
分析化学の話(4) - データの変動と正規分布

データの変動と正規分布の関係を考えてみます。
1. データは変動する?
図1のようなことがよく起こります。測定するたびにデータが変わるのです。

2. 無限に測定を行うと?
それでは、測定を無限に行うとどうなるでしょう?無限とはいきませんが、図2は、約1年間ほとんど毎日、朝食事前に血圧(収縮期血圧)を測定した実際の結果です。

3. ヒストグラム
どのデータが頻繁に現れるか、どのデータがめったに現れないか、それをビジュアルに示すのがヒストグラムです[1]。
図3のように、図2のデータをヒストグラムで表現すると、どのくらいのデータがどのくらいの頻度で現れるかわかります。

4. 正規分布
4.1 式
$$
p(x) = \dfrac{1}{\sqrt{2 \pi}\sigma} \exp \Big ( - \dfrac{(x - \mu)^2}{2 \sigma^2} \Big )
$$
$${x}$$:データの値、$${p(x)}$$:確率密度関数[2]、$${\mathrm{exp} (x)}$$:$${x}$$の指数関数($${e^x}$$と表すことも)、$${\mu}$$:平均値、$${\sigma}$$:標準偏差
4.2 グラフ

4.3 標準偏差とグラフの形

5. 正規分布の例: ガスクロマトグラフィーのベースライン[3]
試しに、クロマトグラフィーのベースラインのノイズがどのような分布(ヒストグラム)に従っているかを見ていきましょう。
手順1: 普通に見るベースライン
図6は、ごく普通に見るガスクロマトグラフィーのベースラインです。一見、なんの変哲もなく、フラットな直線のようです。でも、ベースラインといっても検出器で測定していることには違いありません。

手順2: 拡大してみる
図6を縦方向に拡大してみると、細かくギザギザしていると同時にうねっています。
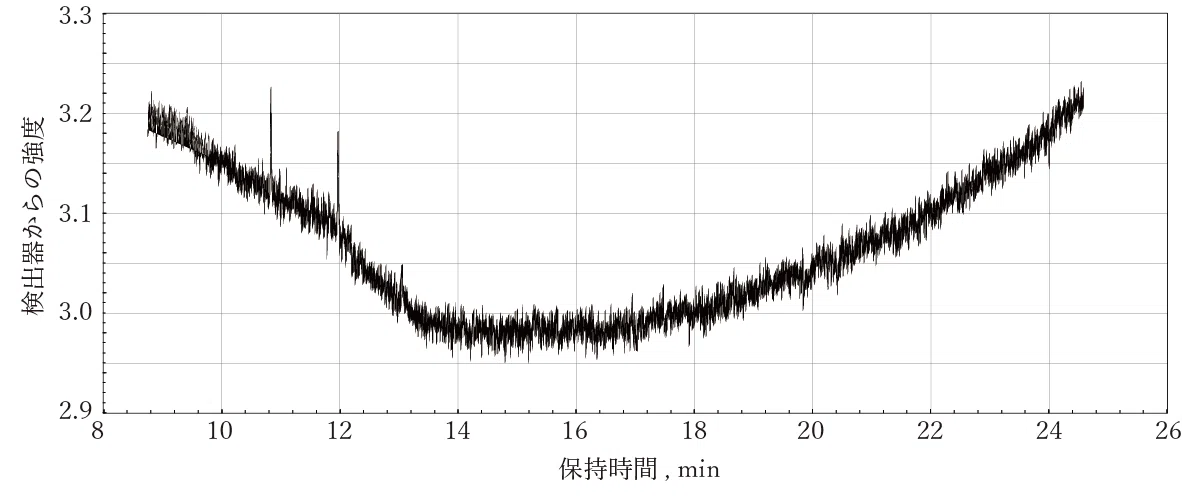
手順3: なめらかにする
うねりをとるために、準備段階として、ベースラインに移動平均[4]をほどこしできるだけ滑らかにします(図8)。

手順4: うねりを取り去る
細かなギザギザだけを抽出するため、もとのベースラインから滑らかにしたベースラインを差し引きます。

手順5: ヒストグラムを作る
図9のグラフは図2と似ているような気がします。そこで、同じようにヒストグラムを作ってみます。その結果が図10です。
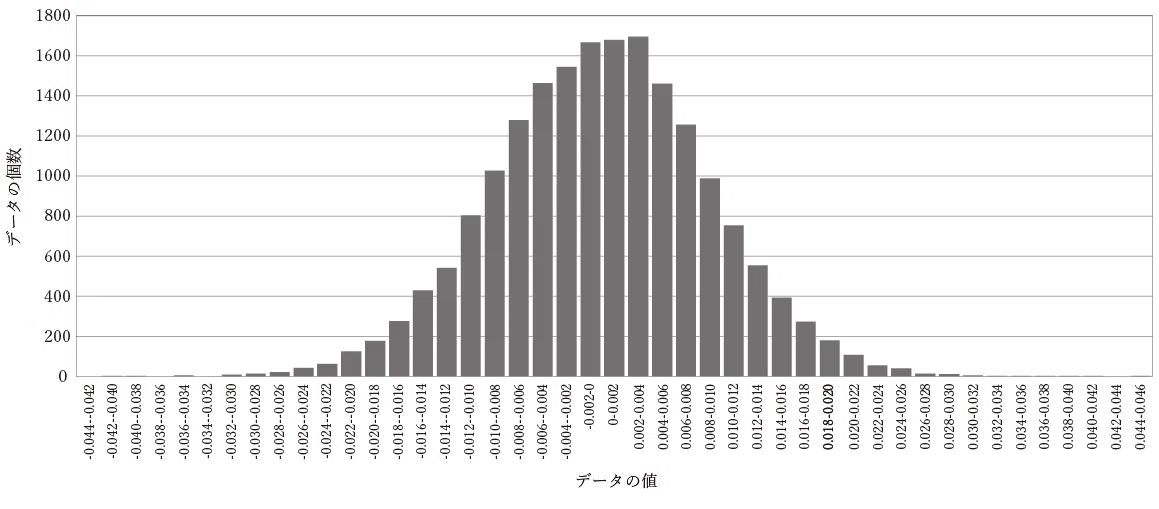
手順6: 正規分布を重ねる
ヒストグラムと正規分布曲線がきれいに一致します。このことから、独立したさまざまな要因が変動することによって、ガスクロマトグラフィーのベースラインが変動することがわかります[5]。

6.結論
正規分布に従う現象は、多くの要因(原因)が足し算的に(掛け算じゃない)独立に変動することによって生まれるといいます[5]。
図3の血圧の例は、マンシェットの巻き方、その時の体調、血圧計のしきい値の決め方など多くの要因が関係するから正規分布に従うものと思われます。
化学分析では、前処理、秤量、装置による測定、ピーク解析など一般に多くの手順を踏みます。つまり多くの要因が独立に重なってくるので、多くの繰り返しデータをとると、その結果は正規分布になるかもしれません(労力の関係でそこまでやる人はいませんが)。
測定するときは、背後に無数の測定データがあり、一定の仕方でばらついている(多くの場合、正規分布)と認識することが大切なんだろうなって思います。
文献とNote
[1] 舞田敏彦、"「平均は格差を隠す」平均値だけを見ても格差の実態は見えない"、ニューズウィーク日本語版、2024年8月21日(水)11時45分。高齢者世帯の平均貯蓄額は1652万円だが、中央値は700万円。著者は、「データというのは、最初は数字の羅列で、これを整理する第一歩は度数分布にすることだ。」と言っています。度数分布とはヒストグラムのことです。
[2] 難しいいい方をすると、データが$${x \sim x+\mathrm{\Delta}x}$$の間にある頻度(確率)が、$${p(x)\mathrm{\Delta}x}$$です。ちなみに、
$$
\displaystyle \int_{-\infty}^\infty p(x) \mathrm{d}x = \dfrac{1}{\sqrt{2 \pi}\sigma} \int_{-\infty}^\infty \exp \Big ( - \dfrac{(x - \mu)^2}{2 \sigma^2} \Big ) \mathrm{d}x = 1
$$
です。これは、図4の曲線とx軸に囲まれた面積が1になるということです。
公式:
$$
\displaystyle \int_0^\infty e^{-a^2x^2} \mathrm{d}x = \dfrac{\sqrt{\pi}}{2a}, \quad \quad \quad (a>0)
$$
(森口繁一、宇田川銈久、一松信、数学公式Ⅰ(岩波全書)、岩波書店、1956.)
[3] KI氏からベースラインのデータをいただきました。
[4] 移動平均とは滑らかにする方法です。例えば、

[5] 次の著書に書いてあるそうです("データ分析の書記録"より): 松下貢、"統計分布を知れば世界が分かる 身長・体重から格差問題まで"、中公新書、中央公論新社、2019.
【免責事項】本記事は単なるメモとして書かれたもので、その正確性を必ずしも保証するものではありません。本記事によって生じたトラブル、損失、又は損害に対して一切責任を負いません。また、著者が所属する組織とは関係ありません。誤りがあればご指摘ください。クレームはご遠慮ください。