機械学習でAAAグループのメンバー識別アプリ作成「Python」

はじめに
AidemyのAI開発講座の成果物作成課題にてAAAの現在のメンバーの顔画像を機械学習に掛け作成した学習済みモデルを使用し、ユーザーが顔画像を送信するとAAAのどのメンバーかを判定してくれるWebアプリケーションの作成をしました。
メンバーは宇野実彩子さん、輿真司郎さん、末吉秀太さん、日高光啓さん、西島隆弘さんの5名で以下敬称略での記載とさせていただきます。
アプリURL aaaapp1.herokuapp.com
目次
画像収集と加工
顔画像の水増し
モデル学習
webアプリケーションへの落とし込み
Herokuにデプロイ
まとめ
画像収集と加工
学習用の画像を収集します。
下記サイトを参考にicrawlerを動かしました。
被った画像やあまり機械学習に適していなさそうな画像をのぞいて各画像を100枚以上を目標に300枚の画像を取得しました。
結果
宇野実彩子140枚、輿真司郎138枚、末吉秀太149枚、日高光啓140枚、西島隆弘141枚となりました。
icrawlerで収集した画像を下記サイトを参考にOpenCVを用いて顔の部分で切り抜きを行いました。この画像を材料に転移学習を行いましたが精度が22%であったため画像の水増しに進みます。
●参考サイト
・icrawler
https://atmarkit.itmedia.co.jp/ait/articles/2010/28/news018.html
・OpenCV
https://newtechnologylifestyle.net/opencv_face_trimingu/
顔画像の水増し
精度が思わしくなかったため画像収集で集めた画像に水増しを行いました。水増しの手法は下記コードにしましたが枚数が多すぎて後の工程の機械学習を行った際にコードの実行ができなかったため2.3割削り無事稼働することができました。最終的に各データ1500枚以上の枚数を確保しました。
作業はじめは枚数に不安があったので1枚の画像を合計で31枚返しましたが枚数が多かった点とぼかす必要があるのか?と作業完了後に疑問に思い次の機会ではぼかしはなくして違う処理をしてみようと反省点に。
import os
import numpy as np
import matplotlib.pyplot as plt
import cv2
def scratch_image(img, flip=True, thr=True, blur=True, resize=True, erode=True):
# ----------------------------ここから書いて下さい----------------------------
# 水増しの手法を配列にまとめる
methods = [flip, thr, blur, resize, erode]
# 画像のサイズを習得、ぼかしに使うフィルターの作成
img_size = img.shape
filter1 = np.ones((3, 3))
# オリジナルの画像データを配列に格納
images = [img]
# 手法に用いる関数
scratch = np.array([
lambda x: cv2.flip(x, 1),
lambda x: cv2.threshold(x, 100, 255, cv2.THRESH_TOZERO)[1],
lambda x: cv2.GaussianBlur(x, (5, 5), 0),
lambda x: cv2.resize(cv2.resize(
x, (img_size[1] // 5, img_size[0] // 5)
),(img_size[1], img_size[0])),
lambda x: cv2.erode(x, filter1)
])
# 関数と画像を引数に、加工した画像を元と合わせて水増しする関数
doubling_images = lambda f, imag: (imag + [f(i) for i in imag])
# methodsがTrueの関数で水増し
for func in scratch[methods]:
images = doubling_images(func, images)
return images顔部分のみ切り抜いた画像の各パスをfor文でナンバリングしながらpaddingフォルダに保存しました。作成途中に様々なサイトを見ながらうすうす感じたのですが最初からメンバーをリスト化なりの処理を施せばもっと簡潔にコードをかけるのではと思いましたが次回作るときの課題にします。
import glob
img_path = "/content/drive/MyDrive/成果物/face_cut/uno/000001.jpg"
uno_pathlist = glob.glob("/content/drive/MyDrive/成果物/face_cut/uno/*.jpg")
print(uno_pathlist)
for uno_num, uno_path in enumerate(uno_pathlist):
img_data = cv2.imread(uno_path)
img_datalist = scratch_image(img_data)
for num, im in enumerate(img_datalist):
# まず保存先のディレクトリ"scratch_images/"を指定、番号を付けて保存
cv2.imwrite("/content/drive/MyDrive/成果物/padding/uno/" + str(uno_num) + "_" + str(num) + ".jpg" ,im) 水増し画像を加えて転移学習を行い無事精度が65%に上がり、モデルに手を加えていきます。
モデル学習
主にAidemyAI開発講座の男女識別(深層学習発展)CNNを用いた画像認識などのコードを参照して作成しました。
epochsを100,200,300の順で上げ200から大幅に精度が向上しましたが300では大差なかったため200にしました。
batch_size=500,画像サイズを100×100に調整すると83%に着地しました。
#ファイルの読み込み結果をリストや配列に格納
#参考https://github.com/machine-perception-robotics-group/JDLALectureNotebooks/blob/master/notebooks/01_holdout_svm.ipynb
# テキストファイルの読み込み
import matplotlib.pyplot as plt
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras.utils import to_categorical
import matplotlib.pyplot as plt
import numpy as np
import glob
import cv2
from sklearn.model_selection import train_test_split
human_namelist = ["uno", "kosi", "nisijima", "hidaka", "sueyosi"]
img_list = []
class_list = []
for human_no, human_name in enumerate(human_namelist):
fp_facecutlist = glob.glob("/content/drive/MyDrive/成果物/face_cut/"+ human_name + "/*")
fp_paddinglist = glob.glob("/content/drive/MyDrive/成果物/padding/"+ human_name + "/*")
#for fp in fp_facecutlist + fp_paddinglist:
for fp in fp_facecutlist:
img = cv2.imread(fp)
img = cv2.resize(img, size)
img_list.append(img)
class_list.append(human_no)
for fp in fp_paddinglist:
img = cv2.imread(fp)
img = cv2.resize(img, size)
img_list.append(img)
class_list.append(human_no)
X_train, X_test, y_train, y_test = train_test_split(np.array(img_list), np.array(class_list), test_size=0.2, random_state=0)
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)from tensorflow.keras.layers import Activation, Conv2D, Dense, Flatten, MaxPooling2D
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.utils import to_categorical
#CNN実装
# モデルの定義
model = Sequential()
model.add(Conv2D(input_shape=(size[0], size[1], 3),
filters=32,
kernel_size=(3, 3),
strides=(1, 1),
padding="same"))
model.add(MaxPooling2D(pool_size=(2, 2),
strides=(1,1), padding="same"))
model.add(Conv2D(filters=32,
kernel_size=(2, 2),
strides=(1, 1),
padding="same"))
model.add(MaxPooling2D(pool_size=(2, 2),
strides=(1,1)))
model.add(Flatten())
model.add(Dense(256))
model.add(Activation('relu'))
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dense(5))
model.add(Activation('softmax'))
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])
model.summary() import matplotlib.pyplot as plt
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras.utils import to_categorical
import matplotlib.pyplot as plt
import numpy as np
model.fit(X_train, y_train,
batch_size=500,
epochs=200,
verbose=1,
validation_data=(X_test, y_test))
# 精度の評価
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
# データの可視化(検証データの先頭の10枚)
for i in range(10):
plt.subplot(2, 5, i+1)
plt.imshow(X_test[i])
plt.suptitle("10 images of test data",fontsize=20)
plt.show()
# 予測(検証データの先頭の10枚)
pred = np.argmax(model.predict(X_test[0:10]), axis=1)
print(pred)
model.summary()
model.save('./result.h5')herokuでデプロイしようとしたところ容量が大きすぎはじかれました。チューターさんに見ていただき画像サイズを変更し50×50に。精度が下がりそうで嫌でしたが下記の画像のとおりなぜか93%に精度が上がりました。画像ファイルが大きいほうがいいと思っていましたがものによって必ずしも良くなるとは限らないと聞きとても勉強になりました。
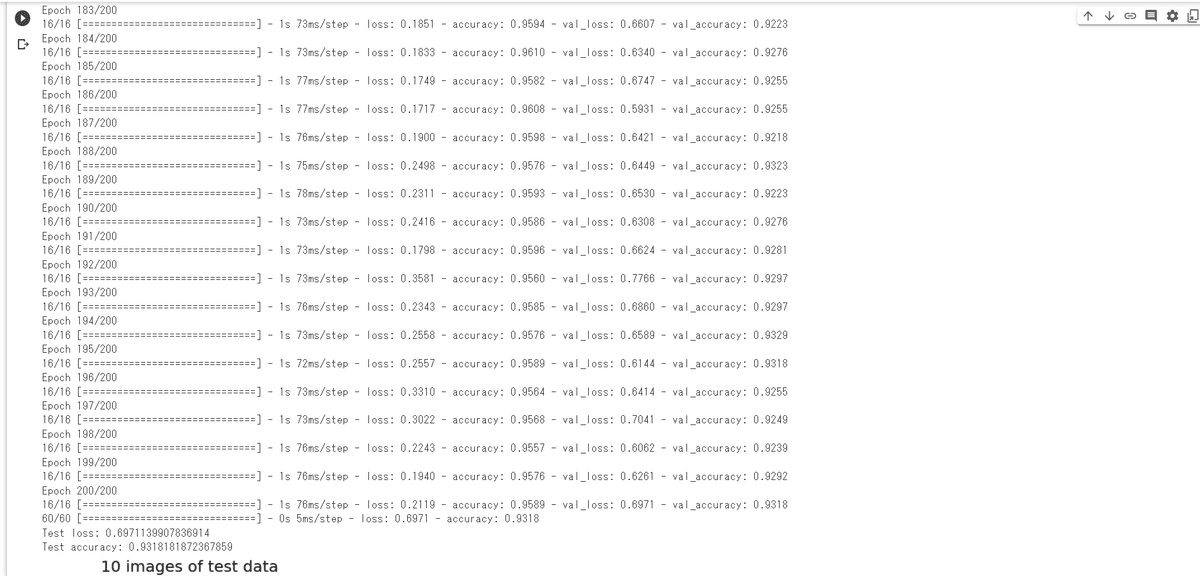
webアプリケーションへの落とし込み
DjangoやFlaskが主流とのことですがDjangoは扱っていないのでFlaskで作成します。FlaskはPythonのための軽量なフレームワークとのことです。フロント部分をHTMLとCSSで整えます。
講座内で作成したものを適宜ほしい機能や不要な部分を調べて作り変えました。
import os
from flask import Flask, request, redirect, render_template, flash
from werkzeug.utils import secure_filename
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.preprocessing import image
import numpy as np
#classes = ["uno", "kosi", "nisijima", "hidaka", "sueyosi"]した書き換え
classes = ["宇野実彩子", "輿真司郎", "西島隆弘", "日高光啓", "末吉秀太"]
image_size = 50
UPLOAD_FOLDER = "uploads"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
model = load_model('./result.h5')#学習済みモデルをロード
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
#受け取った画像を読み込み、np形式に変換
img = image.load_img(filepath, target_size=(image_size,image_size))
img = image.img_to_array(img)
data = np.array([img])
#変換したデータをモデルに渡して予測する
result = model.predict(data)[0]
predicted = result.argmax()
pred_answer = "この人は " + classes[predicted] + " さんです"
return render_template("index.html",answer=pred_answer)
return render_template("index.html",answer="")
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8080))
app.run(host ='0.0.0.0',port = port)
imp<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>メンバー診断</title>
<link rel="stylesheet" href="./static/stylesheet.css">
</head>
<body>
<header>
<a class="header-logo" href="">face recognition machine</a>
</header>
<div class="main">
<h2> AIが送信されたAAAの現在のメンバー(宇野実彩子、輿真司郎、末吉秀太、日高光啓、西島隆弘)を識別します</h2>
<div class="flame02">
<p>こちらから画像を送信してください</p>
<form method="POST" enctype="multipart/form-data">
<input class="file_choose" type="file" name="file">
<input class="btn" value="送信する" type="submit">
</div>
</div>
</form>
<div class="answer">{{answer}}</div>
</div>
<footer>
</footer>
</body>
</html>header {
background-color: #e4c9c0;
height: 60px;
margin: -8px;
display: flex;
flex-direction: row-reverse;
justify-content: space-between;
}
.header-logo {
color: #ffffff;
font-size: 30px;
margin-right: auto;
}
.header_img {
height: 25px;
margin: 15px 25px;
}
.main {
height: 370px;
}
h2 {
color: #444444;
margin: 90px 0px;
text-align: center;
}
.flame02 {
margin-top: 30px;
margin-right: 30px;
margin-bottom:30px;
margin-left: 30px;
width: 90%;
height: 60%;
color: #000;
background-color: #efe8d9;
border: 1px solid #000000;
}
p {
color: #444444;
margin: 70px 0px 30px 0px;
text-align: center;
}
.answer {
color: #444444;
font-size: 20px;
margin: 70px 0px 30px 0px;
text-align: center;
}
form {
text-align: center;
}
footer {
background-color: #a68b62;
height: 20px;
margin: -8px;
position: relative;
}
.footer_img {
height: 15px;
margin: 10px 20px;
}
small {
margin: 15px 25px;
position: absolute;
left: 0;
bottom: 0;
}●参考サイト
http://www.htmq.com/csskihon/001.shtml
https://udemy.benesse.co.jp/design/web-design/what-is-css.html
https://csshtml.work/square-box/
Herokuにデプロイ
完成したアプリを下記の流れで公開し完成しました。
・cdコマンドでアプリのファイルディレクトリに移動
・heroku lobin
・heroku git:remote -a ファイル名
・git add .
・git commit -m "変更点"
・git push heroku master
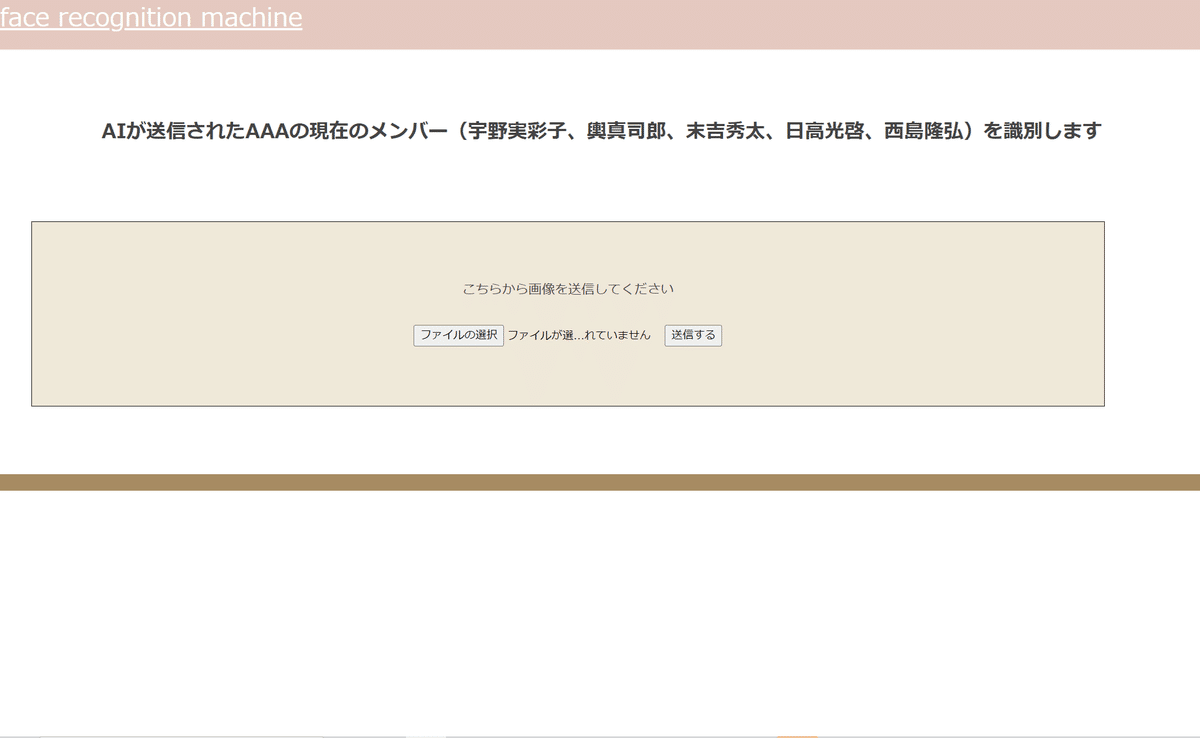
まとめ
Aidemyの講座でアプリを作り画像を集め、下処理を行い学習モデルを制作する過程で様々なライブラリやフレームワーク、関数に触れることができ非常に濃密な3か月を過ごしました。
作成過程で講座やサイト、アプリにYouTubeなどいろいろなコードを組み合わせてはエラーが出るを繰り返したのでチューターさんによる手厚いサポートがなければ完成させることは難しかった、独学で挑戦しなくてよかったと思います。
今回はそれなりに精度が出たので行わなくてよかったですが今後アプリを作る際には重みの固定やモデルを違うものに触れて精度がどう変わるのか試したいです。
今後の課題としては根本的に知識不足でもっとライブラリやフレームワーク、関数についての理解を深め引き出しを増やすこと、
今回の課題で痛感しましたがコードをもっと簡潔に書ければfor文を人数分回してなど無駄な手間を発生させずに済んだと後悔したので今後も勉強を継続していきます。