
Figmaのテキストを自動チェックする用語統一プラグインを作った

なぜ作ることにしたか?
社内でプロダクトに関わるデザイナーが増えるにつれて、用語や表記のブレが目立つようになりました。統一された表記ルールがあると何かと便利です。そのためNotionに用字用語一覧を作成しますが、デザイナーが日々の業務で参照するのは面倒です。もっと手軽に活用できるのが理想です。
Figmaで自動チェックできたら、もっと簡単にルールを適用できそう。そう考えて、Figmaプラグインを作ることにしました。
完成したプラグインは以下に公開しています。
https://www.figma.com/community/plugin/1458441301140419279/custom-text-linter
ChatGPT出力のプロトタイプをベースに構築
まずは、社内のデザイナーがChatGPTにプロトタイプを作ってもらいました。基本的な挙動はこれでOKです。このプロトタイプをベースに本格着手しました。

Notionの用語一覧をCSVでエクスポートして、プラグインに取り込めるようにしました。これなら社内だけでなく、他の人たちにも使ってもらいやすくできそうです。その他にも、日本語・英語の切り替え機能など、細かな機能の追加や調整を行いました。
完成したプラグインは以下のような形です。チェック結果の一覧と、用語一覧のインポートの2種類のViewがあります。

使い方
テキストチェックと、用語一覧の更新方法は以下の通りです。
テキストチェックの方法

Figma内でチェックしたいページを開きます。
プラグインを起動し「ページをチェック」を押します。
チェック結果が表示され、非推奨用語が含まれているレイヤーのリストが確認できます。
問題のある用語をクリックすると、該当するテキストレイヤーにフォーカスします。
用語一覧の更新方法

用語一覧を更新したい場合は「用語一覧の更新」 セクションを展開します。
用語一覧のCSVファイルを選択し、「CSVファイルをインポート」ボタンを押します。
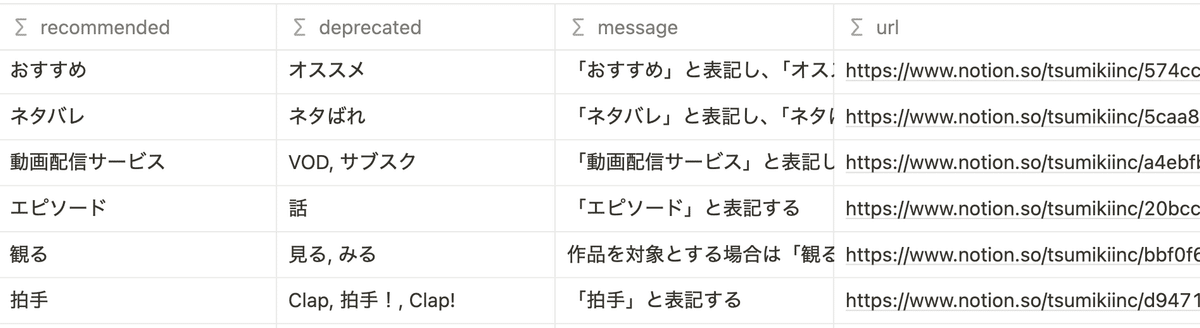
CSVには以下の列を含めます。
recommended: 推奨される用語 (カンマ区切り)
deprecated: 避けるべき用語 (カンマ区切り)
message: 用語についての説明
url: 参照リンク(任意)インポートが成功すると、ファイル名と日付が更新されます。
用語一覧の作成方法
すでにスプレッドシートやNotionで管理している用語一覧があれば、それをエクスポートして使用するのがおすすめです。
社内ではNotionのデータベースにエクスポート用のViewを作成し、関数プロパティを設定。ボタンひとつでインポート用のCSVを出力できるようにしました。

作ってみて気づいたこと
作ってみると、いろいろな気づきがありました。
英語と日本語で処理の違いがある
英語はスペースで単語が区切られるますが、日本語はそうではありません。そのため用語、用字の判定処理を英語と日本語で分ける必要がありました。
日本語では誤検知が発生しやすい
たとえば「◯◯した時、」を「◯◯したとき、」に統一したいとします。推奨用語を「とき」、非推奨用語を「時」にすると、「9時24分」などの表記も誤検出される可能性があります。品詞分解を活用すれば精度が上がるかもしれません。
このあたりは今後も改善していく予定です。
使ってみた感想やリクエストがあれば、ぜひコメントで教えてください!
X(Twitter)でもUIデザインについて発信しています。感想やコメントなどいただけると嬉しいです!