
BigQuery ML

BigQueryを使用してMLモデルを作成する方法を紹介します。具体的には、BigQueryデータセットを作成し、ロジスティック回帰モデルを構築し、評価する手順を説明します。
BigQueryデータセットの作成
まず、MLモデルを保存するためのBigQueryデータセットを作成します。
Google Cloudコンソールにログインし、[BigQuery]ページに移動します。
エクスプローラペインでプロジェクト名をクリックします。
「アクションを表示」 > [データセットを作成]をクリックします。
データセットIDを入力し、[データセットを作成]をクリックします。
ロジスティック回帰モデルの作成
次に、Googleアナリティクスのサンプルデータセットを使用して、ロジスティック回帰モデルを作成します。
クエリエディタで以下のSQLステートメントを実行します。これにより、モデルが顧客の取引確率を予測するためのデータを取得し、モデルを作成します。
CREATE OR REPLACE MODEL `[データセットID].[モデル名]`
OPTIONS(model_type='logistic_reg') AS
SELECT
IF(totals.transactions IS NULL, 0, 1) AS label,
IFNULL(device.operatingSystem, "") AS os,
device.isMobile AS is_mobile,
IFNULL(geoNetwork.country, "") AS country,
IFNULL(totals.pageviews, 0) AS pageviews
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_TABLE_SUFFIX BETWEEN '20170701' AND '20170801'エリが完了するまでに数分かかります。最初のイテレーションが完了すると、モデル(sample_model)がナビゲーション パネルに表示されます。
構文についての解説を少しします。
ステートメントの詳細
CREATE OR REPLACE MODEL: 既存のモデルがある場合は置き換え、新しいモデルを作成します。
OPTIONS(model_type='logistic_reg'): モデルの種類をロジスティック回帰(logistic_reg)に指定しています。これは二値分類や多クラス分類に使用されます。
SELECT: モデルのトレーニングデータを指定します。以下のカラムを取得しています。
label: 取引がある場合は1、ない場合は0に設定。
os: 訪問者のデバイスのOS。
is_mobile: モバイルデバイスかどうか。
country: 訪問者の国。
pageviews: ページビュー数。
このクエリにより、2017年7月1日から2017年8月1日までのデータを使用してモデルを作成します。
注意:
CSVファイルを導入するときに、FROM `[プロジェクトID].[データセットID].[テーブル名]`と変更し、SELECTを適切に変更してください。
モデルの評価
モデルが作成されたら、次にその精度を評価します。以下のSQLステートメントを実行します。
SELECT *
FROM ML.EVALUATE(MODEL `[データセットID].[モデル名]`, (
SELECT
IF(totals.transactions IS NULL, 0, 1) AS label,
IFNULL(device.operatingSystem, "") AS os,
device.isMobile AS is_mobile,
IFNULL(geoNetwork.country, "") AS country,
IFNULL(totals.pageviews, 0) AS pageviews
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_TABLE_SUFFIX BETWEEN '20170701' AND '20170801'
))実行結果
precision recall accuracy f1_score log_loss roc_auc
0.468503937007874 0.11080074487895716 0.98534315834767638 0.17921686746987953 0.046242211011772581 0.98174725274725272指標の説明
Precision (適合率): 予測が正しいと判断された正のサンプルの割合です。0.4685という値は、モデルが予測した「取引がある」とするサンプルのうち、約47%が実際に取引があったことを示します。
Recall (再現率): 実際に正のサンプルのうち、モデルが正しく予測した割合です。0.1108という値は、実際に取引があったサンプルのうち、約11%をモデルが正しく予測したことを示します。
Accuracy (正確度): 全体のサンプルのうち、正しく予測されたサンプルの割合です。0.9853という高い値は、全体の約98.5%のサンプルが正しく予測されたことを示します。
F1 Score: PrecisionとRecallの調和平均です。0.1792という値は、PrecisionとRecallのバランスを考慮したモデルの性能を示します。
Log Loss: モデルの予測の不確実性を測る指標です。0.0462という低い値は、モデルの予測が比較的確実であることを示します。
ROC AUC: 受信者操作特性曲線の下の面積を表し、モデルの分類性能を示します。0.9817という高い値は、モデルが優れた分類性能を持っていることを示します。
予測の実行
最後に、各ユーザーの予測購入数を計算し、上位10人を表示するようにしてみよう。
以下のSQLステートメントを実行します。
SELECT
fullVisitorId,
SUM(predicted_label) AS total_predicted_purchases
FROM
ML.PREDICT(MODEL `[データセットID].[モデル名]`, (
SELECT
IFNULL(device.operatingSystem, "") AS os,
device.isMobile AS is_mobile,
IFNULL(totals.pageviews, 0) AS pageviews,
IFNULL(geoNetwork.country, "") AS country,
fullVisitorId
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_*`
WHERE
_TABLE_SUFFIX BETWEEN '20160701' AND '20170701'
))
GROUP BY
fullVisitorId,
os,
is_mobile,
country
ORDER BY
total_predicted_purchases DESC
LIMIT 10少し構文について解説すると
GROUP BY:
fullVisitorId, os, is_mobile, countryの各列でグループ化します。
各訪問者(fullVisitorId)ごとに、デバイスのOS、モバイルデバイスかどうか、訪問者の国ごとに集計されます。
ORDER BY:
total_predicted_purchasesを降順(DESC)で並べ替えます。
予測された購入数が多い順にデータが並びます。
LIMIT 10:
上位10件の結果を表示します。
結果
fullVisitorId total_predicted_purchases
1957458976293878100 18
0824839726118485274 10
1956307607572137989 8
8197879643797712877 8
9894955795481014038 7
3921649958751416379 7
9089132392240687728 6
7483600664917507409 6
7311242886083854158 6
9377429831454005466 6データの学習評価をは下図から確認できる。
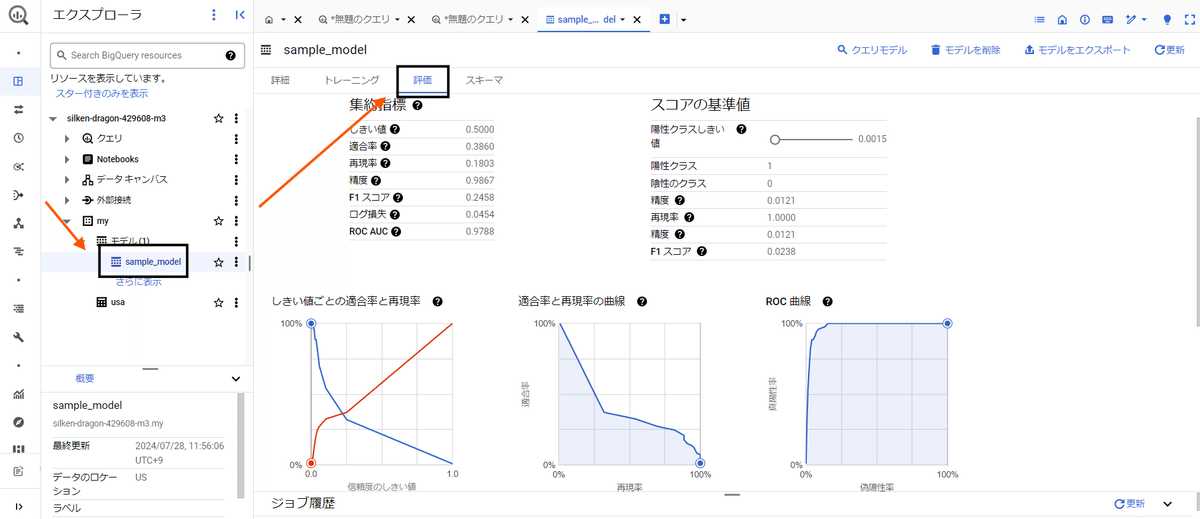
余談
今回はロジスティック回帰について執筆したが、BigQuery MLでは、ロジスティック回帰以外にも様々な機械学習モデルをサポートしています。
サポートされているモデル
線形回帰: 数値予測を行うためのモデルです。例えば、売上や気温の予測に使用されます。
ロジスティック回帰: 二値分類を行うモデルで、特定のイベントが発生する確率を予測します。
K 平均法クラスタリング: データをクラスタに分けるためのモデルで、顧客セグメンテーションなどに利用されます。
行列分解: レコメンデーションシステムなどで使用されるモデルです。
時系列予測: 時系列データを基に未来の値を予測するモデルです。
ブーストツリー(XGBoost): 高精度な分類および回帰を行うためのモデルです。
ディープニューラルネットワーク(DNN): 複雑なパターンを学習するためのモデルです.
これらのモデルを使用することで、様々なビジネスニーズに対応することができます。例えば、売上予測、顧客の分類、異常検知など、多岐にわたる用途に活用できるだろう。