AWSのCloud9で容量不足になった時の対処方法メモ

AWSのCloud9でbotを運用していたら、時々「何か分からないエラーを吐く」様になっていた。(画面の上の方に、disk fullみたいなメッセージが出る時があるけど、しばらくすると消えている)
「df -h」で調べると「/dev/xvda1」とやらがたくさん容量を使っていて、ディスクフルの状態になっていたらしい。

ディスクがいっぱいになったから、テンポラリーデータも含めて書き込み不能になり、エラー停止となっていた。
ぶっちゃけLinux系はよく分からないので、対処した時のメモを残しておく。
</dev/xvda1とは何か>
どうやらいわゆるユーザーデータの保存領域らしい。
色々動いていると、テンポラリーデータとかでいっぱいになっていくんだろう。
対処法案その1・・・要らないデータを消す
対処法案その2・・・ディスク容量を増やす
私は最初に書いたようにLinux系は素人なので、分からないことはやらない。
つまり対処法案その2をすることにした。
調べると色々なブログが発見できたのだが、少なくとも「これを見ればOK」みたいなのはなかった。
それぞれの記事の一部を抽出して(組み合わせて)ようやく対処完了した。
<やること目次>
1,ディスクの容量を増やす(物理的なHDD容量を増やすイメージ)
2,パーティションを拡張する(増やした所のHDDをフォーマットするイメージ)
3,xvda1を拡張する(ユーザーフォルダに増やしたHDD容量を割り当てるイメージ)
<EC2のメニューで割り当てられているディスク容量を増やす>
AWSのダッシュボードに入って、「EC2」の「Elastic Block Store」の「ボリューム」メニュー。
この時、動いているbotを止める必要があるかどうかですが、ブログによって違いがありますが、私の場合は止めずにそのまま行けました。
インスタンス自体も停止せずに行けました。
画像は増やした後です。
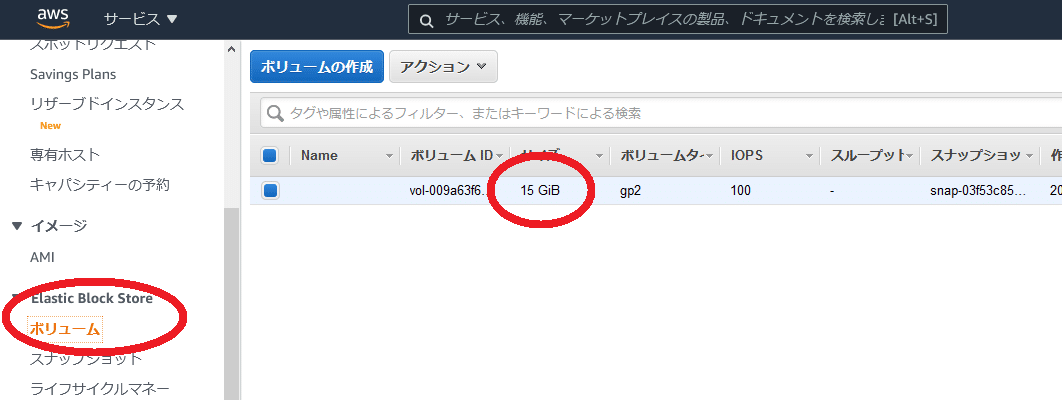
ここの容量を増やすわけです。
「アクション」「ボリュームの変更」

容量を初期値(t2.micro)の10GBから15GBに変更

1GB当たりの値段は、記憶が定かではありませんが、「20円」ぐらいだったと思います。(正確な金額分かれば訂正します)
変更したら右下のボタンを押してしばらく待つ。。。
しばらく待ったら、「F5」ボタン押すとかして、画面をリロードしましょう。
上記の画像の様に、15GBに増えていたら成功。
<増えた容量を使える様にパーティションを拡張する>
「lsblk」で割り当て状況の確認。
(ぶっちゃけコマンドの意味なんて全く分かっていないけど、雰囲気で何しているかだけは分かる。)

どうやら、「xvda」っていうディスクはあるけど、私が使っている1番目のxvda(xvda1)には10GBしか割り当てられていないらしい。
わざわざ書いたのは、最初イチをエルと読み間違えていて、うまくいかなかったから。
きっと同じような失敗する人は居るはず。
という事で、「xvda1」に空き容量を割り当てる。
「sudo growpart /dev/xvda 1」っていうコマンドで、割り当てるみたい。
イチの前にスペース有るので注意。
![]()
なんか分からんけど、エラー出ていないから成功したんだろう。
もう一度「lsblk」にて確認。
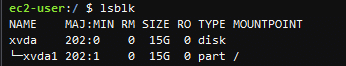
「xvda1」が15Gに増えているので成功っぽい。
<xvda1を拡張する>
実はこれが今回の記事を書こうと思ったきっかけとなったハマッた所。
まずは「df -h」で現状確認。

まだ「xvda1」は使用率100%のままで拡張されていない。
ここでブログを漁ると出てくるのが「sudo xfs_growfs /dev/xvda1」っていうコマンド。
ぶっちゃけ失敗する。
![]()
なぜかは分からない。
(私は素人なので当然)
ここで違うコマンドを発見。
「sudo resize2fs /dev/xvda1」っていうの。
名前からしてソレっぽいよね。

おおー成功したっぽい。歓喜。
「df -h」で再度確認。

めでたく大成功。
念のため、全botを再起動して終了。。。
<最後に>
正直、「df -h」コマンドすら、何のことかよくわかっていない。
雰囲気だけで何となく使用している。
ーーー 以上 ーーー