No.001 pythonとyfinanceで株価取得し分析

1.今回の目的
pythonのyfinanceライブラリを使いベータ値の計算を行ってみたいと思います。
具体的には、
1. ファーストリテイリング(9983.T)と株式会社しまむら(8227.T)の
過去5年間の週次の終値を取得し、
2. 日経平均の乖離からβの算出し分析を行いました。
Jupitor Notebookを使用します。
2.リファレンス
- yfinanceのサイトとしてコチラが公式サイト(PyPIのサイト)
- Pythonのベータ値の計算としてコチラのQiitaの記事
3.yfinanceとは
yfinanceは Yahoo! Financeから情報を取得するためのAPIです。
オープンソースとして公開されています.
python環境がある場合はpip installで簡単にインストールが出来ます。
4.ベータ値とは
ベータ値とは、市場全体(つまり株価指数)に対する、各個別銘柄の株価の感応度をいいます。つまり、日経平均株価やTOPIXといった株価指数が1%動いたとき、個別銘柄が何%動くかを示したものです。
例えばTOPIXを基準とした場合、ベータ値が1の銘柄は、TOPIXが1%上昇すると1%上昇、TOPIXが1%下落すれば1%下落というように、TOPIXと同じ値動きをすることを表します。
ベータ値が2の銘柄は、TOPIXが1%変動するとその2倍の2%変動することを表し、ベータ値が0.5の銘柄は、TOPIXが1%変動するとその半分の0.5%変動することを表します。
5.コーディング
Step1: yfinanceをinstallします。
pip install yfinanceStep2: Jupitor Notebookでライブラリを呼び込みます。
import pandas as pd #データの整形のため
import numpy as np #対数等の計算のため
import matplotlib.pyplot as plt #グラフ描画のため
import yfinance as yf #株価取得のため
% matplotlib inlineStep3: yfinanceで株価の読み込みのための関数を定義
years = 5
tickers = {
'ファストリ': '9983.T',
'しまむら': '8227.T',
'日経平均': '^N225'
}
def get_kabuka(years, companies):
df =pd.DataFrame()
for company in tickers.keys():
tkr = yf.Ticker(tickers[company])
data=tkr.history(period=f'{years}y',interval = "1wk")
data.index = data.index.strftime('%d %B %Y')
data = data[['Close']]
data = data.dropna(how="all")
data.columns = [company]
df= pd.concat([df,data],axis=1)
return dfStep4: 作成したget_kabuka()関数を使い、株価情報を取得し, dfに格納
df=get_kabuka(years, companies)
df.head()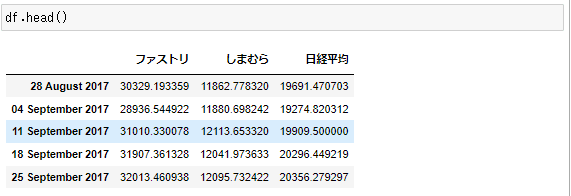
Step5: numpyで週次ごとの変動率の対数をとり log returnsに格納
log_returns = np.log(df/df.shift(1)) #shift(1)で1日データシフトさせている
log_returns = log_returns.dropna() #最初のリストはNaN。よって取り除く
log_returns.head()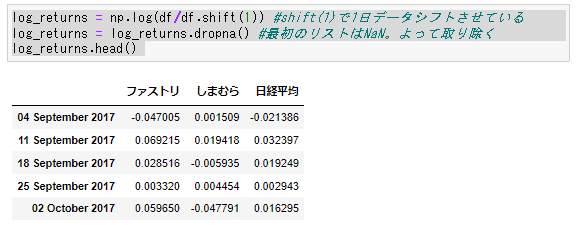
Step6: ファストリと日経平均で共分散のplot, ベータ値の計算
同様にしまむらと日経平均で共分散のplot, ベータ値の計算
#共分散plot
X = log_returns.iloc[:,2] #日経平均
Y = log_returns.iloc[:,0] #ファストリ
from sklearn import linear_model
clf = linear_model.LinearRegression() #線形モデル
X2 = [[x] for x in X]
clf.fit(X2, Y) # 予測モデルを作成
print("ベータ値(回帰係数,傾き)= ", clf.coef_)
print("切片= ", clf.intercept_)
print("決定係数= ", clf.score(X2, Y))
# 散布図
plt.scatter(X2, Y)
# 回帰直線
plt.title('Linear regression')
plt.plot(X2, clf.predict(X2))
plt.xlabel(log_returns.columns[0])
plt.ylabel(log_returns.columns[2])
plt.grid()
plt.show()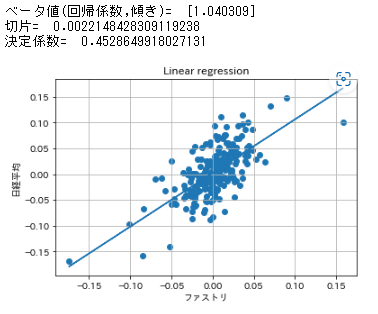
#共分散plot
X = log_returns.iloc[:,2] #日経平均
Y = log_returns.iloc[:,1] #しまむら
from sklearn import linear_model
clf = linear_model.LinearRegression() #線形モデル
X2 = [[x] for x in X]
clf.fit(X2, Y) # 予測モデルを作成
print("ベータ値(回帰係数,傾き)= ", clf.coef_)
print("切片= ", clf.intercept_)
print("決定係数= ", clf.score(X2, Y))
# 散布図
plt.scatter(X2, Y)
# 回帰直線
plt.title('Linear regression')
plt.plot(X2, clf.predict(X2))
plt.xlabel(log_returns.columns[1])
plt.ylabel(log_returns.columns[2])
plt.grid()
plt.show()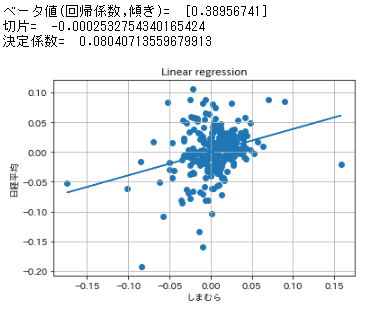
6.考察
ベータ値
ファーストリテイリング 1.04
しまむら 0.39
ファーストリテイリングは衣料品を扱ったディフェンシブ
銘柄のためβ値は低くなると推定したが意外にも1を超えていた。
既に海外での売上が国内売上を上回り、
海外での競争や拡大が求めれるのと、
近年では米中貿易摩擦等国際政治の不透明さから
グローバル企業であるファーストリテイリングのベータ値は
1よりも高くなっているものと思われる。
ローカルのアパレル小売りの株式会社しまむらのβは
5年週次=0.39であった。
ユニクロと比較すると規模も低く、ローカル依存度が高いので、
リスクも低くβ値は低くなっている。
7.株価折れ線グラフ比較
最後に3社の株価トレンドをmatplotlibで描画してみます。
df['ファストリ'].plot(kind='line')
df['しまむら'].plot(kind='line')
df['日経平均'].plot(kind='line')
plt.legend(['ファストリ','しまむら','日経平均'])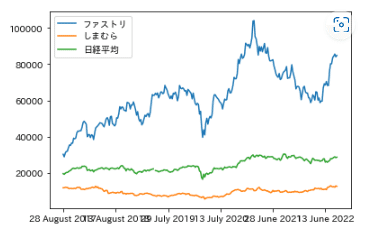
株価の単価が異なるので、別々に見た方がよさそうです。