TwitterAPIが死んだので、Yahoo!リアルタイム検索をPythonでスクレイピングしてツイート数のデータを取得する

かつて無料で提供されていたTwitter APIは、イーロン・マスクによる買収などなんやかんやあって有料化されました。有料プランもあるにはありますが、そこそこの価格とそこそこの制限がかかっており、趣味レベルで手を出すのはちょっと憚られる感じのプランになっています。
そこで、TwitterAPIの代替手段として、Yahoo!リアルタイム検索をPythonでスクレイピングすることでツイート推移のデータを取得することにしました。この記事では、その手法(とコード)について書いていこうと思います。
Yahoo!リアルタイム検索とは
Yahoo!リアルタイム検索は、Yahoo!が提供しているTwitterの検索サービスです。ツイート検索やトレンドなどを確認することができます。とても便利でありがたい。
指定したキーワードを含むツイート数の推移を確認することもできます。

今回は、Yahoo!リアルタイム検索のこの画面をスクレイピングして、ツイート推移のデータを取得していきます。
なお、Yahoo!リアルタイム検索の規約ではスクレイピングは禁止されていませんが、過度の負荷をかける行為は禁止されているため、ほどほどの使用にしておきましょう。
ライブラリのインポート
#ライブラリ等のインポート
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import re
import pandas as pd
from datetime import datetime, timedelta
import urllib.parse使用するライブラリをインポートします。
selenium:スクレイピングするやつ
re:正規表現のやつ
pandas:データ処理のやつ
datetime:時間処理のやつ
urllib:URL処理のやつ
必要に応じて自分の環境にインストールしておいてください。
なお、今回のコードはGoogle Colabでは上手く動きませんでした。ローカルでやってください。
検索クエリの設定
# クエリを設定
query = "ワンピース"
query = urllib.parse.quote(query)
url = f"https://search.yahoo.co.jp/realtime/search?p={query}&gm=w"今回の検索クエリは「ワンピース」です。
検索クエリをもとにurlを作成して、ツイート推移が表示されるページのurlを取得しています。
(おまけ1)ヘルプを見ると色んな検索コマンドが紹介されているので役に立つと思います。オススメは「()」で囲んでOR検索できるやつ。
(おまけ2)今回は、直近7日のデータを表示する「7日」タブを開くためにurlに「gm=w」で指定を入れていますが、他のタブを指定することも可能です。
「1日」のタブを開くときは「gm=d」、「30日」のタブを開くときは「gm=m」です。変更した場合はそれに合わせて以下のコードも適宜修正してください。
WebDriverの設定
# WebDriverの設定
options = Options()
options.add_argument("--headless")
driver = webdriver.Chrome(options=options)
driver.get(url)
# 要素が表示されるまで待機
WebDriverWait(driver, 30).until(EC.presence_of_element_located((By.XPATH, "//*[@id='graph']/div/div[3]/div[2]/p/span[1]")))
WebDriverWait(driver, 30).until(EC.presence_of_element_located((By.CSS_SELECTOR, ".recharts-curve.recharts-area-curve")))スクレイピングをするためのWebDriverを設定します。
ヘッドレスモード(実際のブラウザの画面を表示しない)で起動します。
ページを開いた後、取得したい要素が動的に生成されて表示されるまでの待機時間を念の為に設けています。
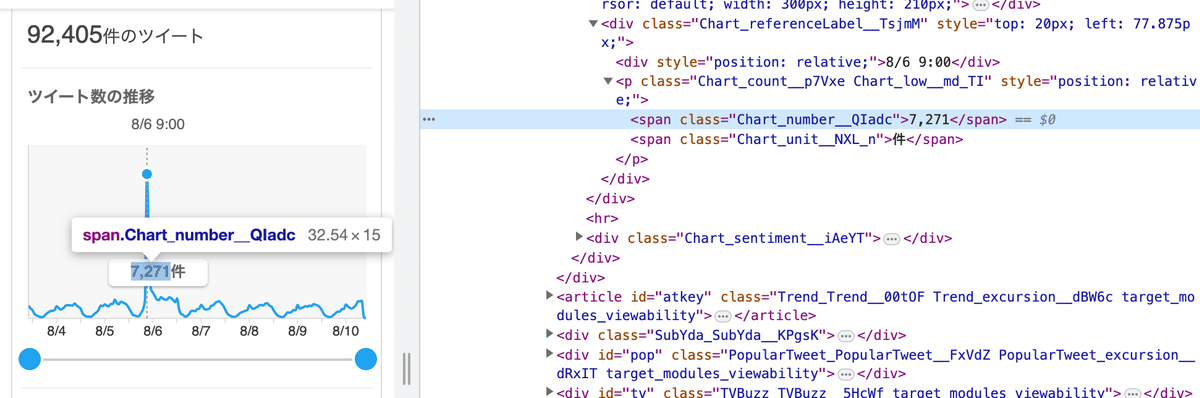
取得したい要素は2つあります。「ツイート推移の曲線」と「ツイート数の最大値」です。
Chromeのデベロッパーツールで確認できます。これも便利。

ツイート推移の取得
# ツイート数の取得
tweet_count = driver.find_element(by=By.XPATH, value="//*[@id='graph']/div/div[3]/div[2]/p/span[1]").text
tweet_count = int(tweet_count.replace(",", ""))
#ツイート推移の取得
time_text = driver.find_element(by=By.CSS_SELECTOR, value=".recharts-curve.recharts-area-curve")
d_element = time_text.get_attribute("d")
modified_string = re.sub(r"[a-zA-Z]", ",", d_element)[1:]
values = modified_string.split(",")[1::6][1:-1]
values = [160 - float(x) for x in values]
max_value = max(values)
#ツイート推移のデータを計算
values = [round((x / max_value) * tweet_count) for x in values]まず、ツイート数の最大値が表記されている要素から数字を取得して、tweet_countという変数に代入しています。
次に、ツイート推移の曲線を取得します。ツイート推移の曲線はSVGのベジェ曲線というやつで表記されています。
M13,149.827C13.542,150.648,14.083,151.469,14.625,152.057C15.167,152.646,15.708,152.611,16.25,153.357C16.792,154.103,17.333,155.882,17.875,156.534C18.417,157.187,18.958,157.192,19.5,157.513C20.042,SVGのベジェ曲線は、終点と制御点を沢山並べることで曲線を表記しています。その中から必要な終点の情報だけを抽出すればツイート数の変化が読み取ることができます。
今回は正規表現を駆使してなんやかんやで取得しました。
ここまでに取得した「ツイート推移の曲線」と「ツイート数の最大値」の2つのデータを組み合わせると、ツイート数を概算することができます(曲線の最大値が100ツイートなら、曲線で半分の高さのところは50ツイート…的な)
時間インデックスの取得
#時間インデックスの取得
now = datetime.now()
start_time = now - timedelta(days = 7, hours=-2, minutes=now.minute, seconds=now.second, microseconds=now.microsecond)
hourly_list = [start_time + timedelta(hours=i) for i in range(24*7-1)]どのツイート数のデータがどの時間のものかを取得します。
今回は7日分のデータ(厳密には現在時刻の6日+22時間前から現在時刻の2時間前)のデータを取得しているので、それに合った丁度いい時間データのリストを作成します。
スクレイピングのコードを回した時間を基準に自動的に作成するようにしています。
結果の表示
#結果の表示
s = pd.Series(values, index=hourly_list)
s.plot()
#WebDriverを終了
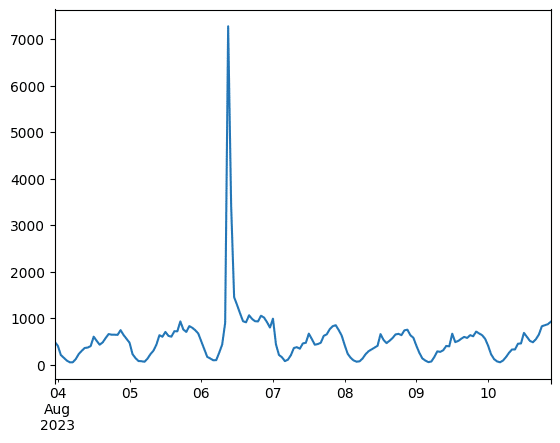
driver.quit()結果をPandasのSeriesとして保存。折れ線グラフでプロットしてみます。いい感じですね。
WebDriverを終了して一連のコードは終了です。
あとは煮るなり焼くなりデータ分析に活用し放題です。
活用例
週刊少年ジャンプの各作品の感想ツイートの数をカウントしてランキングにするのに使っています。
今週のジャンプ関連Twitterデータ。
— シマ (@shima_manga) August 7, 2023
ツイート数1位はヒロアカ。休載を挟んで4話連続の1位です。トレンド入りは5話連続。
呪術廻戦のトレンド入りは3話連続。#wj36 #ジャンプデータ pic.twitter.com/Hs53VRhvBZ
コードの全体像
コードの全体像です。
#ライブラリ等のインポート
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import re
import pandas as pd
from datetime import datetime, timedelta
import urllib.parse
# クエリを設定
query = "テスト"
query = urllib.parse.quote(query)
url = f"https://search.yahoo.co.jp/realtime/search?p={query}&gm=w"
# WebDriverの設定
options = Options()
options.add_argument("--headless")
driver = webdriver.Chrome(options=options)
driver.get(url)
# 要素が表示されるまで待機
WebDriverWait(driver, 30).until(EC.presence_of_element_located((By.XPATH, "//*[@id='graph']/div/div[3]/div[2]/p/span[1]")))
WebDriverWait(driver, 30).until(EC.presence_of_element_located((By.CSS_SELECTOR, ".recharts-curve.recharts-area-curve")))
# ツイート数の取得
tweet_count = driver.find_element(by=By.XPATH, value="//*[@id='graph']/div/div[3]/div[2]/p/span[1]").text
tweet_count = int(tweet_count.replace(",", ""))
print("最大値: "+str(tweet_count))
#ツイート推移の取得
time_text = driver.find_element(by=By.CSS_SELECTOR, value=".recharts-curve.recharts-area-curve")
d_element = time_text.get_attribute("d")
modified_string = re.sub(r"[a-zA-Z]", ",", d_element)[1:]
values = modified_string.split(",")[1::6][1:-1]
values = [160 - float(x) for x in values]
max_value = max(values)
#ツイート推移のデータを計算
values = [round((x / max_value) * tweet_count) for x in values]
#時間インデックスの取得
now = datetime.now()
start_time = now - timedelta(days = 7, hours=-2, minutes=now.minute, seconds=now.second, microseconds=now.microsecond)
hourly_list = [start_time + timedelta(hours=i) for i in range(24*7-1)]
#結果の表示
s = pd.Series(values, index=hourly_list)
s.plot()
#WebDriverを終了
driver.quit()【追記】動いていたコードが急にエラーを吐くようになったときの対処
急に動かなくなりました。
おそらくChromeを更新したことでChromeとWeb driverのバージョンとが一致しなくなったからじゃないかと思います。
バージョンを良い感じに合わせてくれるライブラリ?「chromedriver-binary-auto」があったのでそれを入れます。
Chromeのバージョンを確認して、driverのバージョンを指定します。Chromeのバージョンは設定から確認できます。バージョンの指定は以下のような記述で行います。
pip install chromedriver-binary==118.0.5993.70スクレイピングのコードでインポートしたら動くようになりました。
import chromedriver_binary