
gasでWebスクレイピングを行い、スプレッドシートと連携する方法を解説

はじめに
皆さん、スクレイピングという言葉を聞いたことがありますか?スクレイピングを使えるようになると、ECサイトから最新の情報を引き出したり、自動でWebブラウザに入力したりできるなど、非常に便利です。しかし便利な一面がある一方で、使い方を間違えると違法性が生じることもあるため、注意が必要です。今回は、スクレイピングの注意点や方法についてお話ししたいと思います。
スクレイピングとは
スクレイピングとは、ウェブサイトから自動的にデータを収集する技術や手法のことです。具体的には、プログラムを使用してウェブページのHTML構造を解析し、必要な情報を抽出することを指します。
スクレイピングをする上での注意事項
スクレイピングはとても便利なものですが、Webサイトによってはスクレイピングを禁止していたり、法的な問題が発生する可能性があるので注意が必要です。
スクレイピングを行う際には、以下の注意事項を考慮することが重要です。
1. 利用規約の確認
ウェブサイトの規約: スクレイピングを行う前に、対象のウェブサイトの利用規約を必ず確認しましょう。多くのサイトでは、スクレイピングを禁止している場合があります。
2. 法的リスク
著作権: 収集したデータが著作権で保護されている場合、無断で使用すると法的問題が生じる可能性があります。
プライバシー: 個人情報を含むデータを収集する際は、プライバシー法に注意が必要です。
3. 技術的な配慮
サーバーへの負荷: 短時間に大量のリクエストを送ると、対象のサーバーに負担がかかり、サービスに影響を及ぼすことがあります。適切な間隔を設けてリクエストすることが大切です。
Robots.txtの確認: ウェブサイトのルートディレクトリにあるrobots.txtファイルを確認し、スクレイピングが許可されているかをチェックします。
4. データの正確性
情報の信頼性: スクレイピングしたデータが古い、または不正確である場合があります。データの出所と更新頻度を確認することが重要です。
5. 倫理的な考慮
公平性: 他のユーザーやサービスに影響を与えないように、倫理的な観点からも配慮が必要です。
6. 技術的な対策
IPブロックのリスク: 大量のリクエストを送信すると、IPアドレスがブロックされることがあります。プロキシを利用するなどの対策を考えましょう。
CAPTCHAの回避: 一部のサイトでは、スクレイピングを防ぐためにCAPTCHAが導入されています。これを回避するための手法は、合法性や倫理性の観点から注意が必要です。
詳しくは、スクレイピングの違法パターンについて詳しく解説しているサイトがありましたので、こちらをご覧ください。
スクレイピングの方法2選
今回は入門編として、『Webサイトからデータを取得して保存する』ことを前提に、スクレイピングの解説をしていきます。
Webサイトからデータを取得するには大きく二つの方法があります。
1. 正規表現を使う方法
正規表現を用いてHTMLソースコードから必要なデータを抽出する方法です。特定のパターンにマッチする文字列を検索することで、必要な情報を取得します。
メリット
シンプル: 簡単なデータ抽出には手軽で、特別なライブラリを必要としません。
柔軟性: 正規表現を使うことで、特定のパターンを自由に定義できるため、カスタマイズが容易です。
デメリット
メンテナンス性: HTML構造が変更されると正規表現も修正が必要になり、保守が大変です。
複雑なHTMLには不向き: ネストされた構造や複雑なHTMLでは、正規表現が非常に難しくなり、信頼性が低下します。
2. Cheerioライブラリを使う方法
Cheerioは、jQueryに似たAPIを持つNode.js用のライブラリです。HTMLをDOMとして解析し、簡単にデータを取得できます。
メリット
使いやすさ: jQueryのような文法で、直感的にHTMLを操作できるため、学習コストが低いです。
安定性: DOMの構造を理解しているため、HTMLの変化に対しても比較的耐性があります。
デメリット
パフォーマンス: 大量のデータを処理する場合、正規表現に比べて速度が遅くなることがあります。
Node.js環境の必要: Cheerioを使用するにはNode.jsの環境が必要であり、セットアップが必要です。
※今回この記事ではGASを使ってスクレイピングをしていきますが、GASデモCheerioは使用できます。
プログラムコードと実行方法
今回は例として弊社、電巧社のHPからのスクレイピングを例として解説していきます。他のサイトでも良かったのですが、記事として公開するにはリスクがあるため電巧社HPを例とさせていただきました。
https://de-denkosha.co.jp/product/cyber-sec/colortokens/
正規表現を使う方法
最初に正規表現を使う方法について解説していきます。ソースコードは以下になります。
ソースコード
function scrapeMicroSegmentationInfo() {
// スプレッドシートのIDとシート名
const sheetId = 'あなたのスプレッドシートのID'; // スプレッドシートのIDを入力してください
const sheetName = 'スクレイピング'; // 必要に応じてシート名を変更してください
// スプレッドシートを開く
const sheet = SpreadsheetApp.openById(sheetId).getSheetByName(sheetName);
// スクレイピング対象のURL
const url = 'https://de-denkosha.co.jp/product/cyber-sec/colortokens/';
const response = UrlFetchApp.fetch(url);
const html = response.getContentText();
// "マイクロセグメンテーション"を含む<p>要素を抽出
const regex = /<p>(.*?)マイクロセグメンテーション(.*?)<\/p>/g;
let matches;
const descriptions = [];
// マッチするすべての<p>要素を探す
while ((matches = regex.exec(html)) !== null) {
const description = matches[0].replace(/<p>|<\/p>/g, ''); // <p>タグを取り除く
descriptions.push(description.trim());
}
if (descriptions.length > 0) {
// スプレッドシートに書き込む
descriptions.forEach(desc => {
sheet.appendRow([desc.replace(/<br\s*\/?>/g, '\n')]);
});
} else {
Logger.log('マイクロセグメンテーションを含む説明が見つかりませんでした。');
}
}
sheetIdは、ご自身のスプレッドシートのIDに書き換えてください。
実行方法やIDの確認方法がわからないという方は、過去記事にて執筆しているのでそちらをご確認ください。
※GAS側構築準備からご確認ください。
ポイントは
const regex = /<p>(.*?)マイクロセグメンテーション(.*?)<\/p>/g;の部分です。こちらの部分で正規表現を利用して取得する記事を絞り込みます。
この正規表現は、HTMLの段落(<p>タグ)内に「マイクロセグメンテーション」という文字列を含む内容を抽出するためのものです。
正規表現の解説
const regex = /<p>(.*?)マイクロセグメンテーション(.*?)<\\/p>/g;<p>: 開始の段落タグを探します。
(.*?):
.*?は、任意の文字(改行を除く)を0回以上(できるだけ少なく)マッチさせることを意味します。
最初の(.*?)は、<p>タグの後に続く任意の内容をキャプチャします。
マイクロセグメンテーション: この文字列にマッチする必要があります。この部分が正規表現の中心的なターゲットです。
(.*?):
2つ目の(.*?)も、マイクロセグメンテーションの後に続く任意の内容をキャプチャします。
<\\\\/p>: 終了の段落タグを探します。スラッシュ(/)はエスケープされているため、正確に</p>として解釈されます。
gフラグ: このフラグはグローバル検索を意味し、文字列全体からすべてのマッチを探します。
前述しましたが、正規表現でプログラムを書くとWebサイトの構造が変わった時に、正規表現を変えなくてはいけないというデメリットがあります。
Cheerioライブラリを使う方法
次にCheerioライブラリを使う方法について解説していきます。ソースコードは以下になります。
ソースコード
function scrapeMicroSegmentationInfo() {
// スプレッドシートのIDとシート名
const sheetId = 'スプレッドシートのID'; // スプレッドシートのIDを入力してください
const sheetName = 'スクレイピング'; // 必要に応じてシート名を変更してください
// スプレッドシートを開く
const sheet = SpreadsheetApp.openById(sheetId).getSheetByName(sheetName);
// スクレイピング対象のURL
const url = 'https://de-denkosha.co.jp/product/cyber-sec/colortokens/';
const response = UrlFetchApp.fetch(url);
const html = response.getContentText();
// Cheerioを使ってHTMLをパース
const $ = Cheerio.load(html);
// マイクロセグメンテーションの説明を抽出
const description = $('h4:contains("マイクロセグメンテーション")').next('p').html();
if (description) {
// 改行を処理し、スプレッドシートに書き込む
const formattedDescription = description.replace(/<br\s*\/?>/g, '\n').trim();
sheet.appendRow([formattedDescription]);
} else {
Logger.log('マイクロセグメンテーションの説明が見つかりませんでした。');
}
}
こちらがCheerioライブラリを使った方法になります。
ただ、このままコードを張り付けて実行しても、Cheerioがインストールされていないのでエラーが出ます。ライブラリにCheerioをインストールする必要があります。
Cheerioのインストール方法
①ライブラリの+ボタンをクリックします。
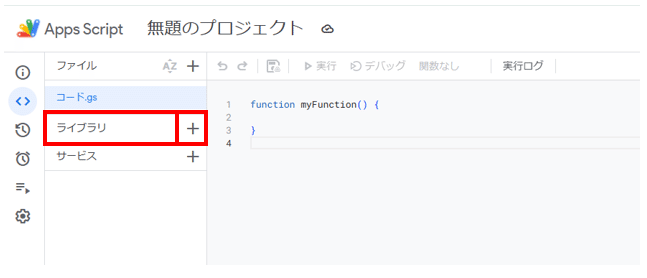
②IDを入力して検索をクリック→追加
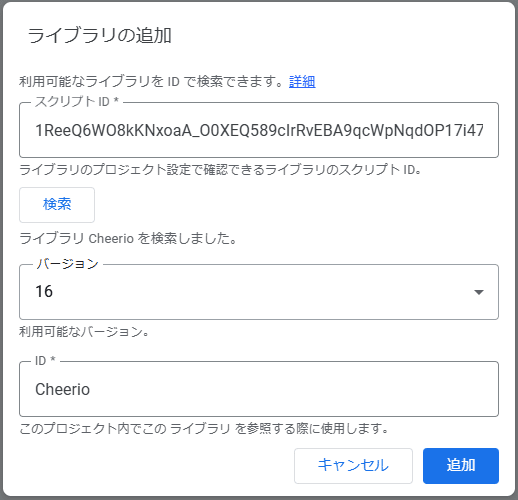
1ReeQ6WO8kKNxoaA_O0XEQ589cIrRvEBA9qcWpNqdOP17i47u6N9M5Xh0上記のIDを入力して検索、最新のバージョンを選んだら『追加』をクリックします。
③Cheerioがライブラリに追加されているか確認する
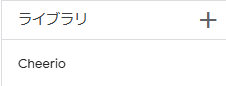
ライブラリに追加されていれば完了です。
後は先ほどのコードを実行してみてください。
ポイントは
const description = $('h4:contains("マイクロセグメンテーション")').next('p').html();$('h4:contains("マイクロセグメンテーション")'):
$('h4'): すべての<h4>タグを選択します。
:contains("マイクロセグメンテーション"): h4タグの中で、「マイクロセグメンテーション」というテキストを含む要素を選択します。この部分で、特定のテキストを含む<h4>タグをフィルタリングしています。
.next('p'):
このメソッドは、選択した<h4>タグの次にある兄弟要素の中から、最初の<p>タグを選択します。つまり、「マイクロセグメンテーション」を含む<h4>タグの直後にある<p>タグを取得します。
.html():
このメソッドは、選択した<p>タグの内部HTMLを取得します。これにより、<p>タグ内の内容が文字列として返されます。
まとめ
ここまで、スクレイピング(情報取得限定)の方法について解説しました。
今回はGoogle Apps Script(GAS)を使用しましたが、Pythonなどの他の言語でもスクレイピングは可能です。スクレイピングは情報を取得するだけでなく、ウェブサイト上のテキストボックスに書き込んだり、検索をかけたりすることもできます。
ただし、法律に抵触する可能性があるため、慎重に行動しましょう。
また機会がありましたら、スクレイピングに関する記事を再度お届けしたいと思います。
おしらせ
電巧社ではセキュリティ分野専門のブログも公開しています。ゼロトラストセキュリティを始めとした、ランサムウェアへの対処法等を紹介しています。こちらもよろしくお願いします。
↓↓ゼロトラストセキュリティ製品『Color Tokens』はこちらから!!↓↓
https://de-denkosha.co.jp/product/cyber-sec/colortokens/