
FFTにより音声フィンガープリント(声紋)認識

1.背景
音楽認識技術の発展により、ユーザーは聴いている曲をすばやく識別し、見つけることが可能となった。この技術は、特定の曲や音楽を検索するための最も便利な方法を提供し、音楽鑑賞の体験を大幅に向上させられる。特に、効率的な識別アルゴリズムと豊富なサウンドフィンガープリントデータベースの組み合わせにより、ユーザーはわずかな秒数で曲を特定することができるようになった。
近年、ショートビデオプラットフォームの台頭により、バックグラウンドミュージック(BGM)の識別がますます重要になっている。特に、TikTok、Youtubeなどのプラットフォームでは、多くのユーザーがBGMを使用して動画を作成しており、その音楽の識別はコンテンツの発見と共有において重要な役割を果たしている。
2.要旨
PythonツールとAmazonクラウドデータベースRDSサービスを使用して、音声の認識を実現する。このシステムは、音声ファイル(wav)を読み込み、FFT(高速フーリエ変換)を用いて音声フィンガープリントを抽出し、それをデータベースに登録することで、ユーザーが特定の曲を簡単に検索できるように設計されている。音声認識技術とクラウドデータベースの組み合わせにより、大規模な音楽データベースの管理と効率的な検索を可能にし、ユーザー体験を向上させることが目指されている。
2.1 技術スタック
プログラミング言語
Python: 高水準のプログラミング言語であり、データ処理、解析、そして機械学習の分野で広く使用されている。
ライブラリとモジュール
os: ファイルやディレクトリの操作を行うための標準ライブラリ。
re: 正規表現のサポートを提供する標準ライブラリ。
wave: 拡張子WAV音声ファイルを操作するための標準ライブラリ。
numpy: 数値計算を効率的に行うためのライブラリ。FFTなどの数値解析にも使用される。
matplotlib: データの可視化を行うためのライブラリ。音声データの波形をプロットするために使用。
pyaudio: 音声の録音・再生を行うためのライブラリ。音声ファイルの再生機能を提供。
pymysql: MySQLデータベースに接続するためのライブラリ。データベース操作を行うために使用。
データベース
AWS RDS(Amazon Relational Database Service): クラウド上でのリレーショナルデータベースサーの永続化と管理に使用される。
3.原理
3.1 FFT(高速フーリエ変換)
高速フーリエ変換(fast Fourier transform, FFT)は、離散フーリエ変換(discrete Fourier transform, DFT)を計算機上で高速に計算するアルゴリズムである。高速フーリエ変換の逆変換を逆高速フーリエ変換(inverse fast Fourier transform, IFFT)と呼ぶ。
高速フーリエ変換 (FFT) は、シーケンスの離散フーリエ変換 (DFT) またはその逆変換を迅速に計算する方法である 。フーリエ解析は、任意の信号を異なる周波数成分の和として表現でき、時間領域の信号を周波数領域に変換することで、信号の周波数成分を解析できる。これにより、信号の特性を詳細に理解することが可能となる。
時間領域: 信号が時間の関数として表現される領域。
周波数領域: 信号が異なる周波数成分の和として表現される領域。
例えば、周波数1 (A4音、440 Hz(freq1))及び周波数2 (A5音、880 Hz(freq2))で合成された信号をサンプリング周波数を8000 Hzに設定し、1秒間の時間軸を生成する。
fs = 8000 # サンプリング周波数
t = np.arange(0, 1.0, 1.0/fs) # 時間軸
freq1 = 440 # 周波数1 (A4音、440 Hz)
freq2 = 880 # 周波数2 (A5音、880 Hz)
# 2つの正弦波を合成してサンプル音声を生成
signal = 0.5 * np.sin(2 * np.pi * freq1 * t) + 0.5 * np.sin(2 * np.pi * freq2 * t)
# FFTを実行して周波数領域に変換
N = len(signal)
frequencies = np.fft.fftfreq(N, 1/fs)
fft_values = np.fft.fft(signal)
fft_magnitude = np.abs(fft_values)
# 周波数領域のグラフをプロット
plt.plot(frequencies[:N//2], fft_magnitude[:N//2]) # プロット範囲は0~fs/2に制限
合成された信号の440 Hz及び880 Hzの所にピークが現れた。このように、FFT は、DFT に比べて計算量が大幅に削減されるため、大規模なデータに対しても高速に処理できる。今回において、音声データをブロックに分割し、各ブロックに対してFFTを使用することで音声信号のフィンガープリントを迅速かつ正確に抽出し、周波数領域での高エネルギーポイントを抽出する。これにより、音声フィンガープリントデータを数値データとして表現でき、音声認識システムの性能を向上させることができた。
3.2 音声フィンガプリント(声紋)
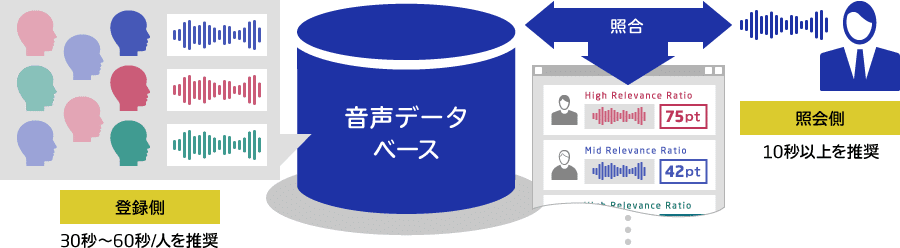
音声フィンガープリントは、音声信号の特徴やパターンを抽出し、その情報をコンパクトな形式で表現し、これにより、異なる音声データ間の類似性や一致度を効率的に検出することが可能となる。
音声が人間である場合、個々の人の声は指紋のように固有の特徴を持つ。この特徴は、音声の周波数スペクトル、発声パターン、声帯振動などによって決まる。声紋認証は、これらの個々の特徴を分析して、特定の個人を識別するための手法である。
具体的には、声紋認証システムは、個々の人の声から特徴的なパラメータを抽出し、これには、声の高さや低さ、発音の速さやリズム、声の波形やスペクトルなどが含まれる。これらのパラメータは、声紋として知られる個人の声の固有の表現を形成する。データベースに登録された声紋と新しい音声データとを比較し、その一致度を評価することで、登録された声紋との一致度が高いほど、その音声データが特定の個人に関連付けられる可能性が高くなる。
4.方法
4.1 環境構築
OSに応じて、pyaudioをインストール。
macOS の場合
brew install portaudio
pip install pyaudioLinux の場合
sudo apt-get install portaudio19-dev python3-pyaudio
pip install pyaudioColab の場合
Google Colab は Debian ベースの環境なので、apt-get を使用して必要な依存関係をインストールできる。
!apt-get install -y portaudio19-dev
!pip install pyaudio4.2 データベース作成
データベース「singdb」作成してから、「fingerprint」というテーブルを作成に、三つのフィールドが含まれている。
CREATE TABLE `singdb`.`fingerprint` (
`id` INT(11) UNSIGNED NOT NULL AUTO_INCREMENT,
`song_name` VARCHAR(200) NULL,
`high_points` LONGTEXT NULL,
PRIMARY KEY (`id`)
) ENGINE = InnoDB
DEFAULT CHARACTER SET = utf8mb4
COLLATE = utf8mb4_general_ci;4.3 音声ファイルを処理するためのクラス
Voice クラス
属性
nchannels: チャンネル数(モノラルなら1、ステレオなら2)。
sampwidth: サンプル幅(バイト数)。
framerate: サンプリングレート(1秒あたりのサンプル数)。
nframes: 総フレーム数。
wave_data: 音声データ。
name: 音声ファイルの名前。
high_point: 各ブロックの高エネルギーポイント。
メソッド
__init__: クラスの初期化。
load_data: WAVファイルを読み込み、音声データを取得する。
plot_waveform: 音声データの波形をプロットする。
fft: FFTを行い、各ブロックの高エネルギーポイントを抽出する。
play: 音声ファイルを再生する。
import os
import re
import wave
import numpy as np
import matplotlib.pyplot as plt
import pyaudio
class Voice:
def __init__(self):
self.nchannels = None
self.sampwidth = None
self.framerate = None
self.nframes = None
self.wave_data = None
self.name = None
self.high_point = None
def load_data(self, filepath):
"""
Load data from a .wav file and store it in the object.
Parameters:
filepath (str): The path to the .wav file.
Returns:
bool: True if the data is loaded successfully, otherwise raises an exception.
Exceptions:
TypeError: If filepath is not a string.
IOError: If the file path does not end with .wav, the file does not exist, or there is an error reading the file.
"""
print(f"Loading data from: {filepath}")
if not isinstance(filepath, str):
raise TypeError("Filepath must be a string")
p1 = re.compile(r'\.wav$')
if not p1.search(filepath):
raise IOError("Filepath must end with .wav")
if not os.path.exists(filepath):
raise IOError("File does not exist")
try:
f = wave.open(filepath, 'rb')
params = f.getparams()
self.nchannels, self.sampwidth, self.framerate, self.nframes = params[:4]
print(f"Audio parameters: nchannels={self.nchannels}, sampwidth={self.sampwidth}, framerate={self.framerate}, nframes={self.nframes}")
str_data = f.readframes(self.nframes)
self.wave_data = np.frombuffer(str_data, dtype=np.short)
self.wave_data.shape = -1, self.sampwidth
self.wave_data = self.wave_data.T
f.close()
self.name = os.path.basename(filepath)
print(f"Successfully loaded: {self.name}")
return True
except Exception as e:
print(f"Error loading wave file: {e}")
raise IOError("Error loading wave file")
def plot_waveform(self):
"""
Plot the waveform of the loaded audio data.
Returns:
None
Debug Info:
Prints a message indicating the plotting of waveform.
"""
if self.wave_data is None:
print("No audio data loaded")
return
print("Plotting waveform...")
time = np.arange(0, self.nframes) * (1.0 / self.framerate)
plt.figure(figsize=(10, 4))
plt.plot(time, self.wave_data[0])
plt.xlabel("Time [s]")
plt.ylabel("Amplitude")
plt.title(f"Waveform of {self.name}")
plt.grid()
plt.show()
print("Waveform plotted.")
def fft(self, frames=40):
"""
Perform Fast Fourier Transform (FFT) on audio data, dividing the audio into blocks and extracting high-energy points in sub-bands.
Parameters:
frames (int): The number of frames per block.
Returns:
None
Debug Info:
Prints block size, number of blocks, and high points for each block.
"""
print("Performing FFT...")
block = []
fft_blocks = []
self.high_point = []
block_size = self.framerate // frames # block_size is the number of frames per block
blocks_num = self.nframes // block_size # Number of blocks in the audio
print(f"Block size: {block_size}, Number of blocks: {blocks_num}")
for i in range(0, len(self.wave_data[0]) - block_size, block_size):
block_data = self.wave_data[0][i:i + block_size]
fft_data = np.abs(np.fft.fft(block_data))
block.append(block_data)
fft_blocks.append(fft_data)
high_points = (np.argmax(fft_data[:40]),
np.argmax(fft_data[40:80]) + 40,
np.argmax(fft_data[80:120]) + 80,
np.argmax(fft_data[120:180]) + 120,
# np.argmax(fft_blocks[-1][180:300]) + 180,
)
self.high_point.append(high_points)
print(f"Block {i // block_size + 1}: High points: {high_points}")
print("FFT completed.")
def play(self, filepath):
"""
Play the audio file.
Parameters:
filepath (str): The path to the .wav file to be played.
Returns:
None
Debug Info:
Prints a message indicating the start and end of audio playback.
"""
print(f"Playing audio: {filepath}")
chunk = 1024
wf = wave.open(filepath, 'rb')
p = pyaudio.PyAudio()
# Check if there are any available output devices
if p.get_device_count() == 0:
print("No audio output devices available")
return
try:
stream = p.open(format=p.get_format_from_width(wf.getsampwidth()),
channels=wf.getnchannels(),
rate=wf.getframerate(),
output=True)
except OSError as e:
print(f"Error opening audio stream: {e}")
return
while True:
data = wf.readframes(chunk)
if not data:
break
stream.write(data)
stream.close()
p.terminate()
print("Playback completed.")テスト:
if __name__ == "__main__":
voice = Voice()
if voice.load_data('/content/ariana grande-one last time.wav'):
voice.plot_waveform()
voice.fft()
# voice.play('/content/sam smith&normani-dancing with a stranger.wav')音声ファイルのパラメータおよび波形図が現れた。

4.4 RDS接続するためのクラス
AWS RDSに必要ら引数として、「RDS endpoint」、「RDS username」、「RDS password」、「 MySQL port」は以下にまとめた。
import pymysql
class RDSClient:
def __init__(self, host, user, password, database, port=3306):
"""
Initialize the RDS client with the given connection parameters.
Parameters:
host (str): RDS endpoint.
user (str): RDS username.
password (str): RDS password.
database (str): Database name.
port (int): MySQL port, default is 3306.
"""
self.host = host
self.user = user
self.password = password
self.database = database
self.port = port
self.connection = None
def connect(self):
"""
Establish a connection to the RDS database.
Returns:
bool: True if connection is successful, False otherwise.
"""
try:
self.connection = pymysql.connect(
host=self.host,
user=self.user,
password=self.password,
database=self.database,
port=self.port
)
print("Connection to RDS successful")
return True
except pymysql.MySQLError as e:
print(f"Error connecting to RDS: {e}")
return False
def query(self, sql, params=None):
"""
Execute a query on the RDS database.
Parameters:
sql (str): The SQL query to execute.
Returns:
list: Query results as a list of tuples, or None if an error occurs.
"""
if self.connection is None:
print("Connection is not established")
return None
try:
with self.connection.cursor() as cursor:
# cursor.execute(sql)
cursor.execute(sql, params)
result = cursor.fetchall()
return result
except pymysql.MySQLError as e:
print(f"Error querying database: {e}")
return None
def close(self):
"""
Close the RDS database connection.
"""
if self.connection is not None:
try:
self.connection.close()
print("Connection closed successfully")
except pymysql.MySQLError as e:
print(f"Error closing connection: {e}")4.5 音声フィンガープリントを保存、比較、検証するためのクラス
Memory クラス
属性
rds_client: データベース接続用のオブジェクト。
メソッド
__init__: データベース接続に失敗した場合、メッセージを表示して終了する。
close_connection: データベースの接続を閉じる。
add_song: 音声フィンガープリントデータをデータベースに追加する。
fp_compare: 2つのフィンガープリントを比較し、最大の類似性を見つける。
search: データベース内の全フィンガープリントと比較し、類似度の高い順に結果を返す。
class Memory:
def __init__(self, rds_client):
self.rds_client = rds_client
# Connect to the database
if not self.rds_client.connect():
print('Database connection failed')
return None
def close_connection(self):
"""
Close the database connection.
"""
self.rds_client.close()
def add_song(self, path):
"""
Add a song to the database if it doesn't already exist.
Parameters:
path (str): The path to the audio file.
rds_client (RDSClient): The RDSClient instance for database operations.
Raises:
TypeError: If the path is not a string.
"""
if not isinstance(path, str):
raise TypeError("The path must be a string")
basename = os.path.basename(path)
try:
# Query the database to check if the song already exists
sql = f"SELECT * FROM fingerprint WHERE song_name = '{basename}'"
rows = self.rds_client.query(sql)
if rows is None:
return None
namecount = len(rows)
if namecount > 0:
print('The song has already been recorded!')
return None
# Process the audio file
v = Voice()
v.load_data(path)
v.fft()
# Insert the song into the database
# insert_sql = f"INSERT INTO fingerprint VALUES ({basename}, {str(v.high_point)})"
insert_sql = "INSERT INTO fingerprint (song_name, high_points) VALUES (%s, %s)"
self.rds_client.query(insert_sql, (basename, str(v.high_point)))
self.rds_client.connection.commit()
print(f"Added to database: {basename} ")
except pymysql.MySQLError as e:
print(f"Database error: {e}")
except Exception as e:
print(f"Error: {e}")
def fp_compare(self, search_fp, match_fp):
"""
Compare two fingerprints and find the maximum similarity.
Parameters:
search_fp (list): The query fingerprint.
match_fp (list): The fingerprint from the database.
Returns:
int: Maximum similarity value.
"""
if len(search_fp) > len(match_fp):
return 0
max_similar = 0
search_fp_len = len(search_fp)
match_fp_len = len(match_fp)
for i in range(match_fp_len - search_fp_len + 1):
temp = 0
for j in range(search_fp_len):
if match_fp[i + j] == search_fp[j]:
temp += 1
if temp > max_similar:
max_similar = temp
return max_similar
def search(self, path):
"""
Search for similar songs in the database.
Parameters:
path (str): The path to the audio file to be searched.
Returns:
list: A list of tuples (song_name, similarity), sorted by similarity in descending order.
"""
if not isinstance(path, str):
raise TypeError("The path must be a string")
# Load the query audio file and compute its fingerprint
v = Voice()
v.load_data(path)
v.fft()
search_fp = v.high_point
results = []
try:
# Query the database to get all fingerprints
sql = "SELECT song_name, high_points FROM fingerprint"
rows = self.rds_client.query(sql)
if rows is None:
return results
# Compare each fingerprint with the query fingerprint
for row in rows:
song_name, match_fp = row
match_fp = eval(match_fp) # Convert string back to list
similarity = self.fp_compare(search_fp, match_fp)
results.append((song_name, similarity))
# Sort the results by similarity in descending order
results.sort(key=lambda x: x[1], reverse=True)
except pymysql.MySQLError as e:
print(f"Database error: {e}")
except Exception as e:
print(f"Error: {e}")
finally:
self.rds_client.close()
return results5.結果
5.1 音声フィンガープリントデータ保存
全てのwavファイルを読み込み、デバッグメッセージが表示された。
if __name__ == "__main__":
from glob import glob
rds_client = RDSClient(
host='RDS endpoint,
user='Admin',
password='RDS PASSWORD',
database='singdb'
)
if not rds_client.connect():
print('Failed to connect to the database')
exit()
memory = Memory(rds_client)
music_files = glob('/content/*.wav')
for file_path in music_files:
memory.add_song(file_path)
rds_client.close()出力:

5.2 フィンガープリントの比較
if __name__ == "__main__":
rds_client = RDSClient(
host='RDS Public IP',
user='root',
password='RDS PASSWORD',
database='singdb'
)
memory = Memory(rds_client)
print('\n', memory.search('/content/ariana grande-one last time.wav')[0][0])出力:

ユーザーが任意の曲を検索したいとき、この曲をフィンガープリント抽出、比較することで、データベース内に一致した曲名を返し、「ariana grande-one last time」という曲名を正しく識別できた。
6.展望
性能の最適化
現在の実装では、単純な線形検索と類似度計算を行っている。データベースが大規模になるにつれて、検索時間が増加する可能性がある。インデックスの使用や、より高度な類似度計算法の導入を検討することができる。
拡張性の向上
現在のシステムは単一のデータベースインスタンスに依存している。将来的には、データベースのシャーディングやリプリケーションを導入することで、システムの可用性と拡張性を向上させることができる。
ユーザーインターフェースの改善
現在のシステムは、コマンドラインベースで操作されている。ユーザーフレンドリーなウェブインターフェースやモバイルアプリケーションを開発することで、より多くのユーザーがシステムを利用しやすくすることができる。
音声認識精度の向上
現在のフィンガープリント抽出方法に加えて、機械学習やディープラーニングを活用した音声認識技術を導入することで、認識精度を向上させることができる。