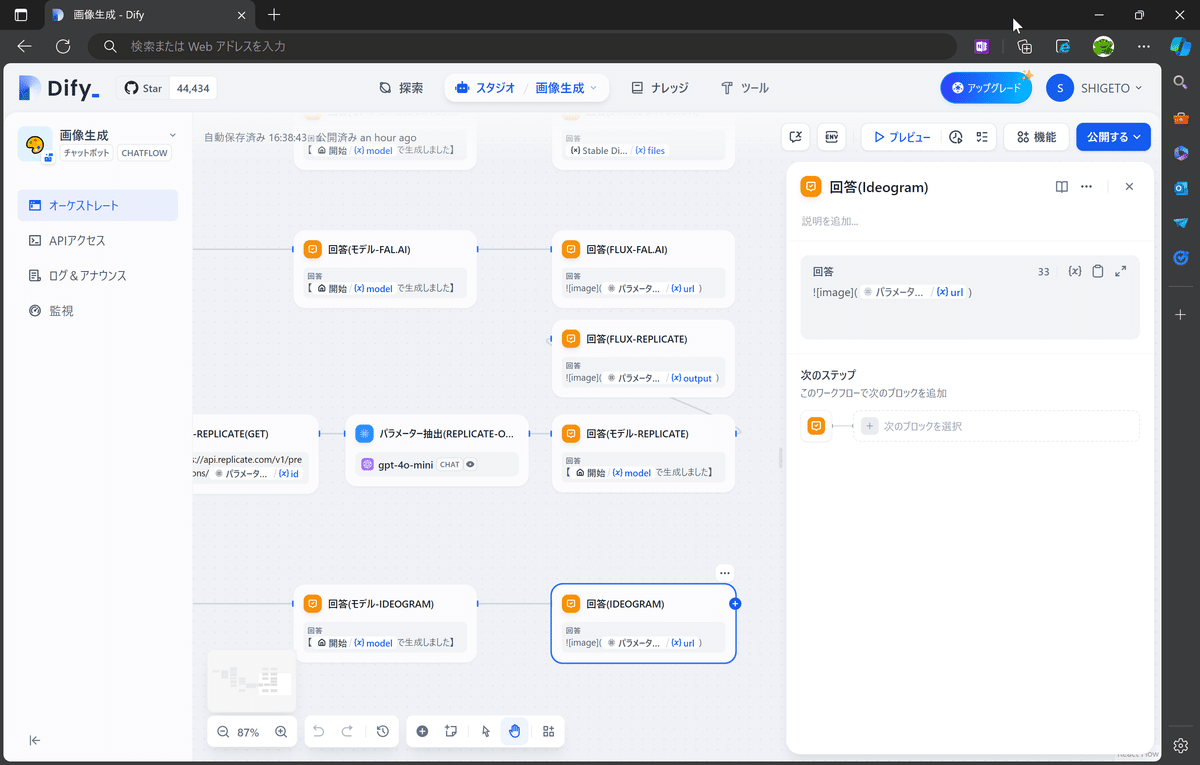
2024年10月20日追記
この方法は、Dify v0.9.2 以降では使えなくなってしまったので、インラインで画像を表示させるには、以下の方法などに変更する必要があります。
Webアプリの完成・実行
Webアプリとして公開し、実行したところです。会話の初めに、使用する画像生成モデルを選択するようにしました。

前回のマルチLLMチャットボットと同様、画像生成を繰り返しているうちに、今、どのモデルで画像生成をしているのかわからなくなってしまうので、回答の先頭に【Stable Diffusin 3 Turboで生成しました】のような文字列を追加するようにしています。
そして、生成画像はWebアプリ上でインライン表示されています。

生成画像をクリックすると、以下のように拡大表示されます。

まとめ
各画像生成AIのWebサイトのように細かい設定はできませんが(ワークフロー中で、「HTTPリクエスト」Bodyを都度修正すれば可能)、複数の画像生成AIでサクッと画像生成ができるので便利です。