StableDreamFusionをgoogle colabで試してみた。

StableDreamfusionとは
StableDreamFusionはtextやimageから3Dモデルを生成するOSSのツールです。
リンク
準備
Google Colabを開き、メニューから「ランタイム→ランタイムのタイプを変更」でランタイムを「GPU」に変更します。
環境構築
インストール手順です。
! git clone https://github.com/ashawkey/stable-dreamfusion.git
%cd stable-dreamfusion
# fix the commit
! git reset --hard e496e35df6e9b67784c3b24504cd61a2e7c19a0d
# install requirements
! pip install -r requirements.txt
! pip install git+https://github.com/NVlabs/nvdiffrast/
# install CUDA extensions (takes about 8 minutes!)
! pip install ./raymarching
! pip install ./shencoder
! pip install ./freqencoder
! pip install ./gridencoder推論
(1) dreamfusion training settings
DreamFusionを学習させるためのパラメータです。ここにtext promptも入れます。
Prompt_text = "a zoomed out DSLR photo of a baby bunny sitting on top of a stack of pancakesr" #@param {type: 'string'}
Training_iters = 5000 #@param {type: 'integer'}
Learning_rate = 1e-3 #@param {type: 'number'}
Training_nerf_resolution = 64 #@param {type: 'integer'}
# CUDA_ray = True #@param {type: 'boolean'}
# View_dependent_prompt = True #@param {type: 'boolean'}
# FP16 = True #@param {type: 'boolean'}
Seed = 0 #@param {type: 'integer'}
Lambda_entropy = 1e-4 #@param {type: 'number'}
Max_steps = 512 #@param {type: 'number'}
Checkpoint = 'latest' #@param {type: 'string'}
#@markdown ---
#@markdown ####**Output Settings:**
Workspace = "trial" #@param{type: 'string'}
# Save_mesh = True #@param {type: 'boolean'}
# processings
Prompt_text = "'" + Prompt_text + "'"(2) Training
import torch
torch.cuda.empty_cache()
%run main.py -O --text {Prompt_text} --workspace {Workspace} --iters {Training_iters} --lr {Learning_rate} --w {Training_nerf_resolution} --h {Training_nerf_resolution} --seed {Seed} --lambda_entropy {Lambda_entropy} --ckpt {Checkpoint} --save_mesh --max_steps {Max_steps}50epoch学習します。
(3) Mesh Inference
%run main.py -O --test --workspace {Workspace_test} --save_meshtrial/mesh/の配下にmtl, obj, albedo.pngが生成されます。
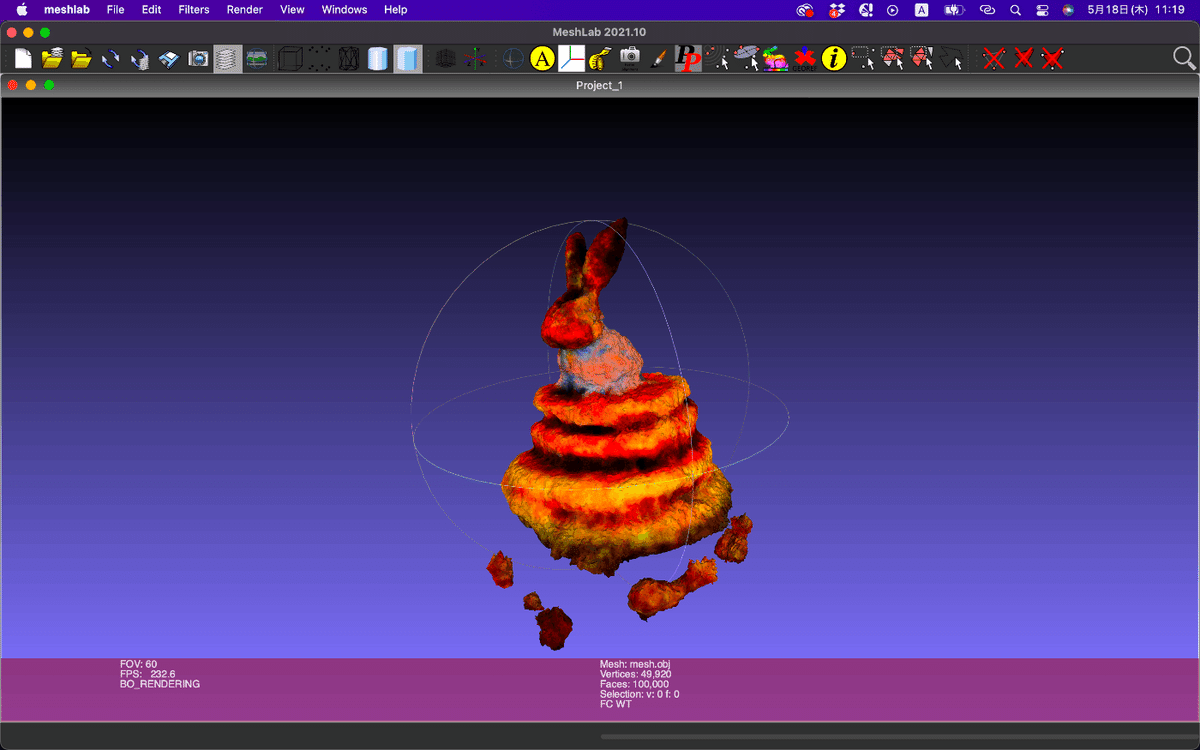
Meshlabで可視化します。
(4)動画にして出力
import os
import glob
from IPython.display import HTML
from base64 import b64encode
def get_latest_file(path):
dir_list = glob.glob(path)
dir_list.sort(key=lambda x: os.path.getmtime(x))
return dir_list[-1]
def show_video(video_path, video_width = 600):
video_file = open(video_path, "r+b").read()
video_url = f"data:video/mp4;base64,{b64encode(video_file).decode()}"
return HTML(f"""<video width={video_width} controls><source src="{video_url}"></video>""")
rgb_video = get_latest_file(os.path.join(Workspace, 'results', '*_rgb.mp4'))
show_video(rgb_video)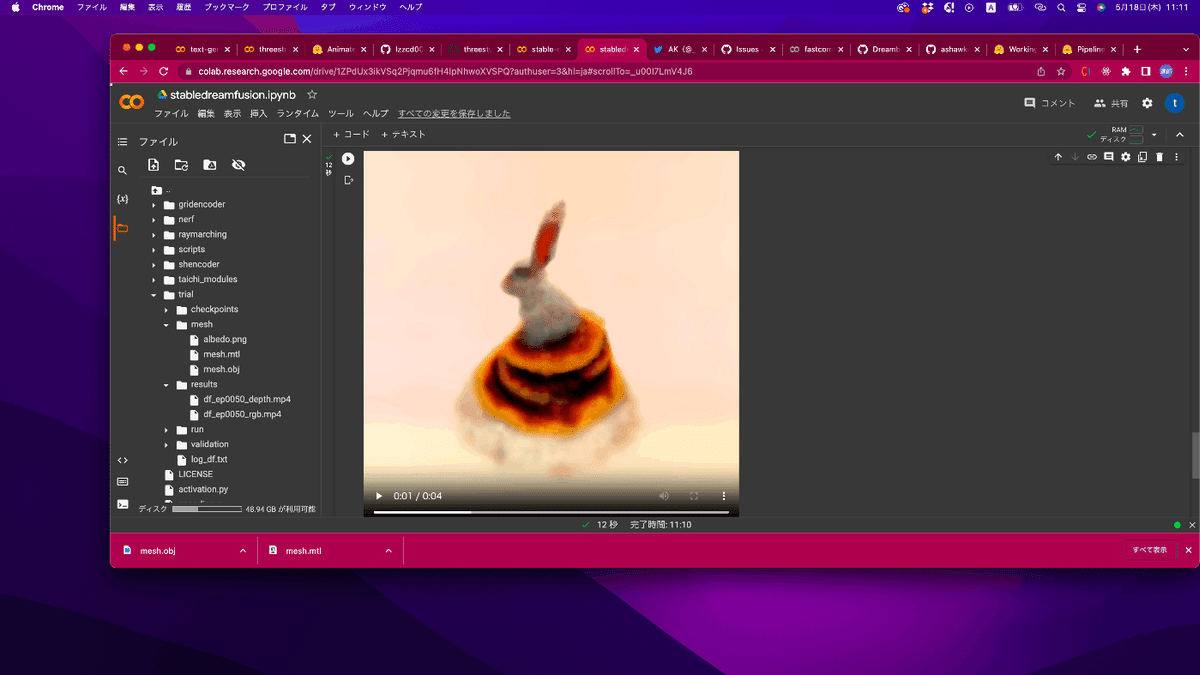
最後に
今回はDreamFusionを簡単に使えるStabledremfusionをgoogle colabで使用してみました。
結構いい感じで3Dモデルが出力されていますね。ただ少しローポリ感は否めない。
Meshlabで出力するとメッシュが変な感じになるのはなんでなんでしょうか?
生成するための学習時間は結構あるので類似画像検索と組み合わせたりしないと実用アプリケーションで活かすのは難しそうですね。
今後ともLLM, Diffusion model, Image Analysis, 3Dに関連する試した記事を投稿していく予定なのでよろしくお願いします。