
OpenAI*Fast API*Renderで社内業務を効率化しようとした話

はじめに
はじめまして。ウイングアークでプリセールスを担当している田代です。普段は当社のサービスをお客様に提案する際の、技術面の要件整理やサポートを行っています。
今回は、いつもの業務からちょっとだけ離れて、よくある(と思われる)社内オペレーションの課題に対して技術を使った解決策を模索した経験についてお話ししたいと思います。
社内課題
たいていの会社の社内オペレーションに「見積作成」業務があると思います。ここでは、顧客に提示する見積は、営業からアシスタントチームにまず依頼があり、アシスタントチームが見積を作成して営業に戻すというフローになっているとします。
見積作成においては、商品マスタから正確な型番を引き、単価と条件を抽出することが求められます。一連の見積作成が完了したら、それをシステム登録し、あとは営業がダウンロードを行ないます。
ここで、営業からの依頼内容から正確な型番を特定することが難しいという課題を仮定します。
たとえば特定顧客向けに特別対応した際の商品型番など、マスタ上に似たようなレコードが大量にあり、営業が入力する商品名から一意の商品を特定するのが難しいという問題です。
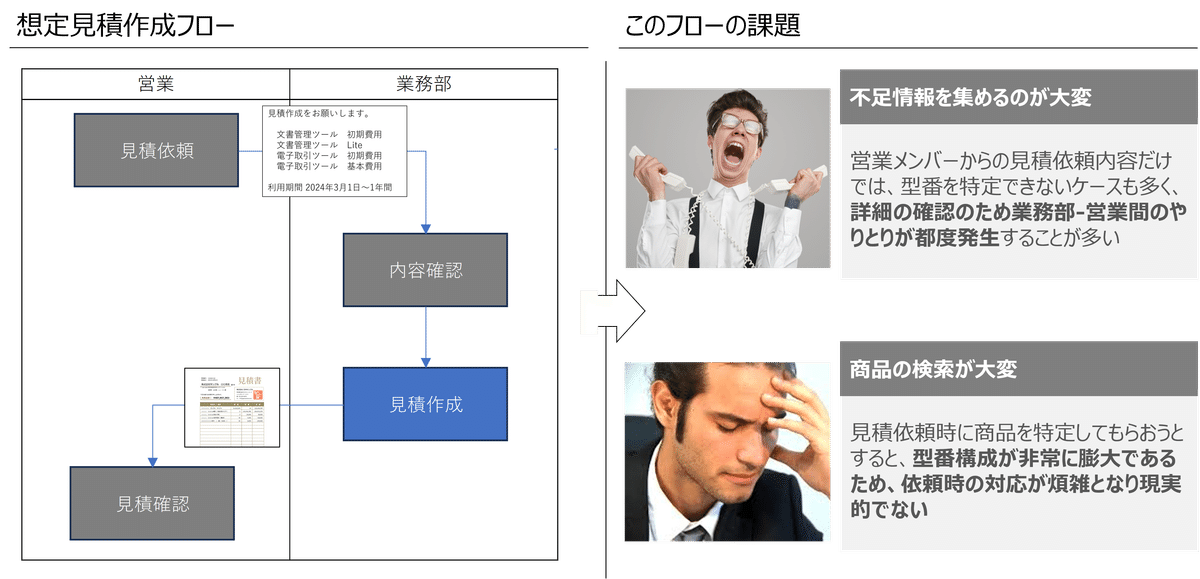
結果的に、同じ営業の過去の依頼内容から推測したり、あるいは結局のところ依頼元である営業に連絡を取って確認作業を行なうことを余儀なくされそうです。
基本設計
上記の課題および要件がある中で、今回私たちは以下のような設計をしました。

既存業務フローに手を入れる箇所
もっとも工数がかかる部分は営業部から上がってくる見積依頼の内容確認です。当然、まずはここに手を入れることにしました。
これまで目視やヒアリングを実施して確認していた部分を自動化します。
また、自動化の結果、精度が100%ではない場合は、最終的には担当者のチェック工程は必ず残す必要があります。
必要な機能について
見積依頼の精度向上のために、次の機能を開発することにしました。
フリーフォーマットの依頼内容をシステム可読性の高い形式に変換
記載された製品名から型番を検索
機能設計
フリーフォーマットの依頼内容をシステム可読性の高い形式に変換
これは、OpenAIのGPTを使うことにしました。
会社で使用しているチャットツールに営業担当がフリーフォーマットの見積依頼を送信します。その際、後の工程でマスタ検索をする際に使用するためのカテゴリを選択させます。ユーザーがカテゴリを選択すると、入力された文章をリクエストに含めたうえで、GPTのAPIをコールするようにChat Botを構成します。
そして、得られたレスポンスを次の処理に渡します。
形式は、次のようなCSV形式とします。
見積番号,明細番号,商品名,数量,契約開始日,契約終了日,商品カテゴリ
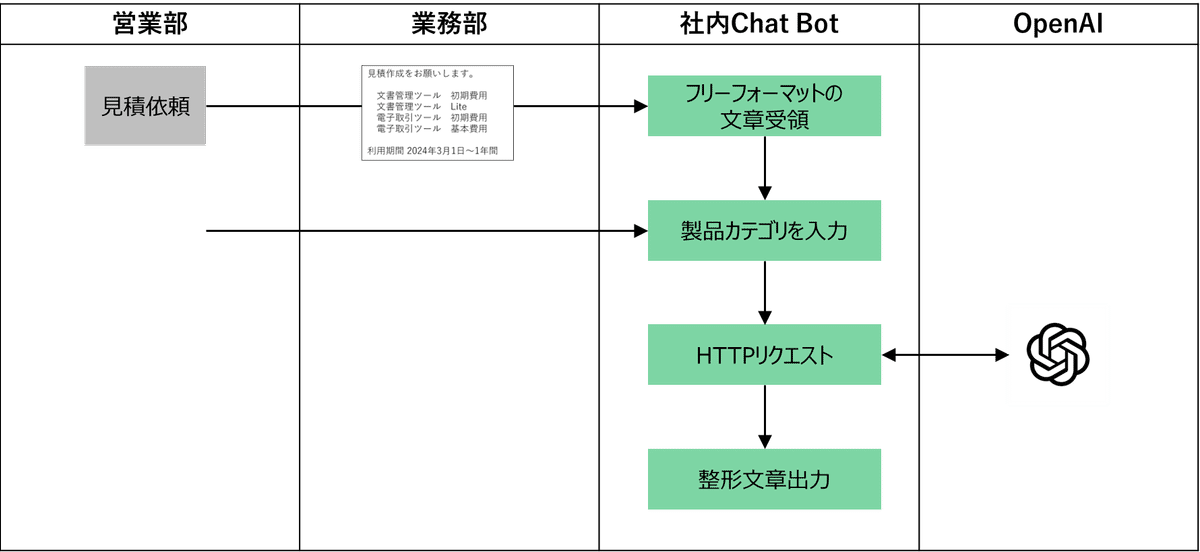
記載された製品名から型番を検索
これは、製品マスタをベクトル化したうえで類似度検索を行なうことにしました。
ベクトル化はOpenAIのembeddings APIを使用します。embeddingのモデルはtext-embedding-3-largeを使用しました(当時最新)。なお、次元数はとくに指定せず、デフォルトの3,072次元で試しました。
類似度検索は、ベクトル化した製品マスタをPostgreSQLに格納したうえで、PostgreSQLのpgvector拡張を使ってコサイン類似度を用いることにしました。また、検索の際は少しでも処理を軽くしたいので製品カテゴリを抽出条件として用います。
AIや機械学習を使った自動化の際は、出力の評価やモニタリングが求められるはずです。
精度が100%になることはありえないし、モニタリングをして業務ユーザーに精度感を示さないと、業務ユーザーに信頼されず、結局従来どおりの方法で業務を続けられてしまいます。
そのため、出力値の評価については、コサイン類似度の他に編集距離、とくにジャロー・ウィンクラー距離を使った近傍検索を採用し、さらにそれぞれの検索結果をBEST3まで出力することにしました。
検索実行後の出力フォーマットは以下のとおりです。
---検索結果---
入力された商品名【<検索対象製品名>】
<コサイン類似度>
TOP1:<型番>,<製品名>
TOP2:<型番>,<製品名>
TOP3:<型番>,<製品名>
<編集距離>
TOP1:<型番>,<製品名>
TOP2:<型番>,<製品名>
TOP3:<型番>,<製品名>

実装
実装に関しては、Chat Botの部分は省略いたします。
また、Renderの構築に関しては別記事にまとまっているのでそちらをご参照ください。
フリーフォーマットの依頼内容をシステム可読性の高い形式に変換
Chat Bot側は省略するので、この機能についてはOpenAIのGPT APIに与えたプロンプトだけ紹介します。
##指示事項
下記「対象文書」には契約期間、商品名、数量、などの情報を含んでいます。
表示例の様にCSV書式で見積番号,明細番号,商品名,数量,契約開始日,契約終了日,商品カテゴリを記してください。
ただしCSVにおけるヘッダーにあたる表示例の1行目は出力しないでください。
明細番号は商品ごとにカウントアップしてください。
見積を分ける指示がある場合は、見積ごとに見積番号をカウントアップしてください。
商品区分名は<ユーザー選択カテゴリ値>で固定。
記載がない場合、数量は”1”、契約開始日と契約終了日は”-”としてください。
必ず見積番号,明細番号,商品名,数量,契約開始日,契約終了日,商品カテゴリの要素が必要です。
##対象文書
<ユーザー入力値>
##表示例
見積番号,明細番号,商品名,数量,契約開始日,契約終了日,商品カテゴリ
1,1,パッケージA 初期費用,1,2024/04/01,2025/03/31,新規クラウドA
1,2,パッケージA 月額,1,2024/04/01,2025/03/31,新規クラウドA
当時はGPT-3.5でした。
現在のGPT-4oでは最適なプロンプトは異なるかもしれません。
記載された製品名から型番を検索
Web Service on Render
RenderのWeb Serviceにデプロイしたのは以下のコードでした。
from fastapi import FastAPI, HTTPException, Depends, Header
import os
from fastapi.responses import PlainTextResponse
from vector_search_pgvector import DB_SELECT_AND_SEARCH
app = FastAPI()
# APIキーの設定
valid_api_key = os.getenv('AUTH_API_KEY') #RenderのAPIキー
# APIキー認証の依存性関数
def verify_api_key(api_key: str = Header('Authorization')):
# APIキーの検証
if api_key == valid_api_key:
return True
else:
raise HTTPException(status_code=401, detail="Unauthorized")
@app.get("/search")
async def search(Q_item_name: str, Q_item_category: str, authorized: bool = Depends(verify_api_key)):
return PlainTextResponse(content=DB_SELECT_AND_SEARCH(Q_item_name, Q_item_catChat Botはhttps://<webservice name>.onrender.com/searchにリクエストします。
その際、パラメータ【Q_item_name】【Q_item_category】にそれぞれ製品名と製品カテゴリをセットします。
また、HTTP Headerも【Authorization】にAPI KEYをセットします。ここで言うAPI KEYは、RenderのWebServiceのAPI KEYです。Renderの環境変数に静的に設定していました。
もしAPI KEYが一致しなかった場合は401を返します。
API KEYが一致していた場合は、【Q_item_name】【Q_item_category】を関数DB_SELECT_AND_SEARCHに渡して呼び出します。
そのDB_SELECT_AND_SEARCHは以下のとおりです。
import openai
import os
import Levenshtein as ls
import time
import psycopg2
import csv
from io import StringIO
def DB_SELECT_AND_SEARCH(Q_item_name, Q_item_category):
openai.api_key = os.getenv('OPENAI_API_KEY')
# PostgreSQLへの接続情報
conn = psycopg2.connect(
dbname = os.getenv('DB_NAME'),
user = os.getenv('DB_USER'),
password = os.getenv('DB_PASSWORD'),
host = os.getenv('DB_HOST')
)
# 検索用の文字列をベクトル化
retries = 5
while retries > 0:
try:
vector_query = openai.Embedding.create(
model='text-embedding-3-large',
input=Q_item_name
)
break
except openai.error.OpenAIError as e:
print(f"Error: {e}")
retries -= 1
time.sleep(5) # 5秒待機してリトライ
vector_query = vector_query['data'][0]['embedding']
cur = conn.cursor()
# PostgreSQLへのSELECT文作成し実行
vector_query = f"SELECT \"Item_Number\", \"Item_Name\", 1 - (embedding <=>'{vector_query}') AS cosine_similarity FROM m_items_vector WHERE \"Item_Category\" = '{Q_item_category}' ORDER BY cosine_similarity DESC LIMIT 3"
cur.execute(vector_query)
results_vector = cur.fetchall()
# クエリ結果を辞書に変換
vector_list = []
for row in results_vector:
item_dict = {
'item_number': row[0],
'item_name': row[1],
'similarity': row[2]
}
vector_list.append(item_dict)
cur.close()
cur = conn.cursor()
# PostgreSQLへのSELECT文作成し実行
items_query = f"SELECT \"Item_Number\", \"Item_Name\" FROM m_items WHERE \"Item_Category\" = '{Q_item_category}'"
cur.execute(items_query)
results_items = cur.fetchall()
cur.close()
conn.close()
# 総当りで類似度を計算
jaro_winkler_list = []
for row in results_items:
result_dict = {
'item_number': row[0],
'item_name': row[1],
'similarity': ls.jaro_winkler(row[1], Q_item_name)
}
jaro_winkler_list.append(result_dict)
# ジャローウィンクラー距離の近い順で降順(大きい順)にソートしてTOP3だけ取得
results_jaro_winkler = sorted(jaro_winkler_list, key=lambda x: x['similarity'], reverse=True)[:3]
results_sorted = vector_list + results_jaro_winkler
return results_sorted
DB_SELECT_AND_SEARCHはOPENAI_API_KEYからOpenAIのAPI KEYを取得して、製品名Q_item_nameをベクトル化します。その後、そのベクトル値を用いて類似度検索をPostgreSQLで実行します。結果セットは類似度順に並べたうえで上位3件だけ取得します。
その後、再度対象の製品カテゴリの全件を取得し、今度はPython上で総当たりでジャロー・ウィンクラー距離の測定からの類似度計算を行ないます。
お恥ずかしい話、だいぶ非効率できれいでない書き方だと思います。たとえば、たぶんPostgreSQLのほうでも編集距離の計算ができそうなので、本来はそうするべきだと思います。
PostgreSQL on Render
PostgreSQLに用意したm_items_vectorのCREATE文は以下のとおりです。
CREATE TABLE IF NOT EXISTS public.m_items_vector
(
"Item_Number" character varying COLLATE pg_catalog."default",
"Item_Name" character varying COLLATE pg_catalog."default",
"Item_Category" character varying COLLATE pg_catalog."default",
"Item_Brand" character varying COLLATE pg_catalog."default",
embedding vector
);
embeddingに3,072次元のベクトルが格納されることになります。
ここに、予め製品名をベクトル化したマスタを格納して利用します。
おわりに
今回は省略していますが、本来はChat Botで、ユーザーからリクエストのあった依頼内容を処理途中でDBに格納したりといろいろ考えていました。処理途中でエラーになった場合、Resumeできるような対策です。
さて、技術面の拙さはともかく、今回設定した課題とそれに対するアプローチについて、みなさんはどう思われたでしょうか? たとえば、見積依頼がフリーフォーマットという運用はかなり特殊だと思いますか?
私はけっこう、ビジネス優先でマスタ整備が後手に回ってるとか、あるあるの課題じゃないかと思ったりしています。
見積依頼時に正規化して入力させるべきだよねとか、MDMのようなシステムがあるべきだよねとか、正道なやり方としてどうあるべきかはたぶん全員わかっているはずです。それでも社内状況やコスト、スケジュールの問題で諦めている現状に対して、AIを投入してクイックに解決を目指していくというのはコンセプトとしては間違ってないと思いますけどどうなんでしょう。