
AQUILA2のテクニカルレポート紹介[BAAI]

タイトル
AQUILA2 TECHNICAL REPORT
リンク
https://arxiv.org/pdf/2408.07410
ひとこと要約
英語、中国語のバイリンガルモデルであるAquila2のテクニカルレポート。独自のHeuriMentor(HM)を採用し、効率的な訓練に成功。
メモ
Aquila2とは
7B、34B、70Bパラメータの二言語(中国語・英語)モデルシリーズ
HeuriMentor(HM)フレームワークを用いることで、従来の学習に比べて効率的な学習を実現
HeuriMentor(HM)
HMフレームワークの構成要素は以下3つ。
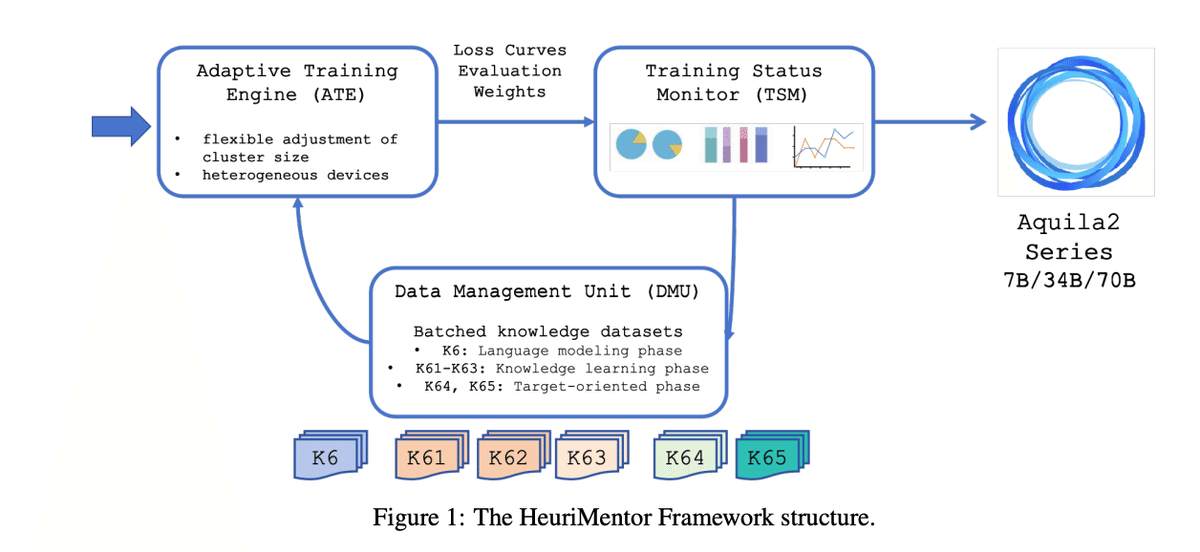
Adaptive Training Engine (ATE)
データの並列処理、FlashAttion-2等を用いて訓練速度を向上
異なるデバイスでの訓練等に柔軟な設計
Training State Monitor (TSM)
損失、パフォーマンス、重みの分布を監視して修正
Data Management Unit (DMU)
学習データの管理
信頼できるソースの選択しリスクのあるデータを削除
重複排除
3段階の学習のためのデータ管理(データ構成は以下図)
言語モデリング段階:基本的な言語理解のため高品質データ(K6)での初期学習
知識学習段階:専門的な知識を徐々に増やすために、知識集約型データ(K61-K63)の追加して学習
タスク指向段階:特定の課題に対応できるように、特定のタスク(K64,K65)のデータを追加して学習

Aquila2の精度

全体的性能
Aquila2-34Bが最も優れた性能を示し、平均スコア72.20を達成。特に中国語タスク(76.56)で高いスコアを記録し、英語タスク(68.63)と良好な結果
NLPタスク
BoolQ(88.84)、CLUEWSC(85.93)、HellaSwag(82.51)など達成
推論能力
統合推論データセット(IRD)でそれぞれ70.0%と75.0%のスコアを達成
マルチモーダル能力:
POPE(87.05%)やCMMU(約41%)で良好な成績

主観的・客観的評価の両方で、比較対象のモデルと比べて最高スコアを達成
HeuriMentor(HM)の効果
ATE
訓練速度の向上
Aquila2-34Bの訓練速度:約666トークン/秒/GPU
柔軟性の向上
訓練中にクラスターサイズを変更や異なるデバイスでの訓練が可能
TSM
リアルタイムモニタリング
訓練中のモデルの状態に応じてデータを調整可能=>これにより、モデルの収束が加速し、性能が向上(したと筆者らは主張している)
DMU
データ利用の効率化
Aquila2-34Bは約1.8兆のバイリンガルトークンで訓練。これは、LLaMA2-70B(2兆トークン)やQwen-14B(3兆トークン)と比較して少ない。
データ選択と品質管理プロセスにより、約3%の潜在的に問題のあるデータを除去