
【Suphx論文解説⑥】Global Reward Prediction

今回からいよいよSuphxの特徴である「3つの機能」の解説です。
・Global Reward Prediction (👈今回はココ!)
・Oracle Guiding
・run-time policy adaption
前半部分は麻雀プレイヤー向けの直感的な説明、後半はガチ勢向けの技術的な説明です。
まずは直感で理解する
麻雀プレイヤー向けのユルめの解説を先にしておきます。
麻雀は1半荘あたり8~12回の対局を行い、その総得点を競うゲームです。そのため、以下のような駆け引きが重要となります。
・南1局ライバルの親番を早い手で流す。
・南3局で50000点くらい持っていれば無理せず、降り気味に打つ
・オーラス、ラス落ち回避のために1000点で三着を確定させる
麻雀の上級者は点棒状況を常に気にしながら、スピード重視 or 打点重視で行くかを考えています。「ここで2000点アガっておけばオーラス満貫条件に持ち込める。だからスピード重視で行こう」といった感じです。
”ここで2000点”という部分を計算するのがGlobal Reward Predictionです。Global Reward Predictionというのはその局にどんな手を目指せばいいのかを示す目標値なのです。
実際に具体例を見てみましょう。
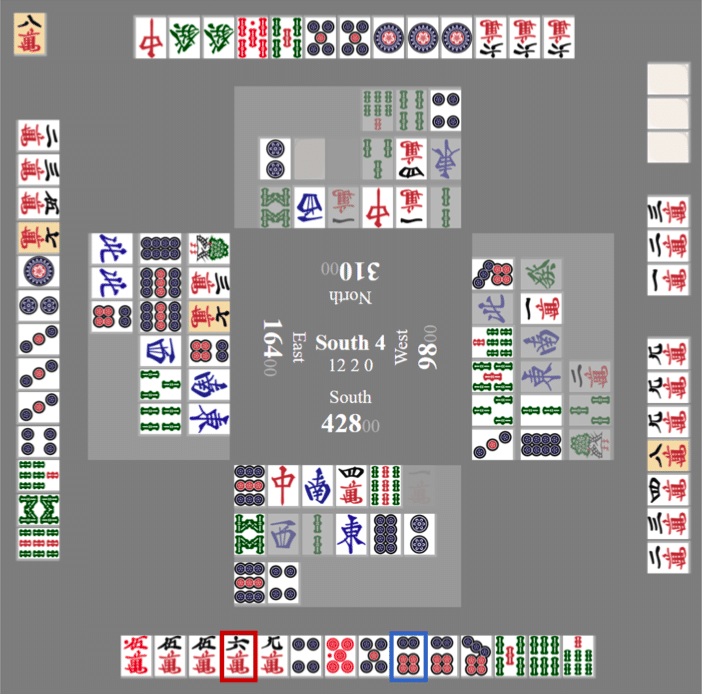
この盤面はSuphxの論文で紹介されているものです。
オーラスで自分がトップ目42800点持ち、ドラ8mで切り番です。一応テンパイを取れますが、9m切りはフリテン3面待ち。下家が染め手っぽい捨て牌なので、人間なら降りるところでしょう。
この状況でSuphxはどうするかというと…
Global Reward Prediction有り:🀞6p切り 😊
Global Reward Prediction無し:🀌6m切り 😱
こうなります。6m切りはかなりリスキーですね。無謀にも程がある。
何故こんな打牌をしてしまうのかというと、「5つの戦術モデル」にはリスクマネジメントという観点がないからです。押し引き判断ができないので、常に効率重視でアガリに向かって猪突猛進してしまいます。
要するに「Global Reward Predictionが押し引きの基準として機能する」ということですね。ある時は「戦略的撤退」、ある時は「ブキギレ全ツッパ」。このような人間に近い打牌選択が再現可能になります。
ゆるめの説明はここまで。
ここから先は技術的な話に興味がある人向けです。
強化学習によって5つの戦術モデルを改善する
これまでの解説記事で教師あり学習(ニューラルネットワーク)による「5つの戦術モデル」について説明してきました。
先ほどの例のように、教師あり学習だけではオーラス間際の押し引きのような繊細な判断ができません。この部分を強化学習によって改善します。

Suphxでは上図のような構成で強化学習を行います。
左の「環境」は対局が行われるシミュレータです。まずは環境から観測された盤面の情報が「状態S」としてエージェントに送られます。送られた状態Sは「方策P」に入力されます。この方策Pというのは「5つの戦術モデル」であるニューラルネットワークです。ここで適切な「行動A」が出力され、環境にフィードバックすることで対局を進めていきます。これを繰り返して、最終的な「報酬R」が決まります。
この報酬Rの良し悪しで「5つの戦術モデル」の改善を行っていきます。
自己対戦による強化学習
では具体的にどういう流れで強化学習を進めるのでしょうか?普通に考えれば実際の天鳳でSuphxを打たせて学習すればいいと思うかもしれませんが、それでは学習に途方もない時間が必要となってしまいます。
その問題を解決するためにSuphxでは自己対戦型(self-play)の分散強化学習 を利用します。文字通り「自分自身のコピーとの対戦」によって強化学習を行う手法です。これはAlphaGoでも使われている手法です。
何それ😳?って感じですね。多分ほとんどの人はイメージがわかないでしょう。そんなアナタにドンピシャな具体例があります。
大ヒット国民的ニンジャ漫画「NARUTO」です。NARUTOの作中では自分の影分身と修行するシーンが出てきます。

https://jumpmatome2ch.biz/archives/84308
影分身というのは文字通り自分の分身(コピー)を作り出す忍術のことです。この影分身の術…実は各コピーが経験したこと・学んだことを後で本体に集約することが出来ます!これにより「一人が二十年かかる修行でも千人なら約一週間でいい」という、チートのような学習が可能になるのです。
自分の分身を作り(分散処理)
→ 自分の分身と戦って(self-play)
→ 経験値を後で集約する(パラメータ更新)
…これもうNARUTOと一緒やん!(無理矢理)
実際のSuphxでは下図のような仕組みで学習します。

図の左側(Self-play workers)はSuphxの影分身が戦っている場所だと思ってください。Inference Enginesでは方策P(5つの戦術モデル)が動いており、対局シミュレーション(環境)に対して打牌選択・鳴き判断などを行います。
状態Sと行動Aの送受信を一定回数をこなしたら、右側のパラメータサーバで経験値をバッファに蓄積していきます。その結果をもとに、方策Pの(5つの戦術モデルの)パラメータ更新を行います。およそ150万対局のシミュレーションを行なっているそうです。
このように「5つの戦術モデル」をブラッシュアップしていきます。
麻雀では何を報酬とすれば良いのか?
強化学習で重要なキーワードである「報酬R」についてまだ説明していませんね。実はここにSuphxの強さの秘訣が隠されています。
報酬を決めるポイントは2つです。
【① 一半荘ではなく、一局ごとに報酬を用意する】
麻雀は半荘のトータルスコアを競うゲームです。そのため、「最終順位」や「最終持ち点」を報酬にすれば何となく良さそうに思えます。
ところが、実際はそんなうまくいきません。「良かった局/悪かった局」の区別がつかなくなってしまうためです。「オーラスバカヅキしてトップ取れたけど、ラス前に下手くそな放銃した。」みたいな経験ありませんか?結果よければ全てよし!ではうまく学習が進みません。一局ごとに反省していくべきですね。
【② 単純な点棒収支ではなく、点棒状況を考慮した報酬を用意する】
じゃあ「一局ごとの点棒収支」を報酬とすれば良いのでは?と思うかもしれませんが、そこでもまだ問題があります。
麻雀ではアガリに向かわなくていい特殊な場面(60000点以上のトップなど)があり得ます。配牌からオリ気味に打つのが最善の場合もあるでしょう。ということは、その局の点棒収支がマイナスであっても、それが悪手だとは限らないということになります。時には戦略的撤退も必要です。
それでは適切な報酬を設計するには、一体どうすれば良いのでしょうか?
「一局ごとに最終持ち点を予想する」
これがMicrosoftの答えです。
最終持ち点から逆算して最善策を考える
例えばラス前に12000点のハネマンをあがって60000点持ちのトップ目になったとします。そんな時に「この調子で行けば70000点overも夢じゃない!オーラスも頑張るゾォ!」と考える人はいるでしょうか…?もちろん、そんな人はいませんね?天鳳ルールなら何点持ちでも同じ一着です。最終的に50000~60000くらいで落ち着くと予想して、サシコミなどを考えても良いでしょう。
逆に東3局に18000に放銃して7000点持ちのダンラスになってしまった場合はどうでしょう。親番があれば無限の可能性がありますが、一先ずラス抜けしたいですね。原点復帰を目指して満貫くらいはアガりたいところです。
このように我々人間は、最終持ち点をイメージし、そこから逆算することで「今の局で目指すべき行動」を考えることが出来ます。これを実現するのがGlobal Reward Predictionです。
Global Reward Predictionとは?
さて、それでは最終持ち点を予想するにはどうしたら良いでしょうか?
実は株価予測と同じ要領で最終持ち点を予測することが出来ます。株価予測では過去の情報をもとに、未来の情報を予測します。
それと同じように、Suphxではそれまでの局での情報を入力データとして最終持ち点を予測します。この機能をGlobal Reward Predictionと呼びます。Global Reward Predictionは「終局時の持ち点を予測するニューラルネットワーク」です。

下の「Round 〇〇 info」というのが入力データです。具体的には各局ごとの点数に関連する情報(点棒収支や持ち点、本場など)です。東1局から現時点での局まで、各局ごとに入力していきます。入力されたデータはニューラルネットワークの計算を経て、最終的には「終局時の持ち点の予測値」が出力されます。
【入力】各局の情報 → 【出力】終局時の持ち点
入力と出力だけ抑えておけば大丈夫です。
ここでは再帰型ニューラルネットワーク(Recurrent Neural Network:RNN)とよばれる特殊なアルゴリズムを用いています。RNNは教師あり学習の一つであり、時系列データをうまく扱うことが出来るのが特徴です。LSTMが有名ですが、SuphxではGRUという手法が採用されています。図中では(おそらく精度向上のために)途中で二層のニューラルネットワークに接続されています。詳しくは下記のリンクをご覧ください。
Global Reward Predictionの学習
学習に用いる教師データには「トッププレイヤーの点数推移のデータ」を使っているそうです。おそらく鳳凰卓のプレイヤーの牌譜を使っていると思われます。コードは非公開ですが、損失関数の数式は紹介されています。

具体的な手順は下記の通りです。
① その局での「予測持ち点」を求める
② 実際の「最終持ち点」との差を求める
③ 全局ごとに二乗誤差を求める ※絶対値を考えるため二乗する
④ ①〜③を学習データの全てのゲームで計算する
⑤ その平均値を最小化するようにパラメータを調整する
いや難しいですね。(ぶっちゃけ僕も完全に理解できてません。)
要するに、下図の赤矢印が出来るだけ小さくなれば良いのです。

ここから先は考察ですが、おそらく東1局時点での予測値にほとんど意味はありません。東1局の情報だけではあまりにも情報不足のため、予測の余地がないと考えられるからです。Global Reward Predictionが効果を発揮するのは南入してからじゃないかなと思います。「東場は大胆、南場は繊細」というのは人間も同じですね。
※Global Reward Prediction自体の精度は論文中には載っていませんでした。どれだけ正確に予測できるのかは気になるところです。
状況に応じて柔軟に報酬を変化させる
ただし、予測値をそのまま報酬として扱うわけではありません。
「今局での予測値」と「前局での予測値」の差分
を報酬として用います。
実際の点棒推移を考えてみましょう。
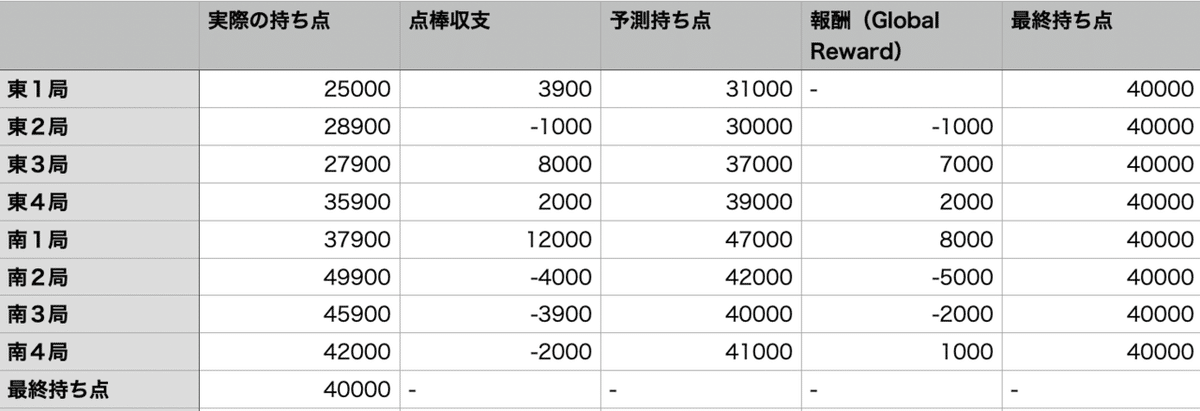
※予想持ち点は僕が適当に決めているので、あくまでもイメージです。
例えば東3局での報酬は
(東3局での予測値)-(東2局での予測値)
というように求めます。
■東3局で8000点アガった
東2局での最終持ち点予測値:30000
東3局での最終持ち点予測値:37000
→ 報酬:2000
■南3局で3900点を放銃
南2局での予測値:42000
南3局での予測値:40000
→ 報酬:-2000
■南4局で2000点を放銃
南2局での予測値:40000
南3局での予測値:41000
→ 報酬:1000
点棒収支と報酬をグラフにしてみます。

東3局&南1局でダントツになったので、後半はかなり引き気味に打ったと仮定しています。
グラフでみると、南2局の放銃は残り局数が多いので罪が重い(報酬がマイナス)のに対し、南4局での放銃はむしろ褒められる(報酬がプラス)というような状況がわかりますね。
仮に「点棒収支(青棒)」を報酬にしてしまった場合は、その局の点棒状況を全く考慮しません。東発での失点とオーラスでの失点が同じ事象とみなされてしまいます。こんな教育方針では「オーラスでも必死にアガリに向かっていってしまうアホAI」に育ってしまうかもしれません。
一方、「予想持ち点の差分(緑棒)」を報酬とした場合は、状況によって報酬の値が柔軟に変化します。「攻めるべき局はしっかり攻めて、降りるべき局はしっかり降りる」という教育も可能でしょう。
まとめ
長かったので重要なポイントをまとめます。
・self-playによる分散強化学習を利用して学習を効率化している
・麻雀では「各局ごと」に「戦略的な」報酬を考える必要がある
・Global Reward Predictionで最終持ち点を予想し、最善策を見つけ出す
・Global Reward Predictionが押し引きの判断基準になる
Suphxの「ダマ選択」や「先切り」の背後には、このような緻密な計算が隠れています。配布検討する時には「最終的にどれくらいの点数を目指しているんだろうか」という視点を持つと、Suphxのお気持ちに近づくことが出来るかもしれませんね。
この記事が気に入ったらサポートをしてみませんか?