
SIGNATE_おれおれ環境構築備忘録_2(MLflow追加編)

はじめに
前回の記事では、Docker環境でJupyter Notebookを使用する基本的な環境構築について説明しました。今回は、機械学習の実験管理ツールであるMLflowを追加し、モデルの開発・管理をより効率的に行える環境を構築します。
MLflowについては下記サイトの他、解説を参照願います。
変更点の概要
前回の環境から以下の機能を追加します:
MLflow UIによる実験管理
実験結果の可視化
モデルのバージョン管理
設定ファイルの変更
Dockerfile
FROM condaforge/miniforge3:latest
RUN apt update && \
apt install -y build-essential
COPY requirements.txt /tmp
RUN pip install -r /tmp/requirements.txt
RUN pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
# 必要なディレクトリを作成
RUN mkdir /home/work
RUN mkdir -p /mlflow/artifacts
# ポートの設定
EXPOSE 8888 5000
# 作業ディレクトリを設定
WORKDIR /home/work
# MLflowサーバーとJupyter Notebookを起動
CMD mlflow server --host 0.0.0.0 --port 5000 --backend-store-uri file:///mlflow/mlruns --default-artifact-root file:///mlflow/mlruns & \
jupyter notebook \
--port=8888 \
--ip=0.0.0.0 \
--allow-root \
--no-browser \
--NotebookApp.token='' \
--NotebookApp.notebook_dir='/home/work'docker-compose.yml
version: "3"
services:
jupyter-mlflow:
build: ./
shm_size: '2gb'
ports:
- "8888:8888"
- "5001:5000"
volumes:
- "./:/home/work"
- "./mlflow:/mlflow"
environment:
- MLFLOW_TRACKING_URI=/mlflow/mlrunsrequirements.txt に追加
mlflow
scikit-learn環境構築と基本操作
コンテナのビルドと起動
docker-compose up -d --buildアクセス方法
Jupyter Notebook: http://localhost:8888
MLflow UI: http://localhost:5001
MLflowの使い方
基本的な実験の記録
import mlflow
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import LinearRegression
# MLflowの設定
mlflow.set_tracking_uri("file:///mlflow/mlruns")
# 実験名を設定
experiment_name = "linear_regression_test"
try:
experiment_id = mlflow.create_experiment(experiment_name)
except mlflow.exceptions.MlflowException:
experiment_id = mlflow.get_experiment_by_name(experiment_name).experiment_id
mlflow.set_experiment(experiment_name)
# サンプルデータの作成
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([2, 4, 6, 8, 10])
# データの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# MLflowで実験を記録
with mlflow.start_run() as run:
print(f"Run ID: {run.info.run_id}")
# モデルのトレーニング
model = LinearRegression()
model.fit(X_train, y_train)
# 予測と評価
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
# パラメータと指標を記録
mlflow.log_param("model_type", "LinearRegression")
mlflow.log_param("train_size", len(X_train))
mlflow.log_param("test_size", len(X_test))
# より多くのメトリクスを記録
mlflow.log_metric("mse", mse)
mlflow.log_metric("rmse", np.sqrt(mse))
mlflow.log_metric("coefficient", model.coef_[0])
mlflow.log_metric("intercept", model.intercept_)
# 入力例とモデルシグネチャを設定してモデルを保存
signature = mlflow.models.infer_signature(
X_train,
model.predict(X_train)
)
input_example = X_train[0:2]
mlflow.sklearn.log_model(
model,
"model",
signature=signature,
input_example=input_example
)
print(f"MSE: {mse}")
print(f"RMSE: {np.sqrt(mse)}")
print(f"Coefficient: {model.coef_[0]}")
print(f"Intercept: {model.intercept_}")
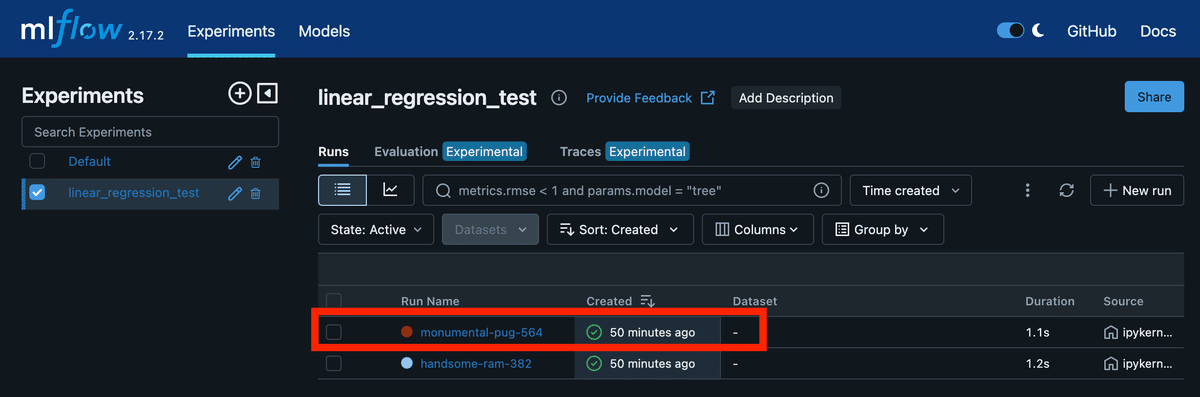
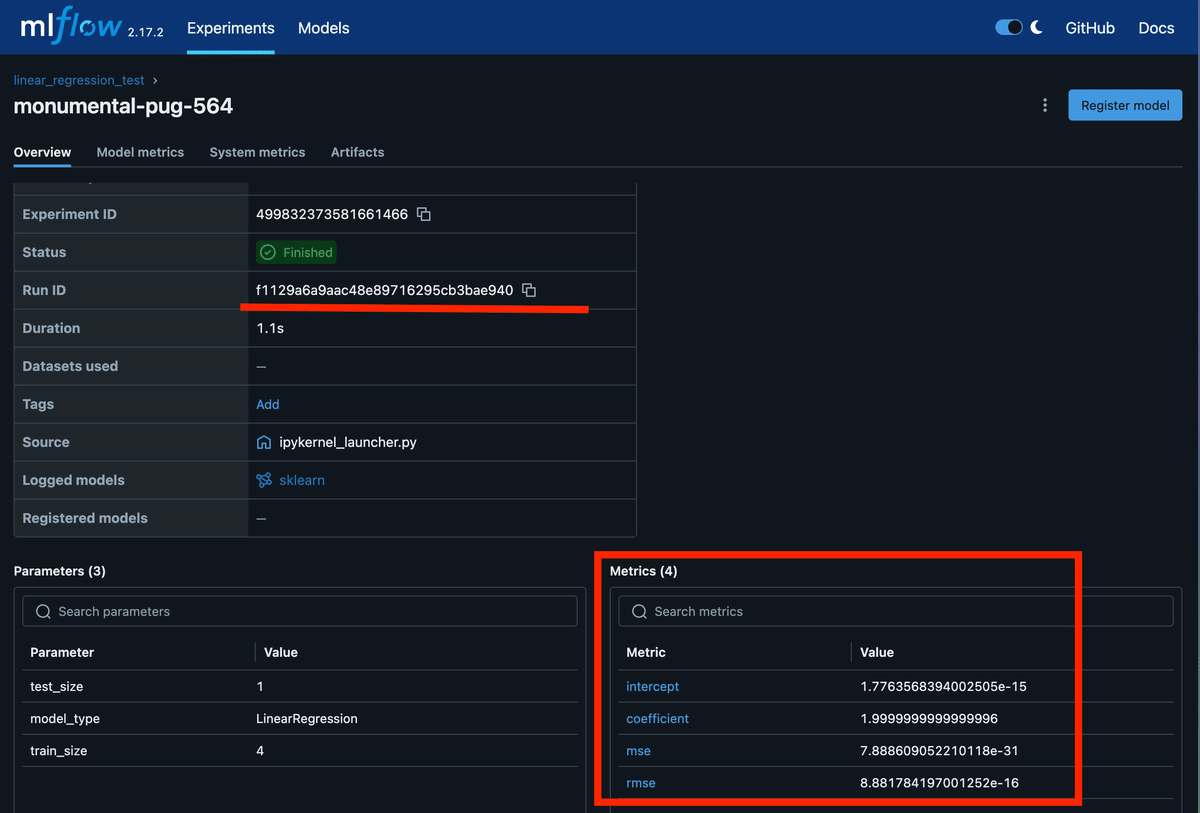
注意点
.gitignoreに以下を追加し、MLflow関連ファイルをGit管理から除外
mlflow/
mlruns/
artifacts/まとめ
MLflowを追加することで、以下のような利点が得られます:
実験結果の可視化と比較が容易に
モデルのバージョン管理が可能に
パラメータとメトリクスの追跡が簡単に
前回の環境に比べ、より本格的な機械学習開発が可能になりました。