
世界一わかりやすいゼロ知識証明 Vol.1: A Gentle Primer on Ethereum

このブログ記事は、こちらのブログ記事をそのまま転載したものです。
執筆に際して、フィードバックとレビューをしてくださった堤隆道さんに感謝します。Special thanks to Takamichi Tsutsumi for feedback and review.
1. はじめに
「すべて偉大なものは単純である。」
日本語で書かれた技術系記事の課題
トピックに限らず、日本語で特定の技術に関して検索をかけると、検索結果が英語での検索に比べて圧倒的に少ないことに加えて、検索結果の99%は以下のいずれかに該当することがわかるでしょう。
幅広い読者層を意識するあまり、解説が表面的すぎる
解説自体は詳しいが、数学や技術に偏りすぎていて、読者層が限定される
海外の有名な記事の直訳
検索結果の絶対量については、テクノロジー分野が英語圏を中心として発展してきたことに起因するため、日本語化に至るまでに多少のタイムラグがあるのは仕方がないことといえます。現に、登場からある程度の時間が経った技術(たとえば初歩的なAIアルゴリズムなど)に関しては、日本語でも全体として記事の層が厚くなる傾向があります。しかし、とりわけ最先端の技術に関しては、上記にあげた通り、なかなか量も質も高くならないというのが現状です。
では英語で書かれた記事をそのまま読んだり、英語が得意でないならば、機械翻訳するなりして読めばいいのではないか、と思われる方もいらっしゃるかもしれません。たしかにそれも良いインプットにはなるとは思いますが、上記にあげた課題感の最初のふたつは、突き詰めると言語によらないものであると個人的には感じています。あらゆる記事やブログは、それぞれの前提と目的をもって書かれているため、一概に比較することはできませんが、特定の技術の認知度と理解度の向上という指標で俯瞰してみると、そのどちらも十分に満たすような記事はほとんどないように思えます。
このブログシリーズが目指すもの
このブログシリーズでは、冒頭にあげた課題感を意識しつつ、ゼロ知識証明と呼ばれる、ここ数年で世界的に注目されつつある新しい技術について解説していきます。ここでは、ゼロ知識証明について何も知らないあらゆる日本の読者(Web3/Web2エンジニアだけでなく、エンジニア以外の幅広い読者層)が、この技術の位置付けや基礎概念について深く理解することができるようになることをひとつの目的としていますが、その一方で、表面的な解説で終わらせず、数学的、技術的な詳細もわかりやすく解説することで、解説の厳密性を担保することも目指しています。ゼロ知識証明は、様々な暗号技術が組み合わさっている複雑な技術であるため、一見すると難しくみえますが、全体を細分化してひとつひとつ解き明かしていくと、その仕組みや重要性、ユースケースがみえてきます。シリーズの途中で数式も多く登場しますが、ぜひ最後まで読み通していただいて、なにかしらのインスピレーションとしていただけたら幸いです。
2. ブロックチェーンとEthereum
“… This they affirm to be the origin and nature of justice; it is a mean or compromise, between the best of all, which is to do injustice and not be punished, and the worst of all, which is to suffer injustice without the power of retaliation. …”
ブロックチェーンとはなにか

ブロックチェーンとWeb3
ゼロ知識証明という技術は、ブロックチェーンと組み合わせて利用されることが多いため、まずはブロックチェーンがどういった課題を解決するために考案された技術であるのかを理解して、具体的にどんなユースケースがあるのかを知る必要があります。ブロックチェーンと聞くと、DAO(Decentralized Autonomous Organization)や暗号資産、Web3といったバズワードを連想される方も多いかと思いますが、これらは同じコンテキストで用いられることが多いだけであって、正確には同義ではありません。端的に表現すると、ブロックチェーンという技術を中心として設計されたWebサービス群がWeb3と呼ばれており、DAOや、主に取引目的で保有される狭義の意味合いでの暗号資産は、それぞれWeb3のユースケースのひとつであるという関係性になります。特に暗号資産は、仮想通貨やトークンとも呼ばれており、ドルや円などの法定通貨を取引する銀行などの金融機関を中心とした中央集権型のCeFi(Centralized Finance)とは対照的に、分散型のDeFi(Decenrtralized Finance)というWeb3サービス群をプラットフォームとして取引されています。
Web1 → Web2
Web3という表現は、これまでのWebサービスの移り変わりを大きく3段階に分けて捉えたときに、第3世代、あるいは第3形態にあたるといった意味合いから、後ほど紹介するイーサリアム(Ethereum)と呼ばれるブロックチェーンの共同提案者であるギャビン・ウッド(Gavin Wood)によって考案されたものであるといわれています。後のインターネットとなった初期の通信技術は、非常に閉鎖的なもので、研究者などの限られたコミュニティー内でデータの共有等を行うために開発されたものでした。そこで、1980年代後半頃からWeb1と呼ばれるフェーズが始まり、次第に誰でもWebブラウザなどのソフトウェアを通じて、インターネット上のデータにアクセスできるようになりました。また、2000年代中頃からは、SNSサービスの登場と共にWeb2と呼ばれるフェーズが始まり、ユーザーは単にデータにアクセスするだけでなく、文章や画像などのデータをアップロードして他のユーザーと共有することが容易になりました。現在のWebサービスもその大半はWeb2サービスであって、ユーザーはストリーミングサービスを利用してリアルタイムでなにかを配信したり、AIサービスを活用して顔認証や自動翻訳を行ったりと、ありとあらゆることがWeb2サービスとして提供されています。
しかし、Web1からWeb2に至るまで、その根本には致命的な問題がありました。その仕組み的にユーザーが自らのデータの所有権を持つことができなかったのです。物理的な仕組みの話をすると、あらゆるWeb2サービス(ここではWeb2がWeb1を含むと考えます)は、サーバーというサービスを提供するコンピューター群を保有しています。サーバーを自前で保有して運用しているオンプレミスと呼ばれる形態もありますが、最近では、AWS(Amazon Web Service)やGCP(Google Cloud Platform)といったような、サーバーなどのインフラストラクチャーを提供するクラウドサービスを利用しているWeb2サービスが大半です。普段は意識することはないかもしれませんが、ユーザーはWeb2サービスを利用する際、Webブラウザやアプリなどのインターフェースを通してこれらのサーバーと双方向のやりとりを行っており、一方でサービス側は送信されたデータをデータベースに保存したり、そのデータを機械学習モデルに与えてモデルを訓練し、それを用いて自動レコメンドなどの機能を提供したりしています。ここで注目したいのは、基本的にユーザーのデータは、Web2サービス側が所有しており、それをどう扱うかはサービス側が恣意的に決定することができるということです。
Web2 → Web3
Web2サービスの例としては、よく銀行が例に挙げられますが、銀行が全ての金融取引に目を通していることを想像してみてください。さらにいうと、銀行は取引に目を通すだけではなく、特定の取引を拒否したり、改竄することも物理的には可能です。また、SNSプラットフォームについて考えてみても、例えばあるFacebookアカウントを凍結したり、あるX上の投稿を削除したりする最終的な権限を持っているのは、そのプラットフォームを提供しているWeb2サービス側です。あらゆるデータがサービスを運営する側によって中央集権的に管理されているという構造は、サービス側への社会的信用と法律的な取り決め、そして株式というインセンティブの仕組みなどによって成り立っていますが、ユーザーは果たして自らのデータの権利に関して、このまま特定のサービスや人間を信頼し続けるべきなのかという疑念は残ります。例えるならば、子供の教育を学校や塾などの教育機関にアウトソースするように、Webサービスのユーザーは、サービス側にデータを預けて何かしらの処理をアウトソースしていると捉えたとき、そのデータに関する主権はその所有者であるユーザーが持つべきであるのは自明なことで、我々はその問題を根本的に解決する必要があります。その解決策の中心となるのがブロックチェーンであって、Web3と呼ばれるフェーズはここから始まるのです。
ブロックチェーンとは、たとえサービス提供者であってもデータを改竄することができないような仕組みを実現するコンピューターネットワークです。中央集権的なシステムの代替案として1980年代にはすでに研究者の間で考案されていましたが、実際に技術として実用化されたのは2009年に運用が開始されたビットコイン(Bitcoin)が初めてでした。ビットコインはそれ自体ではブロックチェーン技術に基づいた発行上限が定められた金融商品であるため、はじめに述べたようなブロックチェーン = 暗号資産といった認識が広まっていますが、後続して開発されたイーサリアム(Ethereum)などのブロックチェーンは、単なる金融商品ではなく、ブロックチェーンネットワーク上で任意のコードを実行できるような設計にしたことで、より汎用的にWeb2の課題を解決する土台をつくることができたのです。つまり、Web3サービスは、Etheruemなどの任意のコードを実行できるようにしたブロックチェーンネットワークをサーバーとして作られるサービス群のことを指し、ブロックチェーン技術にこそWeb3の本質が詰まっているといえます。ここからは、代表的なブロックチェーンであるEtheruemと、それが解決しようとしている課題をみていきます。
Ethereumとはなにか
Ethereumの誕生
Ethereumは、2013年頃にビタリック・ブテリン(Vitalik Buterin)やギャビン・ウッド(Gavin Wood)らによって考案され、実装されたパブリックブロックチェーンで、その時価総額はBitcoinに次いで世界第2位となっています(2024年5月現在)。先述のとおり、Ethereumは当初からWeb2の課題を汎用的に解決すべく設計されており、単にBTC(ビットコイン上で取引されるネイティブトークン)のような仮想通貨を発行して取引できるようなブロックチェーンネットワークにするのではなく、スマートコントラクト(Smart Contract)と呼ばれるブロックチェーンネットワーク上で計算を行うことができる仕組みを提供することで、Web3の概念を具体的な形として世に打ち出しました。より具体的には、スマートコントラクトという任意のロジックを表すコード(通常はSolidityと呼ばれる言語で書かれます)を、ブロックチェーンという分散化されたインフラストラクチャー上にEVM(Ethereum Virtual Machine)と呼ばれる仮想マシンを実装することで実行できるようにしたのです。「ブロックチェーンとEthereum」のセクションで「ブロックチェーンという技術を中心として設計されたWebサービス群がWeb3」と表現したことの意味合いが理解いただけたでしょうか。
Ethereumの概要

「ブロックチェーンという分散化されたインフラストラクチャー」という表現を使いましたが、分散化(Decentralization)とは、ブロックチェーンのみで実現されている概念ではありません。Web2サービスの多くも、特定のサーバーが故障した場合にもサービスを提供し続けられるように、サーバーを世界各地に効率的に分散させることでリスクを最小化しています。このように、分散化とは、サーバー = コンピューターの能力の分散化のことを指しているため、まずはコンピューターとはなにか、について触れなければなりません。普段意識することはないかもしれませんが、我々はコンピューターに対して命令を与えることで、なにかしらの処理を実行させています。それに対してコンピューターは、処理の実行に必要なデータをメモリーに一時的に格納したり、処理結果をハードディスクなどに永続化(保存)することができます。つまり、コンピューターとは任意の命令を理解して実行し、任意のデータを永続化できる機械であると捉えることができます。コンピューターは生命ではないため、どの命令をどの処理に対応させるかは人間が決めるのですが、それを人間にも理解しやすい形で抽象化したものがプログラミング言語というわけです。あらゆるWebサービスやアプリケーションはプログラミング言語で書かれているため、間接的にプログラミング言語を介してコンピューターに対して命令を与え、データを操るというのが、我々がコンピューターを通じて実現している処理の本質になります。
Ethereumは、世界中の不特定多数のコンピューターから構成される1つの巨大で仮想的なワールドコンピューターです。Web2においては、銀行やGoogleなどの特定の企業がサーバーを提供し、データを管理する役割を担っていました。特定の企業の管理下にあるため、たとえ多数のサーバーが分散されている場合でも、データは中央集権的に管理できます。一方で、不特定多数のサーバーを1つのサーバーと捉えたとき、全体としての管理者はおらず、データは中央集権的に管理できないため、サーバー間でデータの整合性についての合意をとり、全体としてただ1つの状態(データ)を正とする必要があります。Ethereumでは、ノード(Node)と呼ばれる不特定多数のコンピューターがP2P(Peer-to-Peer)と呼ばれるプロトコルを介して相互に通信を行い、データに関する合意を形成した上で、ブロックチェーンとしてパブリックにデータを永続化していく形をとっています。特に、この分散された不特定多数のコンピューター間でデータの合意を形成するアルゴリズムはコンセンサスアルゴリズム(Consensus Algorithm)と呼ばれており、Ethereumの核となる仕組みです。つまり、厳密に表現すると、Ethereumとは、コンセンサスアルゴリズムによって全体としての管理者を必要としない(トラストレスな)、世界中の不特定多数のノードから構成されたコンピューターネットワークであるといえます。
Ethereumでは、トランザクション(Transaction)と呼ばれる単位で処理が行われており、これがEthereumネットワークに対する命令にあたります。複数のトランザクションはコンセンサスアルゴリズムを通じてブロック(Block)という単位にまとめられ、ブロックが繋げられていくことによってブロックチェーンとしてデータが永続化されていきます。ここで注目したいのは、ブロックチェーンとはあくまでも抽象的な概念であって、その実体は、各ノードがローカル環境(自らのコンピューター上)に持っているデータを、コンセンサスアルゴリズムを通じて他のノードと同期しているという仕組みであるということです。さて、エンドユーザー視点でEthereumを抽象的に捉えた図が図2になります。ユーザーはウォレット(Wallet)と呼ばれるWeb2でいうアカウントに該当するソフトウェアを起点に、トランザクションを作成し、電子的に署名し、送信することでEthereumネットワークとやりとりをします。電子署名技術についてはVol.2で詳説しますが、ここでは、特定のユーザーが特定のトランザクションを送信したという証明を行っていると考えてみてください。トランザクションを受け取ったノードは、それをネットワークに対してブロードキャストしますが、前述したように、Ethereumは不特定多数のノードによってその実行環境が保たれています。よって、トランザクションがブロックの一部としてブロックチェーンに組み込まれる前に、コンセンサスアルゴリズムによって、そのトランザクションが有効であるか、どの順番でトランザクションをブロックに組み込むかなど、ノード間で様々な取り決めを行うことが必要になります。
コンセンサスアルゴリズム: Proof of Stake

Ethereumでは、PoS(Proof of Stake)と呼ばれるコンセンサスアルゴリズムが採用されています。元々は、PoW(Proof of Work)という、ある計算を最も早く完了できたノードがブロックを追加するという仕組みのアルゴリズムでしたが、2022年9月にThe Mergeと通称される変更で、PoSへの完全移行を終えました。PoWは、ビットコインで利用されているコンセンサスアルゴリズムですが、大量の計算資源を必要とするため(2023年のビットコインネットワークの電力消費量は約120TWhで、これはオランダの年間電力消費量に匹敵します)環境にとって悪いという点と、計算コストによるスケーラビリティーの制限があるという点から、持続可能なネットワークとして理想的ではないというネガティブな側面がありました。EthereumはPoSに移行したことで、PoWを採用していた時期と比較して99.9%以上のエネルギー効率の向上を達成し、それと同時により処理能力の高いブロックチェーンネットワークとしての一歩を踏み出したというわけです。
PoSに限らず、コンセンサスアルゴリズムは、世界中に散らばった不特定多数のコンピューター間で実行されるため、その時間軸を理解することが重要になります。現実世界では、1分 = 60秒といった時間の区切り方がされていますが、Ethereumでは、図3にあるように、スロット(Slot)という単位で時間が区切られており、1スロット = 12秒と決められています。また、1エポック(Epoch)= 32スロット = 6.4分と決められており、スロットごとにブロックが1つ生成されるため、1エポックで最大32個のブロックが生成されることになっています。最大32個と表現したのは、各ブロックの追加に際して、PoSでネットワークの合意形成を図るのですが、様々な理由から合意に至らない場合もあり得るためです。図3のブロック#66やブロック#126は、PoSの結果として、ブロックチェーンに追加されなかったブロック(Missed Block)として表現しています。

スロットをEthereumの時間の最小単位として捉えると、スロット内でノードはどのように動作しているのでしょうか?EthereumのPoSにおいては、ノードはネイティブトークンであるイーサ(ETH)を一定額デポジットすることよって、ネットワークの合意形成に参加する権利を与えられます。PoSに参加する権利を得たノードは、図4にあるように、RANDAOという仕組みによって、エポック内のいずれか1つのスロットにランダムに割り振られます。各スロットにおいて、各ノードは以下のいずれかの役割を果たします。
ブロックプロポーザー(Block Proposer): スロット内でブロックを生成し、スロットに割り当てられたコミッティー(Committee)と呼ばれるネットワークにブロックを提案する。ブロックプロポーザーは各スロットに1つのみ割り当てられる。
バリデーター(Validator): ブロックプロポーザーが提案したブロックについての検証と同意を行う。ノード全体に対する割合として、ノードのほとんどはバリデーターとして割り当てられる。
アグリゲーター(Aggregator): バリデーターによる検証における電子署名をまとめ、ブロックプロポーザーに受け渡す。ネットワークとしての処理速度を向上させることを目的として設定されている。
各ノードが1エポックで参加できるスロットは1つのみであるため、1エポックが終わると、ネットワーク内のすべてのノードが合意形成に関わったことになります。このように、Ethereumでは、1エポックを最小単位として、ネットワーク内のすべてのノードの合意形成を実現しています。

図5は、各スロット内で、ブロックチェーンに新しいブロックが追加されるまでの仕組みを簡略化して表しており、大まかには以下の3ステップに分解することができます。
1 - 新しいブロックの生成(Block Generation)
すべてのバリデーターの中からランダムに選ばれたブロックプロポーザーは、複数のトランザクションをまとめてブロックを生成し、他のバリデーターに対して生成したブロックを提案します。この際、最終的にブロードキャストする対象はすべてのバリデーターとなるのですが、2024年5月現在で約100万ものバリデーターが運用されており、スロットごとにすべてのバリデーターに対して合意を求めているとネットワーク全体としての処理が遅くなってしまうため、スロットごとに割り当てられたビーコンコミッティー(Beacon Committee)と呼ばれる少数のバリデーターから構成されるグループに対してのみ、ブロックの検証と同意を求めます。1コミッティーは複数のバリデーター(最低でも128個のバリデーター)から構成されており、1スロットは複数のコミッティーから構成されるケースがほとんどです。
2 - ブロックの検証と同意(Block Attestation)
プロポーザーによって提案されたブロックを受け取ったバリデーターは、ブロックに含まれるトランザクションを再実行して検証し、アテステーション(Attestation)というデータを生成して電子署名を行い、それぞれのコミッティーに対してそれをブロードキャストします。一方で、それを受け取ったアグリゲーターは、コミッティー内の複数のアテステーションに対する署名をBLS電子署名(BLS Digital Signature)と呼ばれるアルゴリズムを用いてまとめる役割を担っています。これは、プロポーザーによるアテステーションの検証時間を短縮したり、署名をまとめることで最終的なブロックに含まれるデータ量を減らすといった、スケーラビリティー的なメリットを踏まえた設計となっています。
3 - ブロックの追加(Block Addition)
各コミッティーからのアテステーションを受け取ったプロポーザーは、それらをブロックボディ(Block Body)としてブロックに含め、ブロックをローカル環境のブロックチェーンに追加します。その後、追加された新しいブロックは、Ethereumネットワーク全体へとブロードキャストされますが、それが正しいブロックとして最終的にネットワークに受け入れられるかどうかは、後続のプロポーザーやバリデーターがスロットごとに同じ手順を繰り返すことで決定されます。
ここからは、スロットごとに上記の手順が繰り返されることによって、どのようにしてブロックチェーンが生成されていくのかを具体例を交えてみていきます。

Ethereumでは、不特定多数のノード間で特定のアルゴリズムを実行するために、各ノード上のソフトウェアが定義すべきインターフェースをプロトコルとして定義しています。したがって、すべてのバリデーターがプロトコルを正しく実装して、悪意なく振る舞い、ネットワークの遅れなども全くない理想的な環境で動作すると仮定すると、ブロックチェーンはただひとつの直線となるはずです。しかし現実では、バリデーターによるプロトコルの実装に関する保証はなく、悪意のあるバリデーターも一定数存在し、ネットワークによる遅れも発生するため、ブロックチェーンは枝分かれする場合があります。図6は、フォーク(Fork)と呼ばれる、ブロックチェーンが枝分かれした状態を表しています。エポック#5のスロット#1の開始時点においては、ネットワークはブロック#0をブロックチェーンの先頭とみなすことで合意が取れています。しかし、スロット#3の開始時点においては、ブロック#1を先頭とみなすバリデーターと、ブロック#2を先頭とみなすバリデーターとに二分されています。また、スロット#4の開始時点においては、ブロック#2、#3、#3’の3つがブロックチェーンの先頭の候補にあがっていることがわかるでしょう。
なぜこのようなフォークが生まれるのでしょうか?大前提として、EthereumのPoSでは、各スロットにおいて1つのバリデーターしか選出されないことがアルゴリズム的に強制されているため、2つ以上のバリデーターが競合したブロックを生成するということは想定できません。したがって、スロット#1においては、プロポーザーが提案したブロックが何かしらの理由でバリデーターに認められなかったということになります。この原因としては、スロット#1のプロポーザーが、ネットワークの遅れによって前のブロックを受け取れていなかったり、存在しない不正なトランザクションをブロックに含めたことによってブロックの検証が通らなかった、という状態が想定できます。一方で、スロット#3のプロポーザーは2つのブロックを生成しており、これはプロトコル違反となるため、バリデーターによる合意が分散している状態であると考えることができるでしょう。しかし、このような複数の先頭ブロックが存在している場合でも、後続のバリデーターは1つのブロックを先頭として選び、支持しなければなりません。
EthereumのPoSは、Gasperと呼ばれるプロトコルで動作しています。Gasperは、LMD-GHOST(Latest Message Driven Greedy Heaviest Observed Sub-Tree)と、FFG Casper(Friendly Finality Gadget Casper)という2つのプロトコルを組み合わせたもので、このうちLMD-GHOSTは、複数のフォークが存在する場合に、どのフォークを選ぶべきかの判定基準を定めたプロトコルです。特にこの判断基準はフォーク選択アルゴリズム(Fork-Choice Algorithm)と呼ばれており、Ethereumでは、最も多くのステーク(デポジット)されたETHに裏付けされたブロックを選ぶように実装されています。バリデーターは、エポックごとに提案されたブロックに対してアテステーションを生成して同意を示しますが、この同意は各バリデーターのステークしたETH量に応じて重みがつけられており、これによってフォークごとの重みが計算できるというわけです。つまり、図6のようにフォークが存在する状態では、バリデーターは各先頭ブロックまでのETHの重みを計算し、比較して、最も多くの同意を集めているブロックを先頭として採用するという仕組みになっています。
LMD-GHOSTによって、各スロットにおけるバリデーターのブロック選択基準は統一されていますが、追加されたブロックが後にネットワークによってブロックチェーンに含まれなくなる可能性も排除できません。そこで、Gasperのもう一つのプロトコルであるFFG Casperは、ブロックに対するネットワーク全体の合意が確定するタイミング(Finality)を明確に定めています。各エポックの最初のブロックはチェックポイント(Checkpoint)と呼ばれており、バリデーターは特定のブロックに対するアテステーションを生成する際に、1つ前のエポックと現在のエポックのチェックポイントについての投票も行っています。例えば、図6のエポック#5のスロット#4において、バリデーターは、新しい先頭ブロックを選択すると同時に、1つ前のエポックの先頭ブロックと現在のエポックの先頭ブロックがそれぞれどのブロックであるかについても投票し、アテステーションとしてプロポーザーに渡しているということになります。つまり、エポック#5の終了時点で、ネットワークにステークされたETHの全供給量の2/3以上分の同意が得られていれば、1つ前のエポック分のブロック(図6でいうとエポック#4)は確定されたと考えられます。ブロックが確定されるとそれに含まれるトランザクションも確定するため、トランザクションが確定されるまでに、厳密には最低でも2エポック(12.8分)かかるということになります。
Ethereumノード
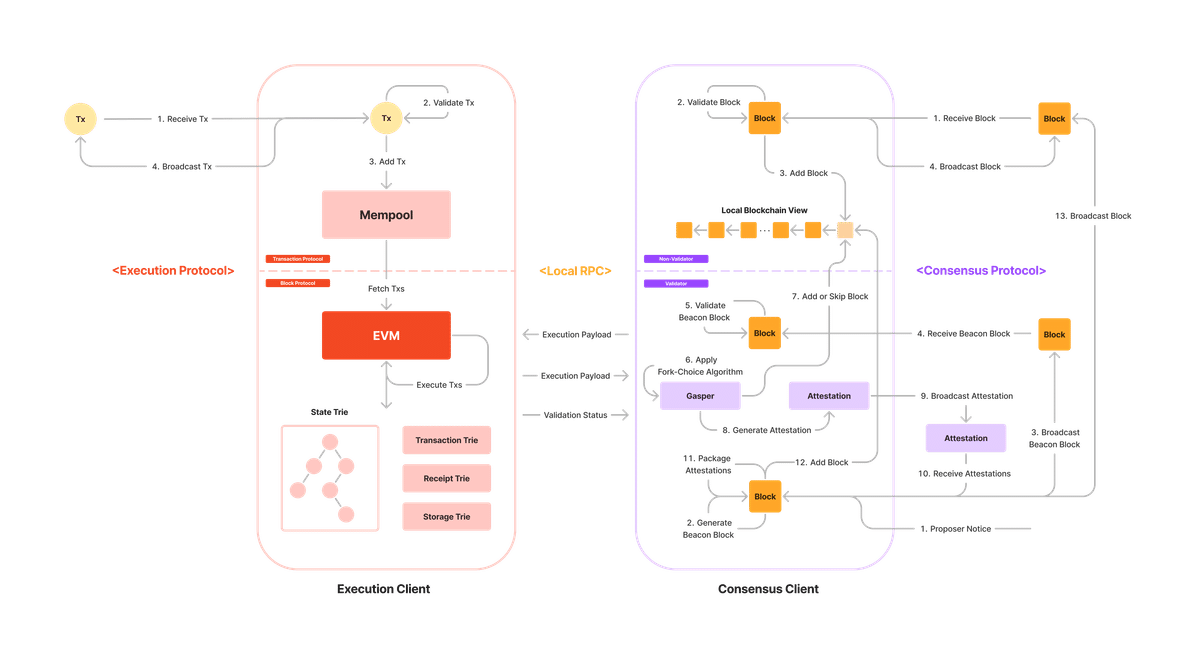
さて、PoSを実行するバリデーターの実体は、一定額以上のETHをデポジットしたEthereumノードでしたが、ノードはどのような仕組みでトランザクションを実行したり、他のノードとの間でトランザクションやブロックを同期しているのでしょうか?図7は、Ethereumノードの処理の流れを表しています。あるコンピューターがEthereumノードとしてネットワークに参加するためには、実行クライアント(Execution Client)とコンセンサスクライアント(Concensus Client)と呼ばれる2つのソフトウェアをインストールして実行する必要があります。それに加えて、バリデーターとしてPoSに参加するためには、バリデータークライアント(Validator Client)と呼ばれるソフトウェアを追加でインストールして、コンセンサスクライアントを拡張する必要があります。図7では、左側の赤い枠が実行クライアント、右側の紫の枠がバリデーターの拡張を行ったコンセンサスクライアントを示しています。ここからは、実際のトランザクションがブロックとしてブロックチェーンに組み込まれるまでの過程をみていきましょう。
ユーザーによって作成され、電子的に署名されたトランザクションは、実行クライアントのJSON-RPC(Javascript Object Notation-Remote Procedure Call)と呼ばれるインターフェースを通じて、特定のEthereumノードに伝えられます。トランザクションを受け取ったノードは、トランザクションが通信途中で書き換えられていないかなどの検証を行った後、メモリープール(Mempool)と呼ばれる、ブロックに組み込まれる前の暫定的なトランザクションが溜められるメモリースペースに格納します。ノードはその後、実行ゴシッププロトコル(Execution Gossip Protocol)と呼ばれる、ノード間の実行クライアント上でP2Pでやりとりを行うプロトコルを介して、ネットワークにトランザクションをブロードキャストし合うことで、トランザクションの同期を図ります。他のノードからゴシッププロトコル経由で受け取ったトランザクションに関しても検証を行い、それぞれのメモリープールに格納していくという流れです。
さて、バリデーターとなったノードがブロックプロポーザーとして選出されると、そのノードは、コンセンサスクライアントを通じて、自身のメモリープールの中からブロックに含めたいトランザクションを選び出し、実行クライアントを通じてそれらをEVMで実行します。EVMは、スマートコントラクトとして書かれたコードの仮想的な実行環境であるため、コンピューターの中に再現された仮想的なコンピューターであると考えてみてください。「Ethereumの概要」のセクションで説明したように、コンピューターとはコードとして書き表された命令を実行し、処理の実行前後のデータを永続化することができる機械でした。より狭義に表現すると、コンピューターとは、データをどのように格納するかを抽象的なデータ構造として表し、それを用いてコードによって明確に定義されたアルゴリズムを実行することができる機械を指します。つまり、EVM上でトランザクションを実行するにあたっては、トランザクションデータそのものや、トランザクションによって変化する各アカウントのデータを格納するためのデータ構造が必要になります。
Ethereumでは、マークルパトリシアトライ(Merkle Patricia Trie / MPT)と呼ばれるデータ構造を用いて、トランザクションやアカウントの残高等のデータを永続化しています。MPTは、マークル木(Merkle Tree)と呼ばれるデータの検証速度が早くなるように設計されたデータ構造を元にして、Ethereumの用途に合わせて、なるべく少ないディスクスペースでデータを格納できるように最適化されたデータ構造です。Ethereumでは、以下の4種類のトライ(Trie)が定義されており、トランザクションの実行時に各トライが更新され、ブロック生成時に各トライのルート(Root)と呼ばれる、そのトライに含まれるすべてのデータを表したメタデータがブロックに格納されることによって、トランザクションによるデータ遷移の正しさを担保しています。
ステートトライ(State Trie): Ethereum全体のアカウントとアカウントに紐づくデータを格納するトライ
ストレージトライ(Storage Trie): アカウントごとに生成され、スマートコントラクトを含むアカウントに関するデータの詳細を格納するトライ
トランザクショントライ(Transaction Trie): ブロックごとに生成され、トランザクション自体のデータを格納するトライ
レシートトライ(Transaction Receipt Trie): ブロックごとに生成され、トランザクションの実行履歴を格納するトライ
よって、ブロックプロポーザーは、選び出した任意のトランザクションによるデータの遷移を、トライのルートとしてビーコンブロック(Beacon Block)と呼ばれるコンセンサス段階のブロックにまとめ、それをコンセンサスクライアント間のゴシッププロトコルを通じてネットワークに提案します。それを受け取ったバリデーターはまず、提案されたビーコンブロックに含まれるトランザクションをEVM上で再実行し、更新された自身のもつステートトライのルートがビーコンブロックに含まれているルートと合致するかを確認することで、それらの有効性を検証します。バリデーターはその後、前セクションで詳説したPoSプロトコルを実行してアテステーションを生成し、ブロックに対する同意をネットワークにブロードキャストします。そして最後に、プロポーザーはバリデーターからの同意を最終的なブロックとしてまとめ、ローカル環境のブロックチェーンに追加し、ネットワーク全体にブロードキャストする、という流れになります。
Ethereumの経済的側面
ここまでは、Ethereumがその不特定多数のノードから構成されるネットワークにおいて、どのようにしてブロックチェーンという一意のデータを保持していくかについての技術的な説明を行ってきました。しかし、ノードの実体は不特定多数のコンピューターとそれを運用する人間であるため、なにかしらのインセンティブがない限り、コストをかけてまでノードを運用しようとはしないことは想像に難くありません。特にバリデーターとなるためには、最低で32ETH(2024年5月現在で約1,500万円)をデポジットしなければならず、初期費用も高額になっています。また、逆にEthereumの立場から考えると、ETHをステークするバリデーターの絶対数が増え、バリデーターの運用主体が多様になればなるほど、特定のだれかを信用する必要がなくなり、ネットワークの安全性を高めることができるでしょう。では、Ethereumはどのようにしてバリデーターに対してインセンティブを与えているのでしょうか?
結論から述べると、正常に動作するバリデーターを悪意なく運用すると、Ethereumから報酬(Reward)が貰えるという仕組みになっています。報酬の種別としては複数あり、ブロックプロポーザーがブロックを生成して提案することに対する報酬や、バリデーターがブロックの検証と同意を行うことに対する報酬、トランザクションに含まれるガス代(Gas Fee)と呼ばれる手数料に上乗せされて払われるチップなどがあります。PoSに関わることによる報酬については、ブロックの生成ごとにETHが新しく発行(Mint)され、デポジットされたETHの額に応じて、バリデーターに対して支払われるという仕組みになっています。また、ガス代に関して補足すると、Ethereumをブロックチェーンというトラストレスなインフラを提供するサービスと捉えると、サービスを利用するための手数料を払うのは自然なことで、ここに関してはWeb2の決済サービスと構造的には違いはありません。また、悪天候時やピークタイムなど、タクシーが捕まり辛い状況で「優先パス」のようなオプションがあるように、トランザクションを早くブロックに取り込んでもらうために、エンドユーザーが追加で手数料を払うというイメージも掴めるかと思います。反対にバリデーター視点では、報酬を最大化するために、より多くのガス代を払ってくれるトランザクションを優先してブロックに含めたいという気持ちが働くのも容易に想像できます(「MEVとPBS」セクションで詳述)。
しかし、上記のような報酬があるだけでは、悪意のあるバリデーターが無制限に出現し、ネットワークとしての安定性が著しく下がってしまいます。そこでEthereumでは、プロトコルで禁止されている行為を行ったバリデーターや、義務を怠ったバリデーターに対して罰則を規定しています。前者でいうと、1スロット内で2つ以上のブロックを生成したブロックプロポーザーなどが該当し、後者でいうと、例えばネットワークに問題があり、オフラインとなってしまったことで時間内にブロックの検証等が実行できなかったバリデーターなどが当てはまります。ここでいう罰則とは、デポジットされたETHが減らされること(Slashing)を意味しますが、ノードの運用は不確定要素も多いため、予期しないところでETHが減らされてしまうことも十分にあり得ます。つまり、自らのETHを危険に晒して(At Stake)、報酬をインセンティブとしてEthereumのネットワークに参加するという意味合いから、このコンセンサスアルゴリズムはProof of Stakeと呼ばれているわけです。一方で、ネットワーク全体として考えてみると、悪意を持ったバリデーターは、PoSにおけるETHの全供給量(2024年5月現在で、約3,200万ETHがステークされています)の $${\frac{1}{3}}$$を確保しない限りコンセンサスを止めることはできず、$${\frac{2}{3}}$$ を確保しない限り悪意のあるブロックに関するネットワークの合意を得ることができなくなっています。ちなみに、PoSにおいて $${\frac{2}{3}}$$の合意に至らない期間が4エポックを超えると、大多数に同意しないバリデーターのデポジットしたETHが徐々に減らされる期間(Inactivity Leak)が始まり、ネットワークとしてなるべく早くコンセンサスが取れるような仕組みになっています。
このように、Ethereumでは、ETHがバリデーターにとっての報酬となり、それと同時に罰則の対象となることで、トラストレスな分散ネットワークとしての安全性が担保されています。しかし、いくらETHが増えたところで、その価値が損なわれてしまうと、ETHを保有したり、バリデーターとしてネットワークに参加するインセンティブはなくなってしまいます。ETHをはじめとした仮想通貨の価値は、法定通貨や株式と同様に、市場の需要と供給によって決定されます。ETHの需要は、EthereumのPoSのステーキングに使用されていることや、Ethereumと互換性のあるブロックチェーンを含めたEthereumエコシステム全体のユースケースに対する需要によって担保されており、DeFiプラットフォームで売買したり、法定通貨に替えたりすることも可能です(2024年5月現在で1ETH = 約47万円)。技術的側面だけでなく、こうした経済的側面(トークン中心の経済という意味合いで、トークノミクスと呼ばれます)があることによって、Ethereumはその市場的な価値を確立しているというわけです。
MEVとPBS

さて、前セクションではバリデーターの報酬についての説明を行いましたが、ブロックプロポーザーとしては、自らの得られる報酬を最大化したいという当然の思惑があります。また、報酬性の高い(手数料を多く払ってくれる)トランザクションを優先してブロックに含めるなどのナイーヴな方法に加えて、DeFiの仕組みを利用することで、通常のバリデーター報酬のみで得られる報酬よりも多くの報酬を得ることができます。プロポーザーが1スロット内で理論的に手に入れることができる最も高い報酬は、MEV(Maximal Extractable Value)と呼ばれており、MEVは、DeFiのAMM(Automated Market Maker)というトークン価格をアルゴリズム的に決定する仕組みをうまく利用することで獲得することができます。より具体的に述べると、AMMは流動性プール(Liquidity Pool)と呼ばれる、複数のトークン(大抵はETH/USDCなどの1つのトークンペア)から構成されるトークンプールにおけるトークンの割合(需要と供給)からトークン価格を決定します。そこでプロポーザーは、例えばある特定のトークンを多く買い付けるトランザクションを自身のメモリープールにみつけた際に、そのトークンを購入するトランザクションと、売却するトランザクションを作成し、それらで元のトランザクションを挟むことで、その価格差によって追加の報酬を得られるというわけです(これはSandwich Attackと呼ばれます)。現状、ほとんどのバリデーターはMEVを得るためのアルゴリズムの実行を外部にアウトソースしており、この仕組みはより抽象的に捉えると、ブロックのネットワークへの提案者(Proposer)とブロックの生成者(Builder)とを分けることから、ブロック提案者とブロック生成者の分離(Proposer-Builder Separation / PBS)と呼ばれています。
MEVを得るためのソフトウェアとして最も有名なのが、図8にあるような仕組みを実装しているmev-boostです。mev-boostは、MEVを得るための自動ボットのようなもので、バリデーターはコンセンサスクライアントを拡張することによって、誰でもその機能を使用することができます。mev-boostでは、サーチャー(Searcher)と呼ばれるソフトウェアが、Ethereumのパブリックなメモリープールや、mev-boost独自のプライベートなメモリープールから収益性の高いトランザクションを取り出し、ビルダー(Builder)と呼ばれるブロックを生成するソフトウェアに対してそれらを渡します。ビルダーは複数存在し、それぞれが最も収益性の高いと考えるブロックを生成してリレーヤー(Relayer)と呼ばれるソフトウェアに渡します。最終的には、プロポーザーが複数のリレーヤーから最も高い収益性を得られるブロックを1つ選択してネットワークに対して提案を行うのですが、その報酬がmev-boostの各ステークホルダーにも分配されるという仕組みです。
このように、プロポーザーがどのトランザクションをブロックに含めるかを決定する必要がなくなることで、プロポーザー側で複雑なアルゴリズムを実装する必要がなくなり、それに伴うバリデーター報酬の偏り(ビジネスとして運用されているバリデーターへの報酬の偏りなど)も是正されると考えられています。また、プロポーザーの権限が減り、外部の複数のビルダーによるアルゴリズム的な競争によって提案するブロックが決定されることによって、プロポーザーによるトランザクションの検閲による不正も起きづらくなるというのが一般的な見解です。このような観点から、PBSは、より公平なバリデーター収益の分配やエンドユーザーのサービス体験に繋がると考えられているため、Ethereumコミュニティーによって推奨されています。
Ethereumの課題と解決策

分散システムのトリレンマ
Ethereumは、そのネイティブトークンであるETHをインセンティブとしたPoSを実装することで、トラストレスで分散化されたインフラネットワークを担保し、スマートコントラクトとして任意のコードを実行できるようなEVMを提供することでWeb3という新しい概念を作り出しました。しかし、Ethereumには光もあれば影もあります。もともとブロックチェーンに限らずあらゆる分散システムのトリレンマとして、CAP Theoremと呼ばれる定理があり、これはあらゆる分散システムは一貫性(Consistency: 全てのノードが同じデータのコピーを持っていること)・可用性(Availability: 一部のノードがダウンしてもシステムが利用できること)・分断耐性(Partition Tolerence: ノード間の通信がダウンしてもシステムが止まらないこと)のうち2つしか満たすことができないということを指摘していました。この観点でみると、Ethereumを含めたほとんどのブロックチェーンは、CAPのうち一貫性を犠牲にして、PoWやPoSなどのコンセンサスアルゴリズムを組み入れて、結果整合性(Eventual Consistency: 一時的にデータの不整合は起こるが、結果的にノード間でデータの整合性が取れるという意味合い)の元に提供している分散システムと捉えることができます。
ブロックチェーンのトリレンマ
データの一貫性については、コンセンサスアルゴリズムを利用することである程度の担保ができることが実証されていますが、それとは別に、ブロックチェーンにもトリレンマがあると言われています。それは、分散化(Decentralization: あらゆる権力がノードに公平に分散されていること)とセキュリティー(Security: あらゆる攻撃に対して耐性を持っていること)とスケーラビリティー(Scalability: 大量のトランザクションを効率的に処理できること)の3つのうち、2つしか満たすことができないというものです。しかし、このトリレンマについては、さまざまな技術革新もあり、最近では全てを満たすことができるのではないかという見方もあることも述べておく必要があります。ここで「満たす」という言葉が具体的にどういう状態を指すのかについては、議論の余地がありますが、スケーラビリティーに関していえば、現状のWeb2システムで処理できる能力と同等かそれ以上であれば、十分であるという考え方ができるでしょう。例えば、Visaの決済システムは 65,000程度のTPS(Transaction Per Second: 1秒間に処理できるトランザクション数)であるといわれていますが、Ethereumもそれ以上のTPSを兼ね備えることができれば、スケーラビリティーについては十分であると考えることができます。
Ethereumのアプローチ
Ethereumは、上記のトリレンマでいう分散化とセキュリティーを優先して設計されてきたため、スケーラビリティーに関しては、後回しにされていた過去がありました。そこで現在は、レイヤー2(Layer 2 / L2)と呼ばれるスケーラビリティーに関する解決策を提供する、Ethereumをベースにしたブロックチェーンが数多く存在します。このコンテキストで解釈すると、EthereumやBitcoinはレイヤー1(Layer 1 / L1)と呼ばれ、L2はL1のセキュリティーやデータ可用性をベースに、スケーラビリティーに関する解決策を提供していると捉えられます。具体的な解決策としては、ロールアップ(Rollup)と呼ばれるL2上で複数のトランザクションをまとめて L1ではひとつのトランザクションとして扱うことができるようにする手法が最も注目されています。ロールアップは大きく分けて、オプティミスティックロールアップ(Optimistic Rollup)とゼロ知識ロールアップ(ZK Rollup)と呼ばれる2種類があります。両者の詳細な比較はVol.2で行いますが、オプティミスティックロールアップがトランザクションの検証期間を設け、不正なトランザクションがあればその証明(Fault Proof)を提出するというスタイルである一方、ZKロールアップは全てのトランザクションに対してその有効性の証明(Validity Proof)を提出するというスタイルをとっているという大きな違いがあります。
派生的な課題も数多く存在します。例えば、分散化を実現するには、Ethereumのように誰でもアクセス可能なパブリックなブロックチェーンである必要がありますが、その反面、トランザクションやそれに含まれるデータも公開されてしまうという、プライバシー観点の課題が存在します。また、依然としてバリデーターの参入障壁は高いため、バリデーターを運用できる層が限られてしまっているという点は、トラストレスという意味合いでの分散化を妨げているひとつの大きな要因となっています。そのほか、異なるブロックチェーン間でスムーズにデータをやりとりするための相互運用性(Interoperability)に関する改善もまだまだ必要であったり、ブロックが確定するまでの時間的コスト、ガス代の高騰、UI/UXの複雑性など、解決すべき課題は少なくありません。一方で、バリデーターの参入障壁を下げるために、軽量ノード(Light Node)と呼ばれるノード種別や、それらにブロック情報を同期するための同期コミッティー(Sync Committee)と呼ばれるバリデーターの役割が実装されていたり、Single Slot Finalityと呼ばれる改善案ではスロット毎に全てのバリデーターの合意を形成してブロックを確定させるための実装案がまとまっていたりします。また、ガス代については、2024年3月に導入されたDencunと呼ばれるアップデートで、Blobと呼ばれるL2向けの新しいトランザクション種別の導入を境に飛躍的に安くなることが予測されており、UI/UX については、アカウント抽象化(Account Abstraction)と呼ばれる仕組みを使うと、GoogleなどのWeb2サービスのログイン機構を用いてウォレットを作成できるなど、各課題に対する解決策の模索と実装は盛んに行われています。
Ethereumのこれから
Webの歴史を振り返ってみたときに、なぜEthereumのようなあらゆる角度において分散化された理想的ともいえるシステムは、最近になるまで台頭してこなかったのでしょうか?理由はいたってシンプルで、中央集権的な仕組みの方が圧倒的に楽だからです。特定の誰かによって中央集権的に管理されたシステムであれば、サーバーの運用者にインセンティブを与えることもなく、Gasperのような複雑なプロトコルを生み出す必要もありません。しかし、運用側のメリットと引き換えに、エンドユーザーは自らのデータの管理やそれに関する権利を、運用側への信用のみに依存して、完全に放棄してしまっているのです。果たして法律改正や規制の強化だけが、既存のインターネットの抱える課題に対する恒久的な解決策なのでしょうか?
Ethereumを筆頭としたWeb3の流れは、そうした現状のあらゆる妥協を、数学・テクノロジー的に解決しようとする壮大な試みです。また、ブロックチェーンという仕組みは基本的にパブリックであり、常になにかしらの脅威に晒されている実験場であると考えると、例えばこのブログシリーズで今後解説していくゼロ知識証明のような新しい技術が数多く生み出され、実用化されやすい環境であるとも捉えられます。そういったこれまでは不可能だと思われていたような技術が実用化されるようになると、今までみえていなかった課題や解決策が浮かんでくる、といった作用もあるのではないでしょうか。また、前セクションで述べたような多くの根本的な課題が解決され、Ethereumが基盤としてより安定すれば、新たなユースケースを生み出すようなWeb3プロジェクトが市場に登場するスピードが加速度的に向上する未来もそう遠くはないでしょう。
Vol.1では、ゼロ知識証明に関する説明に入る前の前提として、ブロックチェーンの仕組みについてみてきました。さまざまなブロックチェーンがある中でも、Web3の概念を世界に推し広め、現在もトップランナーであるEthereumを取り上げ、Ethereumにおけるコンセンサスアルゴリズムやノードの仕組み、経済的側面から顕在化している課題と解決策に至るまで、幅広く深ぼってきました。Vol.2では、いよいよゼロ知識証明についての説明に入っていきます。そもそも現代の暗号技術とはどのような仕組みで成り立っていて、ゼロ知識証明は他の暗号アルゴリズムと比較するとどういった位置付けなのか。なぜブロックチェーンと相性が良いと言われていて、Ethereumではどういった部分で活用され始めているかなど、ゼロ知識証明の本質が深く理解できるような内容を想定しています。
参考
このブログは、以下のリソースを参考にして書かれています。