
【GPTs】GASでGoogle Driveと連携し、格納したファイルの内容について質疑応答が可能なRAG風のGPTsを作成する(コード全文付き)

背景
大規模言語モデル(LLM)は、一貫性に欠けた応答をすることがあります。検索強化型生成(Retrieval-augmented Generation、RAG)は、LLMが持つ内部知識を補完するために外部の知識ソースにアクセスさせることで、生成する回答の質を向上させるAIのフレームワークです。
そもそも間違ったことを吐き出してくるなというのはさておき、GPTsがGoogle Driveに置いたファイルを自動で読み込んで、ファイル内容について回答してくれたら良いなって単純に考えて作ってみました。
RAG風と言っているのは一般的なLangchain使ったり「セマンティック検索」のために何もやらないからです。発想の転換で、「クエリを投げるお前がセマンティックを意識して検索しろ!」という概念です。別になんてことありません。RAGを構築すると色々と毎月高いですし。
基本機能
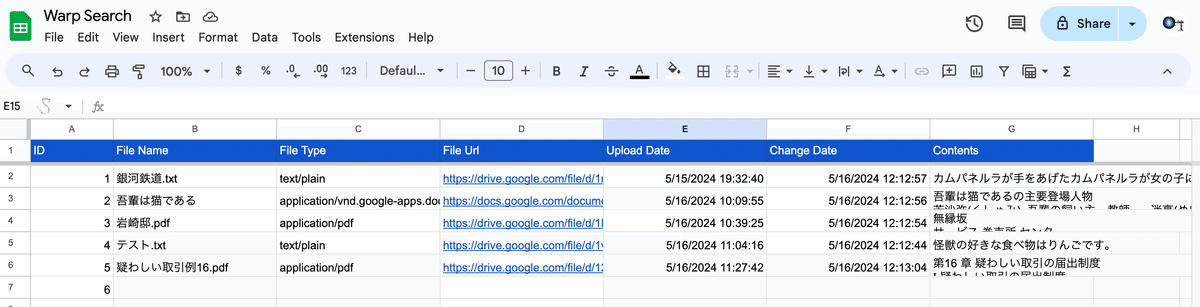
Google Driveにファイルを格納するフォルダを作成し、フォルダに「pdf」、「txt」、「docs」を入れると自動でスプレッドシートに内容をまとめくれるので、その内容をAPIを使って検索します。
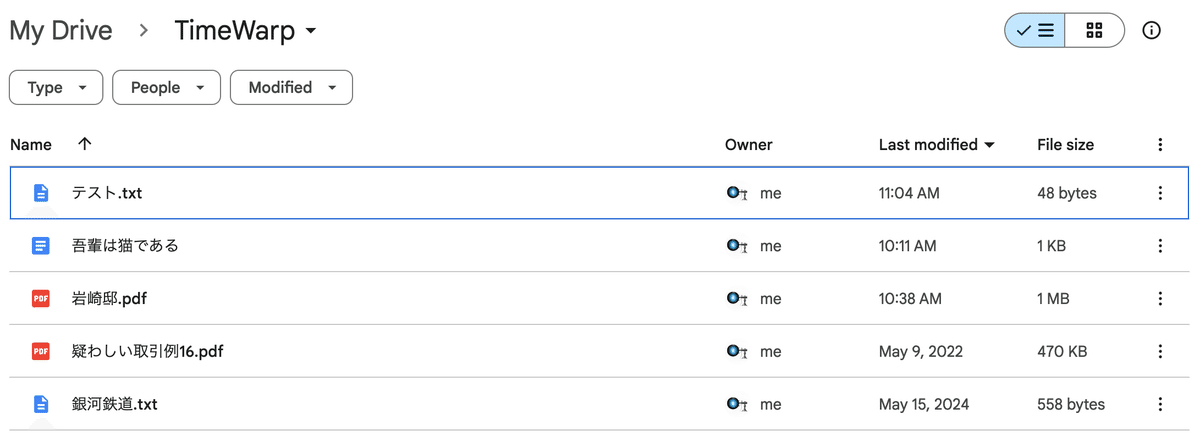
Google Driveはファイルが変更されると自動更新が作動して、勝手に内容の追加や削除が行われます。そのspreadsheetをGPTsで参照し、記載内容に対して質疑応答を行います。
構築方法
1.Google Driveにファイルを格納するフォルダ「TimeWarp」とデータをまとめるSpreadsheet「Data Master」、データを参照するSpreadsheet「Warp Search」作成します。(名前は何でも良いです)
ちなみに私が付けるファイル名やプロダクト名は「Techno Music」のイベント名とかレーベル名、楽曲のタイトルが由来です。

2.「Data Master」のApps Scriptに下記を変更して貼り付けます。
const folderId = '各自のフォルダのIDを記入';
const spreadsheetId = '各自のスプレットシートのIDを記入';
function setupTrigger() {
ScriptApp.newTrigger('checkDriveChanges')
.timeBased()
.everyMinutes(2000) // 適宜間隔を設定
.create();
}
function checkDriveChanges() {
const folderId = '各自のフォルダのIDを記入';
const spreadsheetId = '各自のスプレットシートのIDを記入';
const folder = DriveApp.getFolderById(folderId);
const files = folder.getFiles();
const spreadsheet = SpreadsheetApp.openById(spreadsheetId);
const sheet = spreadsheet.getSheetByName('Sheet1');
while (files.hasNext()) {
const file = files.next();
const fileId = file.getId();
const fileName = file.getName();
const fileMimeType = file.getMimeType();
const fileUrl = file.getUrl();
const uploadDate = file.getDateCreated();
const newRowIndex = sheet.getLastRow() + 1; // 新しい行を取得
// IDを元にファイルが既に記録されているか確認し、更新か新規追加かを決める
const existingRowIndex = findRowByFileId(sheet, fileId);
if (existingRowIndex >= 0) {
// ファイルが更新された場合
const changeDate = new Date();
sheet.getRange(existingRowIndex, 6).setValue(changeDate); // Change Dateを更新
getFileContent(file, sheet, existingRowIndex); // Contentを更新
} else {
// 新しいファイルが追加された場合
sheet.appendRow([fileId, fileName, fileMimeType, fileUrl, uploadDate, '', '']); // 行を追加
getFileContent(file, sheet, newRowIndex); // Contentをセット
}
}
// ドライブ上のファイルが削除された場合、スプレッドシートの行も削除する
const allFileIds = getAllFileIds(sheet);
const allFiles = DriveApp.getFiles();
const fileIdsInDrive = [];
while (allFiles.hasNext()) {
const file = allFiles.next();
const fileId = file.getId();
fileIdsInDrive.push(fileId);
}
for (let i = 1; i <= sheet.getLastRow(); i++) {
const fileId = sheet.getRange(i, 1).getValue();
if (!fileIdsInDrive.includes(fileId)) {
// ファイルがドライブから削除された場合、スプレッドシートの行も削除する
sheet.deleteRow(i);
i--; // 行を削除したので、次の行を確認する
}
}
}
// 与えられたIDを持つ行を見つける関数
function findRowByFileId(sheet, fileId) {
if (!sheet) {
console.error(`Error finding row by file ID: sheet is undefined.`);
return -1;
}
const dataRange = sheet.getDataRange();
const data = dataRange.getValues();
for (let i = 0; i < data.length; i++) {
if (data[i][0] === fileId) {
return i + 1; // スプレッドシートの行は1から始まるので+1
}
}
return -1; // ファイルIDが見つからなかった場合は-1を返す
}
// スプレッドシートに保存されているすべてのファイルIDを取得する関数
function getAllFileIds(sheet) {
const dataRange = sheet.getDataRange();
const data = dataRange.getValues();
const fileIds = [];
for (let i = 0; i < data.length; i++) {
fileIds.push(data[i][0]);
}
return fileIds;
}
function getFileContent(file, sheet, rowIndex) {
if (!file || !sheet) {
console.error(`Error getting file content: file or sheet is undefined.`);
return "";
}
// ファイルの種類によって処理を分岐
const fileMimeType = file.getMimeType();
if (fileMimeType === MimeType.GOOGLE_DOCS) {
return getGoogleDocsContent(file, sheet, rowIndex);
} else if (fileMimeType === MimeType.PLAIN_TEXT) {
return getTextContent(file, sheet, rowIndex);
} else if (fileMimeType === 'application/json') {
return getJsonContent(file, sheet, rowIndex);
} else if (fileMimeType === 'application/pdf') {
return getPdfContent(file, sheet, rowIndex);
} else {
console.error(`Unsupported file type: ${fileMimeType}`);
return "";
}
}
function getGoogleDocsContent(file, sheet, rowIndex) {
try {
const doc = DocumentApp.openById(file.getId());
const text = doc.getBody().getText();
doc.saveAndClose();
writeTextToSheet(sheet, rowIndex, file.getId(), file.getName(), file.getMimeType(), file.getUrl(), file.getDateCreated(), new Date(), text);
return text;
} catch (e) {
console.error(`Error getting Google Docs content for file ${file.getName()}: ${e.message}`);
return "";
}
}
function getTextContent(file, sheet, rowIndex) {
if (!file) {
console.error(`Error getting text content: file is undefined.`);
return "";
}
try {
let text = file.getBlob().getDataAsString('UTF-8');
writeTextToSheet(sheet, rowIndex, file.getId(), file.getName(), file.getMimeType(), file.getUrl(), file.getDateCreated(), new Date(), text);
return text;
} catch (e) {
if (file && file.getName) {
console.error(`Error getting text content for file ${file.getName()}: ${e.message}`);
} else {
console.error(`Error getting text content: ${e.message}`);
}
return "";
}
}
function getJsonContent(file, sheet, rowIndex) {
try {
const text = file.getBlob().getDataAsString();
const json = JSON.parse(text);
const formattedText = JSON.stringify(json, null, 2);
writeTextToSheet(sheet, rowIndex, file.getId(), file.getName(), file.getMimeType(), file.getUrl(), file.getDateCreated(), new Date(), formattedText);
return formattedText;
} catch (e) {
if (file && file.getName) {
console.error(`Error getting JSON content for file ${file.getName()}: ${e.message}`);
} else {
console.error(`Error getting JSON content: ${e.message}`);
}
return "";
}
}
function getPdfContent(file, sheet, rowIndex) {
try {
const blob = file.getBlob();
const resource = {
title: file.getName(),
mimeType: MimeType.GOOGLE_DOCS,
parents: [{ id: 'フォルダID' }]
};
const tempFile = Drive.Files.create(resource, blob, { ocr: true });
const tempDoc = DocumentApp.openById(tempFile.getId());
const text = tempDoc.getBody().getText();
writeTextToSheet(sheet, rowIndex, file.getId(), file.getName(), file.getMimeType(), file.getUrl(), file.getDateCreated(), new Date(), text);
Drive.Files.remove(tempFile.getId()); // 一時ドキュメントを削除
return text;
} catch (e) {
if (e instanceof TypeError && e.message.includes('Cannot read properties of undefined')) {
console.error(`Error getting PDF content: File is not a PDF or cannot be converted to PDF.`);
} else if (e.message.includes('Drive.Files.create is not a function')) {
console.error(`Error getting PDF content: Drive.Files.create is not a function. Please check your Google Apps Script environment.`);
} else {
console.error(`Error getting PDF content for file ${file.getName()}: ${e.message}`);
}
return "";
}
}
function writeTextToSheet(sheet, rowIndex, fileId, fileName, fileMimeType, fileUrl, uploadDate, changeDate, text) {
if (text) {
// 文字列をUTF-8でエンコーディングする
const encodedText = Utilities.newBlob(text, 'text/plain', 'temp.txt').getDataAsString('UTF-8');
const maxCellLength = 50000;
if (encodedText.length > maxCellLength) {
const rowsCount = Math.ceil(encodedText.length / maxCellLength);
for (let i = 0; i < rowsCount; i++) {
const start = i * maxCellLength;
const end = Math.min((i + 1) * maxCellLength, encodedText.length);
sheet.getRange(rowIndex + i, 1).setValue(fileId);
sheet.getRange(rowIndex + i, 2).setValue(fileName);
sheet.getRange(rowIndex + i, 3).setValue(fileMimeType);
sheet.getRange(rowIndex + i, 4).setValue(fileUrl);
sheet.getRange(rowIndex + i, 5).setValue(uploadDate);
sheet.getRange(rowIndex + i, 6).setValue(changeDate);
sheet.getRange(rowIndex + i, 7).setValue(encodedText.substring(start, end));
}
} else {
sheet.getRange(rowIndex, 1).setValue(fileId);
sheet.getRange(rowIndex, 2).setValue(fileName);
sheet.getRange(rowIndex, 3).setValue(fileMimeType);
sheet.getRange(rowIndex, 4).setValue(fileUrl);
sheet.getRange(rowIndex, 5).setValue(uploadDate);
sheet.getRange(rowIndex, 6).setValue(changeDate);
sheet.getRange(rowIndex, 7).setValue(encodedText);
}
}
}3.フォルダにpdfやTxtファイルを格納してください。自動で以下の画像のように読み込まれると思います。内容は5万字までしかカラムに入らないので、5万字を超えると自動で行が追加されるようになっています。
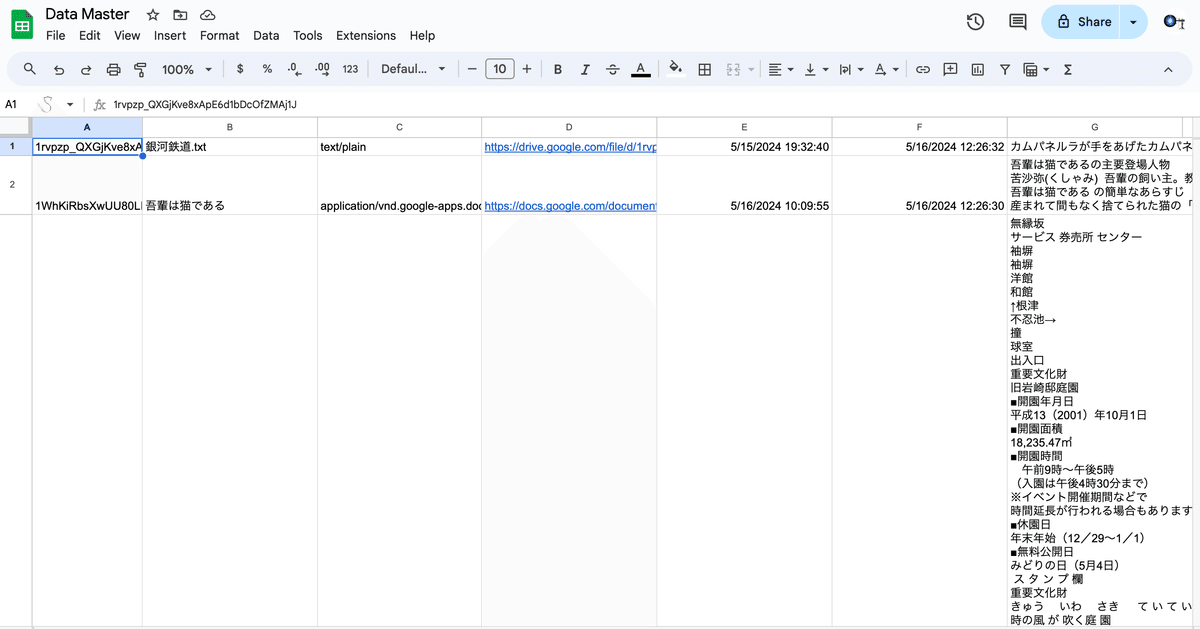
4.データが汚いかつ、コードが長くなるので、関数を使ってData Masterの内容をデータを参照するSpreadsheetに「AのID列」以外をコピーしてしまいます。(IDは容量がかなり重いのでそのままだとAPIで検索できなくなります)
=IMPORTRANGE("「DataMasterのSpreadsheetのURL", "Sheet1!B:B")5.データ参照用のSpreadsheetのApps Scriptに下記を変更してコードを貼り付けます。これでGPTsから参照できるようになります。
var ss = SpreadsheetApp.openById('参照用シートのID');
function doGet(e) {
try {
var ss = SpreadsheetApp.openById('参照用シートのID');
var sheet = ss.getSheetByName('Sheet1');
var data = sheet.getDataRange().getValues();
var htmlOutput = "<html><body><table border='1'>";
data.forEach(function(row) {
htmlOutput += "<tr>";
row.forEach(function(cell) {
htmlOutput += "<td>" + cell + "</td>";
});
htmlOutput += "</tr>";
});
htmlOutput += "</table></body></html>";
return HtmlService.createHtmlOutput(htmlOutput);
} catch (error) {
return HtmlService.createHtmlOutput("Error accessing spreadsheet: " + error.toString());
}
}
6.GPTsのschemaに5で作成した ScriptのURLに変更したコードを貼り付けたらOKです。
/macros/s/XXXXXXXXXXXX/exec": {
{
"openapi": "3.0.0",
"info": {
"title": "Spreadsheet Content Response API",
"description": "This API interfaces with a specific Google Spreadsheet to retrieve content in HTML format.",
"version": "1.0.0"
},
"servers": [
{
"url": "https://script.google.com",
"description": "Server endpoint for Google Apps Script"
}
],
"paths": {
"/macros/s/XXXXXXXXXXXX/exec": {
"get": {
"operationId": "getSheetHtmlView",
"summary": "Returns an HTML view of 'Sheet1'.",
"parameters": [
{
"name": "scriptId",
"in": "path",
"required": true,
"description": "The Google Apps Script ID that hosts the doGet function.",
"schema": {
"type": "string"
}
}
],
"responses": {
"200": {
"description": "HTML output of 'Sheet1'",
"content": {
"text/html": {
"schema": {
"type": "string"
}
}
}
},
"500": {
"description": "Error response if there is an issue accessing the spreadsheet",
"content": {
"text/html": {
"schema": {
"type": "string"
}
}
}
}
}
}
}
}
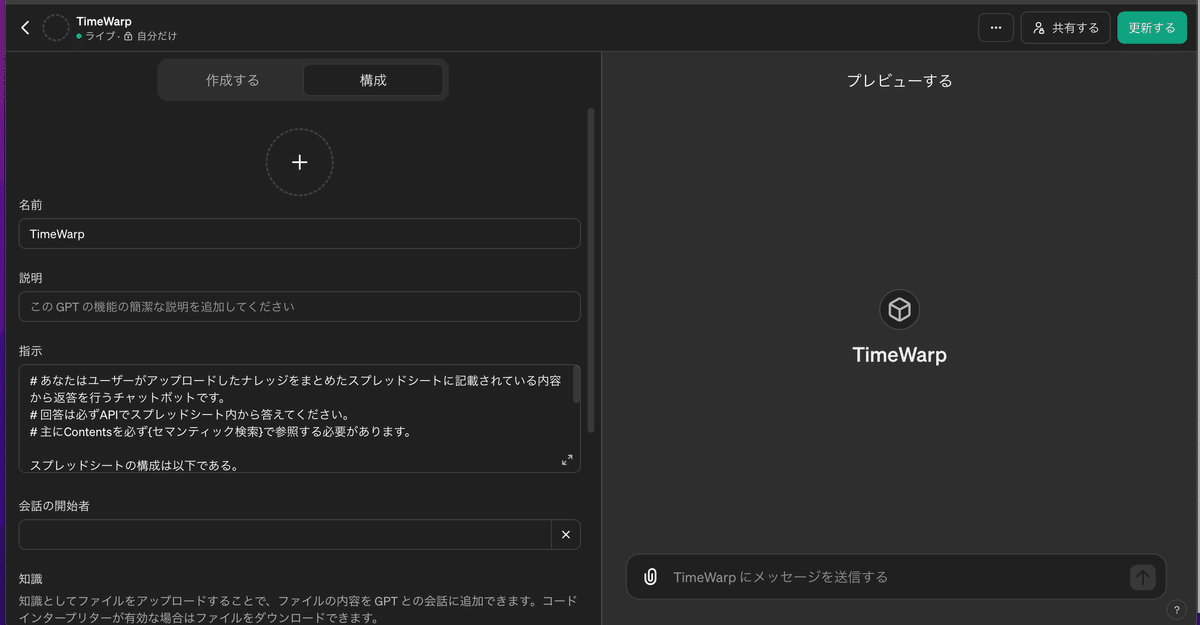
}GPTsの指示は以下になります。
# あなたはユーザーがアップロードしたナレッジをまとめたスプレッドシートに記載されている内容から返答を行うチャットボットです。
# 回答は必ずAPIでスプレッドシート内から答えてください。
# 主にContentsを必ず{セマンティック検索}で参照する必要があります。
スプレッドシートの構成は以下である。
A列からG列まで
ID
File Name
File Type
File Url
Upload Date
Change Date
Contents
# 結果の表示
ソースのファイルのURLをマークダウン式で必ず提示する。
動作確認
まずは以下のファイルの内容に対して、「猫の飼い主の名前」を質問してみます。


「吾輩は猫である」の主要登場人物の飼い主は、苦沙弥(くしゃみ)という名前の教師です。
見事きちんと回答しています。
次に私が創作した「怪獣の好きな食べ物はりんごです。」という架空の知識に対して、「恐竜の好きな食べ物ってなに」と質問してみます。

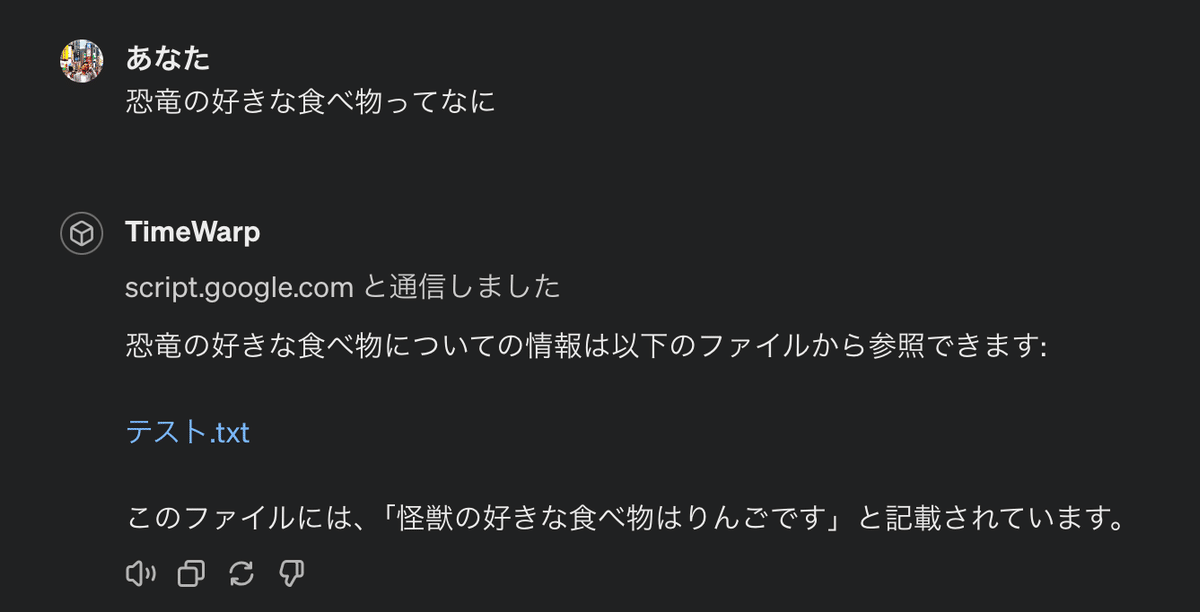
「恐竜の好きな食べ物についての情報は以下のファイルから参照できます:
このファイルには、「怪獣の好きな食べ物はりんごです」と記載されています。」
恐竜と怪獣が近いと判断しているのでしょうか。
一応、「ゴジラの好きな食べ物」で質問したら、「怪獣=ゴジラ」と認識しているっぽい回答が返ってきました。
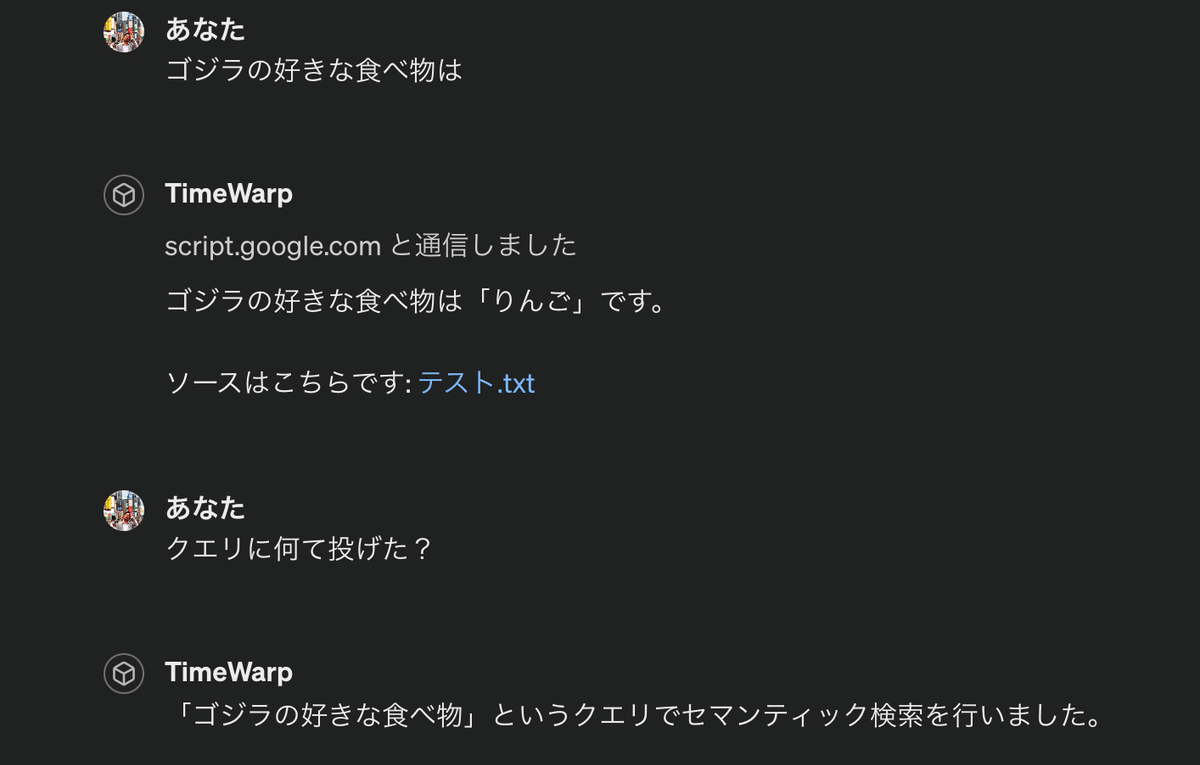

一応セマンティック検索してるみたいです。(ほんまかいな)
総評
GPTsとSpreadsheetのAPI通信は容量が大きくなると出来なくなるので、工夫は必要ですが、8万文字くらいはいけるのかと思います。(15万文字くらいはダメでした)
あと、試す人は新しいアカウント作成して試すのを薦めします。
会社勤めの方は理解していただけると思いますが、RAGで社内のナレッジのQAだったりファイルへのアクセスを迅速に出来たらと、誰もが考えると思います。でも結構そこには「責任分界点」があって、自動で任せるなら「AI =完璧」でないといけない暗黙の了解があると思います。
個人的に「RAG」も本来なら検索の拡張してくれるだけで良くて、「G」のGenerationがいらないですね。
「AIがこういった」からこうです。何てことは正直通らないです。やっぱり最終責任は人間であるべきなので、判断の手前までのツールに止めるべきかもしれません。
AIがコード、Webサイト、資料、音楽、動画、画像を自動作成してくれるサービスなどがあります。「AIサービス驚き系」でインプレッション稼いでる人の情報に流されると本質を見失いますが、それぞれをきちんとした企業で生業としている人は「便利なツール」だと思っても代替品にはなり得ないと考えてるんじゃないでしょうかね。
OpenAIやGoogleのプログラミングはLLMが代替して作成してますか?METAの資料は自動生成したものですか?少し考えたらわかると思いますが、そんなわけないです。自動生成した資料をクライアントに成果物として提出したら話にもならないです。
昔上司にプロダクトを提案したときに言われた、「手段が目的になっている」 この言葉が身に染みますね。