
他者モデルのモデルを絵に書いてみたい

僕らは他者と互いに話し合い、議論をし、お互いに共感を得たり、決裂したり、お互いにとって新しいアイディアを得たりします。これは、僕らのなかに他者がいるからです。でも、僕の中に他者がいるとは、より正確にはどういうことでしょう?本稿ではこのテーマで考えてみます。
このテーマについて、主に神経科学・認知科学的アプローチからの研究をまとめた「脳のなかの自己と他者」(2019年 島田総太郎 著)という本があり、参考になります。とくに、4章ではミラーシステム、5章では心の理論、6章では自他が融合・一体化した認知システムについて取り扱われています(超面白いのでオススメ)。これらは、確かに本稿のテーマに対する答えの一部になります。
でも、筆者(僕)がここで扱いたい話は、ちょっとニュアンスが違います。
僕らは、他者との間で議論・討論・闘論などの形で言葉を尽くして話し合い、そのなかで相手の思いを理解し、しかし自分の考えとの矛盾に直面します。自他の考えの矛盾が、ときに新しく整合的な知を生むことがあり、これを弁証法的なアウフヘーベンと呼びます。筆者はこういった知的生産の過程に焦点を当てたい。他者がいるからこそ、自分の中だけで整合的に閉じた思考からは到底たどり着かないところへ行ける。他者性というものの、大きな価値が、ここにあると思うのです。この話題をあえて「脳のなかの自己と他者」の中で探せば、いちおう5章の心の理論に対応する話題が近いのですが、残念ながら少しニュアンスが違います。
ここで筆者が取り扱いたい話題の取っ掛かりとなる大事な鍵として、2019年ごろから世界を騒がしている、巨大計算量を前提とした自然言語処理モデル(Transformer, BERT, GPT-3, etc)があります。これらは、大量のテキストデータを食わせた巨大な深層神経網であり、これに適当な文章をトリガーとして入力してやることで、自然な言語表現を芋づる式に自動的に生成します。自然言語による質問に対して自然な応答を返したり、外国語の文章を日本語に翻訳して出力してくれます。これは要するに、言葉を生成する自動機械です。
「僕にとって他者とは、言葉を生成する自動機械である」と仮定したうえで「これはもう少し正確にはどのような自動機械なのだろうか?」ということを考えたいわけです。
また、これを考えるために、さらには「僕自身が、言葉を生成する自動機械であり、その僕のなかに、他者の言葉を生成する自動機械が含まれている」このように仮定します。
「そんな僕は、もう少し正確にはどのような自動機械なのだろうか?」
これが問いです。
本稿では、ベイズ的生成モデリングの観点からこの自動機械の形をモデリングし、ベイジアンネットワークの方法を用いた図式で可視化してみます。
あらかじめ言っておくと、本稿は「なかなかリーズナブルな可視化ができたんじゃない?」というところで終わります。決して、これで実装してみたとか、実装できるからやってみよう、というところまでは到達しません。それでも、可視化の過程から分かったことがありましたし、これを使ってさらに考えを進めてゆけそうな感触は得られました。それを共有したいと思います。
著者は近い領域のプロ研究者ではあるのですが、この話題については専門性が低いです。類似研究のサーベイはほとんどできていません。本稿は、休日に本務と無関係に趣味で書きました。勝手ななぐり書きとして受け取ってください。どうせどこかで誰かが考えているアイディアか?もしくは箸にも棒にもかからないアイディアなのだろうという予想が個人的に8割です。
でも、こういうのがどこかで誰かの参考になるかもしれないですし、それ以上に、読者からの何らかのフィードバックが得られたら嬉しい。著者を傷つけ過ぎない程度の批判・ダメ出し・関連情報のご提供など、大いに歓迎いたします。
基本的な生成モデル
あらためて、問題の定式的スケッチをしてゆきます。
僕が他者の言動と向き合うとき、僕は他者のなかにこんな構造を見ています。他者の言動の裏には意図があり、意図の裏には思想がある。というモデルです。

図1 の順方向、すなわち 思想→意図→言動 の流れを、生成モデルと呼びます。僕の目から見て、他者の言動は観測可能であり、しかし意図・思想は直接的には観測不能です。そこで、ベイジアンモデリングの作法に則ってこのような図を描きました。思想・意図・言動の各ノードには変数が対応し、変数の値には思想・意図・言動の内容の記号化されたものが格納されているものとします。(注1, 注2, 注3)
(注1) 思想・意図・言動の各ノードに変数が対応する、とは、変数がとり得る値の集合を想定しつつ、実際にいずれかの値をとるということです。現実世界における現象のさまざまなバリエーションを、記号(変数の値)で表現する方法を、記号化(コーディング)の問題と呼びます。(1) 人工知能のためにベストな記号化方法は何か?(2) 人間の脳神経において使われている記号化方法は何か?これらの疑問の答えは現時点では謎ですが、少し説得力がありそうな仮説ということならばいくらか提案されています。
本稿では、記号化の方法に関する議論はあとまわしにします。
(注2)言動とは、言葉と動きの両方を指します。ひとの心のなかに何か言いたいことがあって、それが外に向けて表現されたとき、その表現の総体を指す言葉として用います。後に示すように、さいきん(2021年)のAI自然言語処理で想定されているような言語のモデルを踏まえつつ、それ以外の身体表現を加えるタイプの拡張を想定しています。
言葉だけを指したほうが、ここでの議論はわかりやすいかもしれません。将来的にAIとしての実装に着地しやすいかもしれません。しかし、言葉の字面だけでなく、それを発するタイミングや、付随する身体的仕草にメッセージが乗る状況を考えないと面白くない、という思いから、ここでは一般に「言動」としています。
(注3) ベイジアンモデリングの作法に慣れていない人向けの解説をここに載せておきます。読み飛ばしてください。
ベイジアンモデリングでは、複数の変数間の独立・従属関係を、変数をノードとし、変数間の確率的な依存関係をリンクとしたグラフ構造で表します。このさい、
(1) 変数が確率変数であるか?与えられた決定論的変数であるか?
確率変数であるときは、
(2) その変数が観測可能であるか?否か?
の区別を大事にして可視化しつつ、観測可能な確率変数が、どのような過程で生成されるか?をモデリングします。
モデルを作図するときは、観測可能な確率変数を四角形、観測できない確率変数を丸で示し、そして変数間の従属関係を有向リンクでつないでゆきます。
モデルの原型は、条件付き確率 P( X | A, B ) のように描きます。これを「条件 A, B が与えられたときに確率変数 X の値が確率 P( X | A, B ) で生成される」と読んで、確率変数 X の生成モデルと呼び、グラフでは A → X ← B のように描きます。
2つの生成モデル, P( X | B ) と P( B | A ) を直列につなぐこともあり、グラフでは X ← B ← A のように描きます。
一般に大きなグラフが、ノードを矢印の順にたどって最終的に観測可能な確率変数Xにたどりつくように描かれているとき、これ全体を確率変数Xの生成モデルと呼び、Xにたどり着くノードの流れを順方向の生成過程と呼びます。
観測 X に向かう順方向の生成モデルを与えることができれば、観測 X を用いて逆方向に向かう手順で、未知の確率変数 A, B の事後確率 P( A, B | X ) を計算できます。
(これは初学者がつまづきやすいところなので強調しておきますが)
ベイジアンモデリングでは、真の目的が「観測 X に基づいて確率変数 A, B の事後確率 P( A, B | X ) を計算すること」であるとき、あえて順方向の生成過程 P( X | A, B ) のモデルを立てたうえで、逆方向の計算を行います。
図1 を読み直してみましょう。これは「思想が意図を生成し、意図が言動を生成する」という順方向の生成過程のモデルです。これに対して 図1 の逆方向、すなわち言動から意図を推定し、意図から思想を推定する、という逆方向の過程も合わせて想定されており、計算的に可能なのです。これが、ベイジアンモデリングにおいて大事な点です。
モデルに時間構造を追加する
言動一般を対象としたモデルにおいて、時間構造は大事であり無視できません。記号化したさいに同等となるような言動であっても、それまでの文脈によって異なる意味を持ち得るからです。同様に言動の裏にある意図にも、時間構造を想定するべきです。言動の文脈情報は「意図」のなかに埋め込まれていると考えましょう。この事情を図2のように書くことができます。

意図や、その時間的変動のダイナミクスを表現するうえで、図3のような深層モデルを考えることで、一般に表現力が増します。
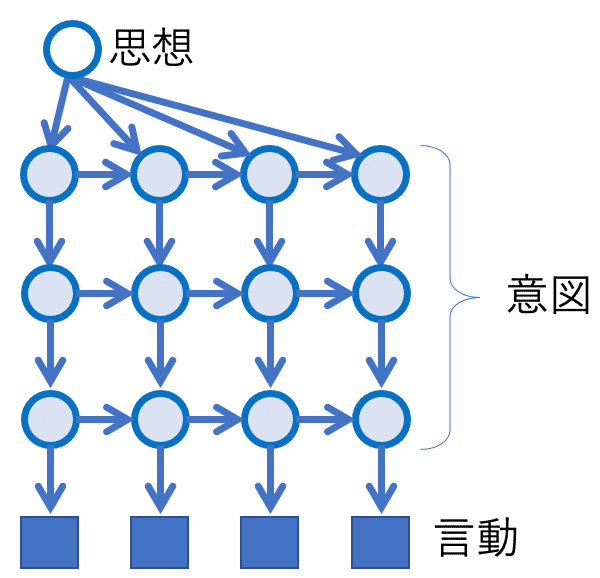
以降では、一般的な可能性として図3のような階層の深いダイナミクスを想定します。というのも、近年の自然言語処理を行うモデル (Transformer, BERT, GPT-1,2,3) などで、深い階層型のニューラルネットワークが高性能を実現しており、これは言動一般のモデリングにおいても同様だろうと思われるからです(注4)。ただ、本稿ではこれ以降、大きな本質的な構造を簡略化して示すためあえて図2のように書くことにしましょう。
(注4) 近年のモデルの成功はリカレントモデルよりもむしろ注意機構によるところが大きいらしいです。ですが、本稿の目的から見たときには本質的ではないので、この違いは無視します。本稿の話題について人工知能としての実装を考えるときには、もちろん Transformer, BERT, GPT 等の実績あるモデルをもとにするべきでしょう。
次にパネル表示という図法を導入します。これもベイジアンモデリングの技術では標準的な書き方です。以下の図4は図2とまったく同等のモデルを、より抽象化した簡略表現で示すことができています。

図2や図4で、とくに「思想」がパネルの外に描かれているのは、これが時系列の外にあって不変であることを意味します。
よく気がつく読者は「相手の思想が時間的に変化することは考えないのか?」という疑問を抱くかもしれません。もちろん考えても良いです。ただ、こういう疑問を抱く読者は、これはあくまでも注目すべき本質を描き出すための簡略化モデルなのだ、ということを思い出してください(注5)。
(注5)モデルは、現実世界の現象を上手に説明し、予測し、操作するためにあります。この目的のためには、モデルを大胆に単純化することが有用であることが多いのです。
このモデルの中で私が意図・思想と呼んでいるものが、世の中で意図・思想と呼ばれている対象と同等である保証はありません。単純なモデルが不適切ならば、モデルに基づいて思考を進めた結果は見当違いなものになるでしょう。しかし、筆者はこの単純化が妥当であろうと踏んで、モデル内のこれら要因に、あえて「意図」「思想」という名前を付けています。
読者は、とりあえず、これらの要因をそういう名前で呼ぶことを認めたうえで、批判的に読み進め、後ほどこれらの名前が妥当であったか否かを判定していただきたい。そのように読んでいただくことを想定しています。
環境要因を追加する
僕が他者の言動から、その意図を、そして思想を推察するとき、僕はその他者が置かれている環境も合わせて見ています。環境要因やその変化を明に示したモデルは図5のように描くことができます。

同じ言動であっても、環境に応じて意味が異なり、したがってそこから読み取るべき意図も異なるものです。拡張したところで、これを図6の右側のように簡略化して描きます。中身は変わりませんが、見やすくなります。

他者との相互作用を追加する
ここから、さらに拡張をしてゆきます。
他者(青のひと)にとって、別の他者(赤のひと)がいる状況を考えます。青のひとにとっての環境として、別の他者がいる状況は、青のひとの思想を知るうえでとても大事です。ひとの思想は、勝手な演説よりも、他者との会話や議論によって、あらわになります。演説であっても、聴衆がいて反応を返す場合とそうでないのとでは、異なるものになるでしょう。
他者(青)にとって、別の他者(赤)がいて、その間に相互作用がある状況を図7に描きます。

図7 の左側は、青のひとも赤のひとも、それぞれが意図と思想を持っており、それぞれの意図はお互いの言動の影響を受けて変化してゆき、意図の変化が言動の変化に繋がり得る、という旨をグラフで表しています。相互フィードバック関係にあると言えます。青と赤の構造は対称です。
図7 の右側では、同じものを少し簡略化して描きました。両者の言動をひとつの黒色ノードでまとめて描き、自他の言動を含む共有世界と名付けました。黒ノードで表される共有世界に、赤・青の言動以外の環境要因を含めることも想定してよいでしょう。これは、コーディングの問題でありモデルの拡張に関して任意性のあるところです。
さて、図7の左側の図を配置だけ変えて(グラフのトポロジー構造は変えずに)描き直しました(図8)。図7 は赤と青が対称でしたので、これを上下で折りたたむとこのような形になります。

図7と図8はグラフとして等価ですが、図8のほうではグラフのノードの解釈(右側のテキスト)に微修正が加えてあります。すなわち、これは全体として青の人のモデルだ、としているのです。赤色で書かれている部分は、青の人の内部にある、赤の人のモデル、すなわち「青のひとが持つ、赤の人についての内部モデルである」ということにしました。
次に、この図を簡略化します。

図9は、図8で描かれた青のひとのモデルを簡略化したものです。青のひとの自分自身の思想と赤のひとの思想をひとつの思想ノードにまとめ、同様に意図や言動についても、赤と青をまとめたノードにしました。一見した形状として図6と図9は同じ形になりましたね。違いはノードの中身に押し込められています。すなわち、図9では「思想」のノードには自分と他人の思想がまとめて入っており、「意図」のノードには自分と他人の意図がまとめて入っており、「言動」のノードには自分と他人の言動がまとめて入っています。こういう違いです。
自他ともに他者の内部モデルを持っていることを想定する
次に、図9のように他者の内部モデルを持つような人が2人いて、こういう人同士が会話する状況をスケッチしてみます。そのモデルは全体としてどのように描けるでしょうか?

図10はトポロジーとして図7と同一です。図7と図10の違いは、思想や意図のノードに押し込められています。思想や意図のノードには、お互いの内部モデルが含まれるということにすると、グラフィカルモデルの形状は同じになるわけです。
こうして、図7 から 図10 までの論理の筋道が、ループになっていることがわかります。
これはおそらく朗報です。
ループを何度も回すことは、他者に関する内部モデルのなかに、他者にとっての他者(例えば自分自身)が繰り返し含まれるようなさらに複雑な状況を考えることになります(図11)。こんな状況も、外形構造としては単純なままで表現可能なのです。ついでに、他者として2人以上を想定する場合についても同様に図9のとおりに書くことができます。

つまり、モデルのモデルのモデルの…のモデルという複雑そうに見える問題は、「モデルの大域的構造の問題ではない」のです。では何の問題なのかというと、結局は「思想・意図の記号化の問題」なのです。もう少し言い換えれば、私のなかの他者のモデルは、思想・意図のコーディングが巧妙であることによって実現しているのです。もしくは、人工知能のなかの他者のモデルは、思想・意図にあたる情報のコーディングを巧妙にすることによって実現できるのです。
ここまでにわかったことは?
結局のところ、この単純に見える構造の外形をいじることなく、思想・意図・自他の言動のノードにあたる情報表現を巧妙にすれば、このなかに他者のモデルを入れ込むことができることがわかりました。
巧妙な情報表現とは、具体的にはどのようなものであればよいのでしょうか?
多数のモジュールがあり、多数の他者のモデルを担当させられる
多数の階層があり、さまざまな抽象度で進む思考に追従できる
時系列に沿った文脈や、文脈の変化に追従できる
変化への追従は、多層的であり、数秒〜数分〜数年といった、スケールの異なる文脈を同時に追従できる
多スケールの文脈を同時に追いつつも、現在フォーカスのあたっている文脈を適切に切り替えられる
などなどなどなど(また思いついたものを加えてゆきます)
そんな都合のよい情報表現なんてあったでしょうか?
あります。言語です。
さらに言えば、言語を取り扱ううえで高い性能を示している、Transformer, BERT, GPT, などなどの汎用言語モデルたちです。
一気に結論に向かおうと思います。
わたしは、これらのポピュラーな汎用言語モデルに、人間が扱い得る限りの多彩な他者のモデルを取り扱うだけのポテンシャルがすでにあると思っています。現時点でそのように見えないのは、ほんのちょっと何かが足りないだけなのではないか。
「自他の言動」にあたるデータの用意のしかた、表現の仕方、分量
他者モデルを用いたタスクの作り方、評価のしかた
このあたりにちょっとした工夫を与えるだけで、それ以外のアーキテクチャに本質的な違いを入れなくても実装が可能な気がします。
突然ですが、最近、カズオ・イシグロの小説をいろいろ読むにつけて、彼の真骨頂は登場人物たちが「噛み合わない会話」を行うところにあるように思っていました。「噛み合わない会話」を生成するのって、他者モデルを使ったタスクとして、とても困難なものだと思うんですよ。
登場人物Aと登場人物Bのそれぞれ固有の言語モデルが用意されており、それぞれの裏に彼ら固有の思想・意図を用意して、会話としては成り立たせながら、しかしその意図が互いにズレる。この会話文を読者が読んで、意図がズレ続けていることを読み取るのだけど、小説家は読者がこれをどう読むか?のモデルも運用しながら、その読み方もコントロールしながら、そこに小説家自身の思想を込めているわけです。
「噛み合わない会話シーン」を通じて何かを描き出そうとする、っていうのは、よく考えてみると相当に大変なタスクだと思う。
— shigepong (@shigepong) December 19, 2021
(GPT-N に「噛み合わない会話を生成して」と言って、これを成功させられるとしたら N はどのぐらいの値になるだろうか?)
もちろん、こんなことがいまの人工知能言語モデルにできるわけではないですが、将来の言語モデルがこれを可能にするような方法があるんじゃないか、あったらいいな、ありそうだな、なぜなら、他者のモデルを考えるからといって、本質的に異なるアーキテクチャが必要になるわけではないんだから。
以上が本稿のとりあえずの結論になります。
いやはや、長くなっちゃった。わざわざ読んでくださったかた、どうもありがとうございました。
この記事が気に入ったらサポートをしてみませんか?