Pandas 行列ごとの処理 for

PythonでPandasを使う人の多くは、自分のExcelやcsvデータに対し、何等かの処理をしたい場合が多い。
単発の処理だとExcel内でやってしまえばよいので、Pythonで仕立てるメリットは少ない。やはり、繰り返しができるからこそPythonでする意味、メリットが大きくなる。
ということで、今回はfor を使って、とにかく1回の処理ではなく、繰り返してみることにしましょう。
irisデータを使い、列名をforでみてみる
ご存知、irisデータを入力します。df1という変数の中に入れ、そのままforループを回してみます。
import pandas as pd
df1 = pd.read_csv("./iris.csv")
for i in df1:
print(i)実行結果:
sepal_length
sepal_width
petal_length
petal_width
speciesループで回すと、列名が内容が確認できました。
列の平均を計算
任意の列の平均をみたいとします。
平均は、.mean()で計算が可能です。irisの列名の一つ、sepal_lengthを確認したい場合は以下でできます。
mean_df1 = df1["sepal_length"].mean()
print(mean_df1)実行結果:
5.843333333333335わーい!できました。
さて、
ここでfor を使った問題
irisを構成する列名をもう一度確認してみましょう。
sepal_length
sepal_width
petal_length
petal_width
speciesこの列名、最後のspeciesは品目名なので、テキスト型で入っています。要するに平均として計算することはできません。
そのため、df1.columnsで考えた時に、df1.columns[0:4]となります。
for の構文を考えながら、どんな風に作れば良いか、考えてみてください。
では、
正解
for i in df1.columns[0:4]:
print(df1[i].mean())実行結果:
5.843333333333335
3.0540000000000007
3.7586666666666693
1.19866666666666721列ずつの平均ができました。
列のいろんなことをfor でみてしまほ~(for)
平均の他にも、最小値、最大値、標準偏差・・も列ごとに確認することが可能です。
for i in df1.columns[0:4]:
print(i)
print(df1[i].mean())
print(df1[i].max())
print(df1[i].min())
print(df1[i].std())実行結果:
sepal_length
5.843333333333335
7.9
4.3
0.8280661279778629
sepal_width
3.0540000000000007
4.4
2.0
0.4335943113621737
petal_length
3.7586666666666693
6.9
1.0
1.7644204199522617
petal_width
1.1986666666666672
2.5
0.1
0.76316074170084141度、綺麗にループが回れば、あとは関数を足すだけなので簡単ですね。
for でなくてもデータの全貌が分かる
.describle()という関数を使うと、結構なことが瞬時にわかってしまいます。
irisのデータを使った場合、speciesの列はテキスト型が入っているため省いておきます。
df2 = df1[["sepal_length","sepal_width","petal_length","petal_width"]]
df2.head()実行結果:
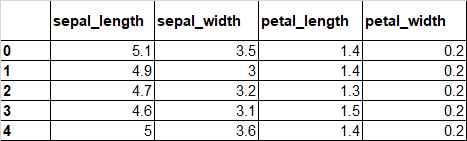
となり、df2の中には計算できる列のみが入りました。
では、さっそく.describe()。
print(df2.describe())実行結果:
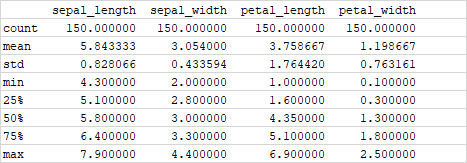
列の要素を計算した値を出してくれます。
簡単ですね・・
この記事が気に入ったらサポートをしてみませんか?