
【projectItemRenamer.jsx】環境読込 55【開発記】

環境読込の parse まとめ🤤
環境確認
草案作成
UI構築
環境保存
環境読込 ←今ココ
準備処理
選択判定
候補処理
選択処理
改名処理
----備忘録
setData(argv1,argv2) → setData({argk1:argv1,argk2:argv2})
obj2strの文字列中エスケープ処理
→記事の画像用意、変に凝ってめっちゃ日数消費してて本末転倒の予感🤪
→この記事は只の思い出話
さてそれじゃ parse の纏め記事よー🤤
今回の parser は本格的な parse を作った事が無かったので勉強の為に始めたけど、結構良い経験になったのかなと思う。
難所だったのは矢張り構造の認識かなぁ?🤔
まぁ eval(str) や return (Function('return ('+str+')')()) だと JS の式とかもなんもかんも parse しちゃうから欲しい値しか parse しないためにも独自のものがあっても良い…筈🤪
OTSParser
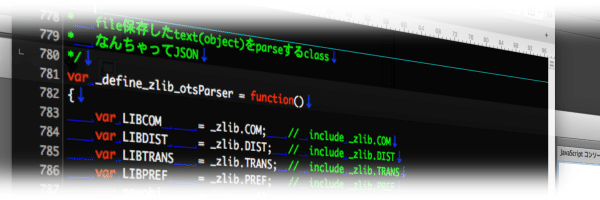
OTSParser は str2obj から呼ばれる文字列解析オブジェクトとして作成を開始🤤
当初は eval とか MDN の安全な parse の例文 で済ますつもりだったけどどっちもそんなに「安全」ではないのよねって気付いて作り始めたわけなんだけど…🙄
参考までに JSON.parse とかも見てみたけれど、使い勝手の事もあるし結局手作りになったわけ🤤
妥協しても良かったけどこれ仕事じゃないし🤪
JSON.parse みたいに1回の走査で変換ヨロシクもダメではなかったけれど何せ不定階層数の万能 parse は作った事が無いし折角機会ができたしで始めて、すんごい時間かかってしょんもりw
1走査変換だったら、もしかしたらもっと時間かかってたかも?
analyzeStrObjEscapeChar
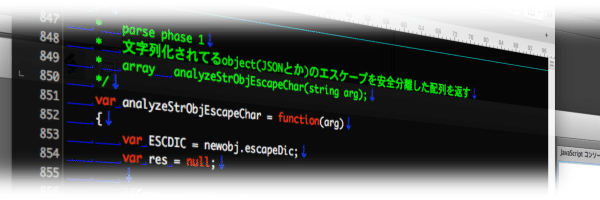
関数名なっが🙄
短くしたい
もっと短くしたい…
もう完成しちゃったからやんない…
phase 1 は文字列を1文字ずつの配列に変換しつつ、次の phase を簡単にするための仕掛けを施す処理🤤
どういう事かと言うと…
a = '"'; // \"
b = "\\" + a; // \\\" (ややこしい表記)
//判定
if(a==="\"")console.log("aは区切り文字\n"); // 出力される
if(b==="\"")console.log("bは区切り文字\n"); // 出力されないそりゃ2文字になってるんだから等価に掛かるはずがない🤪
って仕掛けを想定して最初にこさえたのがこの phase 🤤

analyzeStrObjToken
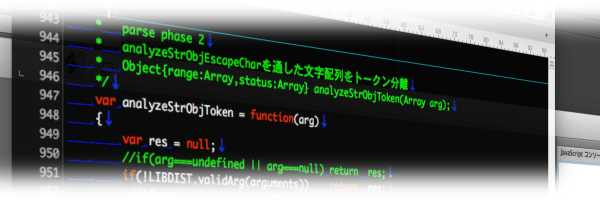
phase 2 は token がどの囲みの範囲なのかを解析する処理🤤
最初は最寄りの範囲を記録しようかなと思ったんだけど、結局空白と文字列以外は区切り文字だけ記録して後は全部何か token って処理に落ち着いちゃった🤪
種別を設定する phase だったので種別の定義がなされ、以降その種別をずっと利用する事にしたからこの parser としては重要な役割を持ってると思う🤤

buildTokenString
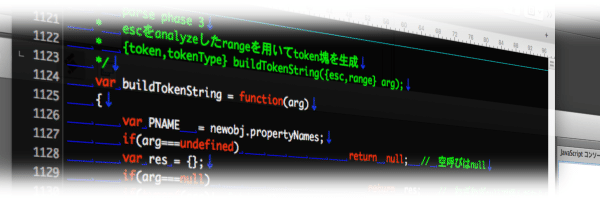
phase 3 は type を見ながら同じ種別で塊にしていく処理🤔
この段階ではまだ「種別ごとに固める」しか処理をしていなくて括弧系の区切り文字もまだ分離したままになってる🙄
効率よく処理するならこの段階で既に統合したオブジェクトにしてしまうべきだけれどこの段階ではまだオブジェクトが無かったので token 塊の配列と、それに対応した type の配列を作って対応したのよね🤔
オブジェクト使って書き直したらもうちょっと後の phase の数が減ったかも…?🤪(歴史に if は無い

OTSPElement
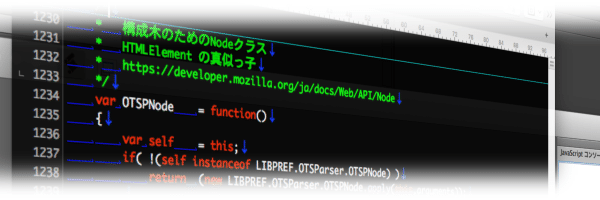
次の phase の準備として用意したオブジェクト🤤
ここまでの phase ではまだ階層構造になっておらず、所謂シリアライズされた状態のままなのね?🤔
これを階層構造、記事中では「構成木」と呼んでいた代物に構築するのが目的で、それを楽にするためのオブジェクト🤤
似た様なオブジェクトが既に存在しており、それを真似る事で設計の時間を大幅に短縮🤪(できた筈…w
最初からこのオブジェクトが有ったら前半の phase をすっ飛ばしていきなりこのオブジェクトに積むとか出来たのかも…?🤔(歴史にi(略
buildTree
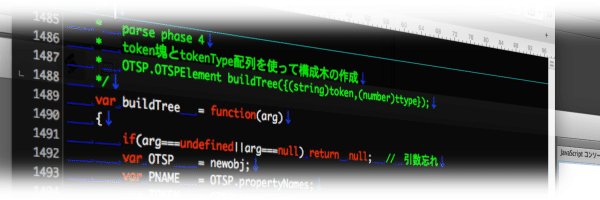
phase 4 は平坦な状態で並んでる token 塊配列を多階層構造 に組み替える処理🤔
デリミタが現れる度に階層を生成するには再帰呼出の逆みたいな処理を手で書く必要が有るのよね🤤
逆に、普通のオブジェクトを文字列化するなら大体は配列や連想配列みたいな奥の階層を持つものが出てきたら、その階層を指定して再帰呼出して文字を吐き出していく、という処理になる。これの逆の事をする🙄
なんて事は無く、処理中の配列スタックを1つのオブジェクトとして退避スタックへ放り込んで仮想下層処理をするだけ🤪(ややこしい
ここではデリミタ基準で階層構造を作るけど、厳密な値の並びは検査しない🙄(役割が違う
オブジェクトは単純配列より多くの情報を持てるのでここでオブジェクトに含ませて単体のデリミタは消滅🤤

parseLeaf
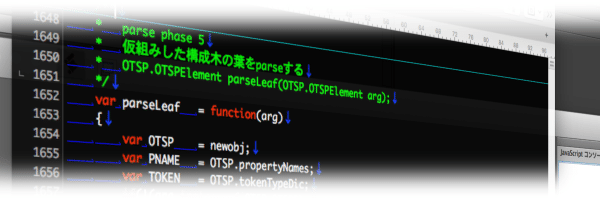
phase 5 は構成木の末端を parse する処理🤤
この段階でも token の並びは解析しないんだけど、階層を持たない token であるなら parse できる筈、という理論の phase🤪
ここで一番問題になったのは Number(token) をやった部分🙄
色々排除してからこの処理になっては居るんだけどそれでも不明の token がここまで残ってる事に気付いて慌てて直した🤪
なので危なそうな語が含まれてないやつだけ Number() する事に🤤
末端を見つけて parse していくだけなのでそんなに複雑な処理構造はしていないのよね、これは🤔

proofread
phase 6 は構成木の並びが正しいかを検査する処理🤤
今まで区切り文字とかが混在していたけれど並び方が正しいなら値(必要によって key 含み)だけを並べた状態に再構築していくわけだけど…🙄
ここの判定が一番ややこしく、手前の phase を作ってる時に「次こそ解析」とか言って phase 分割し続けながら引き伸ばしてきたのよね🤪
可能な限り処理を剥がして簡単になるように加工して、とやってきたけど、ついに解析を組まなければいけないとこまで来たわけで…🤤
DB でもそうなんだけど、どの情報で括りにするか、というのを設計するのには結構な時間と経験が無いと上手く処理できない🙄
今回は作った事が無い物だったのでどの方向から攻めると良いとかそういうの知見が無いので、作ったオブジェクトの配列の順番に処理する事に🤤
他の基準で反復を回す事もできるだろうから JSON.parse なんかは一度じっくり流れを追ってみると良いかも(自分はもうやらないけど🤪(ぉ
この parse では、取り出した要素の種類に応じて「何番目の記述 token なのか」を検査するようになってる🤤
例えば連想配列なら、並びは
key セミコロン 値として妥当な要素 カンマ
で、カンマからは key から繰り返し、最期のデータは VAL で終了等を判定する🙄
JS はカンマだけの省略表記を許すのでその補完を忘れるわけにはいかないんだけどこれが配列と連想配列とで省略できる位置に違いがあるのでそこがとてもややこしい😞
似た処理なので一気に纏めたいところだけどそういう処理の違いがあるおかげで(この parser の構築論では)配列と連想配列は別々になってる🙄
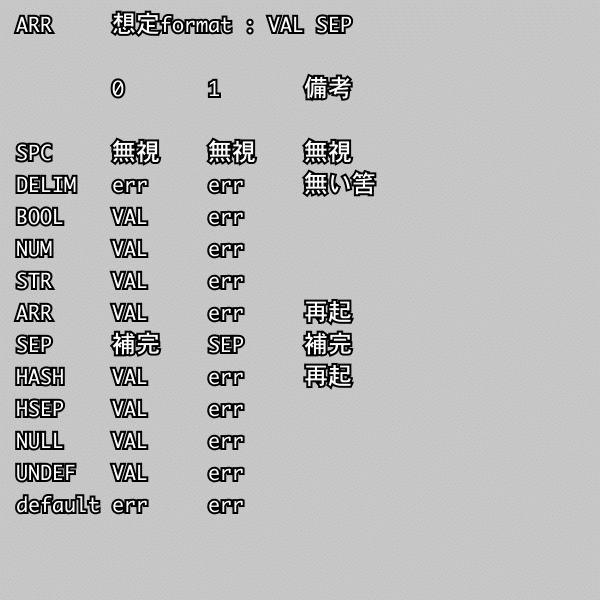
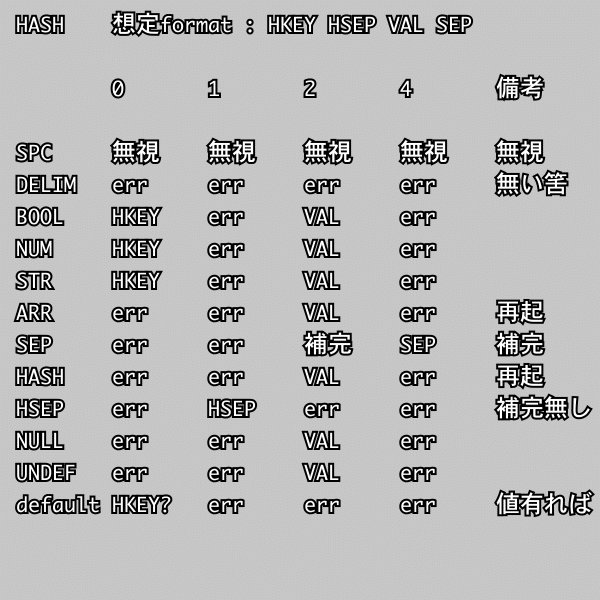
配列中、連想配列中それぞれでなら共通の処理のものは共通化できて「その他」でも纏めて排除する構成になってる🤤
略値が大抵は undefined であるのでこの parser でも undefined を設定するようになってるけど配列へは push だと都合悪そうなので添字を指定して無理やり入れてる🤪

buildValue

phase 7 は、階層構造になってるオブジェクトの配列から値を取り出して連想配列を構築する処理🤤
phase 6 でもう殆ど連想配列に近い状態だけどそれを実際に組み立てる部分。
作った時は phase 6 と処理の構造がまるっきり一緒だったけど phase 6 に手を入れてこの phase では階層構造以外は見ず、値が並んでるだけという前提で処理する様に変更🤪
だって同じ構造なら phase 分ける必要無いし…🙄
勉強の為に処理の系統として phase 分けたので、同じ処理しないようにしたわけ🤤

改造にあたって
現状の開発ではこの状態で完成だけど、一通り終わったらこのスクリプトを更に改造しようかなと考えてるのね?🤤
その時には OTSPElement を使って、初手の phase で parseLeaf 済構成木を組んで、次の phase で proofread しながら buildValue する構成にできそうかなと思ってる🤪
JSON.parse みたいに1走査で変換!とかはできないけど2走査での変換もそれなりに効率が良いモノになってるんじゃないかな?って思うのよね🤔
ただ、OTSPElement でプロパティ名を間接参照にするのは、なんかあんまり良くなかったのかなって感じたので、共用オブジェクト定義では一度決めたらもう変えないくらいの勢いが要るなって思った🤪
次回は
parse した値を使ってパネルの状態を復帰する処理へ復帰よー🤪