RISC-V シミュレーター · 01 Adder (加算器)

これは、数年前に私が書いた RISC-V シミュレーターのチュートリアルです。私自身の日本語学習の目的で、ChatGPT を使って日本語に翻訳し、編集を加えました。自分にとっても他の人にとっても有益であることを願っています。原項目はこれです。
CPUは中央処理装置(Center Process Unit)を指し、小さなチップです。それはコンピュータ(computer)の最も核心的な部分です。
ただし、簡単にするために、第一章でのCPUはコンピュータ全体を指しています。これには、32個の汎用レジスタ、PCレジスタ1つ、そしてメモリが含まれています。次の章では、メモリをCPUから分離します。
この章は、原作者の第一章「CPU with Two instructions」に対応しています。この章のCPUは、add と addi の2つの命令しか実行できません。
1. 基本的 CPU
まず、CPU の構造を定義します。それは 64 ビットの PC、32 個の 64 ビットの汎用整数レジスタ、および u8 ベクターで表されるメモリを含みます。
//main.rs
struct Cpu {
// RISC-V has 32 registers
regs: [u64; 32],
// pc register contains the memory address of next instruction
pc: u64,
// memory, a byte-array. There is no memory in real CPU.
dram: Vec<u8>,
}CPU を初期化するためにはメモリのサイズを定義する必要があります。これは、スタックポインタ(SP)がスタックの頂点(メモリの最高アドレス)を指すためです。同時に、PC を 0 に設定します。これは、プログラムがメモリアドレス 0 から実行を開始することを意味します。
//main.rs
// init memory as 128MB
pub const DRAM_SIZE: u64 = 1024 * 1024 * 128;
struct Cpu { ... }
impl Cpu {
fn new(code: Vec<u8>) -> Self {
let mut regs = [0; 32];
regs[2] = DRAM_SIZE - 1;
Self {regs, pc: 0, dram: code}
}
}2. CPU のパイプライン
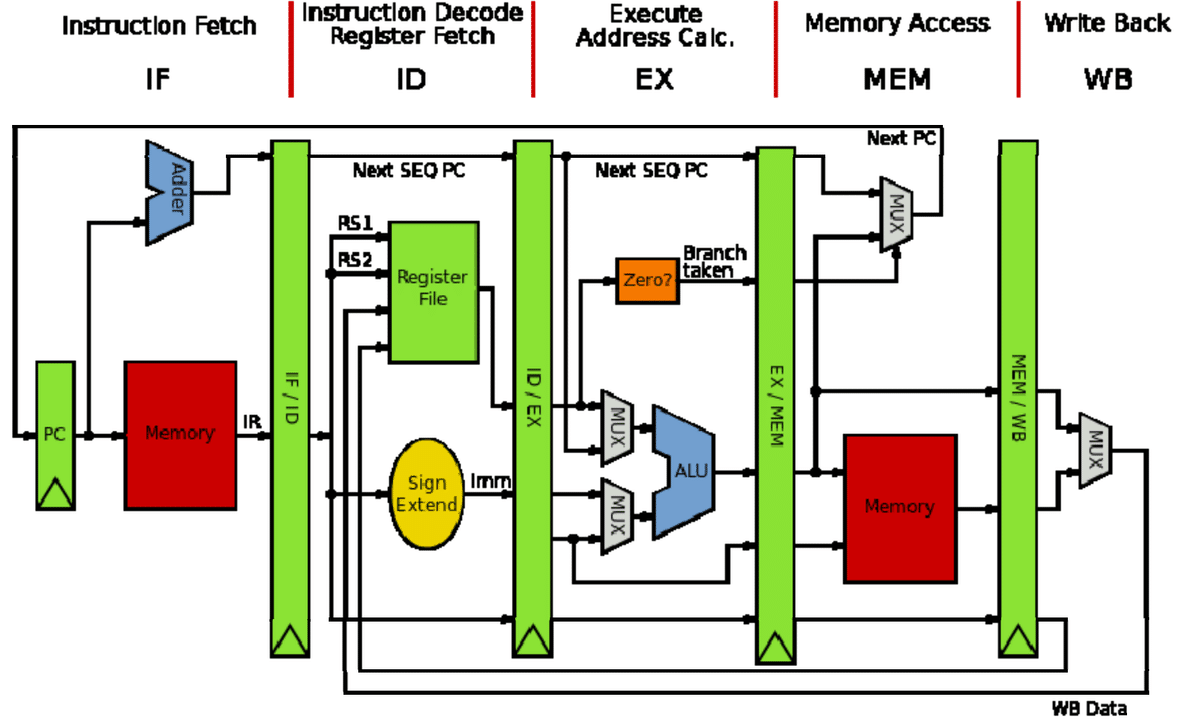
現代の CPU は、その作業を複数のサブプロセスに分割することで、スループットとパフォーマンスを向上させています。クラシックな MIPS パイプラインアーキテクチャは、以下の5つの部分で構成されています。
フェッチ :PC の値に基づいてメモリから命令を読み取ります。
デコード :命令を解読します。
実行 :命令を実行します。
メモリアクセス :結果をメモリに書き戻します。
ライトバック :計算結果(新しい PC の値を含む)をレジスタに書き戻します。
このプロセスは繰り返されます。
3. 命令の取得
まず、命令の取得(フェッチ)の実装から始めます。
//main.rs
impl Cpu {
// ...
fn fetch(&self) -> u32 {
let index = self.pc as usize;
let inst = self.dram[index] as u32
| ((self.dram[index + 1] as u32) << 8)
| ((self.dram[index + 2] as u32) << 16)
| ((self.dram[index + 3] as u32) << 24);
return inst;
}
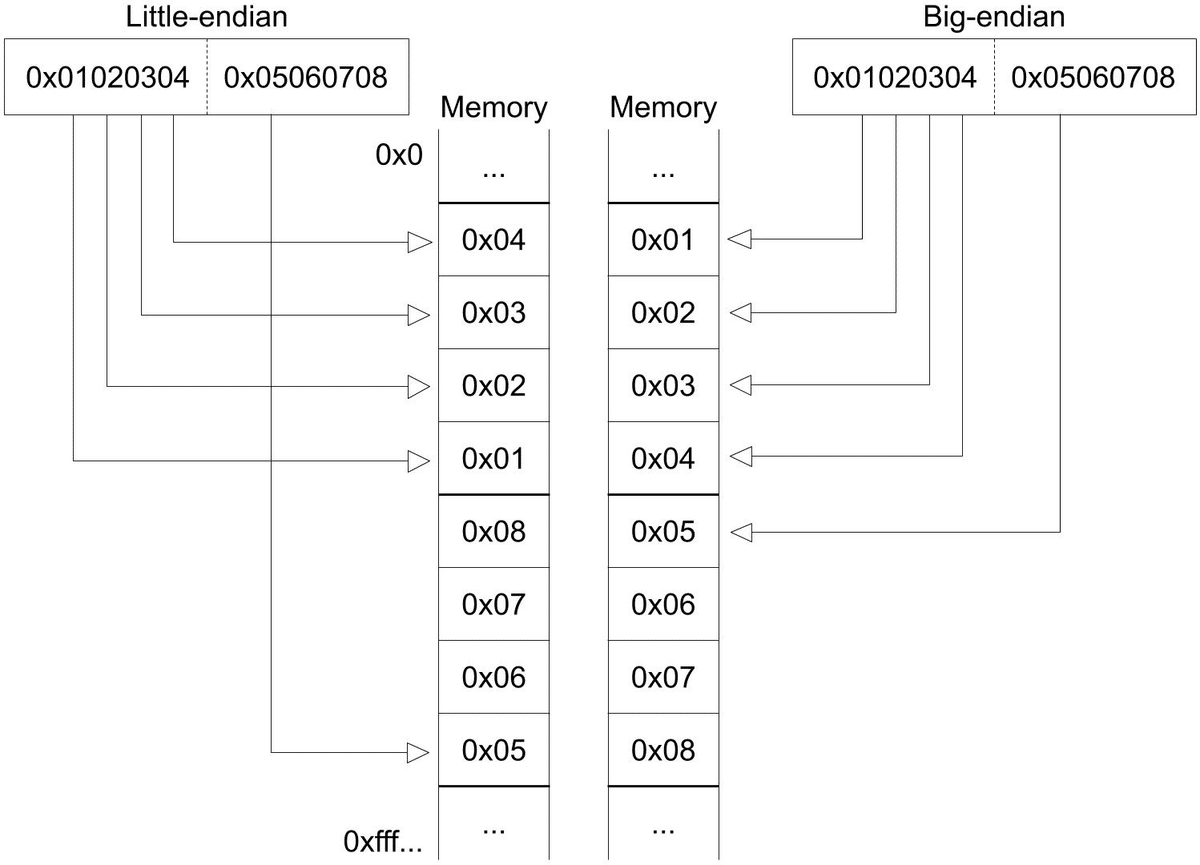
}CPU は PC の値をメモリに送信し、メモリは対応するアドレス上の値を返します。RISC-V の命令は 32 ビットであるため、メモリが読み取るのは [PC, PC+1, PC+2, PC+3] の4つのアドレス上の値で、これらを組み合わせて 32 ビットの命令を形成します。ここで、ビッグエンディアン (big-endian) とリトルエンディアン (little-endian) の問題が関係します。
リトルエンディアンとは、複数のバイトで構成される数値のうち、最下位のバイトがメモリの低いアドレスに、最上位のバイトが高いアドレスに格納される方式を指します。ビッグエンディアンはその逆です。
本実装では、リトルエンディアンを採用しています。RISC-V の標準では、命令の読み取りはリトルエンディアンですが、メモリの読み込みと保存(メモリのロードとストア)は、mstatus レジスタ上の特定のビットを設定することでバイトオーダーを制御することが可能です。
4. 命令のデコード
命令を読み取った後はデコードを行う必要があります。実際のハードウェアでは、デコードは独立したステップであり、チップは複数の命令を同時に読み取り、デコードすることで(パイプライン並列処理)実行速度を向上させます。しかし、私たちのシミュレーターでは、一度に1つの命令しか読み取らないため、この2つの部分をまとめることができます。
まずはデコードのプロセスを見てみましょう。RISC-V には現在、基本的な命令エンコーディング形式が4種類あり(バリエーションを含めると6種類)

現在の CPU は add と addi だけを実行します。それらの機能の説明と命令形式は以下の通りです。

RISC-V の設計者は、ハードウェアの簡素化を考慮して、すべての命令を統一の 32 ビット長に設計しました。レジスタのエンコーディングも可能な限り同じ位置に配置されており、これは即値が複数の部分に分割されてエンコードされる理由でもあります。
各命令形式には共通部分があるため、まずは R 型 (R-type) に従ってデコードを行いましょう。他の形式については、その特定の分岐でさらにデコードを行います。例えば、addi の即値 (imm) は、その処理分岐内でデコードされます。
// main.rs
impl Cpu {
// ...
fn execute(&mut self, inst: u32) {
// decode as R-type
let opcode = inst & 0x7f;
let rd = ((inst >> 7) & 0x1f) as usize;
let rs1 = ((inst >> 15) & 0x1f) as usize;
let rs2 = ((inst >> 20) & 0x1f) as usize;
let funct3 = (inst >> 12) & 0x7;
let funct7 = (inst >> 25) & 0x7f;
// x0 is hardwired zero
self.regs[0] = 0;
// execute stage
match opcode {
0x13 => {
// addi
let imm = ((inst & 0xfff0_0000) as i32 as i64 >> 20) as u64;
self.regs[rd] = self.regs[rs1].wrapping_add(imm);
}
0x33 => {
// add
self.regs[rd] = self.regs[rs1].wrapping_add(self.regs[rs2]);
}
_ => {
dbg!(format!("Invalid opcode: {:#x}", opcode));
}
}
}
}ここで、wrapping_add を使用する理由は、これらの命令が算術オーバーフロー (arithmetic overflow) エラーを無視するためです。オーバーフローしたビットは直接破棄されます(上記の命令に関する説明を参照してください)。
CPU の機能は基本的に完成しました。しかし、CPU が命令を正しく実行しているかどうかを検証するために、レジスタの状態を簡単に確認できるようにする必要があります
//main.rs
const RVABI: [&str; 32] = [
"zero", "ra", "sp", "gp", "tp", "t0", "t1", "t2",
"s0", "s1", "a0", "a1", "a2", "a3", "a4", "a5",
"a6", "a7", "s2", "s3", "s4", "s5", "s6", "s7",
"s8", "s9", "s10", "s11", "t3", "t4", "t5", "t6",
];
impl Cpu {
// ...
pub fn dump_registers(&mut self) {
println!("{:-^80}", "registers");
let mut output = String::new();
self.regs[0] = 0;
for i in (0..32).step_by(4) {
let i0 = format!("x{}", i);
let i1 = format!("x{}", i + 1);
let i2 = format!("x{}", i + 2);
let i3 = format!("x{}", i + 3);
let line = format!(
"{:3}({:^4}) = {:<#18x} {:3}({:^4}) = {:<#18x} {:3}({:^4}) = {:<#18x} {:3}({:^4}) = {:<#18x}\n",
i0, RVABI[i], self.regs[i],
i1, RVABI[i + 1], self.regs[i + 1],
i2, RVABI[i + 2], self.regs[i + 2],
i3, RVABI[i + 3], self.regs[i + 3],
);
output = output + &line;
}
println!("{}", output);
}
}5. テスト
私たちは、RISC-V バイナリファイルを実行することで、実装の検証を行います。
まず、add-addi.s を作成し、以下の内容を書き込みます。
addi x29, x0, 5
addi x30, x0, 37
add x31, x30, x29RISC-V バイナリファイルを生成します。
clang -Wl,-Ttext=0x0 -nostdlib --target=riscv64 -march=rv64g -mno-relax -o add-addi add-addi.s
llvm-objcopy -O binary add-addi add-addi.bin同時に、シミュレーターは add-addi.bin の内容を読み取り、CPU のインスタンスを初期化する必要があります。CPU は各命令を順番に読み取り、実行し、最終的にレジスタの状態を出力します。
//main.rs
use std::env;
use std::fs::File;
use std::io;
use std::io::prelude::*;
// ...
fn main() -> io::Result<()> {
let args: Vec<String> = env::args().collect();
if args.len() != 2 {
println!(
"Usage:\n\
- cargo run <filename>"
);
return Ok(());
}
let mut file = File::open(&args[1])?;
let mut code = Vec::new();
file.read_to_end(&mut code)?;
let mut cpu = Cpu::new(code);
while cpu.pc < cpu.dram.len() as u64 {
let inst = cpu.fetch();
cpu.execute(inst);
cpu.pc += 4;
}
cpu.dump_registers();
Ok(())
}以下のコマンドを実行すると、コンソールの出力から x31 の値が 0x2a であることが確認できるはずです。
cargo run add-addi.bin6. 結論
私たちは、2つの RISC-V 命令(addi と add)を実行できる加算器 CPU を実装しました。また、CPU の実行ステップである「命令の取得」「デコード」「実行」「PC の更新」を学びました。次の章では、メモリを CPU から分離し、さらに多くの命令のサポートとテストフレームワークを追加します。