
LangGraphでLLMとGoogle検索を繋げる

言語モデルと別のツールを組み合わせて簡単な検索システムの作成のため、LangGraphを使いました。LangGraphはグラフ構造(ノードとエッジ)の概念で状態遷移を管理するため、書きやすさを感じました。
私が学校で教えている講義でも同じ内容を使いました。LLMと別のツールを掛け合わせる可能性、またプロンプトを工夫する重要性などを伝えるのに役に立ったと思います。教育者としての活用方法もアリかも?です。
状態遷移図
ユーザーのインプットから出力まで以下の流れを考えます。

主な処理を行う部分が五か所
【ルーター】
入力テキストに対して、Google検索が必要か判断を行う部分
【検索キーワード抽出】
検索が必要と判断された後、検索を行うためのキーワードを抽出する部分
【検索】
検索キーワードを基にGoogle検索を行う部分
【レスポンス】
・Google検索がされない場合、LLMの知識のみでレスポンスする部分
・Google検索の結果を基にレスポンスする部分
上記の各部分を組み立てていきます。
各部分の構築
環境の準備
Google Colaboratoryでノートブックを開き、ライブラリのインストール
!pip install openai langchain langchain-community langgraphルーターの部分
今回はAzure OpenAIにLLMをデプロイしていますが、他のサービス(OpenAI、Anthropic, …)につなげることもできます。(参照)
# Azure OpenAIのエンドポイントにアクセスするキー
api_key = "キーの入力"
endpoint = "エンドポイントの入力"LangChainを通して、Azure OpenAIにデプロイしたGPT3.5にアクセスします。
from langchain.chat_models import AzureChatOpenAI
llm = AzureChatOpenAI(
deployment_name='gpt-35-turbo-0613', # モデル名
openai_api_version='2023-05-15',
azure_endpoint=endpoint, # クラウドにモデルを置いている場所
openai_api_key=api_key, # アクセスするためのカギ
temperature=0 # ランダム性の調節
)ルーター部分では以下のプロンプトテンプレートを用意します。
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
template_router = '''
{input}
上記の質問に答えるために、Google検索で最新の情報を取得する必要があるか答えなさい。
以下のルールに必ず従うこと。
・google検索が必要な場合は、「google」と出力すること
・必要がない場合は、「default」と出力すること
'''
prompt_template_router = PromptTemplate(
input_variables=['input'],
template=template_router
)
chain_router = LLMChain(llm=llm, prompt=prompt_template_router)定義した「chain_router」の動作を確認するために
chain_router.run('今日の天気')を走らせると出力が"google"と返ってきます。計算が必要ない場合は"default"と返ってきます。
ルーター部分のノードに入れる関数を準備します。
# ルーターのノードに入れる関数
def classify_input(state):
question = state['question']
chain_router = LLMChain(llm=llm, prompt=prompt_template_router)
output = chain_router.run(question)
return {'classification': output}検索キーワード抽出の部分
次に、検索が必要と判断された場合、入力テキストからを基に検索キーワードを準備する処理を作成します。
template_search_keywords = '''
ユーザー入力:
{input}
上記の内容でGoogle検索をするために、検索事項に分解したい。
以下のルールに必ず従うこと。
・異なる物事毎に必ず以下の形式で出力しなさい。(,で区切ること)
物事1, 物事2, 物事3, ..., 物事N
・ユーザー入力以外のテキストは含めないこと。
'''
prompt_template_keywords = PromptTemplate(
input_variables=['input'],
template=template_search_keywords
)
chain_keywords = LLMChain(llm=llm, prompt=prompt_template_keywords)動作を確認してみましょう。
chain_keywords.run('日本とアメリカの文化の比較')結果が"日本の文化, アメリカの文化"となります。
検索キーワード抽出のノードに入れる関数を準備します。
# キーワード抽出のノードに入れる関数
def extract_keywords(state):
question = state['question']
chain_keywords = LLMChain(llm=llm, prompt=prompt_template_keywords)
output = chain_keywords.run(question)
return {'keywords': output}検索の部分
Google検索にAPI経由でアクセスするため、Google Serperを活用します。
Serper(https://serper.dev/)に登録してAPIキーを取得する必要があります。最初の2500回アクセスは無料、またクレジットカード登録不要なので、登録が楽で簡単に試すことができます。
# Serper APIにアクセスするためのAPIキー
# https://serper.dev/
# 👆最初の2500回アクセスは無料(クレジットカード登録不要)
SERPER_API_KEY = 'キーの入力'Serper APIにアクセスする準備をします。
from langchain_community.utilities import GoogleSerperAPIWrapper
search = GoogleSerperAPIWrapper(
serper_api_key=SERPER_API_KEY,
gl='jp',
hl='ja',
k=4 # 4つ検索結果だけ
)最初、GoogleSerperAPIWrapperの引数がよくわからなかったのですが、ソースコードから確認して、日本語の設定方法や検索数の制限の設定方法をみつけました。
以下のコードで動作を確認できます。
search.run('大谷翔平')検索ページからタイトルと下に表示される説明文が返ってきます。
詳細(リンクなど)を含めたい場合は以下のコードが使えます。
search.results('大谷翔平')検索のノードに入れる関数を準備します。
# 検索ノードに入れる関数
def search_keywords(state):
keywords = state['keywords']
list_keywords = keywords.split(',')
output = ''
for keyword in list_keywords:
output = output + keyword + ': \n'
output = output + search.run(keyword) + '\n'
return {'search_result' : output}👆各キーワードにループで複数回検索を行っています。
レスポンスの部分
ユーザーからの入力テキストとGoogle検索結果を基にレスポンスを行うために以下のプロンプトテンプレートを用意します。
template_summary = '''
「{input1}」
以下のGoogle検索結果を基に上記の質問に答えてください。
{input2}
'''
prompt_template_summary = PromptTemplate(
input_variables=['input1', 'input2'],
template=template_summary
)
chain_summary = LLMChain(llm=llm, prompt=prompt_template_summary)検索後のレスポンスノードに入れるための関数を準備します。
# 要約ノードに入れる関数
def summarize(state):
question = state['question']
search_result = state['search_result']
output = chain_summary.run(input1=question, input2=search_result)
return {'response' : output}また、検索なしのレスポンスノードに入れるための関数を準備します。
# デフォルトのノードに入れる関数(検索が必要ないとき)
def handle_default(state):
question = state['question']
output = llm.predict(question)
return {'default_response': output}グラフを組み立てる
ここからLangGraphを使いグラフを組み立てていきます。書き方はドキュメントを基に
しています。
グラフに保持する変数の定義から始めます。
# グラフに保持する変数の定義
from typing import TypedDict, Optional
class GraphState(TypedDict):
question: Optional[str] = None
classification : Optional[str] = None
keywords: Optional[str] = None
search_result: Optional[str] = None
response : Optional[str] = None
default_response: Optional[str] = Noneグラフの初期化を行いノードを加えます。
from langgraph.graph import StateGraph, END
# グラフの初期化
graph = StateGraph(GraphState)
# ノードを加える (ノードの名前と、持たせる関数)
graph.add_node('classify_input', classify_input) # ルーターの部分
graph.add_node('handle_default', handle_default) # 検索なしレスポンス
graph.add_node('extract_keywords', extract_keywords) # 検索キーワード抽出
graph.add_node('search_keywords', search_keywords) # 検索
graph.add_node('summarize', summarize) # 検索後レスポンスルーターから(検索なし)レスポンスと検索キーワード抽出のノードにつなげるエッジを用意します。
def decide_next_node(state):
return 'extract_keywords' if state['classification'] == 'google' else 'handle_default'
# 条件付きエッジを定義
graph.add_conditional_edges(
'classify_input',
decide_next_node,
{
'extract_keywords': 'extract_keywords',
'handle_default': 'handle_default'
}
)ユーザーからの入力はどこか、また終わりはどこかを定義します。また、残りのエッジを加えます。
# 始まりと終わりは?
graph.set_entry_point('classify_input')
graph.add_edge('handle_default', END)
graph.add_edge('summarize', END)
# 残りのエッジを加える
graph.add_edge('extract_keywords', 'search_keywords')
graph.add_edge('search_keywords', 'summarize')これで、グラフの構築終了です。
app = graph.compile()動作を確認してみましょう。
inputs = {"question" : "今日は何月何日ですか、また東京都と大阪の天気はなんですか。"}
result = app.invoke(inputs)
print(result['response'])出力が
「今日は5月23日、東京都の天気は晴時々曇で、最高気温は25℃、最低気温は18℃です。大阪の天気は25℃です。」
とかえってきました。
以下のコードでグラフを可視化できます。
!sudo apt-get install python3-dev graphviz libgraphviz-dev pkg-config
!pip install pygraphviz
from IPython.display import Image
Image(app.get_graph().draw_png())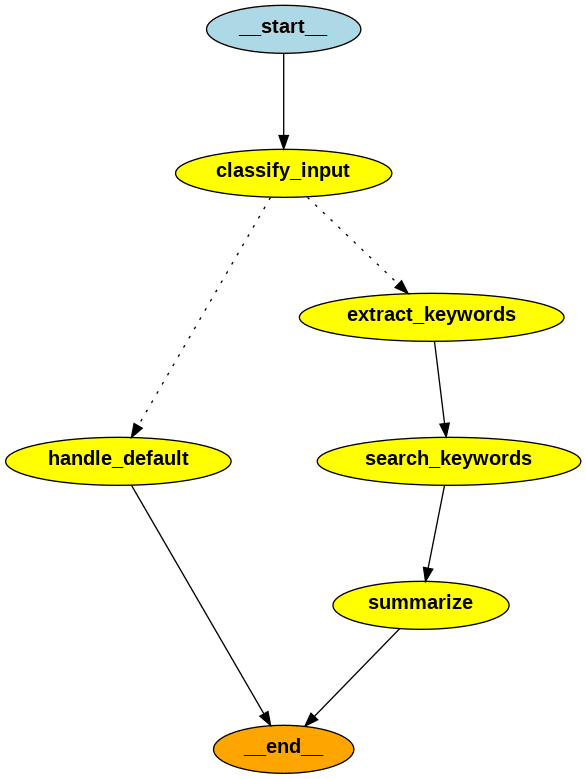
良い感じのものができたといいたいですが、改善の余地がかなりあります。
例えば、「5/22の大谷翔平の成績」と入力すると、検索キーワード抽出が”大谷翔平”、”成績”と不必要な分解が行われ、「5/22の大谷翔平の成績に関する情報は提供されていません。」と返ってきました。
Google検索にそのまま入力しても良いケースがあるため、ルーターの分岐を多くしたりプロンプトを工夫したりと、いろいろ改善点がみつかりました。
ここまで読んでいただきありがとうございます。少しでも何かに役立てば嬉しいです。