
にじボイス API を試す

tl;dr
にじボイス API が正式リリースしたよ
5,000 文字分の無料音声生成クレジットが付与されるよ
クレジット消費は入力文字数に応じて計算されるよ
にじボイス公式の API 画面から音声は生成できるよ
Python でも生成してみたよ
下記のにじボイス API ページより Google アカウントでログインしましょう。

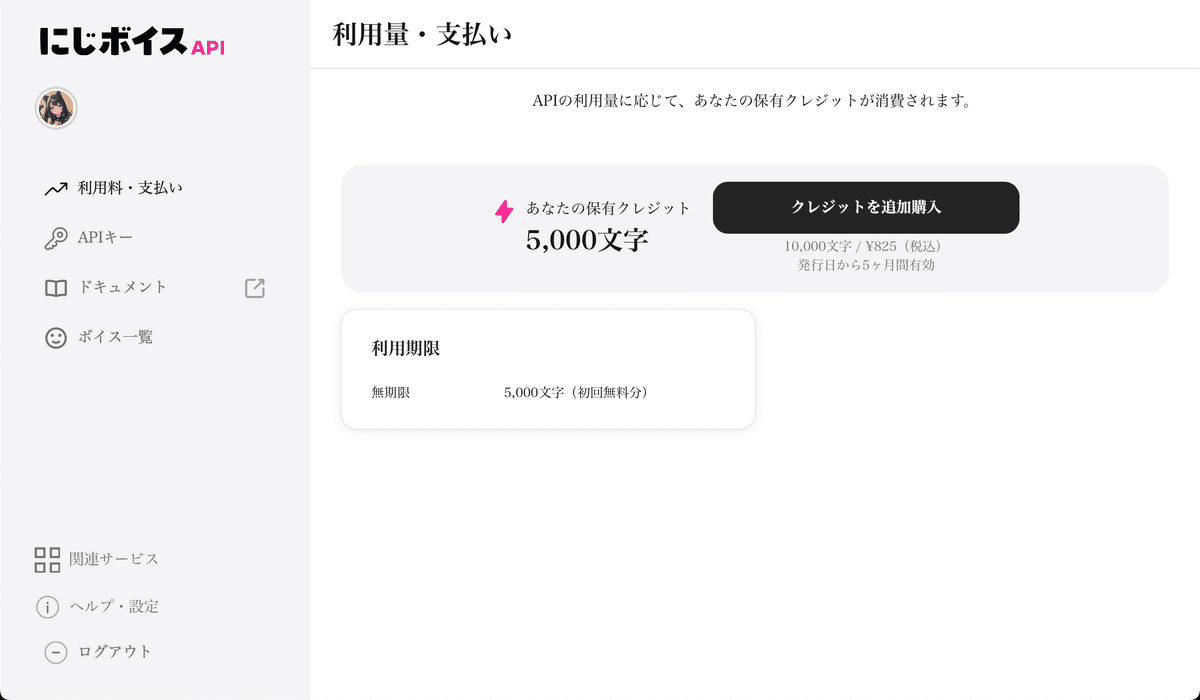
ログイン後の画面で現在の利用状況の確認や支払い、API キーの発行などが可能です。初回登録の無料利用枠として 5,000 文字の音声生成用のクレジットが付与されます。今のところ有効期限はないようです。
値段はというと、フリープランで毎月 1,000 文字まで無料。有料だと 1 文字あたり0.08~0.1 円程度のよう。クレジットカードを登録しなければ無料の範囲内で使うことも可能。検証する分には無料で試せそうです。

API キーを使って動かしてみましょう。default-key として初めからひとつだけ登録されています。右側にある目のマークを押すと API キーを確認することができます。

API キーの左下にコピーボタンがついていますのでクリックしてください。

にじボイス API の公式ドキュメントも用意されています。
API のリファレンスも公開されています。cURL や Node、Ruby、PHP、Python 他多数のリクエストフォーマットが記載されています。
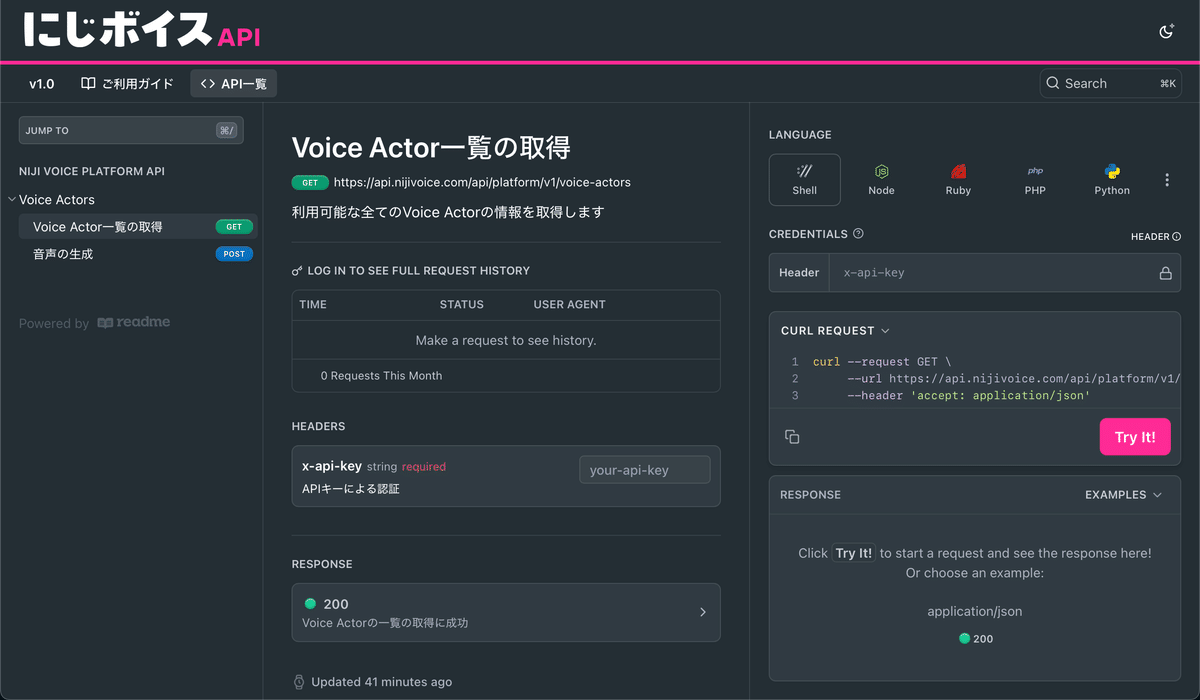
まずは音声生成!といきたいところですが、Voice Actor 一覧の取得から始めてみましょう。ちなみにこちらのリクエストは音声の生成ではないので無料です。この後の音声生成の前にリクエストの確認がてら触ってみます。
いろいろなプログラミング言語のリクエストに対応していますが、まずは cURL で動かしてみましょう。先ほどコピーした API キーを下記の画像のように Header のところに API キーを入れると「CURL REQUEST」の部分に --header が自動で入力されます。

にじボイスに限った話ではないですが、こういった API キーを入力する画面の画像などを含む記事を書かれる方は必ず隠すなりの対処をしてください。開発者の方々には言うまでもないことかもしれませんが、API キーを使い慣れていない方も試されると思うのでコメントまで。
では実行してみます。ピンク文字の「Try It!」をクリックしてください。

もしローカル環境で動かしたい場合は、左下のコピーボタンをクリックして、ローカル環境で実行してください。
id や名前、読み方、性別生年月日などのさまざまなキャラクターについての情報を取得することができます。
では試しに水戸明日菜さんの声で音声の生成をしてみましょう。左側のサイドバーから「音声の生成」をクリックしてください。

ページの下部を見ていきましょう。「required」という項目が音声の生成に必須の項目です。先ほど cURL を実行した際に id がありました。お好きなキャラクターの id を指定します。script に何を読み上げてもらうかを指定します。speed では読み上げ速度を調整します。任意で音声ファイルの出力フォーマットを指定できます。デフォルトは mp3 です。最後に API キーを指定します。

水戸明日菜さんの id は下記の通り。お好きなキャラクターの id を指定してください。
dba2fa0e-f750-43ad-b9f6-d5aeaea7dc16script は今回は下記の文章で音声を生成します。
あなたの名前はなんて言うの?speed は 1.0 として、x-api-key に API キーを入力して、右側のピンク色のボタン「Try It!」をクリックしてください。

audioFileUrl に生成した音声があり、audioFileDownloadUrl にダウンロードリンクがあります。14 文字分のクレジットが消費されました。文字数通りです。
今回生成した音声を置いておきます。かわいい。
せっかくなので、最後に開発者向けに Python でも実行してみましょう。右側の Shell を Python に変更します(クリックするだけ)。コードが現れますので、左下のコピーボタンよりクリックしてコピーしてください。

環境構築をしましょう。uv を使うので、uv をお使いでない方は読み替えてください。macOS で Homebrew をお使いの方は下記でインストール可能です。
brew install uvディレクトリとファイルを作成します。
mkdir nijivoice
cd nijivoice
touch nijivoice_generate.pynijivoice_generate.py に先ほどコピーしたコードを流し込みます。<YOUR_API_KEY> の部分がご自身で発行した API キーになっていることをご確認ください。
import requests
url = "https://api.nijivoice.com/api/platform/v1/voice-actors/dba2fa0e-f750-43ad-b9f6-d5aeaea7dc16/generate-voice"
payload = {
"format": "mp3",
"script": "あなたの名前はなんて言うの?",
"speed": "1.0"
}
headers = {
"accept": "application/json",
"content-type": "application/json",
"x-api-key": "<YOUR_API_KEY>"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)レスポンスとして返ってきたものは下記の通り。
{"generatedVoice":{"audioFileUrl":"https://storage.googleapis.com/ai-voice-prod-storage/platform/18ed9b0d-47f2-4272-83de-1d1d49893d0a/voices/2024/12/11/3d2f9fbf-62bb-4180-b042-df0bd8b70dca/uploaded-audio.mp3?GoogleAccessId=ai-voice-api-prod-sa%40algomatic-global-ai-voice.iam.gserviceaccount.com&Expires=1733969747&Signature=kljEFzbvscogDazrUX4D%2F3ElX9oMowO4Uqcpu8GO5wH30qzi1kTuKcum014Wwg9qeUbh721hrszcVU3NPa2pB3bzPZImD%2Bh%2Bwh0zqK2ES4ecB19dA5MNGKevmpx8V8681b9PI3do99oBaVwrwE9eOVL3prJ7XO9JBckeWoaNkme7uGFEdnIdRStpJ3GiPpK3mIvnZcij%2Bau0rD31Jyp8%2B13JCzb12iNCajM96U2rdVipE6wYMswjvyHVAeilI4oIWCgU6g3n%2BtG%2B60cuyfL7aGcXaYv6ijCjdZ1dtQ%2F9ynaLHMqYr62Oigsdx7a8IyxzjNWZ9XkPGm4ZmswXEoiaNQ%3D%3D","audioFileDownloadUrl":"https://storage.googleapis.com/ai-voice-prod-storage/platform/18ed9b0d-47f2-4272-83de-1d1d49893d0a/voices/2024/12/11/3d2f9fbf-62bb-4180-b042-df0bd8b70dca/uploaded-audio.mp3?GoogleAccessId=ai-voice-api-prod-sa%40algomatic-global-ai-voice.iam.gserviceaccount.com&Expires=1733969747&Signature=kljEFzbvscogDazrUX4D%2F3ElX9oMowO4Uqcpu8GO5wH30qzi1kTuKcum014Wwg9qeUbh721hrszcVU3NPa2pB3bzPZImD%2Bh%2Bwh0zqK2ES4ecB19dA5MNGKevmpx8V8681b9PI3do99oBaVwrwE9eOVL3prJ7XO9JBckeWoaNkme7uGFEdnIdRStpJ3GiPpK3mIvnZcij%2Bau0rD31Jyp8%2B13JCzb12iNCajM96U2rdVipE6wYMswjvyHVAeilI4oIWCgU6g3n%2BtG%2B60cuyfL7aGcXaYv6ijCjdZ1dtQ%2F9ynaLHMqYr62Oigsdx7a8IyxzjNWZ9XkPGm4ZmswXEoiaNQ%3D%3D&response-content-disposition=attachment%3B%20filename%3D%22voice_%E3%81%82%E3%81%AA%E3%81%9F%E3%81%AE%E5%90%8D%E5%89%8D%E3%81%AF%E3%81%AA%E3%82%93%E3%81%A6%E8%A8%80%E3%81%86%E3%81%AE_%E6%B0%B4%E6%88%B8%20%E6%98%8E%E6%97%A5%E8%8F%9C.mp3%22","duration":2043.0000000000002,"remainingCredits":4972}}
実装上は audioFileUrl の部分を再生処理に渡せば良いでしょう。
以上です。
私は音声合成の専門ではありませんが、それでもここ二年の合成音声の「ナチュラルさ」の進展には目を見張るものがあります。
AI Tuber がポツポツと現れ始めた 2023 年初頭の段階では、VOICEVOX や Koeiromap(現 Koemotion)、COEIROINK くらいしか使える音声合成の選択肢はなかったのですが、それから RVC が 4 月に発表されて(これはボイチェンですが)、Bert-VITS2、Style-Bert-VITS2、Fish Speech とかなりこなれた音声合成技術が発達して、一気に加速しましたね。
海外の音声合成事情(たとえば英語など)はあまり追えていないのですが、ElevenLabs の AI Voice Cloning もなかなかの「ナチュラルさ」だと思います。ChatGPT のリアルタイムで会話できる Advanced Voice Mode や Gemini でもリアルタイム会話ができるようになったことですし、一年後にはどうなっているのでしょうか。楽しみです。