
自動 AI 研究パイプライン

はじめに
初めまして、高木と申します。私は研究ができる AI の実現を目指していて、特にその中でも AI の研究ができる AI の実現を目指しています。
この目標に向けて色々試行錯誤してきましたが、もっともっと加速させていきたいと考えた結果、 AI 研究の自動化というのはどんな感じか、それに対してどんな課題がありそうかなどをちゃんとどこかに言語化しておくのが重要だろうという考えに至りました。それもあって最近 canva でお気持ち表明のスライドを作って公開しました。

ただこの資料だけだとよくわからないかない気もしていて、もう少し細かく文章で書いたやつも必要かなと思いました。そこで、これから何本か自分が考えてみたことややってみたことについての諸々を簡単にまとめた note を書いていこうかなと思っています。今回はとりあえずその中の一部、自動研究したいって結局何したいのか、試しにやってみたごく簡単な例、そこから感じた課題、などを書いていこうと思っています。
自動研究の意味するところ
研究する
研究が自律的にできる AI システムを作りたいと述べましたが、そもそも研究ができるとはどういうことでしょうか。色々な特徴づけ方ができると思いますが、私は暫定的に「研究とは新しい知識を生産する営み」であって、それは「問いの生成、問いに対する答えの予想(仮説)の生成、その仮説の検証、からなる過程」なのではないかと暫定的/作業的に考えることにしました(これについては 2023 年に個人的に考えてプレプリントをまとめたのでもしご関心があれば是非こちらも併せて読んでみてください:Takagi 2023)。
なので、問いを立て、仮説を立て、それを検証することがそれぞれ自律的にできたら、自律的に研究ができたととりあえず考える、ということにしています。もちろん研究はもっと複雑な過程なのでこれで十分ではないとは思いますが、作業的な定義としてとりあえずここから出発することにしました(定義に関する諸々については以下でも書きました)。
自律性
自律性が何かも諸説あると思いますが、私は「あるタスクを実行するときに人間による介入(直接の手助け、事前の設計)などが少ない状態のことを自律性が高いとする」ぐらいに暫定的にゆるく捉えています。
これまで研究の一部の過程を自動化する試みは数多くなされてきていますが、必ずしも全ての過程の自動化というわけではありませんでした。例えば、新しい薬品の候補を自動で提案するような試みはありますが、その薬品が確かに所望のものであることを確かめる検証は人間が行うことがほとんどだと思います。これはある意味で研究における仮説の生成部分の自動化だけど研究過程全体の自動化ではないといえるかなと思います。
また、仮説の生成を自動化するといってもそのためにどれだけ人間が介入するか、事前準備するか、デザインするかによって自動化にも程度があります。例えば、事前に有限の探索区間が陽に定義されている場合もあれば、もっと自由度が高いものもあります。これに関して、2050 年までにノーベル賞を受賞する AI の実現を目指す Nobel Turing Challenge を推進されてる方々が自律性の段階の枠組みを提案しています(Kitano 2021, Kramer et al. 2023)。理化学研究所で研究の自動化を推進されている高橋恒一先生がより具体的にこれを説明されてますが、この区分では、答えについての予測(仮説の生成)を人間が事前にどの程度デザインして探索空間を狭めるかで自律性の段階をレベル 1 からレベル 4 まで分けています。

例えば、探索空間が陽に与えられるのがレベル 1、探索範囲が与えられるのがレベル 2、仮説の形式が制限されるのがレベル 3、仮説の形式にさえ制約を入れないのがレベル 4 以降、といった具合です。
以上まとめると、研究の自動化における自律性については、 1. 研究のどの部分に(例えば仮説生成を自動化するのか検証も自動化するのか)、2. どの程度まで(例えば探索空間を所与とするのか自由に生成させるのか)、人間が介入するか/人間が設計をするか、という観点から自律性の程度を考えることができそうです。当然最初から完全に全てを自律的にできるものを作るのは現実的ではないので、研究過程のどの部分をどの程度どのようにして自動化していくか、そしてその制約をどのように外していくかを考えていくのが、実践としては重要な議論になってくるように思います。
自動研究の方針
最終的には可能な限り自律性が高くかつ高い質の研究ができるものを目指したいと思っています。しかしこの二つを同時に満たすものを目指すのはかなりの困難なので、どちらか片方から優先して自動化を進めていくというのが一般的だと思います。
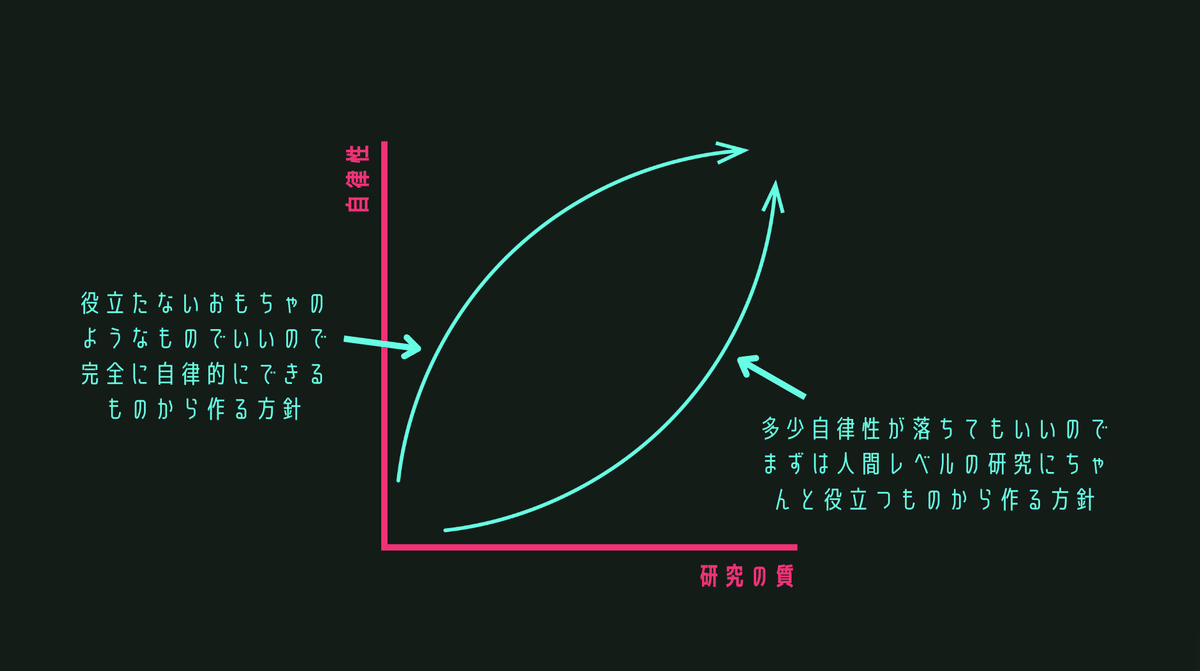
私の認識だと、別に全ての過程が自律的でなくてもいいので役に立つものを作る方向性の方が一般的だと思っています。特に何かを作るときにはある課題を解決したかったり何かの役に立つものを作ることを目指すことがほとんどだと思うので、これは当然と言えば当然です。しかし、例え簡単なものでもトイモデルでもいいので全過程を自動実行させようとすることで初めて見えてくる課題もあるはずです。
そこで私は、いったん簡単なおもちゃのようなものでもいいので、まずは研究過程の多くの部分を自動で実行できるようなおもちゃのプロトタイプを作ってみようと考えました。
自動 AI 研究パイプラインのトイプロトタイプ
この「簡単でもいいのでできるだけ多くの過程を自動実行できる機械学習研究パイプライン」というアイデアのプロトタイプを 2023 年の8月に作成しました(Takagi et al. 2023)。だいぶ前の話なのと研究として質が低いので紹介するのは恥ずかしいのですが、やりたいことと個人的に感じてる課題を説明するのに便利なのでこちらを紹介していきます。
プロトタイプの概要
このプロトタイプは一言で言えば「ある問題が与えられるとそれを解決するためのある解法のアイデアを生成して、そのアイデアの有効性を検証する python スクリプトを作成して、それを実行して検証結果を報告する」ことを全自動で実行するシステムのプロトタイプです。研究過程を複数の部分過程に分割しており、各部分過程は特定の指示を受けてタスクを実行する LLM です。一応参考コードは GitHub にあげてます。

当然任意の研究を自動実行することは難しいので、研究対象をある程度絞る必要があります。私たちは特に「機械学習のプロンプト提案(例えば think step by step を追加するよう提案するなど)の研究であれば自動実行できたりしないかな…?」と考えて、このタイプの研究に誘導するような工夫をすることにしました。プロンプト提案の自動研究が容易そうだなと思った理由は、例えば仮説(提案手法)がテキスト数行で表現され数式などが必要ない、対照群に対して推論時にプロンプトを変更するだけなので訓練の必要がないなど検証の計画・実行が容易そう、など色々ありますがここでは割愛します。
その関係で、今回は問題は所与として問題の発見(問いの生成)は要請しないことにしました。これは問題まで発見させるとプロンプト提案で解けないような問題も出てきてしまうためです。問題としてはプロンプトエンジニアリングで対処できそうな問題を準備し、その問題がなぜ問題であるかを背景情報として丁寧に記述するようにしました。特に今回は「LLMの出力がフォーマットされてない出力を出すことが問題だ」という旨の極めて多純なトイプロブレムを問題として使用しました。
プロトタイプの特徴
このパイプラインで特に意識した点は以下の点です。
仮説の生成と仮説の検証を「どちらも」自動実行させること
仮説に対して陽に仮説探索空間を定めない/仮説の形式を決めないこと(誘導はするが)
検証の計画も特定の形式を事前に定めずに形式自由で計画させること
検証計画だけでなく検証の実行まで自動でやらせること
仮説の生成と仮説の検証を「どちらも」自動実行させる
まず一つ目の点ですが、仮説の生成と仮説の検証をどちらも自動でやらせるのはとても難しいことです。これは仮説に応じてどのような検証が適切かが大きく変わりうるからです。例えば、より早く収束する最適化アルゴリズムを提案したのであれば、何らかのモデルを何らかのデータ・タスクに対して学習して提案した最適化アルゴリズムを使用することで損失が何ステップほどでどれだけ減少するかを調べ、それを既存の手法を使った場合と比較することが「提案法が早く収束する」という仮説の経験的な検証になりうるでしょう。一方である LLM からその LLM に指示されたプロンプトを抜き出す方法を提案するのであれば、その手法を使ってある LLM から実際にそれに与えていたプロンプトが抜き出せているかを確認することが検証になるでしょう。
今回は問題は固定していますが、問題が変動すればこの点はより深刻になります。このように研究過程の上流の変動に対しても適切に適応して下流のタスクを実行できるということが自動研究において重要な要素の一つだと考えられます。その意味で仮説の生成と仮説の検証を同時に自動化することは難しいけれど重要なことです。
仮説生成と仮説検証を形式を指定せずにやらせる
次に仮説生成と仮説検証のそれぞれにおいて、その仮説が具体的にどのようなものであるか、検証がどのようなものであるかを指定しないという点についてです。上で述べたように陽に仮説空間を定めてその中の探索問題に落とし込んだり、実験に必要なパラメータのみを探索させたりということは以前から行われていましたが、人間は形式自由に仮説生成をすることができます。これをやらせたいという気持ちです。また今回は問題を与えていますが、問題まで自分で発見させるとなると形式自由で仮説生成ができることはほぼ必要と言っても良いくらい重要です。
今回具体的に仮説生成において行った指示は「仮説を複数出してください」「その中で最も検証が容易な仮説を選んでください」の二つのみです。


これはかなり広大な仮説の候補たちの中から仮説を出力させているという点で相当程度の自由度を許した指示だと思っています。このような自由な仮説生成に対して仮説検証が適切にできるのかというのが一つのポイントです。
仮説の検証においては、まずテキストで上記の仮説を検証するための検証計画を出力させ、それを python コードに変換するよう指示しています。検証が python コードで実行されることを想定するのは確かに一つの仮定です。しかし、複雑さの程度こそ違えど多くの機械学習の研究が python スクリプトを実行することで実験をしていることを考えるとそこまで強い制約ではないように思っています。
検証計画だけでなく検証の実行まで自動でやらせる
最後に自動実行するところまでやっているという点です。検証の計画を自動で実行するのを素朴にやろうとすると long-horizon な意思決定タスクになってかなり難しいです。特に今回の場合仮説がどうなるかわからないので検証がどのようなものになるか事前で想定することができず実験の準備ができないという難しさがあります。今回は検証計画を検証コードに変換さえてそれを実行するだけにしてる点でその難しさを一旦スキップしてますが、とりあえず簡単な形でいいので実行までやらせることに注意しました。
もちろんこれだけではうまくいかなかったので、一度生成された仮説を定式化させたり、実験コードが典型的に含みうるエラーを後処理で除外したりなどの工夫をしましたが、概要はこのような感じです。
結果
結果としては、あくまで昨年8月段階の話ではありますが、今回のようなかなり簡単なトイ問題でさえ完全に自律実行するのは難しそうだなという結論になりました。具体的には微妙に仮説のニュアンスを捉えきれておらず検証になってない検証を実行したりデータの代わりにそのプレイスホルダーだけ出してしまったり仮説検定を誤って使ったりといった問題が見られました。特に(これに関しては今回は期待してないので問題というかは微妙ですが)実験で使用されているデータがめちゃくちゃ簡単なトイデータを使用していたりベースラインが単純だったりという様子が見られ、人間レベルの実験コードを自動生成するためにはここを改善していく必要性を感じました。
ただ、そうはいうものの、提案された解法のほとんどはその問題を解くための解法としては適切でしたし、仮説の検証として完璧な検証計画を立てられていた場合もありましたし、仮説を読み違えていた場合もそこまで明らかにおかしいというものばかりではありませんでした。ここではとりあえず全て自動実行することを重視して雑にとりあえず作ったので、その意味で各過程を作り込んでいくことでより良いものができていくという期待感を持てる結果でもありました。
課題に関して
これは昨年やったものなので、多くの課題が現在の技術で克服されている、される可能性があると思っています。これらの課題についていくつか模索している改善の方向性があるので、その中の一部を紹介します。
データとベースラインが簡単すぎるという課題について
まず上記の試みの課題の一つとして上がったのが、生成される実験コードが人間の研究で実際に使われるそれに比べてあまりにも簡単すぎるという点でした。その中での一つの例として検証で使われるデータセットがトイデータセットに留まってしまっていることを述べました。多くの機械学習研究において研究レベルのコードを生成するためには、検証内容に応じて適切にデータセットを使えることは重要です。
しかし、実際に人間がどのようにそれを実行しているかを考えると、思っているよりは複雑なタスクであることがあります。例えば、まず自分のやりたい実験に関連する先行研究がどのようなデータセットを使っているかを調べて確認し、見つけたデータセットを検索してダウンロードし、適切なディレクトリに移動して、データのカラム名などを確認しつつ、自分が実行したいコードで使えるように調節をする、などをしなければなりません。
これも時間が解決する問題だとは思いますが、現段階ではまだ難しい課題です。この問題を緩和する上で役に立つと思っているのが、 prompt2model です(Viswanathan et al. 2023)。これはテキストで指示を与えるとデプロイ可能なレベルのモデルを学習してくれるという枠組みです。このフレームワークではテキストで指示を与えるだけでそれに適した事前学習済みモデルとデータセットを Hugging Face から自動取得し、使いやすい形に整形して用意してくれます。

これを用いることで、トイデータセットではなく実際に研究に使われるようなデータセットやモデルをしかもテキストによる指示で取得することができます。これはより人間の研究に近いコードを簡単に生成できる可能性を大いに高めてくれます。
個人的には Hugging Face を媒介しているのがこの枠組みの一つのポイントだと思っています。 Hugging Face 側がある程度形式を整えてくれているおかげで、形式の揺らぎをある程度無視することが可能になっています。例えば、データが全て csv 形式で保存されている、Hugging Face にあるモデルならある程度統一的に扱える、モデル個別に Tokenizer を用意しなくても AutoTokenizer である程度のモデルは扱えるなど、の利点があります。全自動研究の一番のポイントは研究過程上流で発生した揺らぎをいかに吸収するかに尽きると思っていて、その意味で細かいところが参考になる枠組みでした。この、研究過程の上流で発生した揺らぎをいかに吸収するかの議論はとても大事だと思っているので、また別の記事で改めて書こうと思います。
過去の実験を参考にするという方向性について
また、人間の研究者は実際に研究を設計する際に、過去の類似した研究を見つけたり分野のお作法から、どのような実験をするべきかをある程度参考にします。強く依存している先行研究がありそれが GitHub 上にコードを公開している場合は、それを基に実験コードを作成することもあります。完全にゼロから実験を作成しなければいけない研究は研究目的のより深い理解が必要なため人間のような実験コードを生成することは困難かもしれませんが、こうした参考になる実験がある研究の場合はやや現実的と言えます。実際に手元で仮説検証をしていても、先行研究を陽に参照させる場合はよりそれらしいものが出せるなと感じています。
従って、人間らしい実験コードを生成するためには、類似した実験をやっている先行研究を見つけること、もっと言えば、その中でも特定の分野でみんながやっているような標準的な実験を探してくることが大事です。そうなると結局は所望の論文を検索して取得すること、そしてその論文から適切な適切に情報を抽出することが重要になってくるように思います。学術文献の処理は研究自動化の大本命中の大本命でで極めて重要な部分です。これは多くの人が取り組んでいて大幅な改善を見せている分野ではありますがまだやるべきことは残っている分野だと思っています。これについてもまた改めて記事を書こうと思っています。

パイプラインからエージェントへ
私が上で作ったのは研究の処理過程をつなぎ合わせたパイプラインでした。しかし、自由度の高い研究をさせようとすると限界があります。特に、一つ一つの部分過程の質をよりあげていこうとすると、一つの部分過程でも相当数の処理を実行する必要があります。こうした理由から、研究過程をパイプラインとして表現するのではなく、研究ができるエージェントを作っていくという方向性は自律性を高めていくという意味ではより可能性があるように感じます(2023年はエージェントの年だったので去年8月の段階で本当はそれを作れてて欲しいところですが…)。また、人工研究者を作りたいという目的に照らしてもこちらの方が素直です。それもあってその後エージェントの実装についても色々試行錯誤したので、こちらについてもまた記事にまとめようと思います。

【追記:20204年6月20日】
「研究の質を高めるためにエージェントへ」という風に読める可能性がある書き方をしてましたが、どちらかというと「自律性を高めるためにエージェントへ」という方が正確だったなと、note を読んでくださった方からのご指摘をいただいて思い直しました。なので、その点を強調しました。
終わりに
今回は、自動研究ということで何をしたいか、そのコンセプトを表す簡単な例、そこで見えた課題と、課題緩和の方向性について書きました。特に、課題としては研究の質を向上させること、そしてそれらのためには研究過程上流で発生した揺らぎをうまく吸収する枠組みを作ることや、先行研究の上手い活用が重要そうであることを述べました。
こうした課題や改善方針を念頭に色々と試行錯誤していますが、私の力不足のせいで未だ大きな成果には至っていません。もし人間のような研究が出せるより強いパイプラインを作成することを手伝ってくださる方がいらっしゃいましたら、ぜひご連絡いただけますと幸いです。あるいは私と一緒にやらずともこういうのを作成に興味がある方がいらっしゃいましたら、私がこれまでやってきた範囲での気づきや知見を共有できればと思いますのでお気軽にご連絡ください。その他、より良い改善方針や、役に立ちそうなツールや枠組みなどご存知の方がいらっしゃればご教授いただけますと幸いです。AI 研究の自動化をぜひ加速していけたらと思います。
よろしくお願いします!!!!!!!!!