
[オタク機器日記] ローカルLLMに必要となるCPUメモリの話

今回もローカルLLMの話
さて先日の記事で、こんなウワサに流されてしまったことを報告した。
"llama.cpp(llama_cpp_python)、メインメモリよりモデルサイズが大きい場合はuse_mmap=Falseにする必要があるらしい。"
そもそもCPUメモリはOS等でも使用されているから、メインメモリとローカルLLMのモデルサイズというのが、今一つ意味不明である。その記事で報告したように、別に64GBメモリしか搭載していない拙者の貧弱PCでも、4bit量子化版Command R+ 改造版160B版は問題なく動作してくれたでござるよ。
記事を投稿した後で、ウワサの出所が紹介されていた。すごい誠実な御方のようで、嬉しい限りである。
「……..なるほど」である。
議論された日付を見ると2023年6月頃というのが分かる。今もそうだけれども、この頃のLlama.cppは超発展途上にあった。部分的にしかVRAMにモデルをオフロードしない場合、CPUとGPUへのアクセス等に改善の余地があり、性能が大幅に低下する状況だった。
だから当時のLlama.cpp利用者の設定は二択で、「モデル全てをGPUのVRAMへオフロードする」か、「モデル全てをCPUメモリへオフロードするか」だった。
もちろんCPUメモリの場合は仮想メモリを利用することが可能だった。ただし何でも仮想メモリへスワップさせることはできない。だから今でも変わらないけれども、例えばCPUメモリ8GBマシンで64GBを超えるようなモデルサイズのGGUFファイルでLLMを実行しようとすると、「モデルをロードできないのでLLMを実行できません」と表示されて終わってしまう。
ちなみに64GBメモリだと当時は仮想メモリへスワップさせた時の性能低下が酷かったので、ここでもLlama.cppがLLMを実行できない事態となる。その時に「性能が低下しても構わないから頑張って貰う」という設定をする方法が、上記のスレッドで議論された。
ちなみに現時点でもCPUメモリサイズ64GBで64GBのLLMモデルサイズという状況だと、動くことは動くけれども、どうも応答(生成)結果が今ひとつである。どうもこの挙動はLlama.cppがハードウェア資源を見て決定しているっぽくて、やはり4bit量子化版Command R+ 104B版を実行する場合には、16GB以上のVRAMを搭載したGPUがあると嬉しいという印象だ。
(12GBのVRAMを搭載したGPUだと、古のNVIDIA TITAN Xしか保有していないの。さすがにこれでは試す気にはなれない)

応答(推論)内容はともかく、意外に出力が速いことに驚かれた方も多いかと思う。ちなみにIntel CPUユーザは、llama.cppではOpenBlasを利用したIntel.MKL設定が推奨されている。しかし上記の例では特に使用していない。単純にLlama.cppディレクトリでmakeコマンドを叩いただけだ。だからモチロン、BLAS=0 … つまりGPUも使用しない設定になっていることが実行結果の画面から分かる。
(なおOpenBlasとは、CPUで数値計算するためのライブラリらしい。単純にCPUを使うだけよりは良い結果を期待できるようだ)

さてこうなると「当たって砕ける野良エンジニア」としては、歌って踊ることは出来ないけれども、「約64GBサイズのGGUFファイルとなっているLLMを、64GBを超えるCPUメモリで試したらどんな結果になるだろうか?」という興味が湧いてくる。
"When targeting Intel CPU, it is recommended to use llama.cpp for Intel oneMKL backend."
そんな訳で「好奇心、猫を殺す」ではなく、「好奇心、オノセーの財布を空にする」で、とうとう128GBメモリに手を出してしまった。できれば暫く頑張って、第14世代以降へ進むことを狙っていたので、無念の限りである。
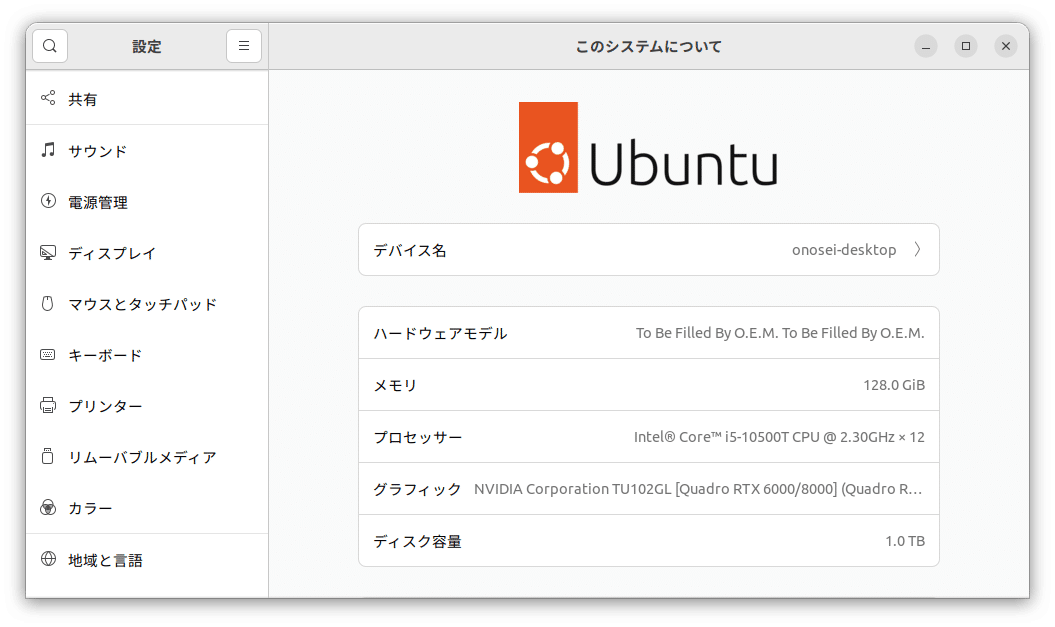
と、いう訳で、一応48GBのVRAMであるNVIDIA Quadra RTX 8000に妥当と一般的には言われている128GBメモリをポチってしまったという訳である。残念ながら今はIntel GPU ARC A770方面で忙しいので、結果はそのうち報告させて頂きたいと考えている。
なんだか冒頭画像のように雲行きが微妙になりつつある気もするけれども、一方で少し明るい雰囲気を感じつつもある今日この頃である。
それでは今回は、この辺で。
ではまた。
ーーーーーー
記事作成:小野谷静(オノセー)