
AIアイネス開発記録 #1

私が開発しているAIである、AIアイネスフウジン(略AIネス, AIアイネス)の進捗を整理していきます。
日々の開発の様子はTwitterにて「#AIアイネス」のハッシュタグで発信してます!
AIアイネスって?
AIアイネスは、『ウマ娘 プリティーダービー』に登場するキャラクターである「アイネスフウジン」を模倣した応答を出力するAIです。
ここでの模倣とは、口調のような表面的な特徴だけでなく、彼女の性格や周囲の人間関係、彼女の置かれた状況から導き出される内面的な特徴(簡単に表現すると、話す内容の傾向)も模倣することを目標としています。
具体的には、以下の機能の実現を目指しています。
問いかけに対し、アイネスフウジンらしい応答ができる
アイネスフウジンらしい応答のまま、以下のテーマに沿った会話ができる
日常会話
ウマ娘に関する会話
(レース条件に合わせたウマ娘・サポカ編成のアドバイス)
これまでの振り返り
AIアイネスは、2023年04月下旬から始まったプロジェクトです。
4月からの約3カ月間、定期的にTwitterで進捗を発信してきました。
今回は第1回目ですので、全体的にどういうことをしてきたのか、軽く触れておこうと思います。
今まで何をやってきたのか知っているよって方は飛ばしてもらって問題ありません。
1. プロンプトによる模倣
まず初めに、ChatGPTにプロンプトの形で情報を提供し、アイネスフウジンらしい応答をさせることを目指しました。
最終的なプロンプトは、以下のツイートに記載のGithubリポジトリにて公開しています。
(ちなみにREADME.mdの内容は全てChatGPTに出力させたものです)
InesFujinDataset v2
— Sakusakumura (@Sakkusakumura) May 14, 2023
ChatGPTにアイネスフウジンらしい応答をさせるデータセットとプロンプトを更新しました
文字数を大幅削減したのと、GPT-3.5用のプロンプトを追加しましたhttps://t.co/ADQAPtozYc#ウマ娘 #アイネスフウジン pic.twitter.com/TtEhiUUif3
このプロンプトでは、以下のような作業を行いました。
アイネスフウジンのプロフィール、セリフを集める。
セリフは、ホーム画面でのセリフと育成中のセリフ、そしてチーム競技場での掛け合いが対象です。
データはウマ娘 プリティダービー 攻略 Wiki様より取得させていただきました。セリフについて、ChatGPTにアイネスフウジンの特徴がよく反映されているものを選んでもらう。また、必要のない情報をChatGPTと共に精査する。(≒蒸留?)
このステップは3回繰り返し、約25000トークンだったセリフを、5000トークン程度に圧縮しました。
GPT-3, GPT-3.5向けには、さらにギリギリ品質を保てる限界までセリフを削減し、約2200トークン程度に圧縮しました。
GPT-4は8192トークンまで、GPT-3.5は4096トークンまでのコンテキスト長に対応しているので、プロンプト入力後、GPT-4は3000、GPT-3.5は2000トークン程度の間会話ができる計算です。残ったセリフを読み込ませ、アイネスフウジンの口調やセリフの特徴をできる限りたくさん出力してもらいました。
結果として12個の、特徴を説明する文章を得ることができました。これまでのステップで得た文章からプロンプトを作成し、一度に送信できるトークン数(この頃は2500くらいだった)に分割します。
結果として、85%~90%くらいの精度でアイネスらしい応答をさせることができました。
しかし、やはりプロンプトベースだと話しているうちにキャラを模倣させるという制約が抜けてしまうこと、そして急に別のタスクをさせると化けの皮が剝がれてしまうこと、この2点が依然として課題でした。
この時期にプロンプトによる模倣に限界を感じ、LLMのファインチューニングに手を出していくことになります。
2. アイネスの会話コーパス作成
とりあえずChatGPTに模倣させた時のデータでファインチューニングしてみたところ、ちゃんと模倣できそうなのでセリフデータの対象を、ゲーム内のすべてのイベントに広げることにしました。
この時のデータセットのサンプル数は190でした。
アイネスフウジンの会話データセットを作ってrinnaのgpt-neox-smallをファインチューニングして遊んでたら日が昇ってましたとさ
— Sakusakumura (@Sakkusakumura) May 25, 2023
ちゃんちゃん☆ pic.twitter.com/Z0YwmgIM2e
ホーム画面や育成中のセリフと違い、イベント中のセリフまで文字起こしして網羅しているサイトはありません。
そこで、以下のステップで会話データを集めました。
ゲーム中の『会話ログ』画面をスクショする
スクショ画像中の、各セリフ領域を矩形で囲む。
画像からの文字認識(OCR)を行う際、1つの画像に1つの文章のみを含むようにすると精度が上がるためです。Tesseractを用いてOCRを行う。後述するワークフローによって得られたモデルを使用しています。(最終的なエラー率は10%くらいだったはず)
Manga-ocrとか知っていれば試せたんですけどね・・・OCR結果と実際のスクショとを見比べて、間違いの修正を行います。
正直ChatGPTに任せたかった感じはある「(キャラクター名): (セリフ)\n」のフォーマットに直します。
連続したセリフのうち、同じ場面や状況、心境で発せられたものをまとめます。
セリフの文脈が変化したり、タイミング的に間が空いている場合は、セリフ間にトレーナーのセリフを入れて、モデルがその発言の文脈を認識できるようにする必要があります。得られたフォーマット済みのテキストファイルをjson形式に変換します。
作業ワークフロー
次のようなワークフローを組みました。
各工程の結果を確認したかったのと、私しか作業に携わる人が居ないので、小さなスクリプトを複数作成し、半自動化のようなかたちで作業しました。
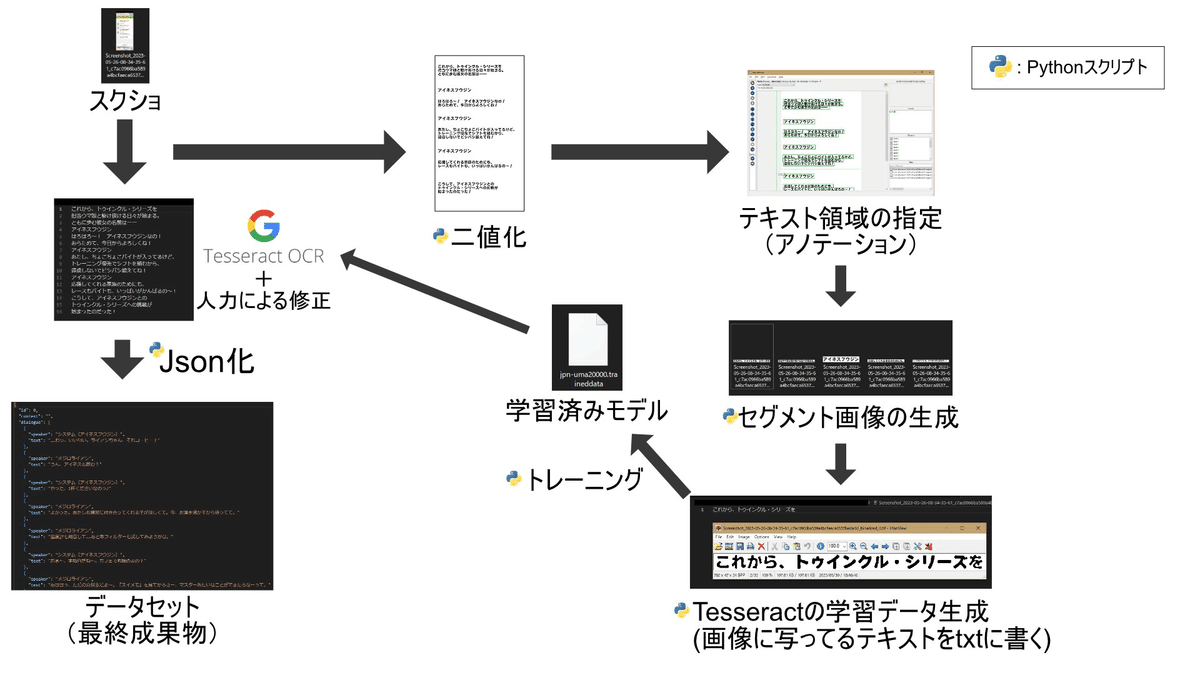
OCR結果の修正は簡単なツールを作成して行いました。
うーんうーん修正修正・・・ pic.twitter.com/FKjoY5O9mC
— Sakusakumura (@Sakkusakumura) June 1, 2023
途中からデータセットエディタも作成して導入しています。
データセット作成ツールはこんなもんでええやろ#AIアイネス pic.twitter.com/6UnrWi8LqA
— Sakusakumura (@Sakkusakumura) June 18, 2023
スクショ画像中の、各セリフ領域を矩形で囲む作業(アノテーション作業)はYOLOによる自動化を目指しています。
もう少し精度を上げないと実用には耐えないかなーといった感じです。
とりあえずちゃんとデータセット作った これくらいの精度だったらあとは手直しすればいいだけだから大分楽になるかな? roboflowは訓練したモデルデータをサービス側に握られてて、推論にはクレジットが必要だからそのうち乗り換える予定#AIアイネス pic.twitter.com/lOtOw6lF6i
— Sakusakumura (@Sakkusakumura) July 29, 2023
3. 技術検証(ウマ娘知識の導入)
データセット作成と並行して、モデルをウマ娘関連の攻略情報でトレーニングすることで、instruction(事前情報)を与えた時の応答精度を向上させ、さらに事前情報無しでもウマ娘関連の用語を出力させることに成功しました。
ただし、現在所持している、ウマ娘関連の情報でトレーニングしたモデルはハイパーパラメータの調整をしていないため、適切に学習できていません。
情報の正確さは失われてしまっていることからも改善の余地があると分かると思います。
学習データの増強と、ハイパーパラメータの調整が今後の課題です。

instructionの内容はウマ娘ラボ様より収集させていただきました。
現在の進捗
ここからは前回Twitterに投稿した進捗からの差分についてです。
1. アイネスの会話コーパス
協力してくださった方々のおかげで、ちょうど2カ月後の8/1にようやく62%の進捗を達成しました。
スイメモと育成ウマ娘ストーリーの会話をデータセットに追加完了しました!
— Sakusakumura (@Sakkusakumura) August 1, 2023
頂いたExcelファイルが凄く整理されていたので作業がとても楽だった・・・
今のサンプル数は1227です!
試しにファインチューニングするぞ~~~~~~#AIアイネス pic.twitter.com/OuFPJo49kX
撮影したスクショ:約850枚
会話データ:1227個
含まれる全キャラクターのセリフ:46万1454文字(重複あり)
アイネスのセリフ:4万2789文字(重複なし)
となっています。
『アノテーション』タスクは結構大変な作業なので、気長に少しずつ進めていこうと思います。
2. LLMのファインチューニング
アイネスフウジンのセリフデータ数が1000を超え、小さいながらデータセットとして成立する規模になりました。
そこで、既に対話チューニングが施されたモデルに対して、このデータでファインチューニングを行い、チャットボットを作成しました。
Flask+StreamlitでAIアイネスと会話できるチャットアプリ作った!
— Sakusakumura (@Sakkusakumura) August 6, 2023
steaming/バッチ推論は今の構成だとできなそうなのが悲しい#AIアイネス #ウマ娘 #アイネスフウジン pic.twitter.com/HKZk21swWc
本チャットアプリは、今月13日に開催される
「AIキャラクターオフ会 at Tokyo #0 by Saldra」
にて展示する予定です。
8/13(日)に「AIキャラクターオフ会 at Tokyo #0 by Saldra」を開催します🥳
— saldra(サルドラ) (@sald_ra) July 26, 2023
参加想定者はAIキャラの制作者だけでなくファンもです! 色々な出会いのきっかけになりますように。
参加費は2000円(学生無料)
以下が申し込みページです! 先着60人のためお気を付けください!https://t.co/sZ3HVVFXhi pic.twitter.com/gkQitBIkb7
今後の予定
1. ウマ娘コーパスでトレーニングしたモデルの作成
ウマ娘のキャラや用語に関する情報や、ゲーム『ウマ娘』の攻略情報は、既に収集済みで、いつでもモデルのトレーニングが開始できる状態です。
GCP(Google Cloud Platform)の無料クレジットが約30日程度で期限切れになってしまうので、A100インスタンスを借りてモデルのトレーニングに挑戦してみたいと思います。
無料クレジットの期限がかなり迫ってきているので、最優先で進めます。
2. アイネスの会話コーパス
ひとまず残っている画像のアノテーション作業(イベント50個くらい残り)
を進めていきます。
育成シナリオ関連のイベントは全て作業完了したので、今までよりは速いペースで進捗が出ると思います。

「InesFujin_JapaneseCorpus 進捗トラッカー」で公開しています。
3. チャットアプリ開発
クラウド上にAPIサーバーを立ち上げ、WebまたはAndroid向けに公開したチャットアプリの形でサービスを提供しようと考えています。
LineやブルアカのMomo Talkのような雰囲気のUIにしたいと思っています。
4. Misskeyのボット開発
チャットアプリの開発と同様に、Misskeyに自動投稿するBotを作成してみたいなと考えています。
具体的には、
ウマ娘の最新情報に関する投稿
返信への応答
定期的な「独り言」の投稿
の機能を考えています。
要求される技術的ハードルの高さはチャットアプリよりもBot開発の方が低そうなので、こちらを優先するかもしれません。
5. アイコンとか
最近、AIアイネスが形になってきたことで、アイコンやコンセプトアートをそろそろ作成しないとなと思うようになりました。
誰かに有償で委託しようかなと考えています。
興味ある方はTwitter, Discord, またはEmailなどで連絡をいただければと思います。
ということで、これまでの振り返り+進捗報告は以上です。
今後も開発続けていきます。
それでは。
出典
カバー画像: ゲーム『ウマ娘 プリティーダービー』アイネスフウジンの固有スキル演出より ©Cygames, Inc.