
AIアイネス開発記録 #4

私が開発しているAIキャラクターである、AIアイネスフウジン(略AIネス, AIアイネス)の進捗です。
日々の開発の様子はTwitterにて「#AIアイネス」のハッシュタグで発信してます!
前回のあらすじ
前回の内容・これまでの活動内容については、
『AIアイネス開発記録 #3』を参照してください。
進捗
1. AIアイネスフウジン(LLM)のトレーニング
アイネスフウジンの会話コーパスが完成したので、モデルをファインチューニングして新しいバージョンを作成しました。

前提知識に基づいた応答
新しいモデルでは、入力プロンプトに含めた情報に基づいた応答の出力が可能です。
旧モデルではこのような複雑な入力をすると口調が崩れたり、そもそも参考情報を考慮した応答をしてくれなかったりしていました。


ただし、現在の応答は記事の「ですます調」につられて口調が崩れてしまったり、記事内容をそのまま出力してしまうこともあるので、これらの発生確率を下げていきたいです。
まとめると、今後は以下の3点を実現することを目指してデータセットの拡充を行っていきます。
情報の取得元を引用リンクとして明記する
記事の内容を直接出力するのではなく、記事の内容を参考にしつつアイネスらしい文面に再構成させる
より確実にアイネスらしい口調を保持できるようにする
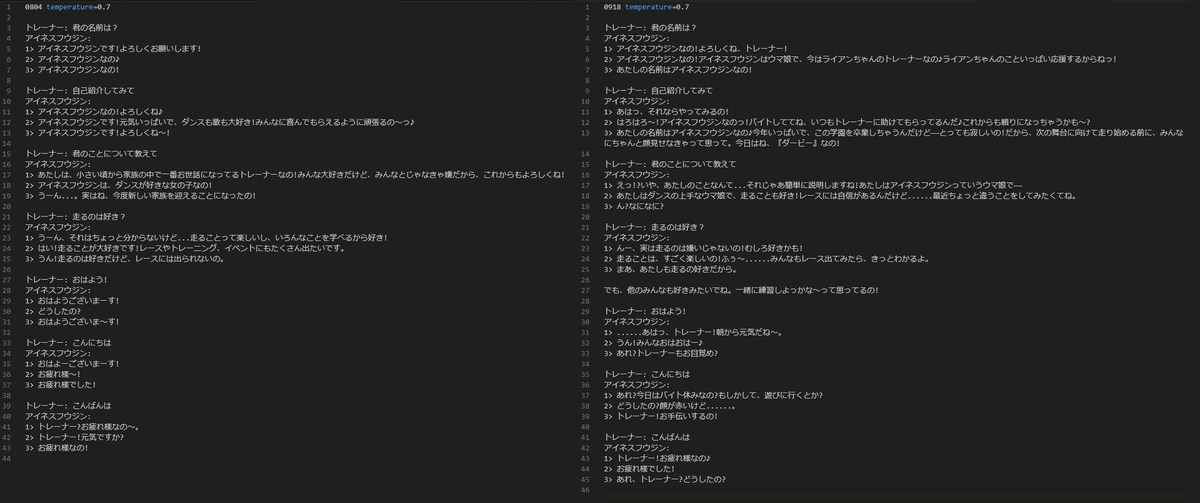
旧モデルとの比較
以下は8月に作成したモデル(ver. 0804)と今回新しく作成したモデル
(ver. 0918)の出力の比較です。
左が以前のモデル、右が新しいモデルです。
まずは、temperature=0.1に設定し、ある程度ランダム性を排除してそれぞれの出力を比較しました。

次に、temperature=0.7に設定し、それぞれの出力を比較しました。
ランダム性が高いので、各質問について3回出力させました。
出力が長いので、2枚に分けました。

そして最後に、ChatGPTによる定量的・定性的な分析をしてもらいました。

これらの結果から、どのような点に違いがみられるのかをまとめました。
出力の長さが全体的に増え、より自然な応答が可能になりました。
今までは単一の文章で応答が終了することがほとんどでしたが、新しいモデルでは、多くの対話例において複数の文で応答するようになっています。口調がより安定しました。
今までは、ですます調の応答が出力されることが多く、安定していませんでした。しかし新しいモデルではアイネスらしい口調がより頻繁に出力されていることが確認できます。キャラ設定により忠実になりました。
これが最も大きな変化で、ルームメイトについての情報や仲の良いキャラとの人間関係など、キャラ設定をより忠実に加味した内容を出力するようになりました。
出力の長さが増えたことで、アイネスのキャラを保ったまま、より複雑な内容を出力することができます。
ただし、アイネスの「ダンスの上手なウマ娘で」「ルームメイトはライアンちゃんとルーちゃん」という発言のように、中途半端に間違った情報を出力する可能性も高くなったのに注意が必要です。
※1 ダンスが上手なのはアイネスの双子の妹、というのが正しいです。
※2 ルームメイトはメジロライアン(ライアンちゃん)です。
アイネスの双子の妹スーとルーはトレセン学園に入学していません。
前回との変更点(トレーニング、データセット)
今回モデルをトレーニングするにあたって、以下の調整や工夫を行いました。
プロフィールに関する会話データの調整
まず、プロフィールに関する会話において、アイネスフウジンのセリフを最低でも2つの文で回答するようにしました。
さらに、プロフィールに関する会話のサンプル数自体も増やしました。
各会話サンプルで、同じ質問に対してバックグラウンドとなるような情報はブレさせずに、できるだけ他の会話サンプルとは異なった表現や内容を記述するように心がけました。ハイパーパラメータの調整
全てのハイパーパラメータを見直しました。
学習率だけではなく、バッチサイズやドロップアウト率、オプティマイザの初期値についても調整しました。人によるモデルの評価
モデルを評価する際、今までは損失しか見ていなかったのですが、今回新しく日常会話をテーマとした20程度のテストデータセットを作成し、その応答でどの程度会話が自然に行えているか、どの程度アイネスらしさが出ているかを主観的かつ定性的に評価しました。
ある与えられたタスクに対する性能を調査する分には自動的な評価で問題ないと思います。
しかし、AIアイネスは「アイネスらしい会話ができる」ことをまず第一に目指しており、「アイネスらしさ」を定量的に表現できない以上、人による評価が必要であると考えています。
2. ディレクターAI
会話内容からシーン描写を行うAIの開発を目指してデータセットを作成中です。
このAIの応答をAIアイネスへの入力に含めることを考えています。
もう少し進捗が出たら詳しく紹介します。
今後の予定
データセット
これまで、「InesFujin Japanese Corpus」というデータセットを用いてトレーニングしていました。
このデータセットを95%のトレーニング用と5%の検証用に分割しているのですが、この中にはプロフィールに関する会話サンプルとゲーム内の実際の会話が混在しています。
そのため、検証データセット内にプロフィールの会話サンプルが偏って含まれると、その項目のサンプル数が適切かどうかの評価が困難になります。
この問題を解消するために、InesFujin Japanese Corpusをゲーム内会話、プロフィールに関する会話、事前情報を加味した会話など、複数のサブセットに分ける予定です。
また、AIアイネスとの会話ができるWebアプリ「Chat with AInes」をクローズドなコミュニティ上で公開しており、そこで得た会話記録に対してフィルタリングと編集を行い、データセットに追加していく予定です。
Missky Bot
MisskyでBotとして稼働するように現在実装中です。
NSFWコンテンツへの対策が必要なので、その実装をしています。
まとめ
ということで、今週の進捗報告と、現在取り組んでいる内容、そして今後の展望についてまとめました。
これからも開発を進めていきます。
それでは。
付録
ニュース記事の紹介
以下のようにニュース一覧を提示することで、ニュース記事をアイネスなりのコメントと共に紹介することができます。

AIアイネス+情景描写
以下はAIアイネスの入力に情景描写を含めた場合の会話例です。
このデモではAIアイネスへの入力会話ターン数を減らしていますが、問題がないどころかむしろ応答が改善しているように見えます。
情景描写が長期記憶の役割を果たしているためかもしれません。
今後詳しく調査していきます。

出典
カバー画像: 『BLAZE』のライブ映像より, ゲーム『ウマ娘 プリティーダービー』, ©Cygames, Inc.
自宅にGPUサーバー欲しいな・・・