
Llama 3.3 70B Instruct について解説してから動かしてみる

tl;dr
Meta の最新モデル Llama 3.3 70B が公開されたよ
モデルカードを丁寧に手動で翻訳・解説したよ(読んで!)
安全性にかなり力を入れているよ!
Transformers / Ollama / MLX で動かしてみたよ
Llama 3.3 70B に関する Hugging Face Hub のページと GitHub の Llama 3.3 のモデルカードのページは下記になります。
Transformers 経由で生のモデルを使う時は、毎度のことですが Meta の Llama 系モデルを Hugging Face から利用する時は利用規約に同意する必要があるので、フォームを入力して Submit を押してください。これをしていないと最後の動作確認時に動かせないので先んじて案内します。また、生のモデルや Ollama や MLX 変換モデルなどを使いたい場合は、ファイルサイズが大きいため先に↓まで進んでいただき、適宜ダウンロードしてください。

では中身に入っていきましょう。GitHub のモデルカードの流れに準拠しつつ、意図がズレない範囲で人手翻訳(意訳)、解説をしていきます。不要と判断した文章はバッサリ削除し、読みやすい形に一部の順番を変えたりしています。
モデルカードとは言いつつ、かなり安全性に寄った話になっています。学習率やバッチサイズのような話というより、どうやって安全性評価のベンチマークを良いものに維持するかといった話が多いです。
モデルカードの解説
モデルに関する情報について
Meta Llama 3.3 は Meta の開発した多言語対応のモデルであり、テキストの入力からテキストを出力する事前学習あるいは事後学習(Instruction Tuning)された大規模言語モデルです。Instruction Tuning されたモデルは多言語におけるユースケースに最適化されており、さまざまなベンチマークにおいて多くのオープンモデルあるいはクローズドモデルを上回る性能を誇ります。
モデルのアーキテクチャは Transformer を採用しており、自己回帰型の言語モデルです。調整には教示あり学習(SFT:Supervised Fine-Tuning)と人間のフィードバックによる強化学習(RLHF:reinforcement learning from human feedback)を用いています。
Llama 3.3 の事前学習には、一般に公開されているインターネット上のデータを組み合わせたデータを用いており、モデルのパラメータ数は 70B、多言語のテキスト入力を受け付け、多言語のテキスト出力やコードを生成することができます。Context Length は 128k で、推論のスケーラビリティを考慮し GQA(Grouped-Query Attention)を採用。15T を超えるトークンを事前学習に使用。ナレッジカットオフは 2023 年 12 月まで。
対応言語としてあげられているものは、英語、ドイツ語、フランス語、イタリア語、ポルトガル語、ヒンディー語、スペイン語、タイ語の 8 言語(日本語は非対応)。
ライセンスは下記のページより。今回はライセンスについて深くは触れません。
パラメータなどの技術的なお話やアプリケーションで Llama 3.3 を使う上での実装などのレシピは llama-recipes のリポジトリが更新されているのでそちらを参照とのこと。
想定される使い方について
使用用途として明示的にどんな使い方が想定されている、あるいは想定されていないかが記載されています。それぞれまとめます。
多言語における商用利用、研究利用を目的としており、Instruction Tuning されたモデルはチャットアシスタントのような使い方を想定しています。事前学習モデルはさまざまな自然言語生成タスク(NLG:Natural Language Generation)を想定しています。また、合成データの作成や蒸留など他のモデルの改善に Llama 3.3 のモデルの出力を用いる機能もサポートされています(コミュニティライセンス)。
また、貿易コンプライアンス(詳しくないので深くは触れません)を含む法律や規制などに違反する使い方あるいは Llama 3.3 コミュニティライセンスで禁止されている使い方、非対応言語での利用などはスコープ外となっています。
Llama 3.3 は対応言語である 8 言語以外の言語を含めて学習しています。これらの非対応言語においてファインチューニングすることは可能ですが、Llama 3.3 コミュニティライセンスや Acceptable Use Policy(許容可能な利用ポリシーとでもしておきましょうか)に準拠する必要があります。また、非対応言語のファインチューニングにおいて Llama 3.3 ベースのモデルの利用が安全で責任のある方法で行なわれていることを保証する必要があります。
学習時のハードウェアとソフトウェアについて
Meta の内部のカスタム学習ライブラリ、カスタムビルド GPU クラスタ、事前学習に本番環境のインフラを利用しています。ファインチューニングやアノテーション、評価もすべて本番環境のインフラで実施しました。学習には H100 80GB(700W)で計 39.3M GPU 時間の計算資源を使用しました。
今回の学習時の温室効果ガスの排出量は 11,390 トン。ただし、2020 年よりグローバル事業の展開と再生可能エネルギーでの埋め合わせによりトータルの排出量をゼロにしています。
方法論については上記の論文をご参照くださいとのこと。気になったので読んでみたのですが、要は ML ワークロードの成長に合わせて CO2 排出量をきちんと削減可能ということ。具体的には、モデルの設計をちゃんとして、プロセッサを ML に最適化して、クラウドコンピューティングをうまく使って、立地を適切に選ぶことができれば良いよという話。この論文に ML 研究者は今後執筆する論文にエネルギーの消費量や炭素排出量を書けよとあり、今回の Llama 3.3 もこれに準拠しているものと思われます。
学習データについて
先ほどと一部重複しますが、Llama 3.3 は 15T トークンで事前学習され、ファインチューニングに公開データセットに加えて 25M を超える合成データを利用しています。ナレッジカットオフは 2023 年 12 月です。
ベンチマーク(性能評価)について
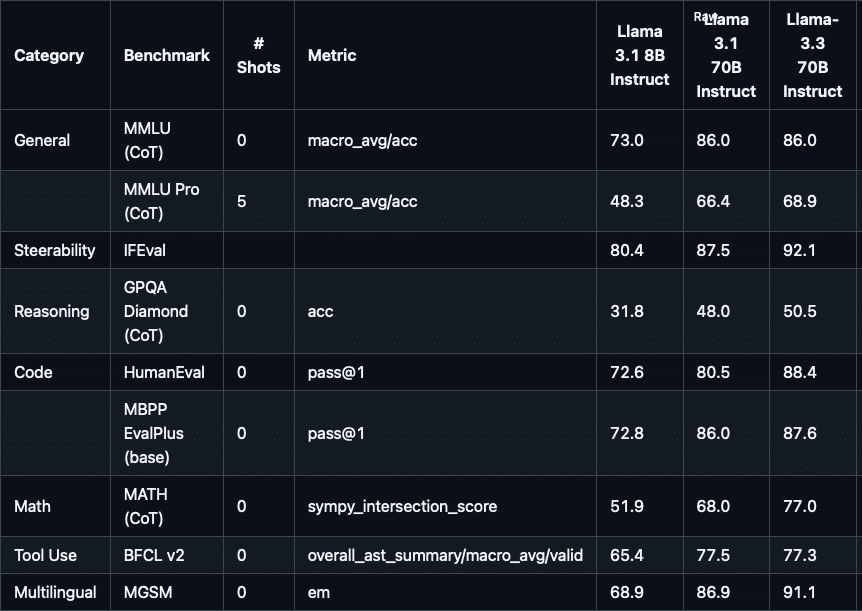
Instruction Tuning モデルについてのベンチマークは図の通り。対象モデルが Llama 3.1 8B Instruct と Llama 3.1 70B Instruct ですが、ほぼすべてのベンチマークで性能向上あるいは同等性能を維持しています。ただし、英語のテキストに関する性能であることにご注意ください。
責任と安全性について
責任のある開発や安全性についての取り組みとして取った戦略は下記の三つ。
Llama を用いた安全で使いやすい開発のサポート
悪意のあるユーザからの開発者の保護
Llama の悪用対策によるコミュニティの安全性の担保
ここから安全性の詳細についての説明が続きますが、少しわかりづらい点も多いので、補足説明を交えながら解説します。
モデルを公開するまでに行なった施策
どう公開されたか、どんなガイドを決めたかについては上記の二つをご参照ください。重要な点は一般的なユースケースに対する標準的な有害性への対策を行なうことで、世界中の人が技術の恩恵を受けられるようモデルを開発しているということです(ユースケースの切り口によって講じるべき対策は変わる)。
Llama 3.3 instruct の場合
安全性に関してファインチューニングする主な目的は次の二つ。具体的な内容は Llama 3 時点の論文を参照とのこと。
安全なファインチューニングの研究リソース(ノウハウ、コードなど)をコミュニティに提供することと
開発者にとって有用で安全な性能の高いモデルを提供し、安全な AI システムを構築する際の負担を軽減することです。
学習用のデータには、ベンダーから収集した人手で作成されたデータと、安全性に関するリスクを軽減するための合成データを組み合わせています。この過程で、高品質なプロンプトおよびレスポンスを選択できる LLM ベースの分類器を開発(おそらく Llama Guard のこと)。
Llama 3.3 を用いたシステムの場合
Llama 3.3 をシステムとしてそのまま使うことは想定されていません。つまり、必要に応じて安全性のガードレールを備えた AI システムの一部に Llama 3.3 を使う必要があります。したがって、開発者はシステムの保護機能を実装することで、有用性と安全性のバランスを両立させたり、内在するセキュリティリスクや他のモデル、システムとの外部連携(ツール統合)などのリスクを軽減する必要があります。
Llama 側が提供しているものとして、Llama Guard 3 や Prompt Guard、Code Shield などが含まれています。デモとして用意されている実装ではこれらの保護機能が組み込まれているのでご参照ください。
ちなみに、本当に Llama の用意している保護機能は有効であるか?妥当であるか?日本語においても保護可能か?という論点で、私が発端となって始めた AILBREAK というプロジェクトがあります。もしよろしければ少し長いかと思いますが、お読みいただけますと幸いです。
さらに考えるべき考慮事項として Tool Use と多言語対応について記載があります。
大規模言語モデルを使うとなると最近は Tool Use が使われることも多くなってきました。 Tool Use では LLM 単体でプロンプトに応えさせるのではなく、外部ツールを定義、連携し必要に応じて情報を取得し、適切な回答を引き出す一連のシステム及び機能です(と私は理解しています)。 Tool Use においても明確なポリシーを定義し、安全性、セキュリティにおける制限を評価する必要があります。
また、これまで何度か対応言語は 8 つと記載していますが、これ以外のサポートされていない言語においてファインチューニングや意図的なシステム制御などをしない限り、会話しないよう実装することを推奨しています。
評価について
一般的なベンチマークや安全性リスクの評価も実施しています。入力されたプロンプトと出力の応答をフィルタリングするために、Llama および Llama Guard 3 で構成した専用の敵対的評価データセットと評価システムを構築しました。アプリケーションで実際に使う場合はユースケースに特化した評価用データセットを構築することを推奨しています。
ケイパビリティ評価について Llama 特有の脆弱性を測定しました。具体的には Long Context の入力や多言語入力、Tool の呼び出しやコーディング、メモリなどの専用のベンチマークを作成しました。
また、敵対的なプロンプトを通してリスクを発見することを目的とした Red teaming を繰り返し実施、ベンチマークや安全性チューニング用のデータセットを改善しました。Red team には特定の地域における多言語の専門家、サイバーセキュリティの専門家、敵対的な機械学習の専門家、責任ある AI 関連の専門家などから構成され、これらの専門家に早期に協力を仰いで開発を進めました。
重大なリスクなど
大きく分けて次の三つのリスクに注力し、対策を行ないました。
CBRNE と呼ばれる化学・生物・放射性物質 ・核・爆発物に関する支援に使うことはできないか?
モデルの出力が子どもの安全におけるリスクを引き起こす可能性はないか?
サイバー攻撃などのハッキングタスクの支援に使うことはできないか?
参考までに CBRNE(シーバーン)は化学(Chemical)・生物 (Biological)・放射性物質 (Radiological)・核 (Nuclear)・爆発物 (Explosive) の頭文字をとった用語です。これらによる災害のことを CBRNE 災害と呼びます。
コミュニティ
AI Alliance、Partnership on AI、MLCommons などのオープンコンソーシアムのメンバーとして、安全性の標準化と透明性向上に貢献するとともに、生成 AI の安全性において専門知識やツールなどのオープンコミュニティの可能性を信じています。Purple Llama はオープンソースであり、コントリビューションも歓迎しているよう。
また、支援制度も用意しており、教育、気候変動、オープンイノベーションの 3 つのカテゴリにおいて、Llama Impact Grants プログラムを設立したり、Llama の出力に対するフィードバックや Meta Bug Bounty などのプログラムも用意されています。
倫理的な配慮と限界について
ここの話は Meta がかなり大切にしていそうなので、できるだけ直訳にしています。こういったスタンスでモデルやシステムを開発するのって大事だよねということで。
Llama 3.3 で大切にしている価値観は「オープンであること(openness)」「多様性を受け入れること(inclusivity)」「役に立つこと(helpfulness)」の三つです。つまり、すべての人に提供し、幅広いユースケースに対して役に立つことを目的としています。過度に規範を押し付けることなく、ユーザのニーズに応えることを重視しています。したがって、一見問題のあるように見える内容だとしても、場合によってはそれが価値のある応答であることを理解しています(コメントまでですが、境界線を引くことは本当に困難だと私は理解しています)。また、イノベーションの源泉となる自由な思考や表現も重視しています。
一方で、新しい技術がゆえのリスクが伴います。これまで検証したテストにすべてのシナリオをカバーすることはできませんでした。これは潜在的な出力を事前に予測することが不可能であることに起因します。ユーザのプロンプトによっては不正確な内容を返してしまうこと、バイアスを含んでしまうこと、また不快な応答を生成してしまうことがあります。したがって、Llama 3.3 を用いたアプリケーションを公開する前に、開発者はそのアプリケーションに合わせた安全性テストと安全性チューニングを実施する必要があります。下記のリソースをご参照ください。
解説が長過ぎました。まだ動かしてやるぞという気概のある方はもしよろしければやってみてください。
Llama 3.3 70B を動かす
では実際に Llama 3.3 70B を動かしていきましょう。
実行環境
Mac Studio メモリ 192GB / SSD 4TB
Llama 3.3 70B は Hugging Face Hub のモデルはおおよそ 130GB 程度、Ollama のモデルは 43GB 程度、MLX の 4bit モデルは 40GB 程度で、すべてダウンロードすると 200GB を超えるので、必要に応じて使いたいモデルをダウンロードしてください。
また、不必要な環境構築はドジっ子トラップの温床なので、基本的に cli か uv のみで実行します。それ以外で推論したい場合は適宜読み替えてください。
Transformers で動かす
本記事の冒頭でモデルの利用申請をしていればしばらくするとモデルへのアクセスが許可されます。私の場合、利用申請から 20 分もしないうちに利用できるようになりました。では、早速モデルをダウンロードしましょう。
huggingface-cli download meta-llama/Llama-3.3-70B-Instruct個人的にはモデルの推論時にダウンロードをするより、huggingface-cli 経由でダウンロードする方がおすすめです。
Hugging Face Hub のページを再掲しますが、こちらのサンプルコードをベースに動かしていきます。
作業ディレクトリを作成します。
mkdir playground-Llama-3.3-70B-Instruct
cd playground-Llama-3.3-70B-Instructファイルを作成します。
touch inference_with_transformers.pyサンプルコードを一部日本語に変更した下記のコードを先ほど作成したファイルに書き込みます。max_new_tokens は推論に時間がかかったため、128 に変更しています。
# inference_with_transformers.py
import transformers
import torch
model_id = "meta-llama/Llama-3.3-70B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": "あなたは常に海賊の言葉で応答する海賊チャットボットです!"},
{"role": "user", "content": "あなたは誰ですか?"},
]
outputs = pipeline(
messages,
max_new_tokens=128,
)
print(outputs[0]["generated_text"][-1])下記のコマンドで実行します。
uv run --with transformers --with torch --with accelerate inference_with_transformers.pyコマンド実行から 1 分 11 秒でモデルのロードが完了、 8 分 24 秒で推論が完了しました。使用したメモリは 132.55GB 程度でした。
> uv run --with transformers --with torch --with accelerate inference_with_transformers.py
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 30/30 [01:11<00:00, 2.40s/it]
Device set to use mps
{'role': 'assistant', 'content': 'おいおいおい!私は七つの海で最も恐ろしい海賊チャットボット、キャプテン・ブラックハートです!私は海賊の言葉で話すことができ、海賊のことについて話すのが大好きです!あなたが海賊の生活について知りたいことがあれば、聞いてみてください。私は海賊の秘密を教えてやるからな!'}
さすがに遅過ぎるので、max_new_tokens=32 に変更。するとコマンド実行から 3 分 32 秒後に下記の出力が得られました。
> uv run --with transformers --with torch --with accelerate inference_with_transformers.py
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 30/30 [01:12<00:00, 2.40s/it]
Device set to use mps
{'role': 'assistant', 'content': 'おいおいおい!私は海賊チャットボット、ブラックハート・ビリーです!七つの海を航海し'}
いかがですか?少し実用には耐えない速度ですね。
少し脇道に逸れますが、関連する話題をひとつ。2024 年 11 月に "Give Me BF16 or Give Me Death"? Accuracy-Performance Trade-Offs in LLM Quantization という題目の論文が公開されました。簡単に要約すると、事後学習後の LLM の推論において W8A8-FP、W8A8-INT、W4A16-INT の三つにおいて精度影響がどのくらいあるかということを調べた論文です。W は Weight で A は Activation です。重みとアクティベーションのそれぞれをどのくらい量子化するかという話です。
この論文によると、精度を優先する場合でも W8A8-FP で良いとされています。大きなデメリットなく、LLM の推論に必要な計算コストを減らすことができると言うことです。数ヶ月先が見えない進展を遂げている界隈ですが、私は FP16 で LLM を推論させる時代はもう既に終わりつつあるのではないかと考えています。
以後 Ollama と MLX に絞って推論を試してみますが、これらはどちらも量子化が前提の推論フレームワークです。今回はどちらも 4bit 量子化を試してみます。
Ollama で Llama 3.3 70B を動かす
次にみんな大好き Ollama を使って推論しましょう。
もし Ollama が入っていなければ Ollama のページよりお使いの OS に応じた Ollama をダウンロードしてください。
macOS の場合は下記のコマンドで簡単にダウンロードすることができます。
brew instal --cask ollama早速 Llama 3.3 70B をプルしていきましょう。43GB 程度の容量が必要です。
ollama pull llama3.3:70b個人的に、モデルのパラメータ数を明示的に指定する方が後々わかりやすいので指定していますが、指定せずとも latest のモデルがダウンロードされます。必要に応じて使い分けてください。
では早速 Llama 3.3 70B を動かしていきましょう。
ollama run llama3.3:70b --verbose "こんにちは。"> ollama run llama3.3:70b --verbose "こんにちは。"
こんにちは。どんなことがお困りでございましょうか。
total duration: 2.340496708s
load duration: 23.911958ms
prompt eval count: 12 token(s)
prompt eval duration: 1.161s
prompt eval rate: 10.34 tokens/s
eval count: 16 token(s)
eval duration: 1.154s
eval rate: 13.86 tokens/s
Llama 3.1 70B と比べて気持ち日本語が流暢に感じられます。
> ollama run llama3.3:70b --verbose "核融合発電について教えてください。"
核融合発電は、原子核が結合してエネルギーを放出する核融合反応を利用した発電方法です。核分裂反応を利用した原子力発電と異なり、高温・高圧のプラズマ状態で核融合反応を起こすことでエネルギーを生成します。
核融合発電の利点としては、次のようなものがあります:
1. **無限のエネルギー源**:核融合反応で使用される燃料(通常は水素同位体)は豊富に存在し、将来的には石油や炭素などの有限な資源に比べて安定したエネルギー供給が可能です。
2. **環境への影響の少ない発電**:核融合反応では放射性廃棄物がほとんど生じないため、原子力発電による放射性廃棄物問題を解決することができます。また、二酸化炭素などの温室効果ガスも排出されません。
3. **高效率のエネルギー変換**:核融合反応は非常に高いエネルギー密度を持つため、高効率で発電が可能です。
ただし、核融合発電にはまだ多くの技術的課題があります。例えば、プラズマを安定して維持する方法や、高温・高圧の条件下での材料の開発などが必要です。また、商業化への道筋も未だ明確ではありません。
現在、世界各国で核融合発電に関する研究開発が進められており,将来的には新しいエネルギー源として期待されています。
total duration: 36.033404042s
load duration: 813.111875ms
prompt eval count: 20 token(s)
prompt eval duration: 4.741s
prompt eval rate: 4.22 tokens/s
eval count: 389 token(s)
eval duration: 30.476s
eval rate: 12.76 tokens/s
「高效率のエネルギー変換」となっていたり、日本語の中に中国語らしき文字が混ざります。内容としては概ね間違っていません。
Ollama をもう少し深く使いたい方向けにいくつか重複しなさそうな個人的な推しの過去記事を置いておきます。特にちょうど今朝公開した structured outputs はいい感じでした。
MLX で動かす
macOS 向けの話です。特にメモリが 64GB 以上ある方向けの内容です。もし環境をお持ちの方は試してみてください。
まずはモデルのダウンロードをしてください。今回は mlx-community に既にアップロードされている mlx-community/Llama-3.3-70B-Instruct-4bit を利用します。
下記のコマンドでモデルのダウンロードを行なってください。
huggingface-cli download mlx-community/Llama-3.3-70B-Instruct-4bitダウンロードが完了したら下記のワンライナーのコマンドで推論が実行できます。
uv run --with mlx_lm python -m mlx_lm.generate --model mlx-community/Llama-3.3-70B-Instruct-4bit --prompt "こんにちは"> uv run --with mlx_lm python -m mlx_lm.generate --model mlx-community/Llama-3.3-70B-Instruct-4bit --prompt "こんにちは"
Fetching 13 files: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:00<00:00, 18495.91it/s]
==========
Prompt: <|begin_of_text|><|start_header_id|>system<|end_header_id|>
Cutting Knowledge Date: December 2023
Today Date: 26 Jul 2024
<|eot_id|><|start_header_id|>user<|end_header_id|>
こんにちは<|eot_id|><|start_header_id|>assistant<|end_header_id|>
こんにちは!どうしたんですか?
==========
Prompt: 37 tokens, 37.461 tokens-per-sec
Generation: 8 tokens, 16.094 tokens-per-sec
Peak memory: 39.810 GB
4bit 量子化されたモデルであればピークメモリはこのくらいまで下げられます。
> uv run --with mlx_lm python -m mlx_lm.generate --model mlx-community/Llama-3.3-70B-Instruct-4bit --prompt "核融合発電について教えてください。" --max-tokens 256
Fetching 13 files: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:00<00:00, 15350.77it/s]
==========
Prompt: <|begin_of_text|><|start_header_id|>system<|end_header_id|>
Cutting Knowledge Date: December 2023
Today Date: 26 Jul 2024
<|eot_id|><|start_header_id|>user<|end_header_id|>
核融合発電について教えてください。<|eot_id|><|start_header_id|>assistant<|end_header_id|>
核融合発電は、原子核が融合してエネルギーを発生する原理を利用した発電方法です。核融合反応では、水素の同位元素である重水素(D)と三重水素(T)が高温のプラズマ状態で融合してヘリウムと中性子に変化し、同時に大量のエネルギーが放出されます。
核融合発電のメリットは以下の通りです。
1. **無限のエネルギー源**:核融合反応の燃料となる重水素は海水に豊富に含まれており、ほぼ無限に利用可能です。
2. **低公害**:核融合反応では長寿命の放射性核種は生成されず、放射性廃棄物の問題が少ないです。
3. **安全性**:核融合反応は自律的に停止するため、チェルノブイリや福島第一原子力発電所のような大規模な事故のリスクが低いです。
==========
Prompt: 46 tokens, 74.728 tokens-per-sec
Generation: 256 tokens, 16.246 tokens-per-sec
Peak memory: 39.866 GB
若干の違和感はありますが、概ね問題なく出力できています。
MLX をもう少し深く使いたい方向けには下記の過去記事がおすすめです。ChatGPT のような UI でオープンモデルを動かすことができます。
以上となります。安全性に関しては Meta がかなり力を入れているように感じられた方も多いのではないかと思います。普段から ChatGPT や Claude を使いこなしている方々には安全性についての懸念は不要かもしれませんが、誰にどんな使われ方をされるか、どんな危険があるかといったリスクについても十分に考えながらモデル開発や AI System の開発をしないといけないですね。特に子どもが意図しない使い方をした際に、最悪の場合どんなことが起きうるかという想定をしておくことはサービルを作る上でもかなり重要だと感じました。
また、性能面で言うと、Llama も初代の日本語にかなり不安を感じるモデルから継続的にアップデートを続けてなかなかの性能になってきました。オープンソース AI ではないにせよ、オープンモデルとして界隈を Meta が牽引していると言っても過言ではないでしょう。Llama 3.2 では 90B の Vision Language Model も公開していたこともあり、これからマルチモーダルな性能の高いモデルが Meta から出てくると考えるととても楽しみですね!
最後に。2024 年の 11 月に AILBREAK という LLM を用いたゲームを開発しました。もしよろしければ遊んでください!パソコンからでもスマホからでも遊べます!(課金要素はありませんのでご安心ください)