
自動入札を理解する!機械学習の基礎

【注意】独学で得た知識を基に書いています。
また、初学者向けのため極端に内容をデフォルメしている箇所があります。それに伴い、厳密な定義からは外れる説明も含みます。
いつのまにか新年度が迫ります。
毎年恒例、新メンバーが増える時期です。
WEBマーケターへの道でつまずきやすい筆頭である機械学習の理解を促進するため、まずは基礎編を書いていきます。
私たちが普段使っている自動入札(クリック最大化、CV最大化、目標CPA、目標ROAS…)の裏側で何がどう動いているのか?
根本理解を助けられれば幸いです。
新卒のマーケターを意識して書いていますので、初歩的な内容を含みます。※本文中のリンクを踏むと、その用語を検索できます。
例:IS
1. 機械学習とは?
広義には、人工知能(AI)がビッグデータを解析し、背景にあるルールやパターンを発見することです。
広告学習における機械学習は、広告主の目的(コンバージョンを増やしたい)が達成されやすい条件や傾向を発見して、その傾向が強いユーザーへ強く入札をかけることで目的を達成しやすくすることを指す場合が多いです。
ユーザー属性(年齢 / 性別 / 居住地…)
シチュエーション(検索行動 / 曜日 / 時間帯…)
アセット(画像 / テキスト / コンテンツ…)
これら条件をどのように解釈していくか?という仕組みを「アルゴリズム」と言います。
広告の最適化のほかに、以下のように使われます。
売上予測・自動運転・顔認識・音声認識・文章要約・自動翻訳・ゲーム解析
2. 機械学習の3パターン
機械学習のパターンは以下のように分類されます。
ここでは「教師あり学習」のみを詳細に説明します。
教師なし学習はセグメンテーションに便利だったりと使いどころも多いので、気になる方はぜひ調べてみてください。
| 教師あり学習
入力した内容と、それに一致する正解データを合わせて蓄積していく学習。
「線形回帰」や「決定木」などをベースにアルゴリズムが発展しています。
教師あり学習は手元にある変数の関係性を表すことに長けています。
| 線形回帰
例えば以下のように考えてみましょう。
目的変数:コンバージョンのしやすさ
説明変数:ユーザー属性 / シチュエーション / アセット
これを学習していくことで、説明変数それぞれがコンバージョンのしやすさにどれくらい強い傾向があるかを発見することができます。
少しわかりにくいので更に簡易化していきます。
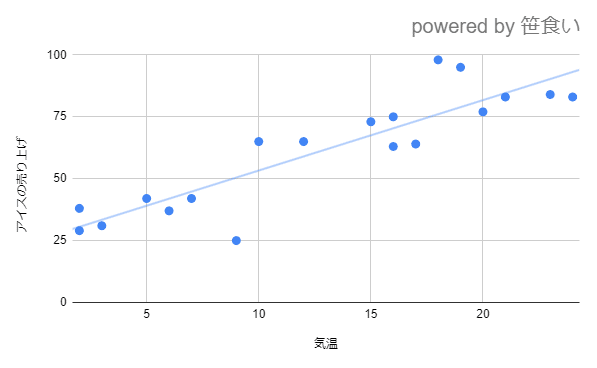
目的変数:アイスクリームの売り上げ
説明変数:気温
上記のように分析すると、
気温(説明変数)が1度上がれば
アイスクリームの売り上げ(目的変数)が5億増加する
というようなデータを発見することができます。
説明変数を増やしてみましょう。
目的変数:アイスクリームの売り上げ
説明変数:気温、湿度、風の強さ
このように分析した時、気温・湿度・風の強さが1単位上がるごとにどれだけアイスクリームの売り上げに影響するのか発見できることでしょう。
このように、説明変数をどんどん増やして多項式の回帰分析に拡張することで表現力を高くできます。
これが「線形回帰」です。
目的 / 説明変数ともに変化し続ける値にとても強いです。
| 決定木
例えば以下のように考えてみましょう。
目的変数:コンバージョンのしやすさ
説明変数:サイト訪問回数
サイト訪問数を基準に考えると、ユーザー属性が例えば大きく2つにわかれるかもしれません。
結果、以下図のように分布が確認できる場合があると思います。
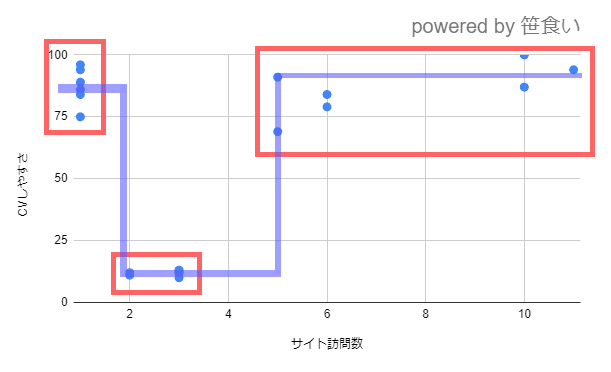
結果的に2-4回訪問ユーザーは凹んでいます。
このような場合に回帰分析を使うと、多項式にして表現力を高めた場合でも正確な表現をしにくいでしょう。
サイト訪問回数が1の時→CVしやすさは75以上
サイト訪問回数が2-4の時→CVしやすさは25未満
サイト訪問回数が5以上の時→CVしやすさは70以上
このように枝分かれして事象を説明すると、説明と事象の誤差が少なくなります。
これが「決定木」です。
説明変数のレンジによって目的変数の傾向が分かれる場合に強いです。
【補足】表現力について
ちょくちょく出てきた「表現力」
これは回帰分析における説明変数や決定木における枝分かれの数を増やすことで、「手元にある数値からの誤差が少なくできる」という意味です。
表現力は高ければ高いほどいいのでしょうか?
これは実は「NO」です。
例えば以下のアイスの売り上げと気温の図を見てください。

青い点(今あるデータ)からの誤差は極端に小さくなりました。
ですが、点がない部分の確からしさはどうでしょうか?
気温が5度の時、アイスの売り上げは前後と比べて急上昇するでしょうか?
気温が7度の時、アイスの売り上げは前後と比べて急落するでしょうか?
このように、現数値に近付けることを重視しすぎるがあまり肝心の「予測精度」が落ちてしまう要因、あるいはその事象を「過学習」と言います。
そもそもの目的である「予測のための機械学習」という意識を忘れてはいけませんね。
【さらに補足】
このような「過学習」を防ぐモデルは賢い人がたくさん考えてくれています。天下のGoogleなんて言わずもがな。
コンバージョンアクションを極端に増やさない限りは、実際の運用で心配することはありません。
過学習を防ぐ手法としては、リッジ回帰、ラッソ回帰などが有名です。気になった方は調べてみてくださいね。
3. 広告における機械学習の活用
先述の通り、広告の最適化にも機械学習は大きく貢献しています。
広告主の目的(コンバージョンを増やしたい)が達成されやすい条件や傾向を発見して、その傾向が強いユーザーへAIが強く入札をかけることで目的を達成しやすくなります。
広告運用の場では、これらの条件や傾向の中身を「説明変数」ではなく「シグナル」と称されることが多いですね。
把握しておくべきなのは
・入札戦略
・入札の正体 の2つです。
更に、何らかの「コンバージョン」を重視する場合、以下の二つも追加されます。
・コンバージョン設定 / 価値
・アトリビューションモデル
順番に行きましょう。
①入札戦略
入札戦略とは、「何をもって成功とするのか?」を広告媒体に明確に与える内容です。
ブランド認知なのか、サイト流入数なのか、資料のダウンロード数なのか、「広告配信を以て獲得したいものが何なのか」を定義することと言えます。
手動入札については私の宗教に反するので割愛します。
他の人のNoteを見てください。
入札戦略の中身は随時更新があり得るので、各媒体ヘルプを確認するようにしましょう。
主要な3媒体のリンクを載せておきます。
▼Googleの入札戦略
▼Yahoo!の入札戦略
▼Facebookの入札戦略
②コンバージョン設定 / 価値
以降はコンバージョン関連の入札戦略を中心に説明します。
基本的に、「コンバージョン数最大化」なら「設定されているコンバージョンアクションの総計を内訳を問わずに最大化させる」という単純な構造です。
つまり、前章で言うところの「目的変数」がコンバージョンとなり、「説明変数」は各媒体が取得・活用できるすべてのWEBシグナルおよびオフラインイベントになります。
それでは、設定コンバージョンが複数ある場合などは、「目的変数」が複数設定されるのでしょうか?
これは厳密には正しくなく、コンバージョンの最大化で運用する場合、目的変数は「コンバージョンとして設定されたすべてのイベント総計」となり、内訳などの考慮は度外視されます。
つまり、
・極端に発生頻度が低いAというCVイベント
・発生頻度が高いBというCVイベント
という設定だった場合、本当に目指したいのがAというCVイベントだったとしても、箱を開ければ100件中100件がBだった、ということも当然あり得るわけです。
それでは「コンバージョン値の最大化」なら価値付けがなされるから安心でしょうか?
そんなことはありません。
最終的に重視するイベントがAの時、Aに強くCV値を付与するとしましょう。
・CVR0.1%のAというCVイベント(CV値:1万円)
・CVR10%のBというCVイベント(CV値:1000円)
上記のようなケースで考えてみましょう。
設定コンバージョンが複数あるので、目的変数はCVイベントそれぞれではなく最終的な「CV値の総計」となります。
極端な思考実験で、以下条件でCV値の総計を計算してみましょう。
広告費全てをイベントAのために投資する
(条件)クリック単価100円 / 広告予算100万円
※CVR0.1%のAというCVイベント(CV値:1万円)
CVR10%のBというCVイベント(CV値:1000円)
- クリック→1万
- イベントAの発生回数→10回
- CV値総計→10万円
広告費全てをイベントBのために投資する
(条件)クリック単価100円 / 広告予算100万円
※CVR0.1%のAというCVイベント(CV値:1万円)
CVR10%のBというCVイベント(CV値:1000円)
- クリック→1万
- イベントBの発生回数→1,000回
- CV値総計→100万円
結果、CV値をAに強く設定したにも関わらず、「イベントBに全額ツッパした方がCV値最大化できるな!!!」と広告媒体は判断してしまう可能性が高いわけです。
これは目標CPA、目標ROASの場合も基本構造は同じです。
CPA、ROASの算出に使うCV数・CV値の算出は同じフローを踏むからです。
この結果に対して、「Aの方が欲しかったのに」なんて愚痴を言っても、機械学習モデルは人間じゃないので「CV数(値)は最大化できたのに、何を言っているんだ?」と一笑に付されるだけです。機械なので笑いませんが
③「入札」の正体とは
上記の通り、入札戦略に沿って広告媒体は突き進みます。
では、どのように「最大化」する入札が行われるのでしょうか?
目的変数:コンバージョン
説明変数:各媒体が取得・活用できるすべてのWEBシグナルおよびオフラインイベント
上記の通りなので、目的変数を最大化させるモデルに沿って、最も良い結果が得られると推測される説明変数の要素に一致する入札対象のオークションへ参加・入札がなされます。
当然ですが、この「モデル」は機密事項であり明確なアルゴリズムは伏せられています。そのため、公式発表を基にした私個人の推測を大きく含みますのでご了承くださいませ。
また、この内容は日々進化していくためあくまで執筆時点のものです。
Googleの場合、この「説明変数の要素」は以下の通り2つに分類できると推測しています。
1. ユーザー
2. 検索語句
検索語句はそのままです。
CVしやすい「検索語句」を指します。
CVしやすい「ユーザー」については、Googleが取得できる以下のような情報全てを対象に判断されると考えられます。
年齢 / 地域 / 性別 / 世帯年収 / 扶養家族 / アフィニティ / 前後の検索語句 / 曜日・時間帯 / シーズン …
書ききれないほどのオンラインシグナルと、場合によっては広告主が提供するオフラインシグナルを基に目的変数(CV数 / 値)を最大化できるモデルをくみ上げ、予測し、その一致する要素が多いユーザーと検索語句に対して入札をかけるということです。
ここで留意すべきことは「過去データを基に予測モデルは作られ、未来を予測して入札がなされる」ということです。
過去データに準拠はしますが、あくまでそこから導き出される「予測」を基に入札がなされます。
完全に過去をトレースしたものでなく、モデルを基に「このユーザーもCVしやすいだろう」というような予測を用いて入札はなされることに留意してください。
例えば「特定のユーザー属性への入札が弱まっている」という事象の場合、「現モデルだとそのユーザーはCVしにくいと推測できる」と媒体は判断している可能性があります。
④アトリビューションモデル
「アトリビューションモデル」も重要な要素です。
CVをどのように評価するか?という内容です。
たとえば、家電量販店でPCが1台売れました。
これは誰の功績でしょうか?
・家電量販店で接客した店員A
・売れ筋だから、と入荷を決めた店長B
・来店のキッカケを作った公式アプリの通知
・認知のキッカケを作ったポスティングチラシ
広告においても考えかたは同じです。PCで考えます。
・最後にクリックされたPCモデル名の検索キーワード
・PCモデル名を知るきっかけになった「PC オススメ」というキーワード
・買い替えを決意させた「PC 寿命 何年」というキーワード
さて、ここは何か特別な信条がない限り「全部のタッチポイントに功績があるな」と考えると思います。
そんな人はGoogleなら「データドリブン」のアトリビューションモデルを選択しておけばまず問題ないでしょう。
おわりに
今や、よほど特殊な操作でない限り人の手で入札単価をコネコネする時代は終わりました。
自動入札なら不眠不休で、高い精度で、膨大な情報を基に調整をかけてくれます。
委ねましょう。
私たちが努力すべきは、それを高い精度でコントロールすること・ユーザーの本質的な分析・クリエイティブのPDCA・本質的なマーケティング戦略。一例ですが、これらです。
ただ、学習はブラックボックスなので振り回されていた人も多いでしょう。
そんな人たちへ向けて、このNoteは書きました。
独学なので鵜呑みにはできないかと思いますが、少しでも参考になればいいなと思います。