
DeepLabCut multi-animal support 5

本記事は、DeepLabCut multi-animal support 4の続きです。
Step 4. Create training dataset
前回のステップで作成したラベルデータを使ってtraining datasetを作成します。「Creating training dataset」タブをクリックします。「Set a specific shuffle index (1 network only)」は、トレーニングのデータセットを何パターン用意しますか?という意味です。ここでは1にします。「Specify the trainingset index」もデフォルトの0でいいです。「Crop and Label Data (Recommended)?」は、ディープラーニングをするときに画像をクロップしますか?という意味です。ネットワークにあった画像サイズの方が学習が適切に進むので通常はYesを選択します。「User feedback (to confirm overwrite train/test split)?」は、前回の学習結果を上書きして保存してもいいですかということです。通常はNoです。Yesにすると学習ごとに上書きしていいかを訊ねられます。詳細は、論文、サイト、Helpを参考にしてください。すべて選択したらOkを押します。Anaconda Promptに「The training dataset is successfully created」表示されるまで待ちます。

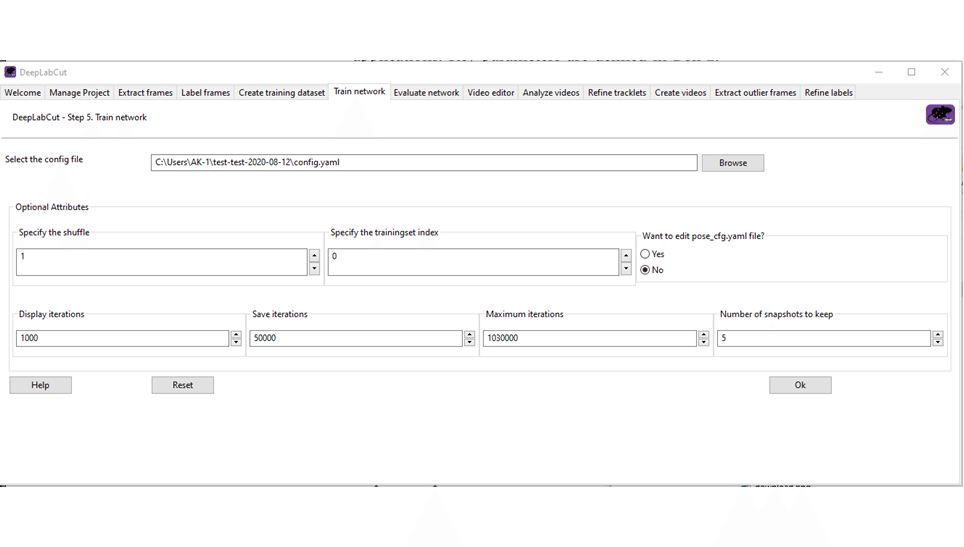
Step 5. Train network
いよいよ学習のステップです。ここでは学習の詳細な条件を決めていきます。学習は、ラベルした画像を何度も反復(iteration)しておこないます。「Display iterations」は学習の様子を何回おきに表示していくかを、「Save iterations」は学習した結果(重みやバイアス)などを何回おきに保存していくのかを、「Maximum iterations」は何回反復して学習させるのかを指定するオプションです。反復は通常、50,000程度で十分だそうです。詳細は、論文、サイト、Helpを参考にしてください。今回は、「Display iterations」を10、「Save iterations」を500、「Maximum iterations」を50,000にします。Okを押します。
学習がスタートします。Windowsの場合、Task Manager(Ctrl+Shift+Esc)でGPUのメモリが消費されていることを確認しておきましょう(下図)。

学習が正常にスタートしていれば、Command Prompt(Windows)に、
Starting multi-animal training....
iteration: 10 loss: 0.3018 scmap loss: 0.2302 locref loss: 0.0185 limb loss: 0.0531 lr: 0.0001
iteration: 20 loss: 0.0566 scmap loss: 0.0392 locref loss: 0.0048 limb loss: 0.0125 lr: 0.0001
iteration: 30 loss: 0.0374 scmap loss: 0.0296 locref loss: 0.0023 limb loss: 0.0055 lr: 0.0001
...と表示されてきます。
学習は「Maximum iterations」で指定した回数おこないます。学習が終わるまでPCをそのままにしておきます。
DeepLabCut multi-animal support 5に続きます。
参考文献・サイト