
おっさん初めての生成AI(環境構築編 その3)

前回、LM StudioでローカルLLM環境を構築しましたが、自身の知識レベルの問題もあり、どうも釈然としなかったため、今回改めて不明点の理解を深めつつ、ローカルLLM環境を再構築してみました。
用語の理解
まず、LM Studioの設定時につまずいた点について、自分なりに調べてみました。尚、記載内容には、私の理解/認識間違いが含まれていますことご了承頂ければと思います。
llama.cppについて
これは、すでにちゃんとNoteにまとめてくださっている方がおられました。
ものすごくおおざっぱですが、「Metaが作ったLlamaを動かすためのソフト(プログラム/ランタイム)みたいなもの。」と理解しました。
CUDA、ROCm、Vulkan、CPUの違い
これも超おおざっぱですが、「ハードウェアメーカー(CUDA→NVIDIA、ROCm→AMD、Vulkan→Apple(Khronos)、CPU→不明(汎用?どこ?))ごとに最適化されたllama.cppが提供されている。」と理解しました。
KoboldCpp導入
今回のゴールとしては、"VulkanではなくROCmでローカルLLMを動かす。"ということにして、ROCmで動く(動かせそう?)なKoboldCppをセットアップしてみました。
インストール
ROCm向けKoboldCppをダウンロードします。gitにはexeファイルがそのまま置いていますので、保存したいところにダウンロードしてください。
koboldcpp_rocm.exeをダブルクリックすると、KoboldCppが起動するのですが、毎回ですが最初の起動が非常に時間がかかります(実測で2分から2分半位)。しばらく待つとコマンドプロンプト画面が表示し、設定画面が表示されます。


設定画面が開くと、"Presets"と"GPU ID"がそれぞれ"ROCm"と"gfx1032"が読み込まれています。"gfx1032"は"RX6650XT"なので、ご使用のRadeon GPUによって表記は変わるものと思われます。ここで、"GGUF Text Model"に、使用したいモデルを選択して、"Launch"ボタンをクリックすれば、基本使用できるようになるはずです。今回は、日本語モデルを使用したかったので、Llama-3 ELYZAの日本語モデルを準備しました。
あと、私の環境だけかもしれないのですが、モデルを選んで"Launch"するだけだと、KoboldCppのチャット画面は表示されるのですが、文字を入力すると、KoboldCppがエラーで停止してしまいました。
Processing Prompt (27 / 27 tokens)ROCm error: CUBLAS_STATUS_INTERNAL_ERROR
current device: 0, in function ggml_cuda_op_mul_mat_cublas at D:/a/koboldcpp-rocm/koboldcpp-rocm/ggml/src/ggml-cuda/ggml-cuda.cu:1125
hipblasGemmEx(ctx.cublas_handle(id), HIPBLAS_OP_T, HIPBLAS_OP_N, row_diff, src1_ncols, ne10, &alpha_f16, src0_ptr, HIPBLAS_R_16F, ne00, src1_ptr, HIPBLAS_R_16F, ne10, &beta_f16, dst_f16.get(), HIPBLAS_R_16F, ldc, cu_compute_type, HIPBLAS_GEMM_DEFAULT)
D:/a/koboldcpp-rocm/koboldcpp-rocm/ggml/src/ggml-cuda/ggml-cuda.cu:73: ROCm errorエラーの内容がよくわからず、エラーの文言と以下のWIKIを確認しました。
WIKIの内容から、"Quantized Mat Mul (MMQ)"と"Flash Attention"が関連しているっぽいので設定を見てみると、"Quantized Mat Mul (MMQ)"はもともとチェックされておらず、"Flash Attention"については以下の画面で"Requirements Not Met"と赤文字で表示されており、この赤文字にカーソルを合わせると、"FlashAttention"を有効に、"ContextShift"を無効にしろと表示されていました。

で、最終的に以下の設定にして無事正常起動することができました。

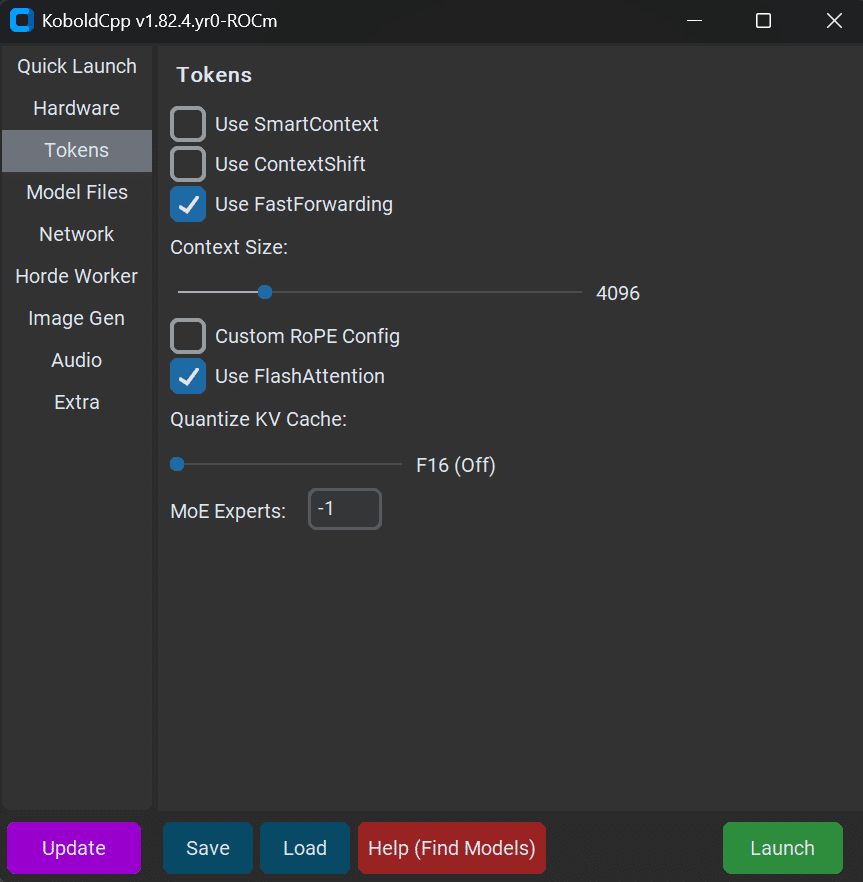
尚、これらの設定は、"Save"ボタンをクリックすると、.kcppsファイルとして保存することができます。また、最初の設定画面を介さずに、この設定で起動させたい場合は、コマンドプロンプトで、--configオプションでコンフィグファイルを指定することで起動できます。こんな感じ。
koboldcpp_rocm.exe --config コンフィグ名.kcpps正常に起動すると、以下のような画面がブラウザに表示されます。

動作検証
適当にチャットした際の動作を検証してみました。

正常に動いているように見えます。


また、KoboldCppの起動時の出力に以下の項目があるので、ROCmでローカルLLMを動作させることに成功した、と言えるのではないかと思います。

振り返り
AMDのサポート
今回いろいろとネット界隈の情報を探索しましたが、AMDに関する情報が無いわけではないですが、やはり情報が少なく感じました。ローカルLLMを実現するためのソフト/ツール類は、ほとんどNVIDIAの30シリーズからサポートされていますが、AMDのRadeonについてはROCmのサポートに依存しています。ROCmの最新6.3.3では、RX7900以降しかHIP SDKをサポートしていませんし、私が導入したROCm 6.2.4では、RX6800以降しかサポートしていませんでした。私のRX6650XTでStable Diffusionを動かすことができたのは、他のユーザーさんが善意?で作成されたUnsupportedのライブラリのおかげです。たしかにだいぶ古いグラフィックボードではありますが、せめて7000台まではサポートしてくれれば良いのにと思いました。
生成AIとハードウェア
こうなると、ローカルLLM=NVIDIAのGPU一択なのか?と思ってしまいますが、世の中にはCPUベースでローカルLLMを動かす手法を構築されている方々もおられます。Intelが開発したOpenVINOというIntel版CUDAみたいなものかと思いますが、これすごいですね。
そもそもAppleのハードウェアも、ごついグラフィックボードは搭載していませんし、MicrosoftのSurfaceやAndroidデバイスなども、強力なGPUを乗せていないと思います。こういう技術が向上するとグラフィックボードが不要で済むのでありがたいですね。そういう点は、ROCmで動かすとかVulkanで動かすとか、仕組みは別としてハードウェアリソースがちゃんと使われるのであれば、どの方法でも良いのでは?と思いました。
ちまたでは、5070tiが発売/即完売になるくらい、NVIDIAのグラフィックボードが枯渇していますので、NVIDIAに依存しない方向に、ローカルLLMの技術がアップデートされるといいなぁと思いました。
最後までお付き合いいただきありがとうございました。