
Core ML版 Llama 2 7B と Falcon 7B をiOS/macOSオンデバイスで動かしてみた

Hugging Faceの以下のブログ記事が大変おもしろかった。
ざっくりいうと「LLMモデルをCore ML化する際に自前でcoremltoolsでやると非常に大変なので、そのへんをいい感じにやるツールを公開しました」という内容の記事なのだけど、
"Released Today" に
Some converted models, such as Llama 2 7B or Falcon 7B, ready for use with these text generation tools.
とあり、既にCore MLに変換済みのLLMモデルが公開されている。
変換ツールも試してみたいがまずは公開済みのモデルを動かしてみよう、ということでそれらをiOS / macOSで動かしてみた。
モデルのダウンロード
以下から .mlpackage をダウンロードする。
Llama 2 7B
Falcon 7B
それぞれ 13.48GB, 27.69GB もある。既に不穏な感じしかしない…
結果から
iOSで動かしてみる(iPhone 15 Pro)
モデルをロードしはじめたところからグングンと使用メモリ量がアップし、
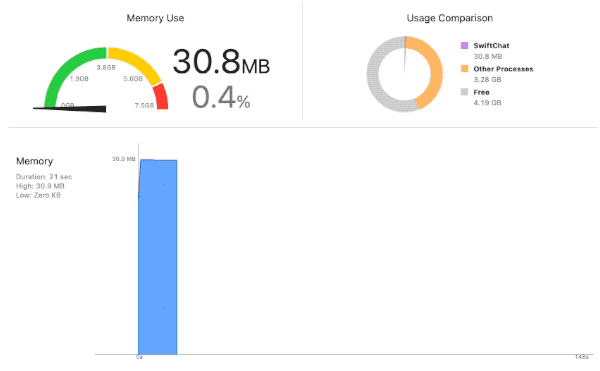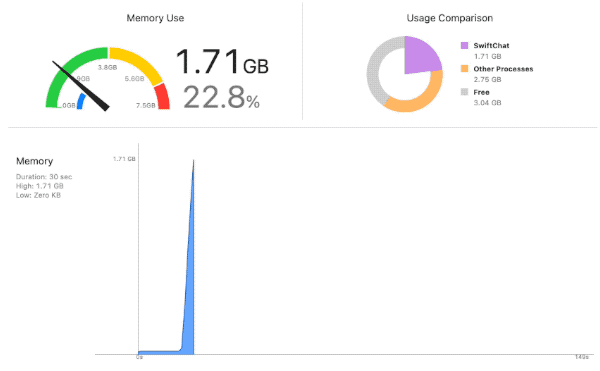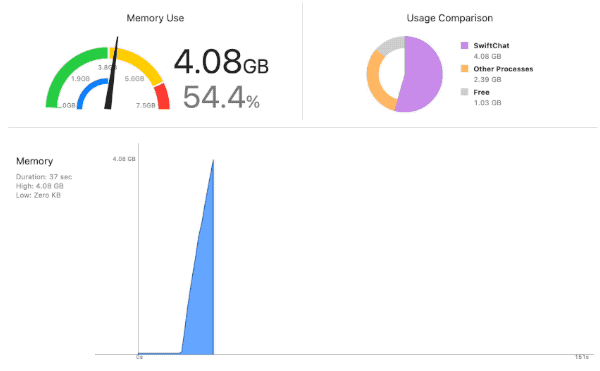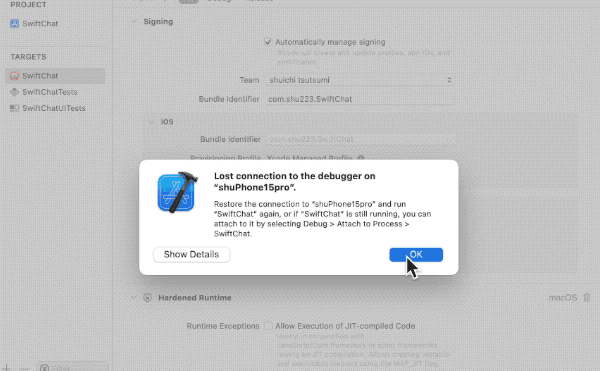
4GBを超えたあたりでクラッシュ。
小さい方の llama-2-7b-chat.mlpackage でこれ。
さらに倍もある falcon-7b-64-float32.mlpackage でも当然クラッシュ。
macOSで動かしてみる(MBP M1 Max / メモリ64GB)
無事動いた:

Llama 2の方の使用メモリ量はピークで11GB。4.56 tokens/s。
Falconの方は使用メモリ量が40GB近くに達した。

推論処理も重かった。1.01 tokens/s。

動かし方

最後まで読んでいただきありがとうございます!もし参考になる部分があれば、スキを押していただけると励みになります。 Twitterもフォローしていただけたら嬉しいです。 https://twitter.com/shu223/