
誰でもWebスクレイピングできちゃうOctoparseを使ってハローワークのクロールを試してみたので語ってみる

Webサイトから情報を取得して分析データとして活用したい❗️とか、Webサイトの情報を勝手にクロールして情報を分析したい❗️時ってたまにありますよね🙂
あるのか❓ないかなw
基本的には、クローラー、スクレイパーと言われるものは、ちょっとしたプログラムの経験があれば誰でも簡単に作れます😉
今回は、ノーコードのツールで誰でもWebスクレイピングができてしまうサービス「Octoparse」を試しに使ってみたので、少し語ってみますね。
とにかくOctoparseを使ってみたので、使い方とちょっとした感想。いつも通り、事実のみ書きますー✏️

とにかく試してみたいという人が使えるフリープランが用意されています。ラッキー✌️
利用できるのは以下の通り
・取得ページ数無制限
・インストール台数無制限
・データエクスポート10,000レコード/回
・並行ローカルタスク数* 2
・作れるタスク数 * 10

まず画面の下にいくとプランが表示されています。
無料ではじめるをクリック☝️
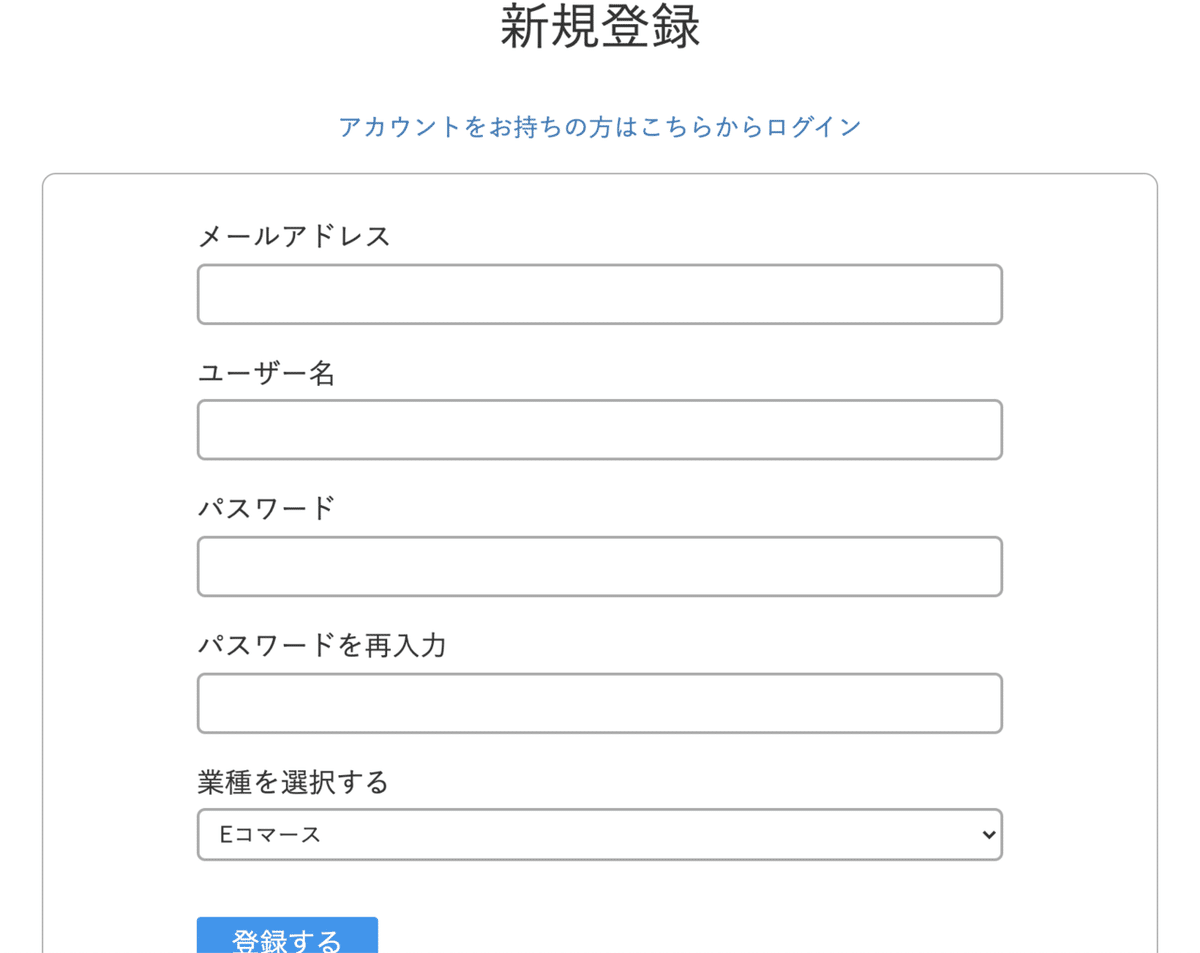
メールアドレス、ユーザー名、パスワード、業種を選択すると登録が完了します。

ダウンロードをクリックします☝️
macOS版とWindows版の最新版をダンロードします。
手順もダウンロードページに記載されているので、記載されているとおりにダウンロードします。
Macにダンロードされた octoparse が 開けない😭
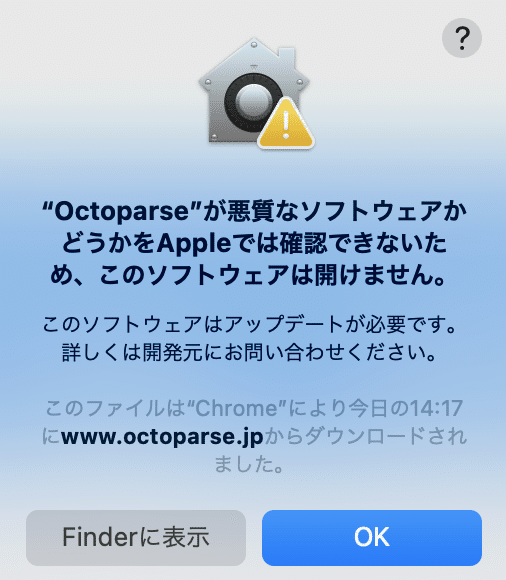
こんなメッセージが出る場合があります。このメッセージが出た場合は、どうしたらいいの❓
解決方法は、以下の通り
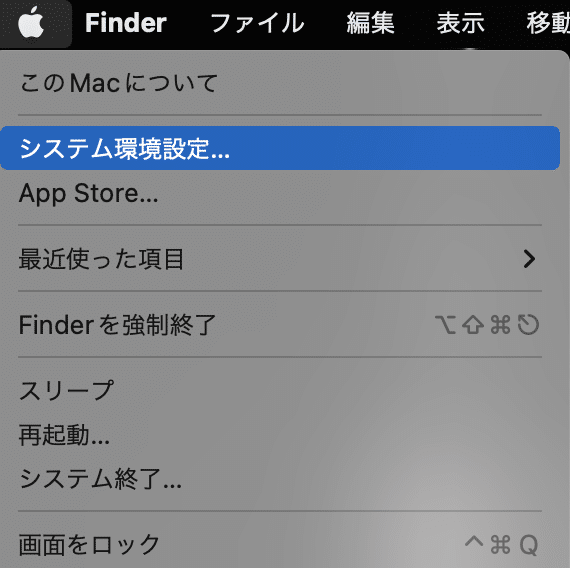
アップルメニューの「システム環境設定」をクリック☝️

「セキュリテとプライバシー」をクリック☝️

「一般」をクリック☝️
このままではダウンロードしたアプリケーションの実行許可を設定することができません😭
ターミナルで次のコマンドを入力します。Root権限の操作なのでパスワードの入力が求められます。パスワードを入力して実行すればOK👌
sudo spctl --master-disableもう一度、「セキュリティとプライバシー」>「一般」を開きます

すべてのアプリケーションを許可に設定が変更されました😉
この状態でOctoparseを起動してみます


ログイン画面が起動されるので、Web画面で入力したメールアドレスとパスワードを入力してログインしてみます😉

ログインに成功するとアプリが起動します✌️
クロールしたいサイトでメジャーなサイトは、人気のテンプレートとして既にテンプレートが用意されているので、そちらを利用しても良いでしょう。便利ですね⭕️
まずは、人気のテンプレートに対象サイトがあるかみてみよう❗️

求人情報サイトは、7社のテンプレートがあるようですが、今回は、ハローワークのクローリングを試してみたいので、テンプレートを活用する方法は次回試してみます😉
いきなり、やる前にホームのチュートリアルにあるカスタマイズモードの初心者ガイドをみてからやってみましょう❗️
6:30秒の動画で日本語で説明をしてくれます
STEP1 :WebサイトのURLを入力する💨

ホームの検索窓にURLを入力して抽出開始をクリック❗️

ワークフローを作成をクリックして、ワークフローを生成します。
データのあるページは、この次の一覧ページなので、アイテムをクリックする要素を追加して検索結果ページへ移動させます。
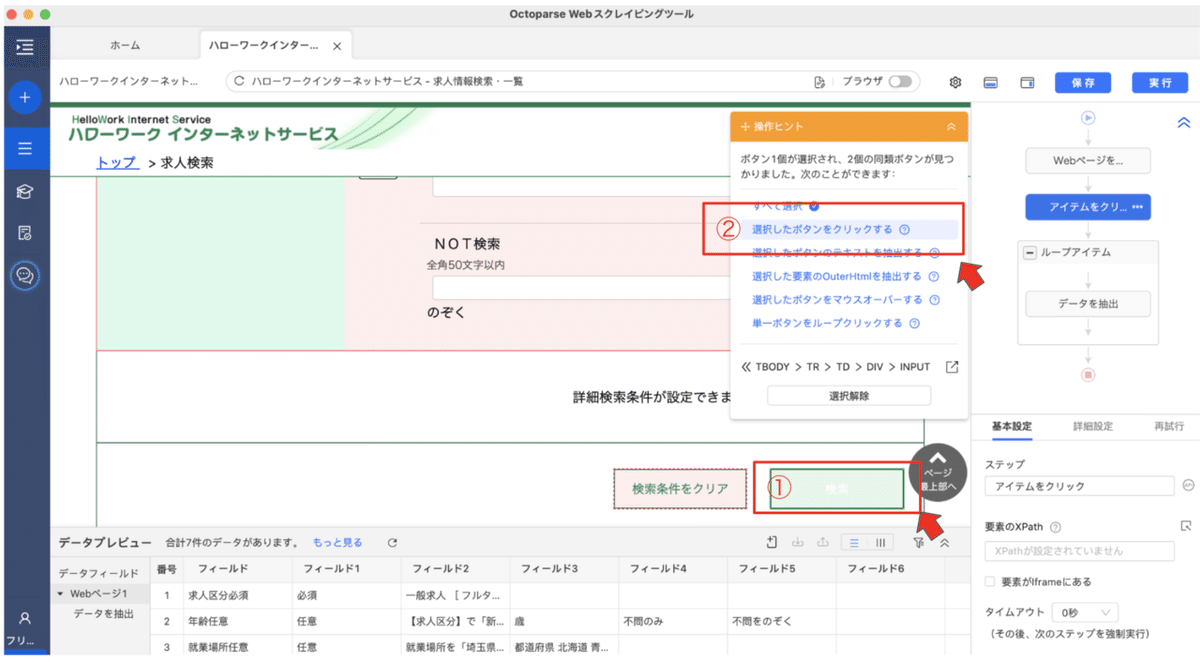
①クリックしたいアイテムをクリック☝️
②選択したボタンをクリックをクリック☝️
あまりの簡単さにスルーしてしまったけど、画面操作する動作がこのUIでサクッと設定できるのは良いですね✌️

Webページを自動識別するをクリックし、識別した内容を確認してデータ抽出をクリックします❗️
この抽出機能、マジでやばかった😲
ページの要素を自動で分析して、抽出できる情報を全てフィールドに変換して値を自動で詰めてくれちゃうんです。
プログラムで書く場合、難しくはないけど面倒で手間がかかる作業のとこです。
概念は同じですね、ターゲットのキーとバリューのセットで1次元のフィールドに落としてくれます。
プログラムでスクレイピングする際も、イチイチここの項目はこの名前でなんてことはしないし、必要なところだけ取れれば良いことが多いけど、1ページ全ての項目から値をとってくれるなんてすごいじゃないか🤗

①でデータの抽出内容が確認できます。要素を自動で判定して必要な項目を集めてくれます。
②ページネーションの設定をするをクリックします☝️
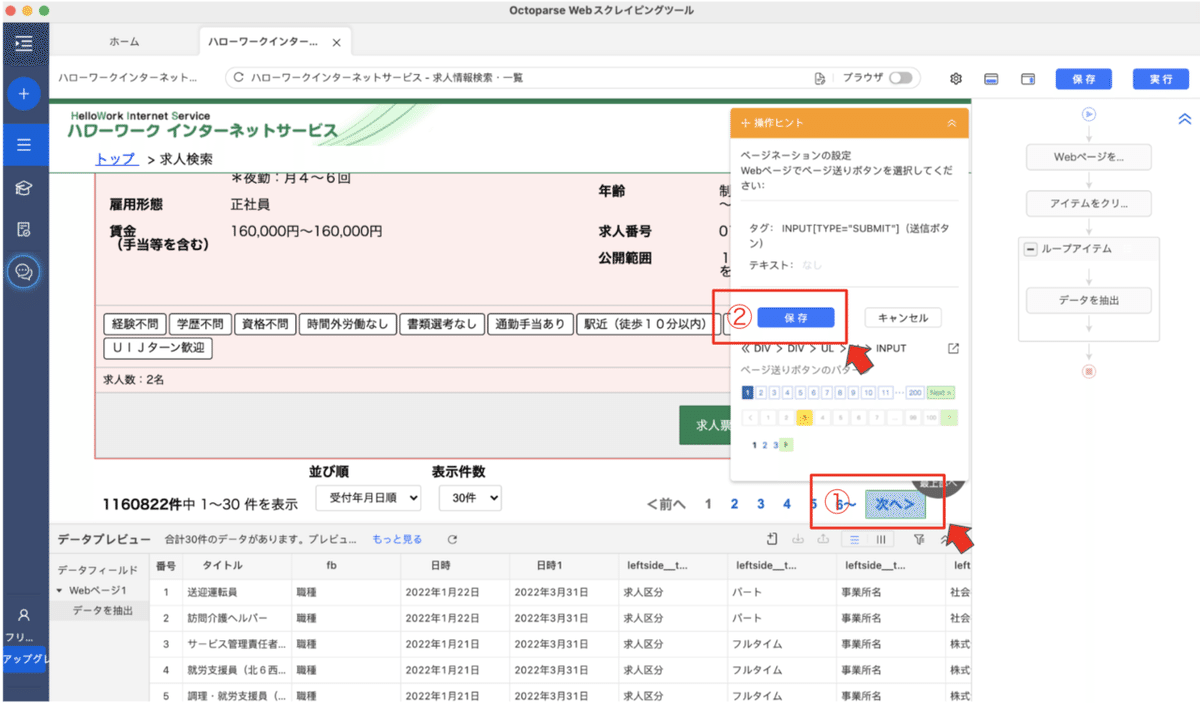
①ハローワークのページは、「次へ」のボタンがあるのでここをクリックして「保存」をクリック☝️

これでワークフローができました❗️
ハローワークのトップページから検索ボタンを押して、一覧に表示されている求人情報を抽出し、ページをすすめる処理です。
これで、100万件ほどある求人情報を1ページ 30求人のペースでデータを抽出してくれます😄
このまま実行すると全力でクローリングしてしまうので、1ページ1秒ルールを適応しておきましょう❗️
適応方法は、こちら

①次のページをクリックをクリック☝️
②詳細設定をクリック☝️
③実行前に秒数を待機をチェックして秒数を選ぶ☝️
④保存をクリック☝️
あとは、実行すれば、全ページのリストを取得することができます。
本当に動くの❓

こんな感じでページ遷移してデータを集めてくれます。
詳細ページのURLだけ欲しいので、少しデータ抽出のフォーマットを変えて実行(無料版はデータ件数が少ないので工夫しないと💦)
途中で止まっちゃわない❓

途中で止まっちゃいますねw。166 x 30= 4,980件ほどのURLを取得して終了😭
都道府県 x 業種 毎にワークフローを作れば、全体の80%くらいは取り込めるのでしょうね😉
実際に取得したデータはこんな感じで、検索結果ページに表示される30求人の詳細ページのURLを抽出してみました❗️

note書きながらやって、3時間ちょっとなので、Octoparseちょちょっとクロールの設定と実行するだけなら1時間で直ぐにデータ取得できちゃいます。
ここまで簡単にデータ取れるのは楽ちんでいいですね。
クロールを防止しているサイトなども有料ならサポートもありそうですし、なかなか良いツールなのでは❓
次回は、多分Stripe使ってみたーな話を予定してます🙇♂️
いいなと思ったら応援しよう!
