ディープラーニングを取り入れたFX自動売買ツール(深層強化学習EA)の開発

この記事では、FX自動売買においてディープラーニング(深層学習)と強化学習を取り入れたEAを作成するためのサンプルコードを掲載しています。
ML-EA(ベースモデル)
以前の記事では、ML-EAという機械学習を取り入れたFX自動売買のベースモデルを作成し解説しました。
このML-EAでは、機械学習モデルとしてLightGBMを採用していました。
LightGBMは、勾配ブースティング決定木 (Gradient Boosting Decision Tree, GBDT) を実装した機械学習ライブラリの一つで、高速で精度が高く、大規模なデータにも対応できるため、多くの機械学習問題で広く用いられています。
このLightGBM(以下、LGBM)も精度が高く有用なのですが、今回はディープラーニング(深層学習)を取り入れてFX取引を行うモデルを作ってみようという試みです。
深層強化学習とは
深層強化学習は、深層学習と強化学習を組み合わせた技術です。深層学習は、データから複雑なパターンや特徴を抽出する能力を持つニューラルネットワークを活用します。強化学習は、環境との相互作用を通じて、試行錯誤に基づいて最適な行動を学習するアルゴリズムです。この2つを組み合わせることで、エージェント(学習するシステム)は、視覚的情報などの複雑な入力から、その状況に最適な行動を決定する方法を自ら学習することができます。この技術は、ゲーム、ロボティクス、自動運転車など、さまざまな領域で応用されています。
より詳しくは、以下の書籍等でご確認ください。以下の書籍のサンプル部分を読むだけでも、ある程度の概要が掴めると思います。
今回はこの中からDQNアルゴリズムを採用して、FX取引に応用してみます。
DQN(Deep Q Network)とは
DQN(Deep Q Network)は、深層学習と強化学習を組み合わせたアルゴリズムの一つで、特にQ学習(Q-Learning)のアプローチを用いています。Q学習では、エージェントは「状態」と「行動」からなるQテーブルを用いて、各状態でどの行動を取るべきかを学習します。
LGBMモデルとDQNモデルは、異なるタイプの機械学習アプローチを採用していますが、それぞれの主な違いは以下の通りです。
LGBM(LightGBM)
タイプ: 勾配ブースティングフレームワークに基づく決定木アルゴリズム。
用途: 分類、回帰、ランキングなどの予測問題。
特徴: 軽量で高速な学習速度、大規模なデータセットでの効率的な処理、低メモリ消費を特徴としています。
アプローチ: 過去データからパターンを学習し、新しいデータポイントの予測を行います。
DQN(Deep Q Network)
タイプ: 深層強化学習アルゴリズム。
用途: エージェントが環境内で最適な行動を学習する問題、特にゲームやシミュレーション環境。
特徴: 深層ニューラルネットワークを使用して、行動の価値を評価するQ関数を近似します。経験再生と固定Qターゲットの技術を使用して学習の安定性を向上させます。
アプローチ: 環境との相互作用からフィードバック(報酬)を受け取り、エージェントがその報酬を最大化する行動方針を学習します。
アプローチの違い
LGBMは、静的なデータに基づいた予測問題に対応し、効率的な分類や回帰を行うためのモデルです。したがって、ML-EAのベースモデルにおいては特徴量に複数の時間足(1分足、5分足、15分足、1時間足)のテクニカル指標を含ませることで、時間経過による変化の情報を織り込ませていました。あくまで各レコードは独立で、テクニカル指標の状態(例えば、1分足のMAと1時間足のMAの大小関係や乖離状況)から得られる結果を学習するイメージです。
DQNは、エージェントが環境からの相互作用を通じて学習し、最適な行動を選択することを目指す強化学習に基づくアプローチです。したがって、1分毎のテクニカル指標という情報を順番にエージェントに提供し、エージェントは3つの行動(買う、売る、何もしない)を選択することができます。それぞれの行動による報酬を関数で与えることにより、エージェントがその報酬を最大化するような行動方針を学習するイメージです。
報酬関数について
DQNにおける報酬関数は、エージェントの行動が目標達成にどの程度貢献したかを数値で表すものです。エージェントは、この報酬を最大化するような行動選択を学習します。FX取引においては、取引の利益を最大化するような行動(買う、売る、何もしない)をエージェントが学習することが目標になります。
この報酬関数は、実現損益だけでなく、未実現損益や機会損失を考慮して設計する方法も考えられますが、今回のモデルではシンプルに実現損益だけで以下のように報酬関数を設計してみます。
実現損益(Profit)
Buy: ある時点で「Buy」を選択した場合、その時点の価格と4時間後の価格の差額が損益となります。4時間後の価格の方が大きければプラスの報酬となり、小さければマイナスの報酬となります。
Sell: ある時点で「Sell」を選択した場合、その時点の価格と4時間後の価格の差額が損益となります。4時間後の価格の方が大きければマイナスの報酬となり、小さければプラスの報酬となります。
Hold: ある時点で「Hold」を選択した場合、買いも売りも行いませんので損益は発生しません。つまり、報酬もゼロとなります。
損益パフォーマンス比較
バックテスト用ツールを今回のモデルに合わせて作成し、モデルの違いが損益パフォーマンスに与える影響を検証してみます。
まずは、以下の記事におけるStep1〜Step4までを反映させたML-EAをLGBMモデルとします。
そしてその状態から、モデルのみをDQNに変更したものをDQNモデルとします。
バックテスト方法について詳しくは、以下の記事も参考にしてください。
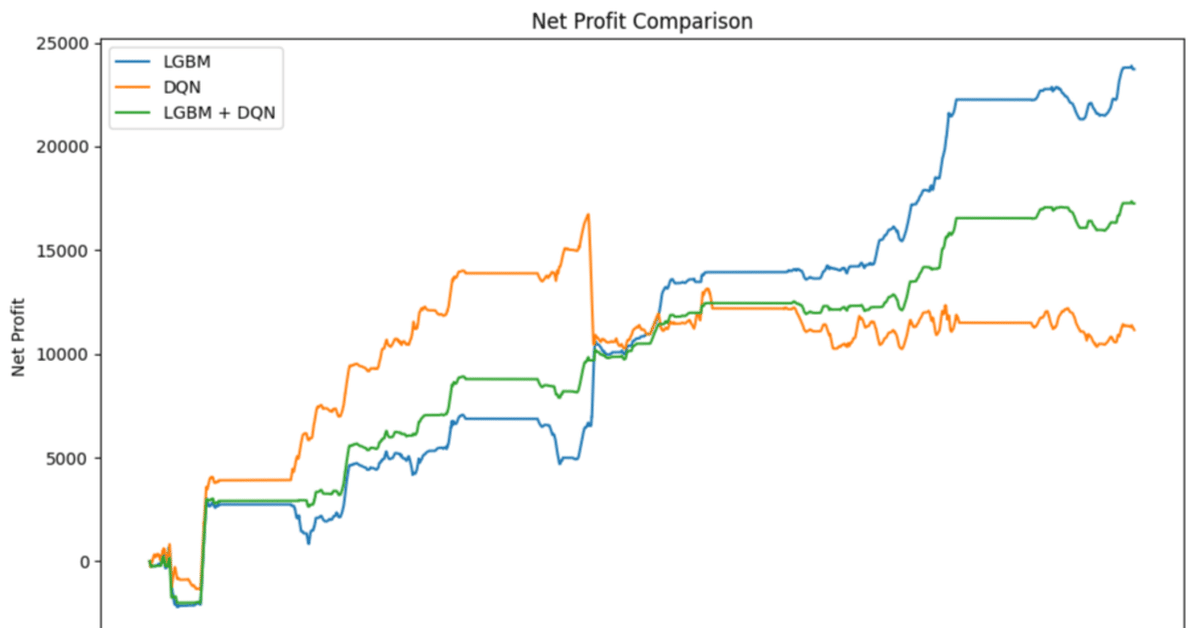
それぞれのバックテスト結果(取引対象はGOLDで、2024年2月の1ヶ月分)は以下の通りです。
LGBMモデル(2024年2月)
Win Rate: 60.78%
Entry Rate: 69.66%
Total Net Profit: 23721.03

DQNモデル(2024年2月)
Win Rate: 54.72%
Entry Rate: 87.13%
Total Net Profit: 11149.16

LGBM vs DQN
単純に結果だけ見ると、累計損益(Total Net Profit)と勝率(Win Rate)のいずれもLGBMの方が良好なパフォーマンスです。一方で、エントリー率(Entry Rate)は DQNの方が高いので、勝率が低くなければ損益パフォーマンスにプラスに働く可能性はあります。
ただし、ここで注目すべきポイントがもう一つあります。グラフの形状をよく確認してみましょう。これは2024年2月の1ヶ月間のバックテストであり、全体的にはLGBMの方が損益が大きいですが、月前半だけで見てみると、DQNの方が損益が大きいことに気付きます。
以下のように、グラフを重ねてみるとよくわかります。

LGBM + DQN
そこで、LGBMとDQNを組み合わせてみます。組み合わせ方は以下の単純な方法を採用します。
LGBMとDQNのどちらもbuyと予測している場合のみ、buyを選択
LGBMとDQNのどちらもsellと予測している場合のみ、sellを選択
この「LGBM + DQN」モデルによるバックテスト結果は以下の通りです。
Win Rate: 62.85%
Entry Rate: 45.50%
Total Net Profit: 17248.03

Entry Rateは下がりましたが、Win Rateが上がりました。グラフを確認すると、視覚的にも損益の発生が安定的になったことがわかるはずです。
2つのアプローチの異なるモデルが、どちらも同じ方向を予測した場合のみにエントリーするという方法が、リスクを減少させる可能性があるということを示唆するような結果を得ることができました。
バックテスト結果の再現性について
DQN (Deep Q Network) モデルによる予測結果は、同じインプットデータであっても試行を繰り返すと異なる結果が出ることがあります。これは深層学習の分野では一般的な現象ですが、詳しい解説は別記事にします。
ここでは同じロジック・同じインプットデータでバックテストを複数回行った結果を簡単にご紹介します。
これまでに見てきているモデルを'LGBM'と'DQN1'とし、その後DQNモデルについては同じ前提で7回バックテストを繰り返し、'DQN2~8'としました。その結果比較は以下の通りです。
バックテスト結果比較(主要数値)

バックテスト結果比較(損益グラフ)

バックテスト結果比較分析
結果を簡単に分析してみます。
DQNモデルに関しては、Win RateやEntry Rateはそれほど変わらない。グラフを見渡してみても、試行のたびに大きく行動パターンが全く異なってしまうわけでもなさそう。
損益結果が大きく変わってくるのは、損益変動(価格変動)が大きくなるタイミングでどの行動(hold,buy,sell)を選択するかという数箇所の予測結果のブレによる影響が大きそう。
相変わらず、最終損益(Total Net Profit)がLGBMを上回るモデルはなかったが、月前半だけで見てみると、LGBMを上回っているモデルは多い。つまり、タイミングによってはDQNモデルの方が予測精度が優れている可能性はある。
なお、バックテストについては別記事でより詳しく解説する予定です。
DQNモデルの実装方法
以下は、DQNモデルを用いた学習と予測を実装するためのコードです。
主要な構成要素とその働きに関する簡単な解説を加えながらご紹介します。
追加ライブラリのインストール
今回は、ML-EA(ベースモデル)で使用したライブラリに加えて、PyTorchというライブラリを使用します。以下のようにインストールしておきます。
pip install torch torchvision torchaudioインストール方法の詳細は以下の記事を参照してください。
TradingDatasetクラス
ここでは、機械学習モデルのトレーニングやテストに使用されるデータセットを設定しています。
class TradingDataset(Dataset):
def __init__(self, features, rewards):
self.features = features
self.rewards = rewards
def __len__(self):
return len(self.features)
def __getitem__(self, idx):
return self.features[idx], self.rewards[idx]具体的には、features(特徴量)とrewards(各行動に対する報酬)を設定しています。
DQNクラス
ここでは、ニューラルネットワークを用いて、取引における各行動('hold', 'buy', 'sell')の価値(Q値)を推定するDeep Q Networkモデルを定義しています。
class DQN(nn.Module):
def __init__(self, input_dim):
super(DQN, self).__init__()
self.network = nn.Sequential(
nn.Linear(input_dim, 128),
nn.ReLU(),
nn.Linear(128, 256),
nn.ReLU(),
nn.Linear(256, 3) # 'hold', 'buy', 'sell'の3行動
)
def forward(self, x):
return self.network(x)入力(input_dim)は特徴量(各種テクニカル指標)を想定していて、出力は各行動に対する推定Q値です。
TradingEnvironmentクラス
ここでは、FX取引の環境をシミュレートしています。これには、現在の市場の状態(テクニカル指標)を取得した上でエージェントが選択した行動に基づいて報酬を計算する機能が含まれます。
class TradingEnvironment:
def __init__(self, data):
self.data = data
self.current_step = 0
def get_state(self):
state = [self.data.loc[self.current_step, feature] for feature in feature_names]
return np.array(state)
def calculate_realized_profit(self, action):
if action == 1: # buy
return self.data.loc[self.current_step, 'FutureClose'] - self.data.loc[self.current_step, 'Close'] - self.data.loc[self.current_step, 'Spread']
elif action == 2: # sell
return self.data.loc[self.current_step, 'Close'] - self.data.loc[self.current_step, 'FutureClose'] - self.data.loc[self.current_step, 'Spread']
else: # hold
return 0
def step(self, action):
reward = self.calculate_realized_profit(action)
self.current_step += 1
if self.current_step >= len(self.data):
self.current_step = 0
next_state = self.get_state()
return next_state, reward「calculate_realized_profit」関数を定義して、実現損益を計算しています。例えば'action'として'buy'を選択した場合は、4時間後の終値('FutureClose')と現在の終値('Close')との差額に、スプレッド('Spread')を考慮した値が実現損益で、これを報酬('reward')としています。
より複雑なDQNモデルの設計
以下の記事では、より複雑なDQNモデルの実装方法を検討しています。是非あわせてご覧下さい。
有料部分の内容
以上、DQNという深層強化学習アルゴリズムを採用してML-EAの機能拡張を行う処理の流れを具体的に説明してきました。
有料部分ではDQNモデルによる一連の処理を実行するための以下のファイル一式をダウンロード可能にしています。
自動売買用ツール
実際に取引を行うためのファイルセットは以下の通りです。
DQN-EA.ex5(MT5用のEA)
DQN-train.bat(バッチファイル)
DQN-predict.bat(バッチファイル)
DQN-train.py(DQNモデルの訓練を行うためのPythonスクリプト)
DQN-predict.py(DQNによる予測を行うためのPythonスクリプト)
バックテスト用ツール
バックテストを行うためのファイルセットは以下の通りです。
DQN-EA_backtest.ex5(MT5用のEA)
DQN-delete_files.bat(バッチファイル)
DQN-backtest.bat(バッチファイル)
DQN-profit_summary.bat(バッチファイル)
DQN-delete_files.py(ファイルを削除するためのPythonスクリプト)
DQN-backtest.py(バックテストを行うためのPythonスクリプト)
DQN-profit_summary.py(損益を集計するためのPythonスクリプト)
本記事のファイルだけで DQNモデルに関しては一通りの実行(実際の取引とバックテスト)が可能ですが、MQL5のソースコード(mq5ファイル)およびLGBMモデルの内容は含まれていません。それらの内容に関しては、以下の記事を参考にしてください。
自動売買用ツール
LGBM用のmq5ファイルのソースコードについて詳しく解説しています。基本的な構造は同じですのであわせてご覧ください。
バックテスト用ツール
LGBM用のmq5ファイルのソースコードについて詳しく解説しています。基本的な構造は同じですのであわせてご覧ください。
注意点
当記事で掲載しているコードはPythonの環境設定含め、必要な準備が整っている上での実行を想定しています。環境設定に問題がある場合はご自身で解決していただかないと実際のプログラム実行まで辿り着けない可能性があります。
記事執筆時点で稼働確認を行なっており、エラーが出ないことを確認しておりますが、その後の環境変化等で想定通りに稼働しない可能性はございます。動作保証等はいたしかねますのでご了承ください。
リアル口座にアクセスして取引を行うことも可能なコードになっておりますが、必ずデモ口座で事前に稼働確認をしていただくことを推奨いたします。
当記事で解説しているロジック通りの動作を保証するものではございません。特にDQNモデルによる予測結果は、同じインプットデータであっても試行を繰り返すと異なる結果が出ることがありますので、当記事のバックテスト結果を完全に再現できるとは限りません。
DQNモデル専用のロジックになっており、LGBMモデルの機能は搭載されておりません。また、MT5部分に関しては実行用EA(ex5ファイル)のみであり、ソースコード(mql5ファイル)は含まれておりません。
VPS(実行環境)のスペックについて
DQNを含むディープラーニングモデルの運用には、高度な計算能力と大量のメモリが必要です。特にモデルの訓練時には、多数のパラメータを同時に更新し、大量のデータをメモリ上に保持する必要があります。このため、標準的な仮想プライベートサーバー(VPS)ではメモリ不足に陥る恐れがあります。
上記の記事で紹介している最低限のVPSでも稼働可能なことは確認していますが、LGBMと比較するとモデルの訓練にはかなり時間がかかります。また、同時に他のMT4/MT5を稼働させている場合などは操作の途中でメモリ不足になる頻度が高いことも確認しています。必要に応じて、よりハイスペックなVPSの導入を検討することを推奨します。
ここから先は
¥ 5,000
Amazonギフトカード5,000円分が当たる
よろしければ応援お願いします。いただいたチップは今後の記事の執筆に活用させていただきます。