
LLMニュースまとめ[2024年9月30日~10月5日]

2024年9月30日~10月5日のLLM関連のニュースとして有名なもの、個人的に刺さったもの9点を以下にまとめる。
1. Contextual Document Embeddings
周辺文書を考慮した文書埋め込みを提案。
エンコーダーのアーキテクチャを変更し、隣接文書の情報をエンコードに組み込めるようにし、トレーニング時に隣接文書を明示的に取り入れて学習を行っている。

2. ENTP: Encoder-only Next Token Prediction
ENTP:エンコーダーのみのトランスフォーマーを使用して次のトークンを予測する。エンコーダーとデコーダーの表現力が異なることを示している。

3. SFR-Judges
SFR-Judges: ポジティブおよびネガティブなデータから学習することで、他のモデルの出力を評価する能力を向上させる、評価バイアスに対しても強い耐性。
4. Hyper-Connections
residual connectionの改良手法であるハイパーコネクションを提案。ハイパーコネクションにはDepth-connectionsとWidth-connectionsがあり、前者は異なる深さの接続を同時にモデル化できるようになり、後者は同じ層内の隠れベクトル間で情報を交換するためのものである。

5. QUANTIFYING GENERALIZATION COMPLEXITY
SCYLLA:モデルのパフォーマンスを訓練データに含まれるデータ(ID)と含まれないデータ(OOD)で評価し、タスクの複雑さに応じた一般化と記憶の関係を明らかにするフレームワーク。
タスクの複雑さが増すにつれて、IDとOODデータのパフォーマンスギャップが広がり、ある点でピークに達した後、再び狭まるという「一般化の谷」(generalization valley)と呼ばれる現象が確認。このピークは「臨界複雑さ」(critical complexity)と呼ばれ、モデルが記憶に依存する度合いが最も高くなるポイントを示している。
モデルのサイズが大きくなると、この臨界複雑さがシフトする。
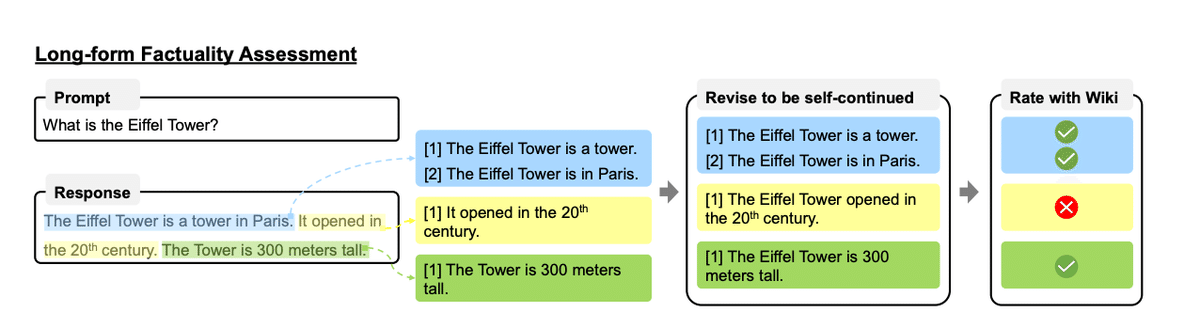
6. FactAlign
FACTALIGN:大規模言語モデル(LLM)が生成する長文の応答の事実性を向上させるためのフレームワーク。生成された長文を細かい文単位で評価し(具体的には信頼できる情報源(例えば、ウィキペディア)に基づいているか評価し)、事実に基づいた内容に整合させる。
7. Law of the Weakest Link: Cross Capabilities of Large Language Models
大規模言語モデル(LLM)の能力を個別に評価するだけでなく、複数の能力を組み合わせた「クロス能力」(Cross Capabilities)に焦点を当てている論文。タスクの遂行能力は複数能力の内、弱い方に引っ張られる。

8. Emu3: Next-Token Prediction is All You Need
Emu3: 画像、テキスト、動画を扱うことができるモデル。具体的には、画像や動画をトークンに変換し、それを使って次に来るトークンを予測することで、生成や理解のタスクをこなす。
9. Ruler: A Model-Agnostic Method to Control Generated Length for Large Language Models
RULER:「メタ長トークン(MLT)」を使用して、応答の長さを制御できるようにする手法。MLTではモデルが生成する応答の長さを示す特別なトークンを使用している。