
GLITにおける求人検索の品質改善①(準備編)

こんにちは,Caratの斎藤( @saitoxu )です.
今回はGLITにおける求人検索の品質改善の方法について紹介します.
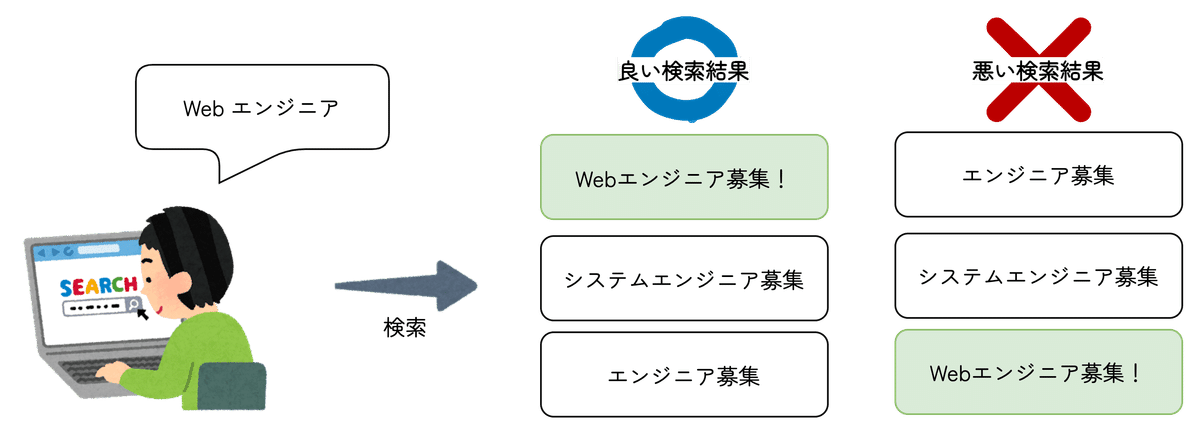
検索における品質とは何かと言いますと,ユーザがある検索条件で検索を実行したときに,そのユーザが求める検索結果を上位で表示できるかどうかの程度を指します(図1).
最近,この品質改善を定量的に行うための仕組み作りができてきて,これから積極的にやっていこうかという機運が高まってきました.
今回は,自分たちのようなこれから検索の品質改善に取り組むチームの参考になればと思い,弊社での取り組み内容を書いてみました.
それではどうぞ.
求人検索の品質改善
はじめに品質改善のための準備から運用までの全体像を図2に示します.

「①検索品質の定義決め」と「②検索品質を計算する基盤作り」が準備にあたり,運用では「③オンライン評価」「④改善」「⑤オフライン評価」のサイクルを回していくことになります.
書いてみたらそこそこの文量になったので,今回は準備について書き,運用については次回紹介します.
準備編
①検索品質の定義決め
検索品質を改善するといっても,それが定量化されていないと継続的に改善していくことは難しいです.
なので,最初に検索品質の定義を決めます.
こういった検索を良くしたいというモチベーションはアカデミックの分野でも古くからあり,品質を定量化する様々な評価指標が提案されています.
GLITではMean Reciprocal Rank(MRR)という評価指標を採用し,これで検索品質の良し悪しを測ろうと決めました.
MRRは検索結果のランキングを評価するための代表的な評価指標の1つで,正解データの順位の逆数の平均を取ったものです(何を持って正解とするかも決めないといけないですが,よくクリックなどが使われます).
正解データの順位が分かれば計算できるので,計算が容易であるといった点や,ランキングを改善したいという動機でGLITではMRRを採用しました.
※たとえば横に2つだけ検索結果を表示するようなUIの場合は,ランキングと言うよりは正解がその2枠に入るかどうかが大事なので,適合率などを設定するといいかもしれません.
MRRの計算方法を図1の例で説明します.「Web エンジニア」という検索に対し緑の求人が正解(クリックされた)とすると,
良い検索結果は緑が1位なのでMRR = 1 / 1 = 1
悪い検索結果は3位なのでMRR = 1 / 3
となります.MRRは1に近いほうがよいです.このようにして検索品質を定量化します.
その他の評価指標は下記の記事によくまとまっていると思うので,興味がある方は参照してください.
②検索品質を計算する基盤作り
検索品質の定義ができたら,次はそれを実際に計算できるようにログを保存する必要があります.
最低限保存が必要な情報は以下のようなものでしょうか.
①検索結果の閲覧ログ:通常,検索条件ごとに改善を行っていきたいので,ユーザが入力した検索条件も合わせて保存します.
②正解データの情報:正解(クリックされた,など)データの検索結果中の表示順位を保存します.①と紐付けて保存して,どの検索条件によるものかをトレースできるようにします.
上記の情報をログとして残すことで,検索条件ごとに評価指標を計算できるようになります.
最後に,簡単な具体例でログを使った評価指標の計算方法を見てみましょう.表1はある検索条件Aにおける①検索結果の閲覧ログと②正解データの情報になります.

ここから,検索条件AのMRRは次のように計算できます.
$$
\text{MRR} = \frac{1}{5}(0 + \frac{1}{6} + 0 + \frac{1}{3} + \frac{1}{1}) = 0.3
$$
運用フェーズでは評価指標をもとに,検索仕様の改善に取り組んでいくことになりますがその話はまた次回.
おわりに
以上,GLITにおける求人検索の品質改善の方法について紹介でした.
だいぶざっくりとした説明でしたが,イメージを掴んでいただけたら嬉しいです.
最後に,弊社では日本の仕事探しにおける負を一緒に解決してくれる仲間を募集しています.
下記の募集ポジションまたは,その他少しでも興味を持たれた方は斎藤のTwitterまでお気軽にご連絡ください.
この記事が気に入ったらサポートをしてみませんか?