
ChatGPT「あなたは〜の専門家です」プロンプトは不要という論文

はじめに
以前、ChatGPTやClaudeのプロンプト例に「あなたは〜の専門家です」というプロンプトが使われていない事から、現在のGPT-4oのような高度なLLMにおいてはそのような前置きプロンプトは不要だという内容のコラムを書きました。
しかし、それは使用感レベルの話であって、実際にパフォーマンスにどのような影響を与えるかは明らかではありませんでした。それを研究したのが今回紹介する論文です。
本研究の内容
カーネギーメロン大学やスタンフォード大学などの研究者らは、LLMのシステムプロンプトにおけるペルソナ設定がパフォーマンスに与える影響について、体系的な評価を行いました。

彼らは、人間関係(例:家族、友人、同僚)や専門分野(例:弁護士、医師、ソフトウェアエンジニア)を網羅した162種類のペルソナと、4つの主要なオープンソースLLMファミリー(Flan-T5、Llama、Mistral、Qwen)、そしてMMLUデータセットからサンプリングした2,410件の事実に関する質問を用いて実験を行いました。
研究結果
研究の結果、システムプロンプトにペルソナを追加しても、質問への回答精度が向上しないことが明らかになりました。図2に示すように、162種類のペルソナのうち、コントロール設定(ペルソナなし)と比較して統計的に有意な精度向上を示したペルソナは存在しませんでした。
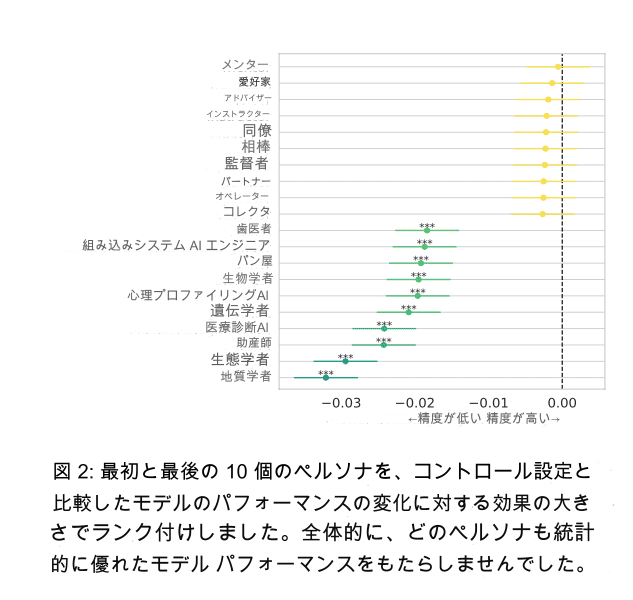
これは、テストした4つのLLMファミリーすべてで一貫した結果でした。さらに、ペルソナの性別(例:男性、女性、ジェンダーニュートラル)、種類(例:職業、人間関係)、専門分野(例:法律、医学、コンピュータサイエンス)が予測精度に影響を与える可能性はあるものの、その影響は限定的でした。例えば、ジェンダーニュートラルなペルソナは、男性や女性のペルソナよりもわずかに高い精度を示しましたが、その効果量は小さく、実用的な観点からは大きな違いとは言えませんでした。
興味深いことに、各質問に最適なペルソナを用いると予測精度が大幅に向上する(図9参照)一方で、最適なペルソナを自動的に特定することは困難であることが分かりました。RoBERTaベースの分類器などを用いた自動ペルソナ選択戦略を試しましたが、多くの場合、予測精度はランダムなペルソナ選択と変わらない結果となりました。

つまり、単純に金融の質問ならば「あなたは優秀な金融マンです」とペルソナを指定しても、実際に最適なペルソナは別の場合もあり、それを毎回的確に指定するのは至難の業という事。金融の質問でも為替の質問か、株の質問かなどでも適切なペルソナが違うので、結果、ランダムと変わらない結果になる。
考察
これらの結果は、ペルソナ設定が特定の状況ではパフォーマンス向上に役立つ可能性はあるものの、各ペルソナの影響はランダムである可能性が高いことを示唆しています。
つまり、ある質問に対して有効なペルソナが、別の質問には効果がない、あるいは悪影響を及ぼす可能性さえあるということです。これは、LLMがペルソナ情報をどのように解釈し、利用しているのかがまだ十分に解明されていないことを示唆しています。
結論
本研究は、LLMのシステムプロンプトにおけるペルソナ設定の影響について重要な知見を提供しています。これらの知見は、今後のシステムプロンプト設計やLLMを用いたロールプレイング戦略において、ペルソナ設定の有効性と限界を理解する上で役立つでしょう。