
v15 Kohya LoRA Trainer Dreambooth の使い方、学習方法解説

バージョン違いにご注意ください
この解説はバージョン15です。
追記箇所
4.2. Data Annotationと5.2. Dataset Configにキャプション付けについての誤りがあったので修正しました。「キャプションとタグを精査する」に説明を追記しました。
v15.0.1の内容に対応
TensorboardとTensorflowのバージョンアップに対応しているので、「Colabで開く」項目からやり直してください。
activation_wordの扱いが変更されました。従来の「meru 1girl」という書き方から「meru」という書き方になります。この記事の方法で行う場合は影響はありません。
それらに伴い、4.2.2. 項目、5.2. 項目を修正しました。
前説
学習にあたって
前回に引き続き、今回も正則化画像なしのLora学習方法を解説します。使うのはKohya LoRA Dreambooth LoRA Training (Dreambooth method)v15.0です。超初心者でもわかります。
正則化画像がないと学習させたモデルが、呼出しトークンを使わなくても出てきてしまいますが、学習精度が上がり短時間で学習できるメリットもあります。そもそもLoraは適用させた時はその学習内容を出したい時なので、今回は正則化画像なしのLora学習方法を解説します。
また、学習方法はキャプション方式を使用します。キャプション方式の他に、instance_classトークン方式がありますが今回はキャプション方式を使用します。
キャプション方式のメリットはLoraモデルの使用時にポーズや服装、髪型など、元々の絵を維持しやすくなります。つまり画風だけ、顔だけを変えると言った事がやりやすくなります。
instance_classトークン方式のメリットは綾瀬はるかと長澤まさみを同時に学習させるなど、複数の概念を同時に学習できる事です。ただし、キャプション方式と違いLoraモデルの使用時にポーズや服装、髪型などが元々の絵を維持しにくくなります。そもそもLoraは適用させたい効果を簡単に加えられる事がメリットなので、複数の概念を一つのLoraモデルに入れるメリットは低いと思っています。
画像収集
学習させたい画像を30枚ほど収集します。なるべく解像度の高い(ボケていない、ノイズがない)ものを集めてください。学習させたい物が人物の場合、髪型、ポーズ、背景、服装をなるべくバラバラにしてください。例えば全部の画像に東京タワーが写ってると、東京タワーもその人物と認識して学習してしまいます。
枚数よりも解像度が重要ですので、30枚は無理ですという人は20枚でもいいです。悪い画像を混ぜた30枚ならば、良い画像の20枚の方が結果は良くなります。
画像収集には『画像ダウンローダー』というGoogle Chromeブラウザーのアドオンが便利です。
画像トリミング
用意した画像を512x512の正方形にトリミングします。
birme.netというサイトを使うと直感的にトリミングできます。
ZIPでダウンロードできるので便利ですが、ZIP/フォルダー/イメージとなってしまうので、SAVE FILESの方で画像を保存し、手動でZIPにして下さい。
用意した画像をZIPに圧縮する
学習画像をフォルダーに入れてZIPに圧縮します。
フォルダー/学習画像.jpg
というようにして圧縮します。
Macはキャッシュファイルごと圧縮してしまう仕様で学習時にエラーが出てしまうので注意が必要です。サードパーティのアプリ等を使ってZIPにしてください。
グーグルドライブへアップロード
用意したZIPをグーグルドライブへアップロードしておきます。
解説開始
Colabで開く
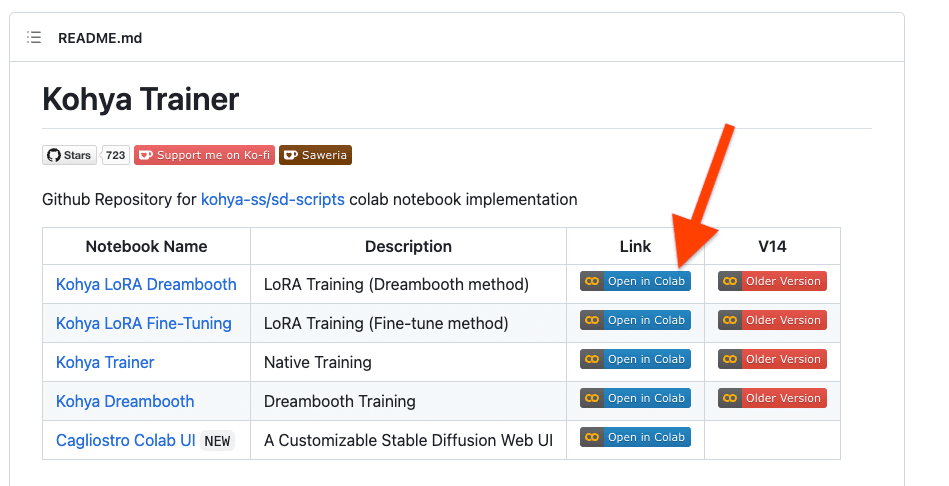
URLへアクセスしColabで読み込む
https://github.com/Linaqruf/kohya-trainer.git へアクセスしKohya LoRA DreamboothのOpen in Colabリンクをクリック
ドライブへコピーをクリック
すると「kohya-LoRA-dreambooth.ipynb のコピー」という物ができるので、それを使って実行していきます。

I. Install Kohya Trainer項目解説
1.1. Install Dependencies
mount_driveのチェックをオンにし実行します。verboseは実行状況の詳細を表示させるオプションなのでチェックは不要です。

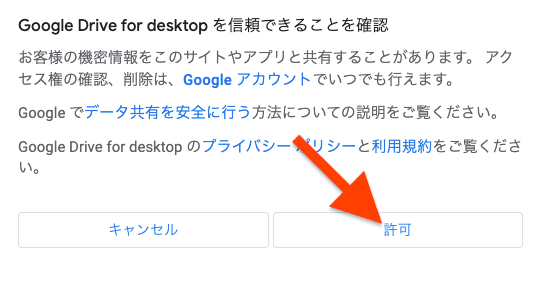
許可を求められるので許可します。

1.2. Start File Explorer
実行しません。
II. Pretrained Model Selection項目解説
2.1. Download Available Model
ベースとなるモデルを選択します。Stable Diffusion2.0系統を使いたい場合は上の段を空白にして、下の段で選択します。

アニメや漫画キャラクターを学習させたい人は「AnyLoRA」、実写の人物などを学習させたい人は「Stable Diffusion1.5」がおすすめです。
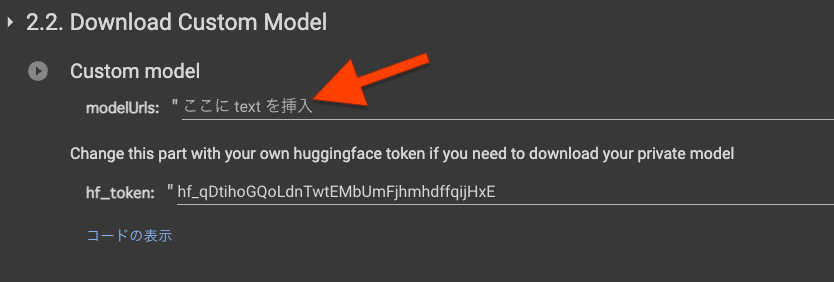
2.2. Download Custom Model
2.1を実行した人は不要の項目です。その他のモデルを使いたい人はこちらでURLを指定して実行します。
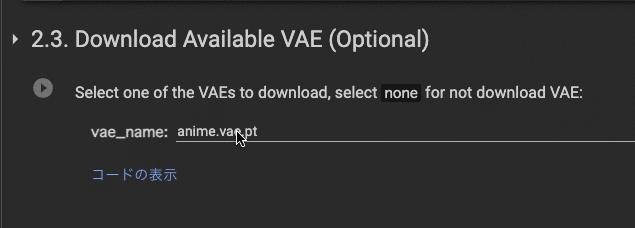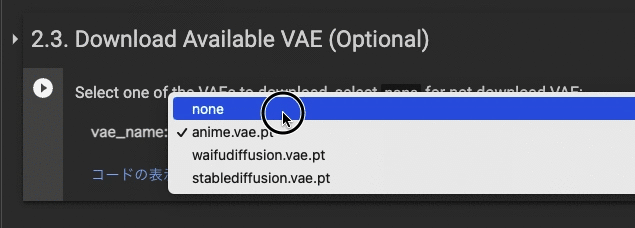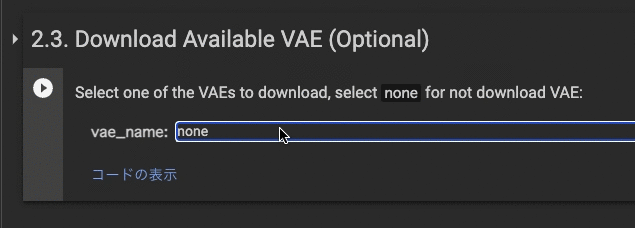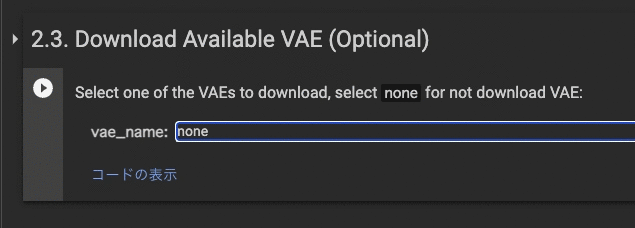
2.3. Download Available VAE (Optional)
noneを選択し実行します。VAEをミックスさせたい人は任意で選んで実行させます。Loraモデルの出来栄えを考慮すると実行しない方が無難です。
ここから先は
Amazonギフトカード5,000円分が当たる
この記事が気に入ったらチップで応援してみませんか?