LLMニュースまとめ[2024年10月6日~10月12日]

2024年10月6日~10月12日のLLM関連のニュースとして有名なもの、個人的に刺さったもの11点を以下にまとめる。
1. GSM-Symbolic
LLMの論理的推論能力に疑問を投げかけている論文。
数値を変更したり、非属性の節を追加したりするだけで、LLMの数学的推論性能が著しく低下した。これによりモデルが論理的推論を行っているのではなく、むしろ学習データからパターンを模倣していることを示唆しており、数学的推論の進歩に関するこれまでの指標に疑問を投げかけている。
2. Only-IF:Revealing the Decisive Effect of Instruction Diversity on Generalization
LLMの新しい指示に対する一般化する能力についての論文
指示の多様性が十分でない場合、モデルは新しい指示に対して一般化できないことが判明。さらにデータの多様性を増やすことで、モデルの性能が向上することが示された。
3. Addition is All You Need for Energy-efficient Language Models
浮動小数点数の乗算を整数の加算で近似する新しいアルゴリズム「L-Mul」を提案。エネルギー効率の向上に期待。
4. MART: MLLM as Retriever
MLLM(Multimodal Large Language Model)を用いた新しいマルチモーダルリトリーバル手法「MART」を提案。
従来のテキストや画像の類似性に基づいた過去の行動データを検索ではなく、MARTはこれまでに行った行動や観察の「軌跡(trajectory)」に基づいて判断する。またMARTでは長い行動の流れを短くまとめ、重要な情報のみを保持している。(軌跡の要約(Trajectory Abstraction))

5. Everything Everywhere All at Once
LLMが「タスクの重ね合わせ」と呼ばれる現象を示し、複数の異なるタスクを同時に実行できる能力を持つことを実証。
6. Astute RAG
元から持っている知識(内部知識)と、外部知識を上手く組み合わせるAstuteRAGを提案。
7. Inheritune: Training Smaller Yet More Attentive Language Models
言語モデルの効率的なトレーニング手法「Inheritune」を提案。
Inherituneでは、大きな事前学習済みモデルから初期の数層を引き継ぎ、それを基に小さなモデルをトレーニングする。
8. TLDR: Token-Level Detective Reward Model for Large Vision Language Models
大規模な視覚言語モデル(VLM)の出力を評価に役立つToken-Level Detective Reward Model(TLDR)を提案。TLDRは、各トークン(単語や記号)に対して個別に評価を行い、どのトークンが適切でどのトークンが不適切かを示す。

9. Inference Scaling for Long-Context Retrieval Augmented Generation
ロングコンテキストが必要なRAGにおいて、ICL&デモンストレーションベースのRAG(DRAG)を組み合わせた反復デモンストレーションベースRAG(IterDRAG)を行うことで、推論リソースがRAGのパフォーマンスをほぼ線形に向上させることを示した。

10. Self-Boosting Large Language Models with Synthetic Preference Data
LLMの自己強化(Self-Boosting)の新しい手法「SynPO」を提案。
人間の選好データを自動で生成して自己強化するのが特徴。
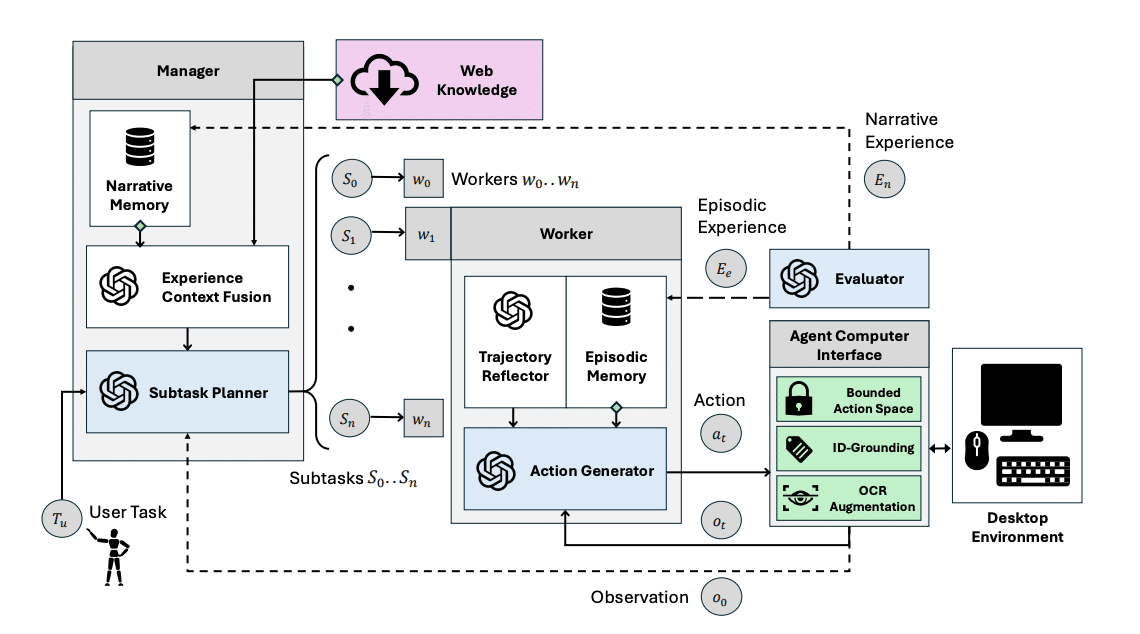
11. Agent S
Agent Sは、複雑なデスクトップタスクを自律的に実行するためのオープンなエージェントフレームワーク。
ドメイン知識の獲得、長期的なタスクの計画計画、動的で非一様なインターフェース(エージェント-コンピュータインターフェース(ACI))を扱うことで複雑な問題に対処。