Pandas csvデータ出入力とアクセス

pythonを使っていると、任意のarrayを打ち込むよりも、持っているデータを解析したい場合が多々あると思います。
特に、csvデータの入出力はよくすると思います。
おなじみ、irisデータをPandasで読み込み、データにアクセスしましょう。
irisをPandasで抽出
入力は、pd.read_csv()で簡単にできます。
()の中に、csvが置いてある住所とcsvの名前をかけばOK。
import numpy as np
import pandas as pd
df1 = pd.read_csv("./iris.csv") #Jupiternotebookと同じファイルなら./ でok
df1.head() #先頭の5行だけをみる実行結果:

こんな感じの先頭5行となります。
任意の列にアクセス
sepal_lengthにアクセスしたい時は以下でアクセス可能。
df1["sepal_length"]実行結果:
0 5.1
1 4.9
2 4.7
3 4.6
4 5.0
5 5.4となります。簡単ですね。
任意の列の平均をみる
sepal_lengthの平均を知りたい時は以下でアクセス可能。
df1["sepal_length"].mean()実行結果:
5.843333333333335となります。
任意の条件の行を抽出する
sepal_lengthの平均は分かりました。7以上の行がどんなものか見たい場合、以下のコードでアクセスできます。
df1[df1["sepal_length"]>7]実行結果:
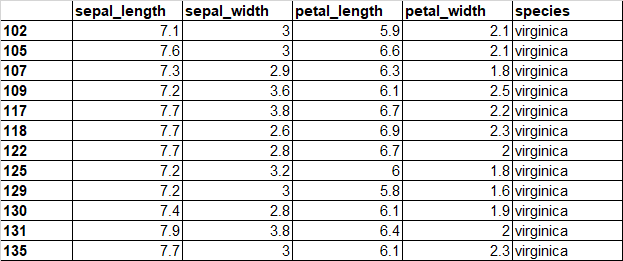
ほほ~~
これで、分かります。
任意の条件のみのDataFrameを作る
例えば、speciesは3種類の要素がありますが、virginicaのみの情報をとってきたいとします。
その場合は以下のように、列名で条件を絞るとok
df2= df1[df1["species"]=="setosa"]
df2.head実行結果:

となります。
DataFrameをcsv保存したい
今回のデータをcsv に保存する場合、簡単にできます。
.to_csv()の関数を使います。
.to_csv()の前に意中のDataFrame変数を置きます。先ほどの”setosa”のみのDataFrameで使ったdf2の場合、df2.to_csv()とします。
また、()の中に、保存したい住所・csvの名前を書けばOK。
df2.to_csv("./iris_df2.csv")任意のフォルダにcsvファイルが保存されました。
さて、このままだと、インデックスが付いたままの保存になります。要するに、列の一番左にセルができてしまいます。
インデックス無しでcsv 保存したい
その場合は、引数に index = Falseを加えるだけです。
df2.to_csv("./iris_df2.csv", index=False)これで、インデックスなしで保存が可能です。
この記事が気に入ったらサポートをしてみませんか?