
LlamaIndexで独自データを元にChatGPTに回答させるSlackボットをGoogle Cloud Functionsで動かす

LlamaIndexを使うと、独自のデータを使ってChatGPTに質問に答えさせることができます。
このライブラリを使用して、Google Colabの環境でオリジナルなチャットボットを作成しました。これをSlackボットとして利用するためGoogle Cloud Functionを利用しました。その際の手順を記事にします。
Google ColabでのLlamaIndexの使用
Google ColabでのLlamaIndexの使用方法はnpakaさんのこちらの記事を参考にさせていただきました。
LlamaIndex を使用して独自のデータを元にインデックスファイルを作成します。バージョンによってインデックスの形式が異なりますが、今回はv0.6.5を使用して以下の3つのファイルが作成されました。
vector_store.json
index_store.json
docstore.json
プロンプトやパラメータなどのチューニングもGoogle Colab上で済ませておきます。LlamaIndexのチューニングについてはGMOさんのこちらの記事が参考になりました。よくある課題別に調整方法が説明されています。
チャットボットとして概ね良い結果が得られたらSlackボットとして動作させる準備に移ります。
Slackボットの準備
今回作成したSlackボットの処理の流れです。
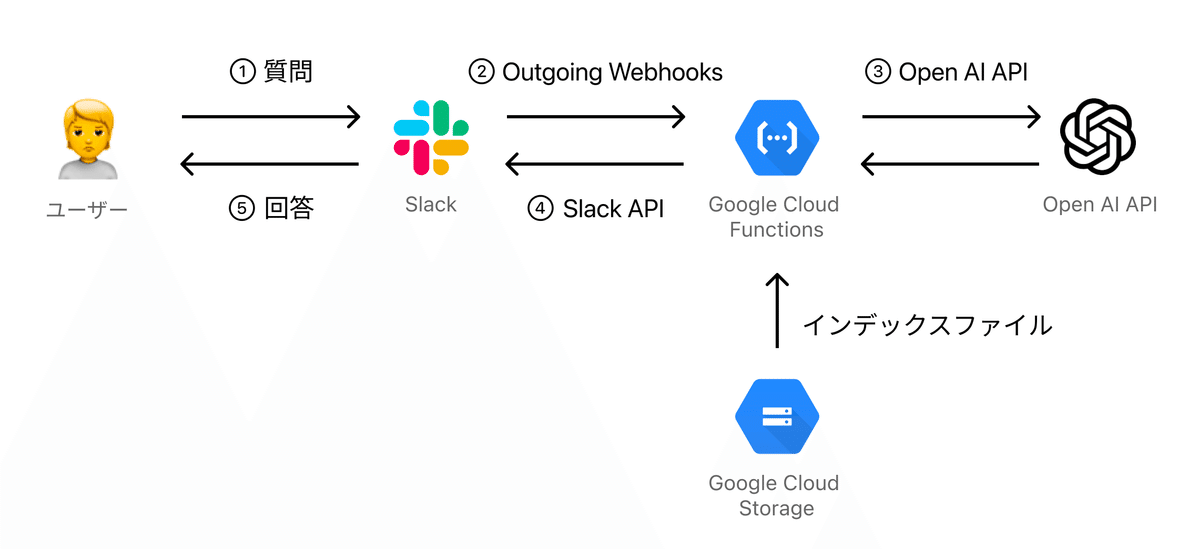
ユーザーがSlackで質問を投げたら、ボットへの「@〜〜」のメンションをトリガーにOutgoinig WebhooksでGoogle Cloud Functions上に作成した関数が呼ばれます。
Google Cloud FunctionsではLlamaIndexを使用し、質問内容に一致する情報をCloud Storageから読み取ったインデックスから抜き出します。
この情報をコンテキストとして元の設問に加えて、ChatGPT APIに質問を送ります。
得られた回答はSlackAPIを通じてSlackでユーザーに返信します。
Slack Appの作成
Slack APIの以下ページから新規にアプリを作成します。
メニューからOAuth & Permissionsを選択し、Scopesから以下を追加します。
chat:write
chat:write.customize
chat:write.public

OAuth TokenのBot User OAuth Tokenの値はあとで使うのでメモしておきます。
メニューのBasic InformationからDisplay Informationを設定。Slackボットとして表示される際のアイコンと名前と概要文を記入します。

Slack Appの設定が完了したら、ボットを動作させたいSlack Channelを開きアプリをInviteしておきます。
Outgoing Webhooksの設定
次にSlackのOutgoing Webhooksの設定を行います。
所属しているSlackのサブドメインから以下のURLを開き設定を行います。
https://{サブドメイン}.slack.com/apps/検索窓から「Outgoing Webhooks」を検索して開きます。「Slackに追加」ボタンを押して設定項目を入力します。

チャンネル:Slackボットを動作させたいChannelを選択
引き金となる言葉:Slackボットへのメンションをトリガーにしたいので、<@{SlackアプリのメンバーID}> と入力
URL:Google Cloud Functionsの関数作成後に入力
トークン:あとで使うのでメモしておく
SlackアプリのメンバーIDは、アプリへのDM画面のチャンネル情報のビューから確認できます。

ここで指定したChannelでトリガーワードを含むメッセージが送信されると、指定したURLにメッセージがPOST送信されます。
AWS Lambdaでの試行
ちなみに当初はクラスメソッドさんの記事を参考にAWS Lambdaで動かす想定でした。
ところが実行時に以下のランタイムエラーが発生します。
[ERROR] Runtime.ImportModuleError: Unable to import module 'src/query': langchain
Traceback (most recent call last):エラー内容を調べながら、外部ライブラリの設置方法を見直してみましたが、自分の知見が乏しく解決の見込みが立たなかったため、Lambdaで動かすのを諦めGoogle Cloud Functionsを試すことにしました。
Google Cloudへの導入
Cloud Storageにインデックスファイルを格納
Google Cloudに新規にプロジェクトを作成し、Cloud Storageにインデックスファイルを格納します。バケットに 「storage」 フォルダを作成し、フォルダ内に「vector_store.json」「index_store.json」「docstore.json」の3つのファイルをアップロードします。

Cloud Functionsの設定
次にCloud Functionsに移動します。
関数の編集画面からランタイムを設定します。
割り当てられるメモリに 2GB、タイムアウトに120秒を設定。メモリは扱うインデックスのサイズによって異なります。メモリが不足すると実行時にメモリ不足のエラーメッセージが出力されるため、実行しながら調整する感じで良さそうです。

ランタイム環境変数には以下の項目を設定します。
OPENAI_API_KEY
:OpenAI APIのAPIキーを入力SLACK_OUTGOING_WEBHOOK_TOKEN
:前述のOutgoing Webhooksのトークンを入力SLACK_API_TOKEN
:前述のBot User OAuth Tokenの値を入力
コードの編集
次にコードの編集画面に移動します。
ランタイムは Python 3.9 を選択。ライブラリのインストールのために、requirements.txtに以下を追加します。
requirements.txt
google-cloud-storage==2.8.0
llama-index==0.6.5main.pyを編集します。
前述の記事 AWS Lambdaで作成済みのインデックスをクエリしてみた と同様に、コールドスタート時にインデックスをロードするようにします。
main.py
from google.cloud import storage
from llama_index import load_index_from_storage, StorageContext, LLMPredictor, ServiceContext, PromptHelper, QuestionAnswerPrompt
from langchain.chat_models import ChatOpenAI
from string import Template
import json
import os
from flask import jsonify
import requests
# Temp配下にインデックスを格納
storage_client = storage.Client()
bucket = storage_client.bucket('storage')
blob = bucket.blob('docstore.json')
blob.download_to_filename('/tmp/docstore.json')
blob = bucket.blob('index_store.json')
blob.download_to_filename('/tmp/index_store.json')
blob = bucket.blob('vector_store.json')
blob.download_to_filename('/tmp/vector_store.json')
service_context = ServiceContext.from_defaults(
llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo", max_tokens=256)),
prompt_helper = PromptHelper(max_input_size=3000, num_output=256, max_chunk_overlap=1)
)
# インデックスの読み込み
storage_context = StorageContext.from_defaults(persist_dir="/tmp")
index = load_index_from_storage(
storage_context = storage_context,
service_context = service_context
)
# tmp配下に格納したインデックスを削除
os.remove('/tmp/docstore.json')
os.remove('/tmp/index_store.json')
os.remove('/tmp/vector_store.json')
# テンプレートの作成
QA_PROMPT = QuestionAnswerPrompt("以下にコンテキスト情報を提供します。\n\n---------------------\n{context_str}\n---------------------\n\n与えられた情報を元に入力へのアドバイスを200文字以内で出力します。与えられた情報に一致しない場合は「すみません。該当する情報が見つかりません。」とだけ出力します。\n\n入力:\n{query_str}\n\n出力:\n")
# クエリエンジンの作成
query_engine = index.as_query_engine(
text_qa_template=QA_PROMPT,
similarity_top_k=2
)次にSlackの指定Channelでトリガーワードが呼ばれた際の処理を記述します。
main.py
# Slackの指定ChannelでTriggerWordが投稿されたら呼ばれる処理
def doPost(request):
form = request.form
# パラメータの取得
if form and form.get('text'):
token = form.get('token')
if token != os.environ.get('SLACK_OUTGOING_WEBHOOK_TOKEN'):
print('OutgoingWebhookTokenに誤りがあります。')
return
trigger_word = form.get('trigger_word')
channelName = form.get('channel_name')
text = form.get('text')
timestamp = form.get('timestamp')
else:
print('パラメータの取得に失敗しました。')
return
# 質問文を作成して回答を取得
text = text.replace(trigger_word,"")
res = query_engine.query(text)
postResult = postSlack(str(res), channelName, timestamp)
return postResult関数のエントリポイントにはこの doPost を指定します。
最後にSlackに投稿する処理を記述します。
main.py
# Slackに投稿する処理
def postSlack(message, channel, thread_ts):
url = 'https://slack.com/api/chat.postMessage'
slackApiToken = os.environ.get('SLACK_API_TOKEN')
payload = {
'token': slackApiToken,
'channel': channel,
'as_user': True,
'text': message,
'thread_ts' : thread_ts
}
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer ' + slackApiToken
}
response = requests.post(url, json=payload, headers=headers)
if response.status_code == 200:
return 'Message posted successfully!'
else:
return f'Failed to post message. Status code: {response.status_code}'デプロイが完了するとAPIとして関数を利用可能になります。
このAPIのURLは「トリガー」タブから確認できます。トリガーURLをコピーし、前述のSlackのOutgoing WebhooksのURL欄に反映します。


これで完成です。
SlackのChannelに追加したSlackアプリにメンションを付けて質問すると、この関数が呼ばれ、実行結果として得られた回答をSlackで返信します。