
SIGNATE COVID-19 Challenge

新型コロナウイルス(COVID-19)が世界中で猛威を振るい、私たちの暮らしや経済活動に深刻な影響を及ぼしています。現実問題としてCOVID-19の根絶が困難な中、私たちにはこのウイルス(および今後出現する新種)とうまく付き合っていくための「知恵」が必要です。世界中の国々で医療システム崩壊を避けるため許容可能な罹患者数を維持するべく、社会的距離戦略が実施され、人との接触を大幅に減らす行動が求められています。一方で、行動制限による経済活動の停止、ひいては暮らしを支える収入減へのインパクトは甚大で、補償にも限界があります。これらはトレードオフであり、医療システムを維持しながら経済活動を最大化する社会のあり方が求められていると考えます。そのためには、私たち一人一人が、正しい知識と判断材料をもとに適切な行動をとることが重要です。人は年齢・性別・基礎疾患・過去の喫煙/飲酒習慣など変えられない属性を持っていて、各々で感染・重症化リスクが異なるはずです。また、活動する場所や内容によってもウイルスの暴露・拡散リスクが異なると考えるのが自然です。リスクホルダーがリスクの高い行動をとることは論外です。低リスクな人々がリスクの低い行動をとることは問題でしょうか?印象論や一部の専門家まかせではなく、広いエビデンスやデータに基づいた意思決定が理想です。幸い、現代の私たちは、インターネット・SNS等の恩恵で、迅速に情報を収集可能な環境にあります(一方で不正確な情報・デマも拡散しやすい副作用:今回の場合いわゆるインフォデミックは問題ではありますが)。客観的な情報を集め、正しく恐れる知恵の共有が「SIGNATE COVID-19 Challenge」の目的です。プロジェクトのタスクは以下の3つです。
Phase1:関連するデータの収集
Phase2:有用な知見の共有
Phase3:今後の見通しの予測
SIGNATEの約3万人のデータサイエンティスト・AI技術者の中から有志にご協力いただき、侃侃諤諤、各タスクを進めております。
まず、Phase1では日本国内の感染状況に関連するデータを網羅的に収集し、分析可能な形式で整備します。具体的には日本国内都道府県別の感染者情報を自治体の報道から一元化します。その際、文章で記載されている行動や症状の変化を時系列順に構造化したデータとして記録していきます。さらに、感染経路が判明している場合は、感染者間の関係性もデータ化します。感染者数推移やクラスターの発生、属性によるリスクの違いなど、様々な検討に利用可能な基礎的データの整備を目指します。

次に、Phase2ではPhase1のデータや外部のデータを用いてダッシュボード等の可視化を行い、全体の状況を一目で確認できるツールの開発を行います。COVID-19対策を目的とした「問い」を設定し、データ分析による例証を試みます。また、海外(特にKaggleチャレンジ)で得られた知見からも学び、日本との比較を含めた検討・共有を進めます。データや論文の裏付けがある知見を認識することで、私たちの行動に関する意思決定がより合理的になることを目指します。

さらに、Phase3では2週間先の感染者推移の予測アルゴリズムの開発を行います。多数のアルゴリズムによる予測結果の多数決を採り、未来の感染状況の見通しを立てることに挑戦します。予測精度を検証し、感染拡大防止施策の前向きな効果予測や社会的距離戦略の意思決定への活用を目指します。

これらのタスクを同時並行で進め、データの収集、知見の共有、対策の検討、行動への反映、結果の見通し、をCOVID-19の社会的収束まで継続していく予定です。
また、本プロジェクトを通じて私たちは何を学ぶことができたのか?得られた成果が今後のパンデミック発生時における情報配信・活用のあるべき姿の議論につながればという思いもあります。
今後、以下に考え方や成果を随時、記載していきます。私は感染症の専門家では無いと言い訳しつつ、仮に専門家であったとしても完全解は無いのだろうというスタンスです。アイデア・改善案等ご意見いただければありがたいです。
変えられないリスクを知る
今現在、年齢・性別・基礎疾患・過去の喫煙/飲酒習慣など、自らは変えられない属性と、COVID-19による感染・死亡リスクの関連は非常に重要です。「なんとなく自分は大丈夫ではないか?」という根拠の無い判断ではなく、定量化されたリスクにより、自分の置かれている状況を客観的に理解することで、自分を守る意識や他者(特にリスクホルダー)への配慮が明確になるのではないでしょうか?アプローチとしては以下が考えられます。
1. 感染者データの整備と分析
厚労省・自治体から毎日報道されるデータにも年代・性別・職業・重症度・症状などが開示されています。しかし、データフォーマットや記述レベルが統一されておらず、PDFや画像データで公開されている場合もあるので、簡単に自動収集し一元化することは困難です(SIGNATE COVID-19 Case Datasetはこのデータを有志で収集しています)。全体の計数(感染者数・重症者数・死亡者数・退院者数など)に関しては、報道機関が収集・公開しているデータも有用です(例えば、NHKのサイトはデータ分析もされていてわかりやすいです)。都道府県別の状況や年代別の感染・死亡リスクの把握が可能です。しかし、どのような職種のリスクが高いか?感染者特有の高頻度な症状は何か?といった詳細に関して迅速に集計公開可能なデータは未だ存在しないのが実際です。前述の自治体報道のデータには、それらの情報は文章で記載されており、表現がまちまちであるため、分析が困難であるためです。そこで、SIGNATE COVID-19 Case Datasetでは、共通の用語で揃えた形式でデータ化を進め、感染実態に迫るべくチャレンジしています。
例えば、2020/5/4時点のSIGNATE COVID-19 Case Datasetを用いて状況を確認してみます。
感染者数の年代・性別における分布を以下に示す。全体としては50代、女性は20代、男性は40代が最も多い。20歳未満と90代以上は少ない。

重症度の年代・性別における分布を以下に示す。男女共に高齢になるに伴い重症化・死亡リスクが高まる。一方で、20歳未満はほぼ半数は無症状で残りは軽症と重症化リスクは低い。

感染者の職業の分布を以下に示す。会社員が最も多く、次いで無職が多い。会社員は30-50代が、無職は60代以上が統計的有意(p-valueはhypergeometric testにより算出)に多い。医療従事者は看護師、福祉従事者は介護士が支配的で、事務職等の一般職員も含めて施設内感染者への接触が多いシーンがリスクを高めていると考えられる。学校に関しては顕著な特徴はみられなかった。ただし、学生に一定数の感染が認められるので、むしろ自粛要請前の街中での活動が増えたことに起因するかもしれない。
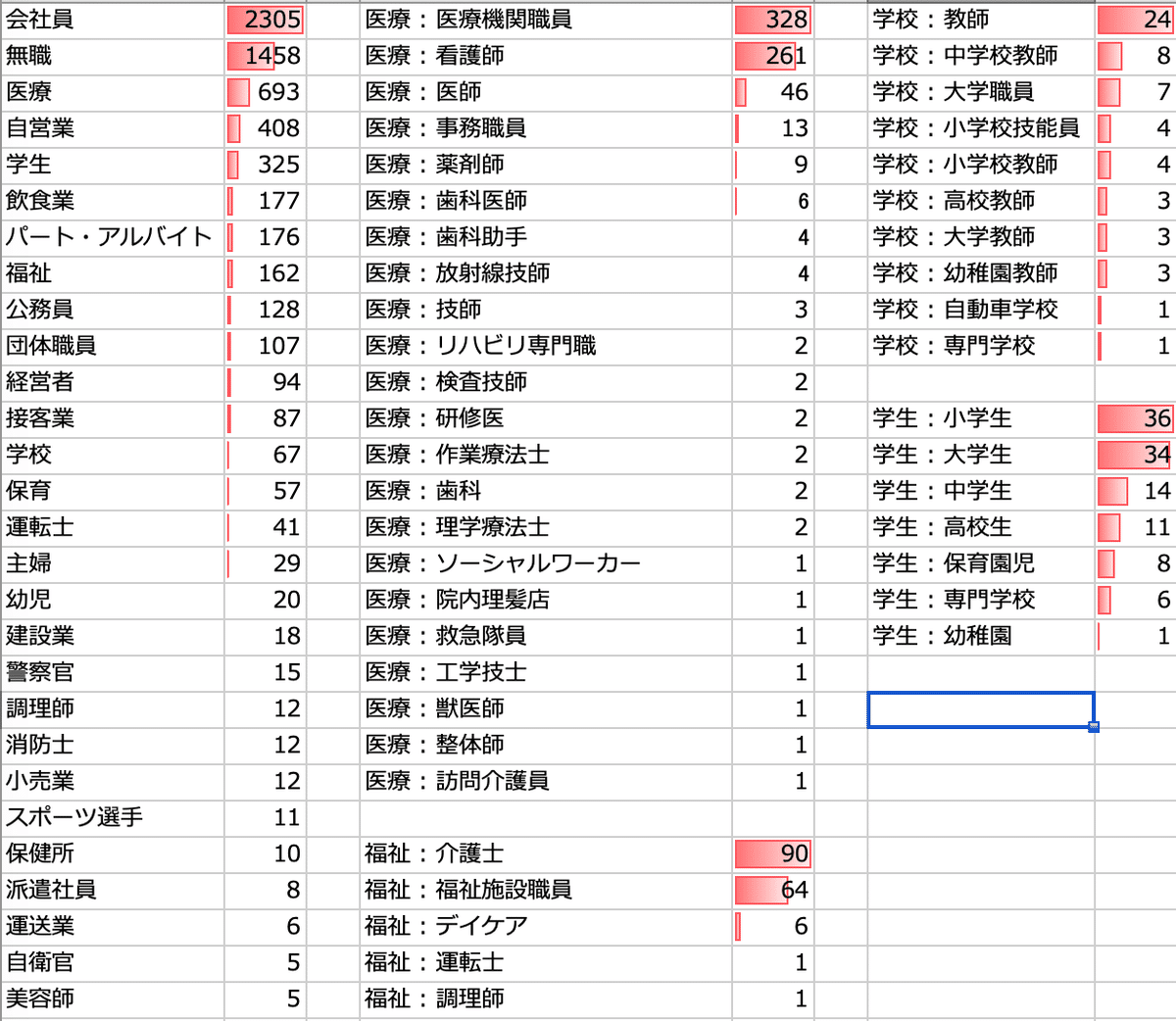

感染者が示す症状の特徴はどのようなものだろうか?自治体の報道資料には症状に関しては、例えば以下のような文章で記載されている。
3月29日咳が出現。3月30日咳に加え、発熱(37.6°C)、頭痛、全身倦怠感、関節筋肉痛、味覚・嗅覚障害が出現。3月31日医療機関Aを受診。インフルエンザ陰性。処方を受け帰宅。4月2日医療機関Aを再度受診。4月3日症状が継続するため、医療機関Bを受診。CTで肺炎像を認め、新型コロナウイルス感染症が疑われ、検体採取。4月4日検査を実施し、陽性と判明。
記述レベルもフォーマットも自治体によってバラバラで、症状・疾患に関する言葉も様々な表記になっていて、このままで集計や分析ができない。そこで万病辞書を用いた形態素解析を行い、ICD10コードに対応する症状を抽出した。上記のレコードの場合、以下のようなイメージだ。
3月29日咳が出現。3月30日咳に加え、発熱(37.6°C)、頭痛、全身倦怠感、関節筋肉痛、味覚・嗅覚障害が出現。3月31日医療機関Aを受診。インフルエンザ陰性。処方を受け帰宅。4月2日医療機関Aを再度受診。4月3日症状が継続するため、医療機関Bを受診。CTで肺炎像を認め、新型コロナウイルス感染症が疑われ、検体採取。4月4日検査を実施し、陽性と判明。
→
咳:R05;発熱:R509;頭痛:R51;全身倦怠感:R53;筋肉痛:M7919;味覚障害:R432;嗅覚障害:R431;肺炎:J189
今回は時間の関係もあり、否定表現などのいくつかのノイズについては目視でチェックを行った。ICD10コードの集計結果を以下に示す。

全体としては、およそ30%の患者さんが発熱し、14%が咳、12%が倦怠感を訴える。これらは、ほとんどの年代で共通して上位3つの症状としてあらわれる。他にも喉の痛み、鼻水など、普通の風邪によく見られる症状を示す。6%に肺炎像が認められる。30代以降、年代が上がると相対的に肺炎の報告が上位になる傾向がある。COVID-19においても特徴的な症状とされる味覚・嗅覚障害は、それぞれ約3%程度であった。こちらは、20-30代に比較的よく認められる傾向にある。

注:本データは完全ではないことを予めご了承ください。報道が限定的であること、我々の収集確認も完璧ではないことから、厚労省発表の全体統計と一致しません(例えば死亡数など)。複数の情報源の計数が一致する配信体制が望まれます。
職種による感染リスクが定量的にわかれば、高リスク従事者を守るための社会的サポートが必要なことが明確化されますし、当事者も細心の注意を払うことができます。感染同定されるまでの初期症状や特徴的な所見がわかれば、類似症状が出た場合に自重することができます。報道時に類型化された職業区分や症状としてICD10と紐づけて報告(入力システムは負荷がかからないものが望ましいですが)できれば、日毎にデータを集計開示することで感染症の実態を迅速に理解することが可能と考えます。
2. 疫学研究の結果を蓄積・統合解析を実施する
1.の報道ベースのデータでは詳細な症状や基礎疾患等などデータの精度に限界があります。一方で、感染が広がる渦中において、国内外でCOVID-19に関する疫学研究が実施され、論文として報告されています。一般的に患者さんの年齢・性別・人種・喫煙/飲酒習慣・併存疾患・症状・臨床検査値等のデータを収集し、興味のある集団間(例えば生存・死亡群)で統計学的に有意な差を示す要因が検討されています。例えば、以下にいくつかの論文のデータをまとめてみたのでご覧ください(注:検査値の整備は未着手です)。国内の疫学論文は以下にも記載した感染研のレポート以外、ほとんど見つけられませんでした(教えていただけるとありがたいです)。

複数の研究結果を統合分析(メタアナリシスといいます)することで、より統計学的に信頼性の高い結果を得ることができます。上記は一部の研究データに過ぎませんが、収集する研究論文数を増やすことで議論の精度を高められると考えます。例えば、一部の論文ですが、俯瞰することで以下のようなことがわかります。
※<感染・死亡リスクとして、年齢(高齢)、性別(男性)、高血圧、呼吸器系疾患、D-dimer(血栓)、IL-6等(サイトカイン)の上昇などの報告が多いようです。現在整理中・統計解析予定。>
研究論文データの統合作業を通じて感じた課題を示します。1つ目は、論文におけるデータの公開粒度がまちまちであることが挙げられます。論文によって項目別の感染者数を記載している場合もあれば中央値・IQRなどの統計データのみを記載している場合もあります。例えば、年齢も階級の数に差があったり、階級の分かれ目が異なったりします。疾患名や症状名も表記レベルが統一されていません。要因検討においてもオッズ比・ハザード比など、解析手法もそれぞれです。2つ目は、TableがExcelのような構造化データではなく、PDFに記載されていることです。表のレイアウトも論文によって違うので統一的な扱いの障壁となります。以下に「こうなったらいいな」を提言します(実際、実現は困難と想像しますが)。
・基本的な報告項目のテンプレートを検討する
疫学研究で共通に検討される項目は予めテンプレートを用意し、推奨報告項目や報告粒度(年齢階級の定義等)を整備。死亡に関する有意性検定など、代表的な統計解析手法については、自動計算機能を提供。症例データはPDFだけではなく、構造化されたフォーマットも添付してもらう。たとえ、大規模なデータベース構築ができないといても、報告形式が統一されていれば、メタアナリシスのハードルが下がる。
・疾患名・症状名・臨床検査項目名などは然るべきオントロジーに準拠する
今回はEMBL-EBIのOntology Lookup Serviceを用い、疾患名は「Disease Ontology」、症状名は「Symptom Ontology」を用いた。他にも様々な体系が存在するので実用性に関しては要議論)。オントロジーIDを付与する意義は、項目を階層的に扱うことを可能にし、複数の研究結果を任意のレベルで横断的にデータ解析・解釈することができることにある。
自治体による感染情報の報道発表・疫学研究論文データいずれにおいても予めデザインされた項目に対しマシンリーダブルな形式で蓄積・配信を行うことで、迅速な統計解析による知見の抽出・注意喚起が可能になるのではないでしょうか?
変えられるリスクを知る
すでにクラスターと呼ばれる集団感染の事実がある中、自らの行動内容と、COVID-19による感染リスクの関連もまた非常に重要です。「3密」の理解や手洗いの徹底など基本的な対策は前提として、データが示唆するリスクの高い場所には近づかない、リスクの高い行為を避ける、といった具体的な施策に一歩踏み込むことで、より自分を積極的に守ることが可能ではないでしょうか?アプローチとしては以下が考えられます。
1. クラスターの発生状況をモニタリングする
日本における感染拡大抑止戦略は、特に初期の頃においては、クラスター対策が中心でした。ここで、クラスターとは「1カ所で5人以上のつながりのある感染者の発生」で定義されます。厚労省クラスター対策班は、感染数理モデルの性質から、1人が多数の2次感染を引き起こす、いわゆる「スーパースプレッダー」によるクラスター発生を重要視しました。クラスターの迅速な特定、発生条件の分析、濃厚接触者の追跡等により爆発的な感染拡大が避けられると考えたのです。しかし、その後、経路不明の市中感染が多数発生することになります。結局、緊急事態宣言により、極度の活動自粛が余儀なくされました。クラスターの存在は事実であり、依然として危険な現象です。私たちはクラスター発生につながる行動を避けなければなりません。政府・専門家から示されたクラスター発生対策は「3密を避ける」ことであり、感染経路不明者が支配的になった時点では「人との接触を8割減らす」という条件の提示でした。実態はどうでしょう?3密とはどこなのよ?8割減らすって具体的にはどうすればいいの?と具体性に欠けるため、判断に迷います。何がよくて何がだめなのかわからないので、パチンコなど、なんとなくイメージの悪いものが叩かれます(実際リスクが高いかもしれませんが)。公園のジョギングは本当に危ないのでしょうか?それらを判断するためには、過去に発生したクラスターを知ることが重要です。感染する確率が高い、場所、シーンを可視化して事実に基づいて判断するのです。多くの人、重症化リスクが高い人であればなおさら、自分の命を脅かす行為を進んで取りたいとは思わないはずです。しかし、リスクの判断材料がないので、一切外出しない以外、できることはありません。過去のクラスター情報の開示状況はどうでしょうか?加藤厚生労働大臣は、2020/5/10時点で250件のクラスター発生について言及しています。内訳は、医療機関で85件、福祉施設で57件、飲食店で23件だそうです。
しかしながら、厚労省のHPでは2020/3/31公開の14都道府県26件から更新が止まっています。開示には自治体との協議が必要とのことです。
SIGNATE COVID-19 Challengeで収集したRelation Dataset(5/4時点)を分析した結果が以下となります。100件のクラスターが確認できました。主な世の中の動きの中、どこでどのようなクラスターが発生してきたのかを俯瞰することができます。
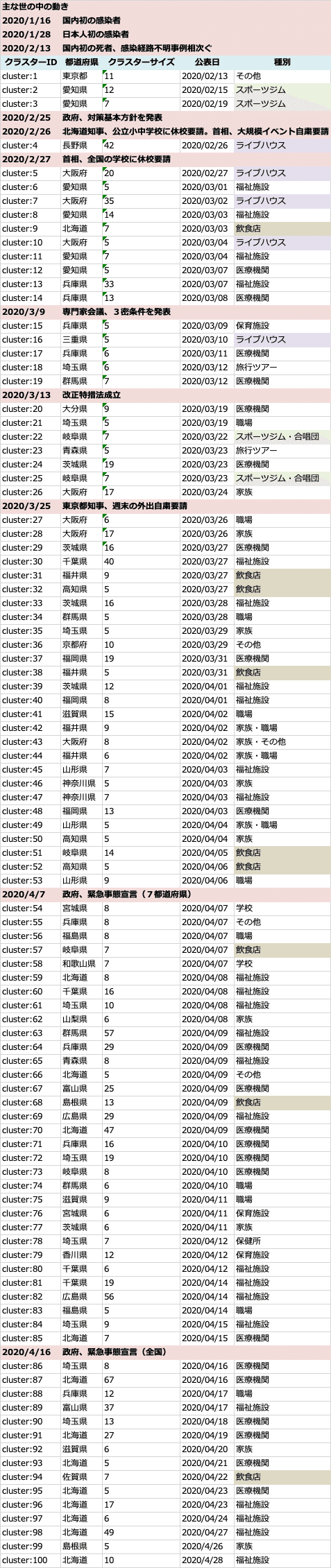
クラスターの約50%は医療機関と福祉施設で占められます。リスクの高いこれらの施設には重点的な対策支援が必要であることは自明です。初期の頃には、スポーツジムとライブハウスのクラスター発生が継続します。これらを早期に警戒すれば、感染拡大の状況に変化があった可能性があります。もっとも3/25の小池東京都知事による週末の自粛要請より前は、まだ、感染者数の増加は指数的ではなく、事態が深刻化していなかったこともあり意思決定が難しかったのだと推察します。その後の急激な感染者増加を受けて、該当施設は営業自粛になっています。一方で、飲食店で発生するクラスターは緊急事態宣言等、世の中の自粛ムードが高まっている状況下においても発生しています。国民の理解が追いついていないことが伺えます。以下に飲食店で発生したクラスター詳細を示します。

飲食店といっても、様々な業態があります。手元のデータでは、バーやナイトクラブの頻度が高く、特に気をつける飲食のシーンが理解できます。東京都知事から「夜の接客業」に関する注意喚起が発表されたのは3/27ですが、残念ながらそれ以降のクラスター発生が起きていることが確認できます。
このような議論においては、プライバシーの問題や風評被害の発生を鑑みて開示に慎重になるという実態があるかと存じます。個人的には有事におけるプライバシーの考え方を抜本的に議論する必要性を感じますが、仮に店舗名などを具体的に開示しなくても、上記のような類型化されたカテゴリー集計の状況開示を迅速に行うだけでも、リスクの可視化とリスクに沿った行動自粛が可能と考えます。