
AWS Glue とは

AWS Glue とは
データの分類、クリーニング、加工を行う、
フルマネージドなETL(Extract(抽出)/Transform(変換)/Load(ロード))サービスです。

メリット
迅速なデータ統合
Glueで抽出、クリーニング、正規化、結合、読み込み、ワークフローの実行など行うことができ、
分析までにかかる時間を数ヶ月から数分に短縮できます
大規模なデータ統合を自動化
いくつものETLジョブを実行・管理ができ、
SQLを使用して複数のデータを結合できます。
サーバー管理が不要
フルマネージドサービスなのでサーバレス環境で実行できます。
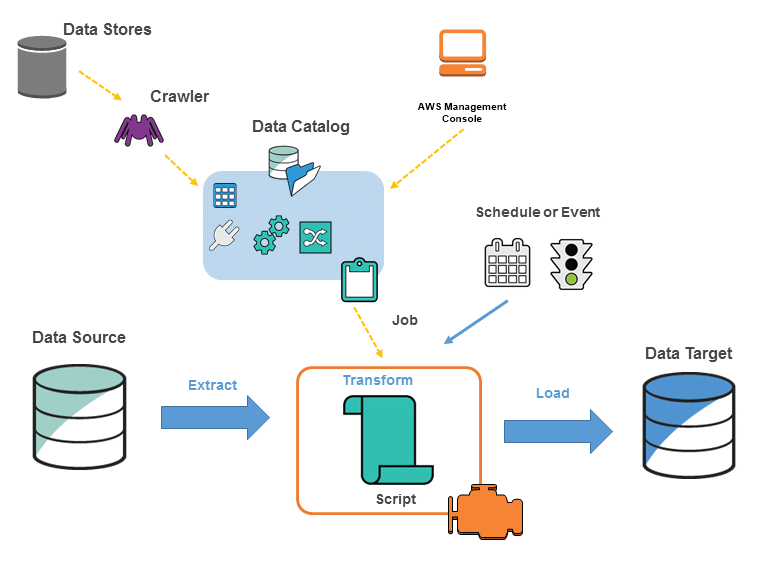
AWS Glue実行環境(構成要素)のイメージです。
目次
見出しを設定すると表示されます
閉じる
キャンセル一時保存公開設定
テキスト未選択のときにタブキーでメニューボタンへ移動できます
AWS Glue以下の流れでETLを実施します。
①データソースをクロールし、データカタログにメタデータテーブルを作成
②データカタログの情報を元にジョブを定義
③ジョブ定義に基づいてETLの雛形コードが自動生成
④ジョブ実行で、データソースからデータを抽出し、変換してデータターゲットにロード
用語
データストア
s3やDynamoDB,RDS等
データソース
Glueに入力するためのデータストア
データターゲット
Glueに出力するためのデータストア
データカタログ
データを分析するための領域
クローラー
いろんなデータストアからデータカタログにデータを集約する
ジョブ
データカタログ内でデータをELTジョブを実施する
以下のようなコードをご参考してください。
# AWS Glue ETL Code
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
## Crawl the data source
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "my_database", table_name = "my_table", transformation_ctx = "datasource0")
## Apply any transformation
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("col1", "string", "col1", "string"), ("col2", "string", "col2", "string"), ("col3", "string", "col3", "string")], transformation_ctx = "applymapping1")
## Load the data into the data target
datasink2 = glueContext.write_dynamic_frame.from_options(frame = applymapping1, connection_type = "s3", connection_options = {"path": "s3://my_bucket/"}, format = "parquet", transformation_ctx = "datasink2")
job.commit()