
動画生成AI『HunyuanVideo』のLoRAの、世界で一番簡単な作り方

本日のテーマはHunyuanVideo LoRA
こんにちは。およそ1年ぶりのnote投稿となります。
前回書いた 『2024年のComfyUI、完全入門』 はありがたいことに沢山の方に読んで頂き、初めて書いたこの1記事だけで150いいね・100フォロワーを達成してしまいました。読んでいただいた方々ありがとうございます。
沢山の方にフォローいただいたにも関わらず、なかなか次のnoteに取り掛かれずにいましたが、今回ローカルで動画生成が可能なHunyuanVideoでLoRAを試した際に、そのポテンシャルの高さに驚いたので、今回はそちらに関する内容を書こうと思います。
具体的なHunyuanVideo LoRAの作り方についても書いていくので、動画生成AIでオリジナルな表現をローカル完結で作りたい、そう考えている方はぜひ最後までご覧になってみてください。
ちなみに、前回がComfyUI入門だったのに、今度はいきなり動画生成AIのHunyuanVideoということで話題がかなり飛んでいる印象もあるかもしれませんが、そこについては過去に投稿したYouTube動画をご覧いただけると幸いです。
このように普段はYouTube上で画像生成・動画生成AIに関する動画を投稿しています。他にもComfyUIに関するトピックを始め、画像生成・動画生成AIに関する様々な内容を動画にして投稿しています。
よろしければチャンネル登録などもして普段の動画もチェックして頂けたら幸いです。
それでは本題に移ろうと思います。
HunyuanVideoのLoRAがすごい!?
最近はローカル動画生成も盛り上がってきています。具体的には
CogStudio
LTX-Video
HunyuanVideo
などが出てきており、これらはモデルが公開されていることもあり、手元のPCやGoogle Colabなどで気軽に動かすことが可能となっています。
最近LLM界隈ではDeepSeekが話題ですが、同様にオープンウェイトとなっており、動画生成に利用するモデルを手元にダウンロードして生成を行うことが可能となっています。
LTX-VideoやHunyuanVideoについてはComfyUIサポートも実現しており、ComfyUIの公式example内にすぐに動かせるワークフローが公開されています。
ローカル動画生成ではLTX-Videoが一番品質が高い…そう思っていました
これらのローカル動画生成の中でどれが一番オススメ?と聞かれたら、私はLTX-Videoを上げます。
理由としてはtxt2vidで生成した際の動画の質が一番高いからです。
(実際の動画については以下のYouTube動画内で紹介しているのでご覧になってみてください)
今回のテーマになっているHunyuanVideoも、ここ最近の動画生成の進化を感じさせるものではありつつも、LTX-Videoのほうが一歩先を行っている印象はありました…そう、LoRAを試すまでは。
HunyuanVideoはLoRAを使うとその真価を発揮する
これは以前Xに投稿した内容ですが、実はHunyuanVideoはLoRAを使うとクオリティが一気に跳ね上がります。
この仮説はあっていたようです
— サファ【AIイラスト多め】 (@safa_dayo) January 22, 2025
HunyuanVideoはLoRAを使うと一気にクオリティが上がります。まるでStable Diffusionの1.5のときのような感じで、ベースモデルではなくファインチューニングされたモデル(LoRA)ありきの生成モデルなのかもしれません https://t.co/r0oSAsEHhD pic.twitter.com/7L5NU4crkJ
画像生成に慣れ親しんでいる方にとっては、Stable Diffusion 1.5の頃を彷彿とさせるのではないでしょうか?
(SD1.5もベースモデルはイマイチですが、LoRAやファインチューニングされたモデルを使うと品質が一気に高くなります。みなさんはどんなモデルを愛用されていましたか?)
そして上の仮説を裏付けるようにCivitaiにはすでにたくさんのHunyuanVideo用のLoRAがすでに存在しています。ちなみにLTX-Videoなどの他の動画生成AIに関するLoRAもCivitaiのカテゴリーには存在していますが、調べた時点ではまたLTX-Video用のLoRAはありませんでした。
(CivitaiでのHunyuanVideo LoRAの検索方法は以下のとおりです)
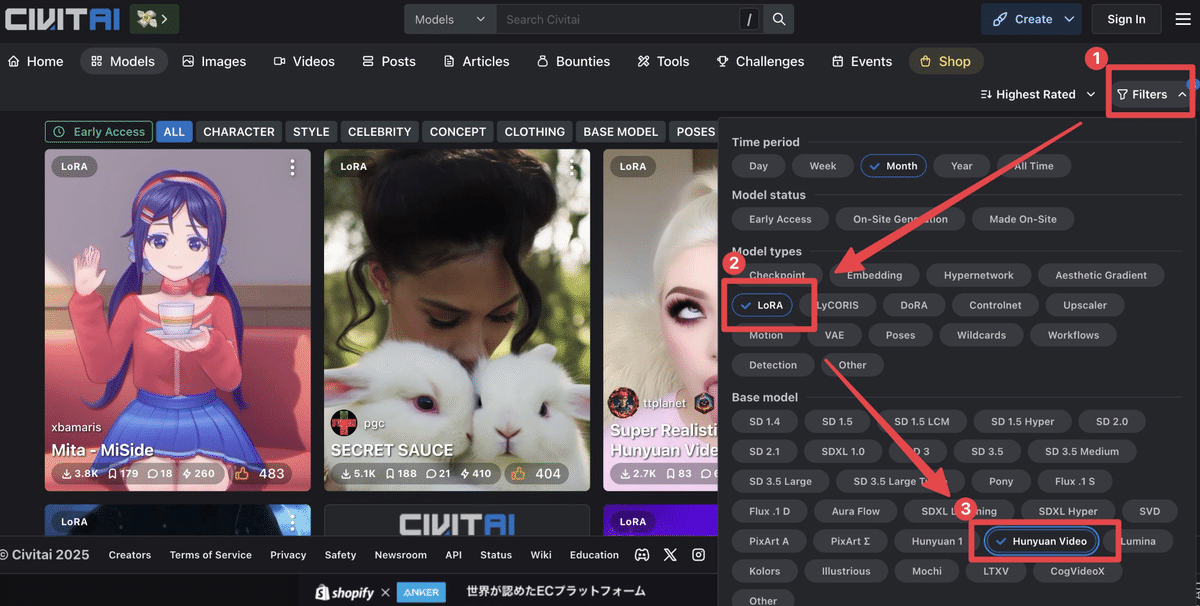
ちなみにどういったLoRAがあるかというと、例えば
動画のスタイルを変化させるもの(例:〇〇風)
人物に特定の表情や動きをさせるようなもの(例:人物に変顔させるなど)
人物の顔を〇〇にさせるもの(これはたぶんアウトなやつ)
などがありました。雰囲気的にはまさにStable DiffusionでLoRAが出始めたばかりのような雰囲気があり、良くも悪くもカオティックな印象です。
これから盛り上がっていき、洗練されていくんだろうな…という感じもあり、まさに飛ぶ鳥を落とす勢いを感じさせる状態になっています。
そんなわけで色々と興味深い動きが起きているHunyuanVideo界隈、私自身も早速HunyuanVideo LoRAについて紹介したYouTube動画を作成しました。
動画内で紹介している生成動画をご覧いただければ分かる通り、LoRA経由で生成した動画は一気に品質が上がります。
そして、HunyuanVideo LoRAを自分でも自由自在に作れるようになったら、より柔軟な動画表現が可能になるのではないか?と考えていましたが、このたびその作り方も分かりましたので、今回はそちらをテーマにnoteを書いていきます。
HunyuanVideo LoRAのとても簡単な作り方
なお、先にYouTube動画も作成して公開していますので、併せてこちらもご覧いただけると嬉しいです。
これを見れば画像5枚だけでLoRAを作ることが可能です。
動画生成AIであるHunyuanVideoのためのLoRAなのに静止画像5枚だけでLoRAが作れてしまうというのは、ちょっとすごくないですか?
HunyuanVideo LoRAを簡単に作れるGoogle Colabノートブックを作りました
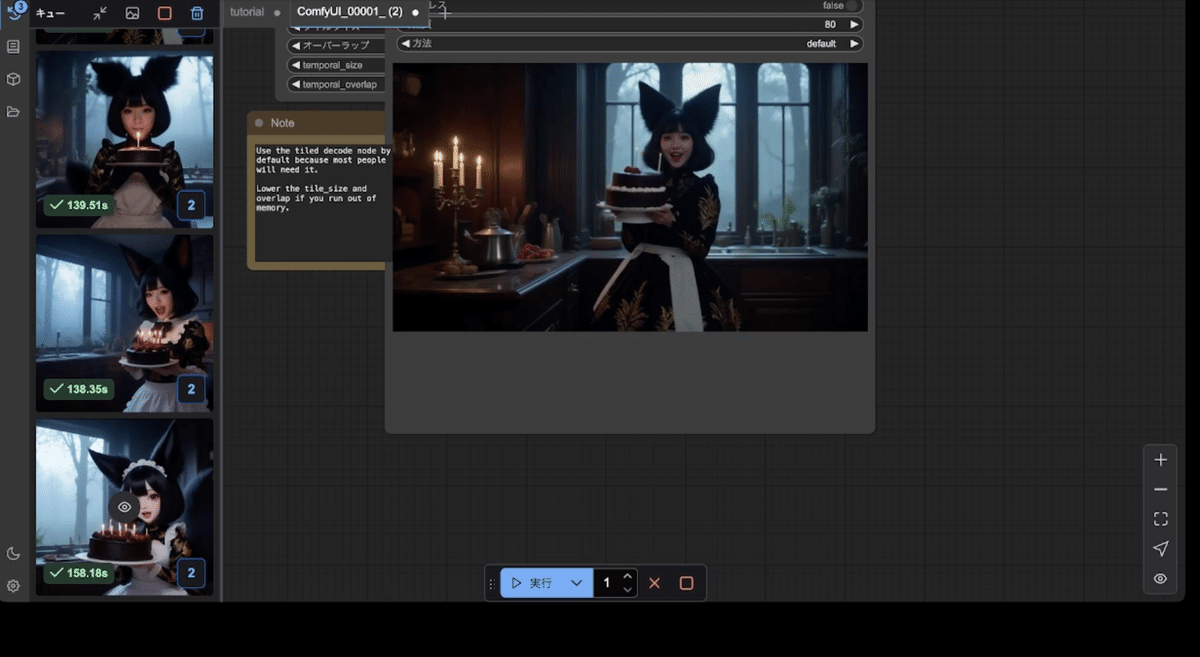
私は基本的に怠け者なので、HunyuanVideo LoRAといえど一番楽に作れる方法を探してしまいます。そして行き着いた結果、以下のGoogle Colabノートブックを作ることにしました。
hunyuanvideo_lora_training.sh (gist)
これは「Hunyuan Video」ベースのLoRAをColabローカル上で作成するためのノートブックとなり、学習素材は画像・動画のいずれかが利用可能です。
先にも書いた通り、私個人としては画像を学習させる方法が一番簡単に行えるLoRA作成方法なので、こちらの内容を紹介していきます。
まずは上のGoogle Colabノートブックを実際にコードセル単位でGoogle Colabにコピペしていきます
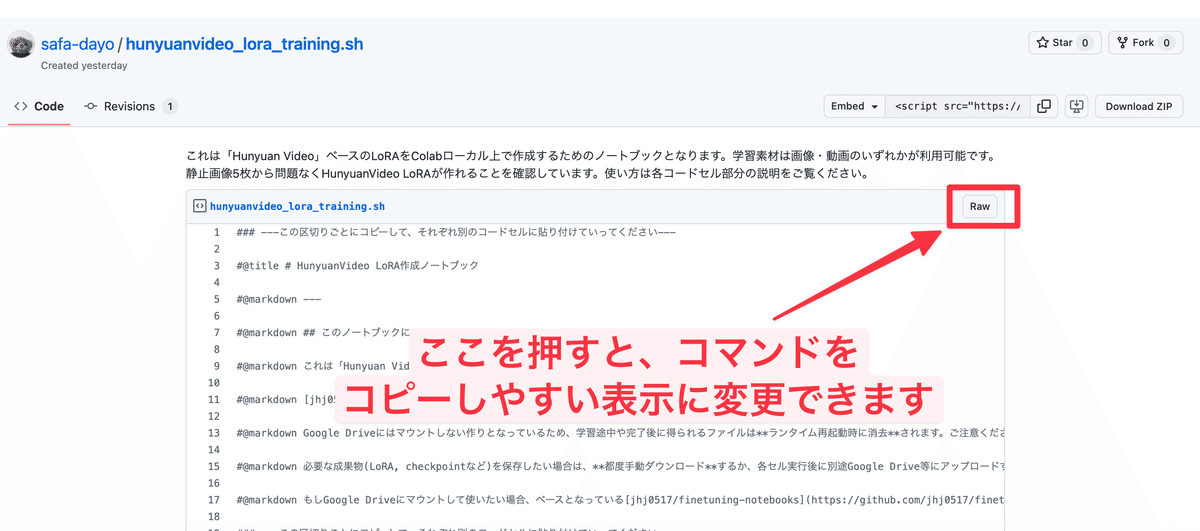
コピーの仕方ですが、### ---この区切りごとにコピーして、それぞれ別のコードセルに貼り付けていってください---、と書かれている間の記述をそれぞれGoogle Colabのコードセルに貼っていく形となります。

実際にGoogle Colabに貼っていくとこのような見た目になっていき、各コードの説明やパラメーター入力フォームなどが利用できるようになります。
HunyuanVideo LoRAの使い方
では、上に貼ったGoogle Colabノートブックの使い方について書いていきます。
今回は簡単にHunyuanVideo LoRAを作れることをテーマにしているため、最初にも書いた静止画像5枚だけをもとにLoRAを作るやり方を書いていきます
なお、こちらのColabノートブックは以下のColabノートブックをベースに作成しています。
当初は上のノートブックを使わせていただこうと考えていましたが、こちらのノートブックはGoogle Drive連携が前提の作りになっていました。
これは完全に私の好みですが、Colabノートブックで処理を行う際は不用意にGoogle Driveとの連携はしたくないと考えており、できればオプショナルな選択肢であってほしいと考えています。
(Google Colabのランタイム自体が隔離されたサンドボックス環境となっており、都度リセットされていくのも個人的には魅力的なポイントです)
そこで上のノートブックをベースにGoogle Driveとは連携しない形に作り変えさせていただいたのが、今回公開したColabノートブックとなります。
そのためGoogle Driveとの連携をしたいという方は上のColabノートブックを試してみてください。
さて、では使い方に移ります。
といっても簡単で、上から順にコードセルを実行していくだけです。
まずはライブラリのインストール
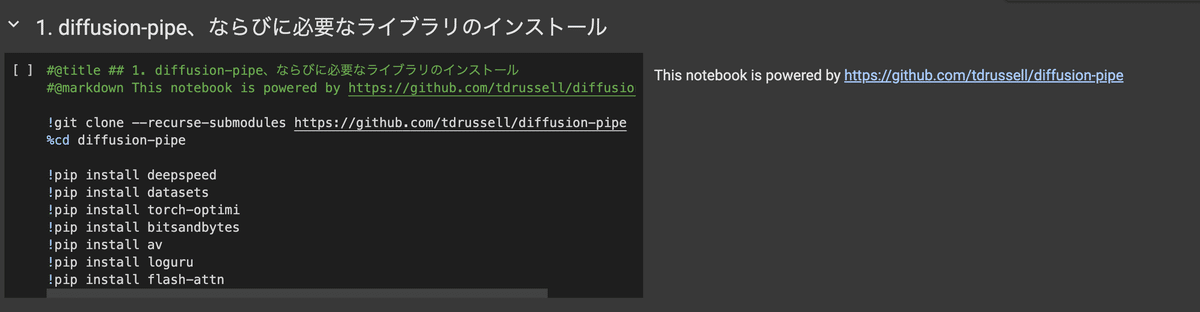
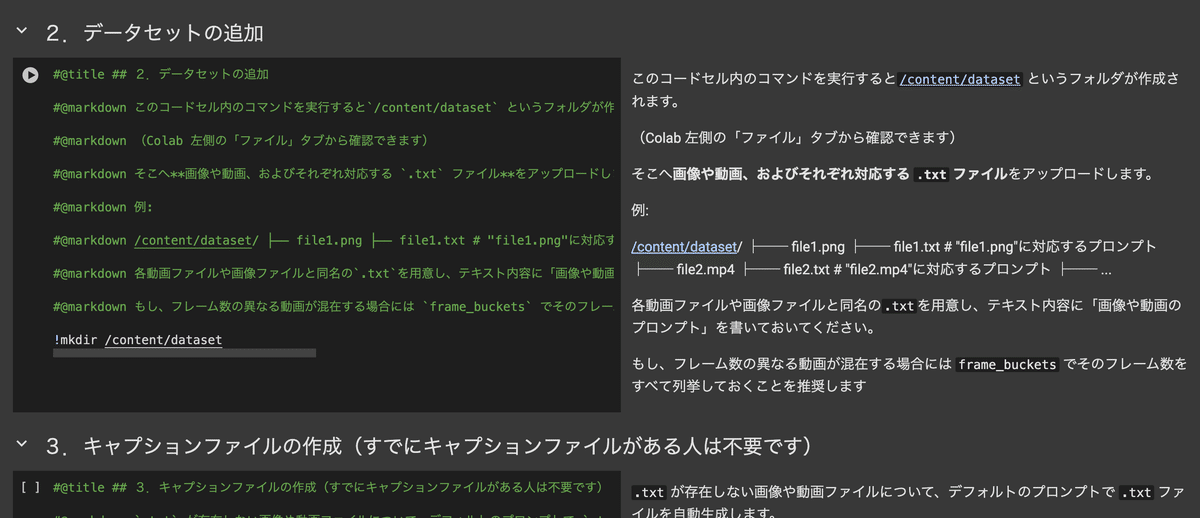
次にデータセットの追加。このコードセルを実行すると、/content/datasetというフォルダが作られるので、そちらに学習対象の画像・動画を格納してください。
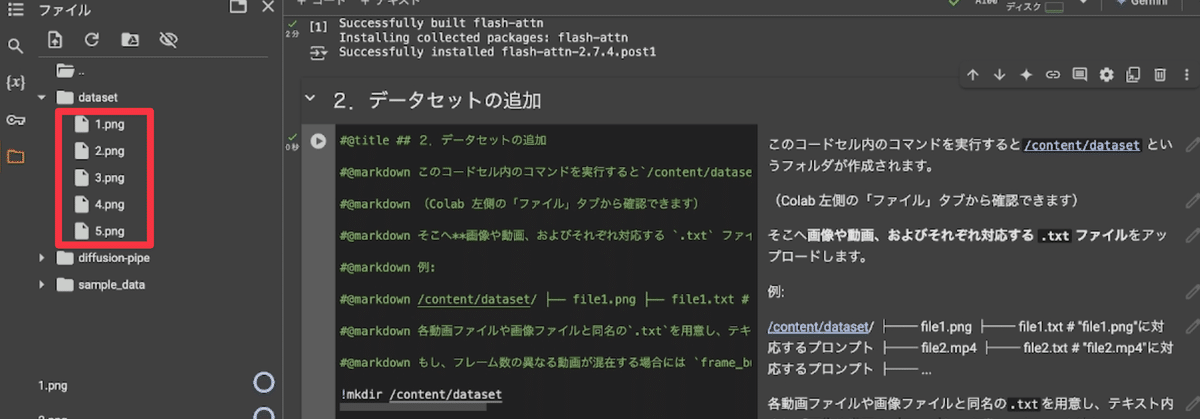
次にキャプションファイルの作成です。
LoRA学習の際は素材に対応したキャプションが必要になります。このキャプションの考え方、怠け者の私としてはいつもLoRA作る際に調べ直したりしています。
ただ、今回HunyuanVideo LoRAを作る際には難しいことは一切考えず、学習素材となる画像を生成した際のプロンプトをそのままキャプションにすることにしました。
(正直、これでやったら意図したLoRAが作れたので、もうこれでいいや、ぐらいの怠け精神でいます)
学習画像を /content/dataset に入れた状態で、以下のキャプションファイル作成のコードセルで、default_image_prompt欄にプロンプトを入れて実行をします。
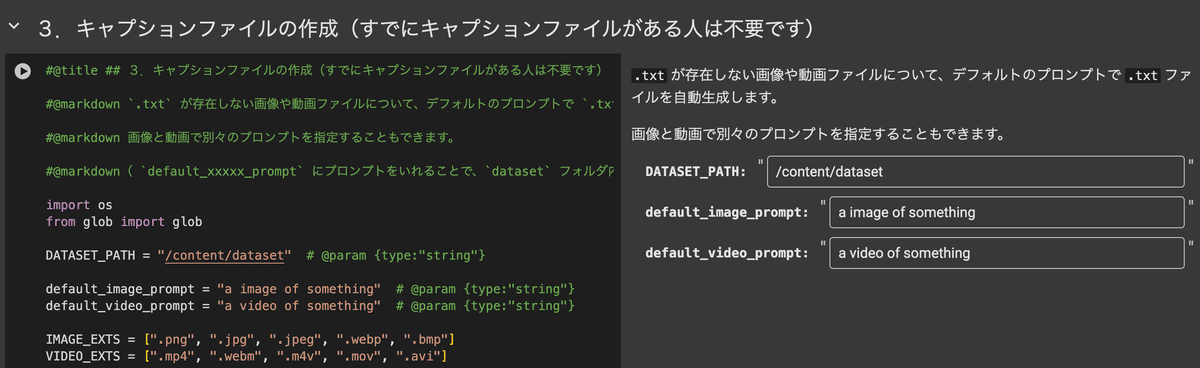
すると各画像に対応したキャプションファイルがテキストファイルとしてそれぞれ生成されます。中身は入力したプロンプトがそのまま入っているだけなので、もし丁寧に作りたい場合は手動で編集してください。
この処理はあくまで『楽したい人向けの安直な方法』となります。
ちなみに余談ですがLoRAのキャプションの考え方は、YouTubeチャンネル『ダルトワ★TV』さんの動画『LoRAの作り方(2023年11月版)【Stable Diffusion 初心者】』がとてもわかり易いのでオススメです。
(最新情報が乗った改訂版動画も出ていますので、これから見る方は上の動画の概要欄から改訂版を見ていただいたほうが良いかもしれません)
私もいつもLoRAを作るたびにこの動画を見返し、キャプションの考え方を学んでいます。
(HunyuanVideo LoRAもちゃんとキャプションをつければもっと品質あげられるかも…!)
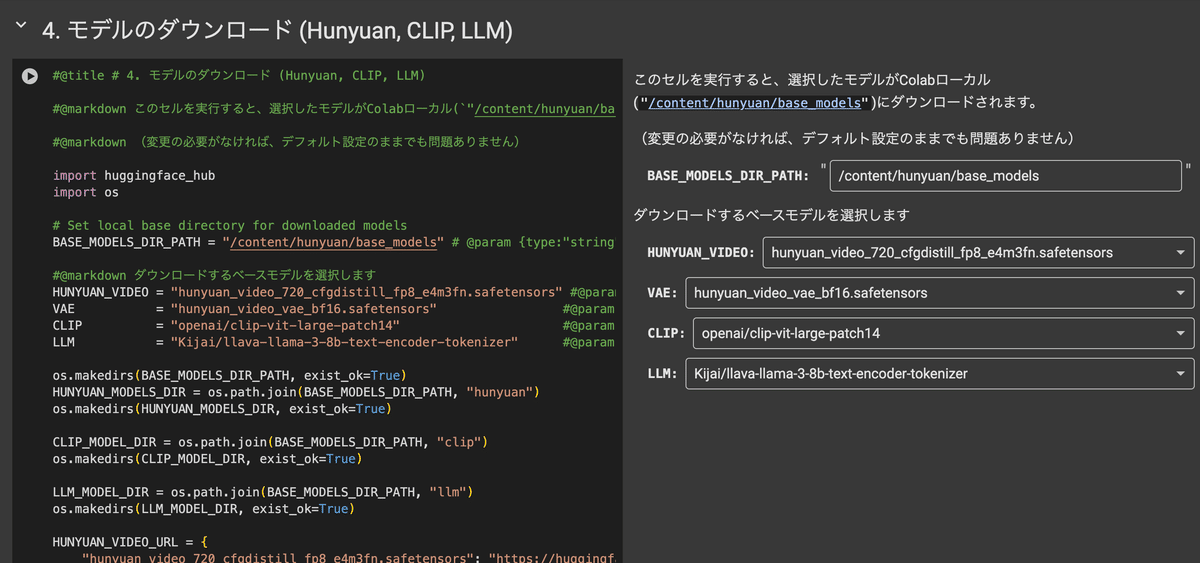
次にモデルのダウンロード処理です。
色々とモデルを選択できるようになっていますが、今回のケースでは何も変えずそのまま実行してしまって問題ありません。
そして次はいよいよトレーニングです。パラメーターも色々と変更可能ですので、最適な学習のためにはパラメーター調整も必要かと思います…が、今回はいちばん簡単なLoRA学習を目指すので、パラメーター調整も不要です。
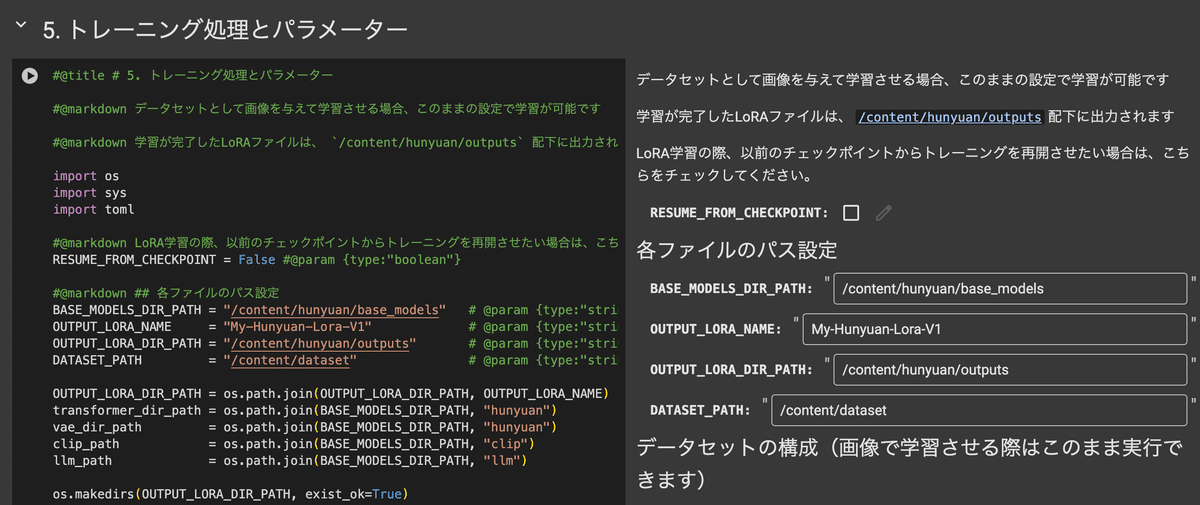
今回のように画像を学習してLoRAを作る際は、デフォルトの設定のままで学習できるようになっているので、これもそのまま実行しましょう。
気になる学習時間ですが、Google ColabのA100で20~30分程で学習が完了しました。
意外と動画用のLoRAでもそこまで学習時間は変わらないような気もします。が、今回はそもそも画像5枚だけという内容なので、動画などを学習させる際はもっと掛かりそうではあります。
学習が完了すると、/content/hunyuan/outputs というフォルダに作成されたLoRAが表示されていますので、こちらをダウンロードして完了です。
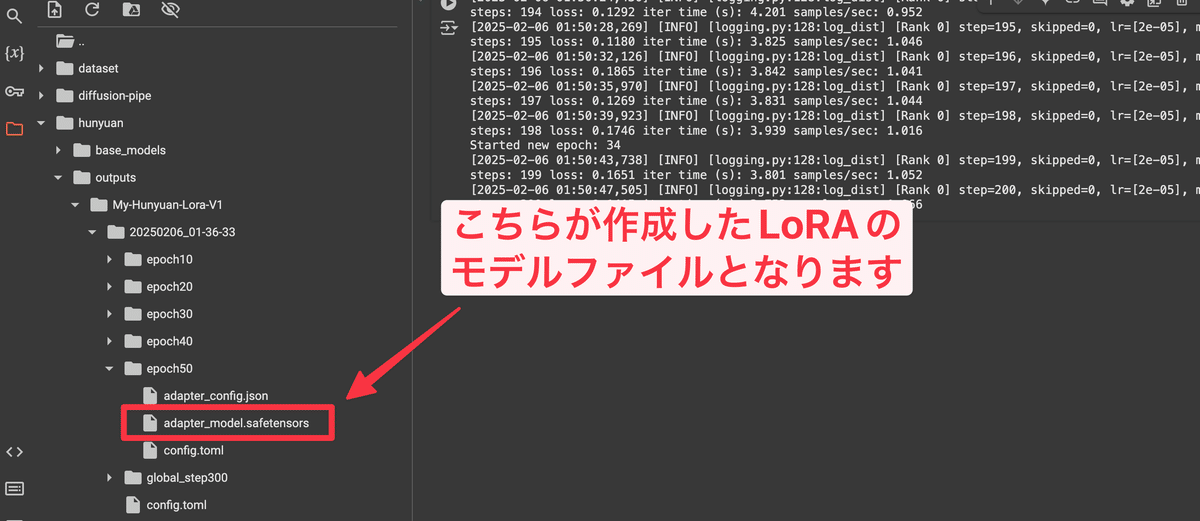
そして完成したフォルダも同様のフォルダ名配下に生成されます。
これでLoRA作成は完了です。
動画生成LoRAといえど、びっくりするぐらい簡単ですよね。
(この方法の場合、画像生成のLoRAよりも簡単かもしれません)
実際にHunyuanVideo LoRAを使ってみる!
実際に使う方法についてもご紹介します。
私はGoogle Colabをよく使うので、ComfyUI上に構築したHunyuanVideo環境が使える以下のColabノートブックを利用した前提で説明していきますね
(Windows PCなどを利用される方は各自ComfyUI環境を起動してください)
HunyuanVideo_with_ComfyUI.sh (Gist)
ComfyUI環境を起動したら、ComfyUI公式ページのワークフローをダウンロードしてドラッグ・アンド・ドロップで適用します
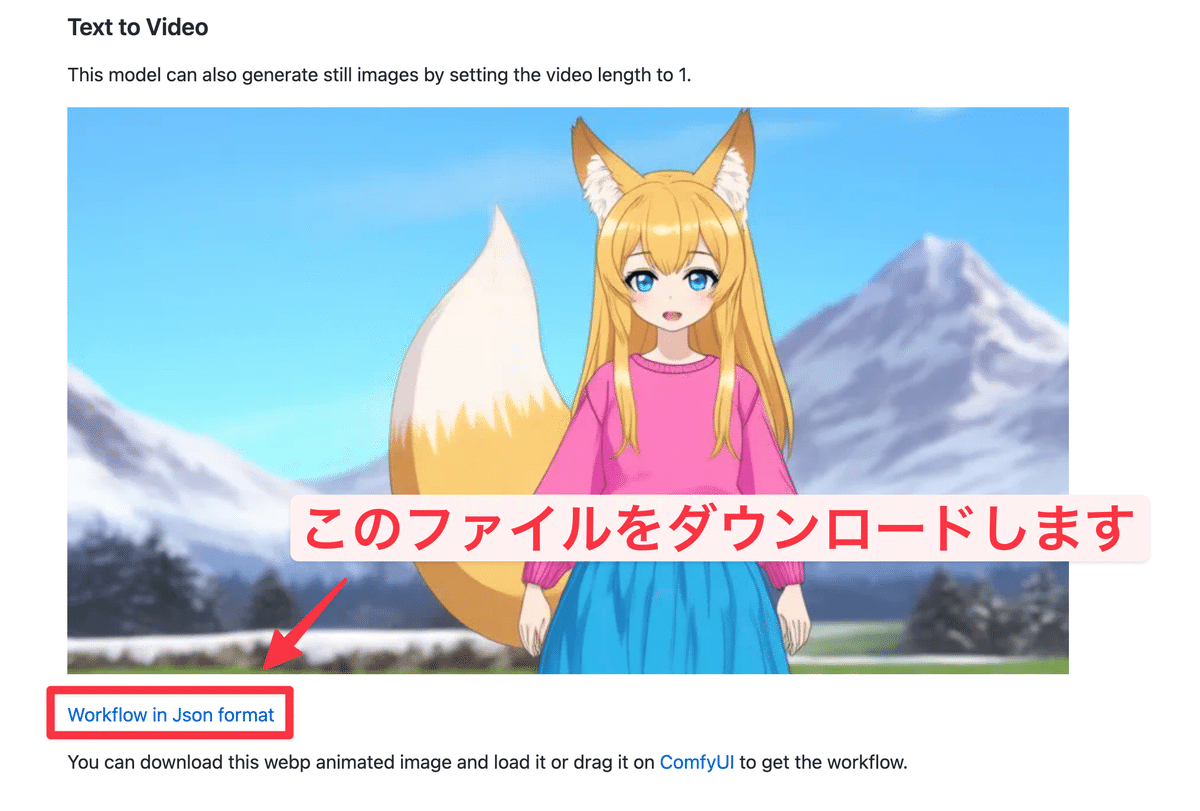
ダウンロードしたらComfyUIにドラッグ・アンド・ドロップすると、これだけでHunyuanVideoが使える状態になるかと思います
次に以下のようにLoRA読み込み用のノードを追加します
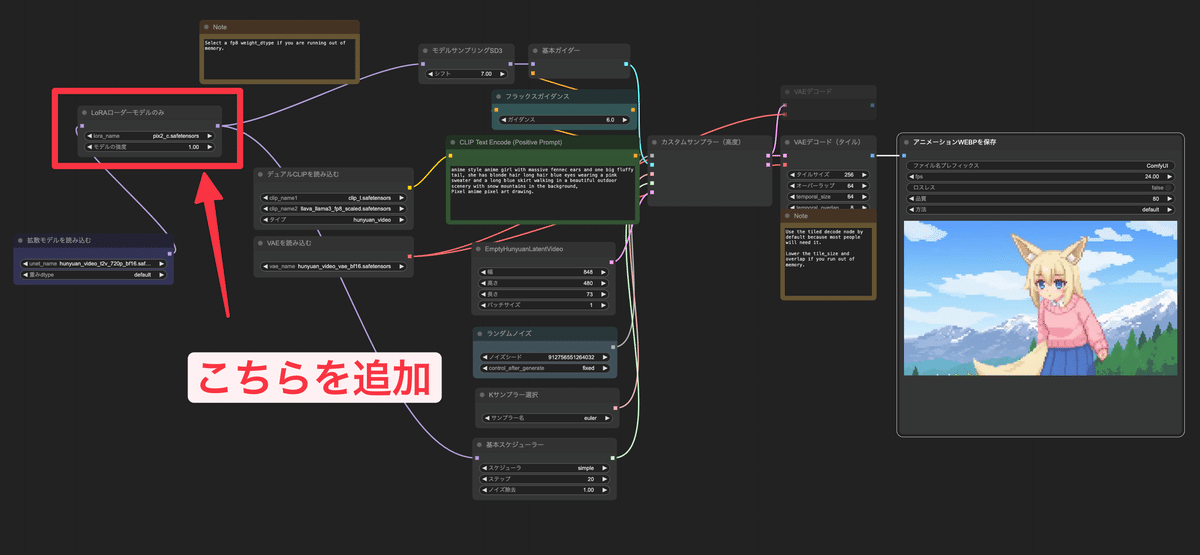
追加する場所ですが、
『拡張モデルを読み込む』ノードの後段
『モデルサンプリングSD3』と『基本スケジューラー』ノードの前段
に挟んで設定してください。
次に先ほど作成したLoRAファイルをComfyUIのLoRA用のフォルダに追加します。
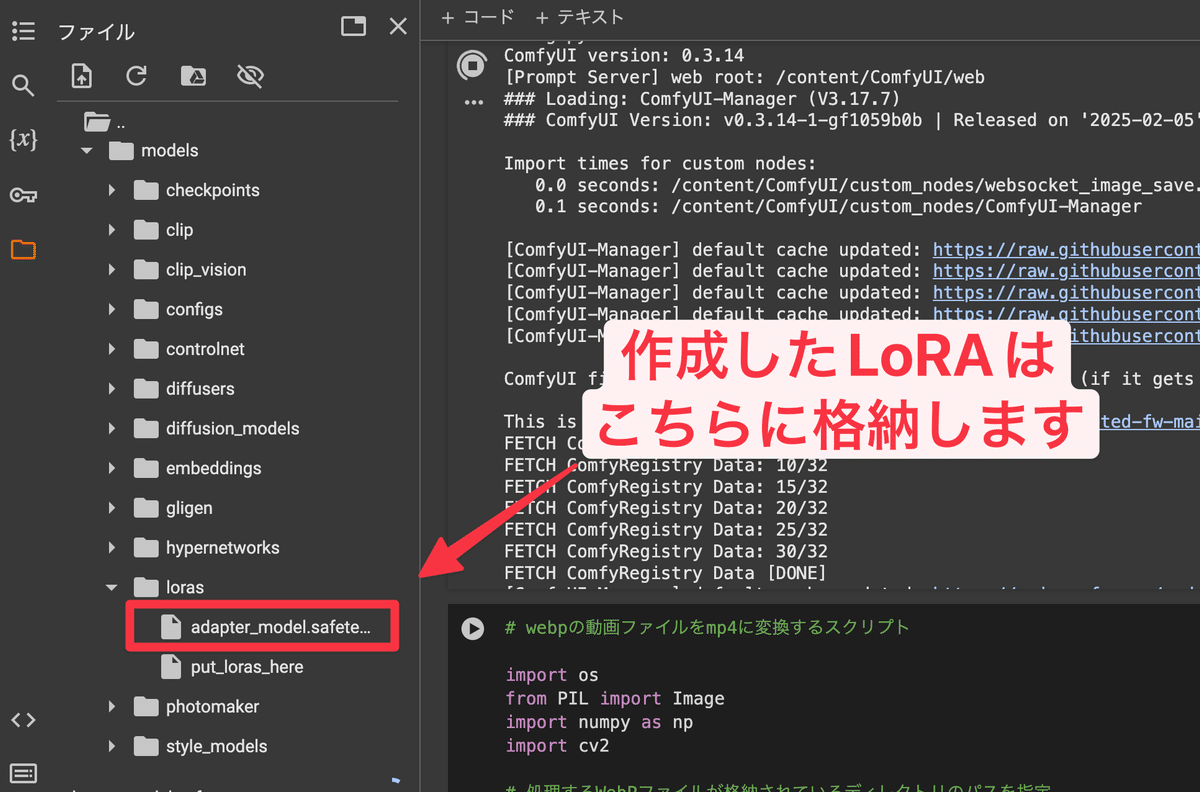
次に先ほどのLoRA読み込み用のノードに追加したLoRAファイルを設定します。
そして次にプロンプトですが、実は今回のLoRA学習ではトリガーワードを設定していません。
トリガーワードは使わず、キャプションにも用いた元画像のプロンプトをそのまま動画生成時のプロンプトとして用います
これで学習した画像がそのまま動き出したかのような動画が作れます。
例えばこれは学習に利用した画像のうちの1枚です。

そしてこの画像から作成したLoRAを利用して生成した動画がこちら
(noteには動画は貼れないようなのでXの投稿を貼ります)
同じやり方でリアル系画像でも問題なくLoRAできました
— サファ【AIイラスト多め】 (@safa_dayo) February 6, 2025
HunyuanVideo LoRA使えば、ある程度狙った動画をローカル環境完結で生成できてしまうかも https://t.co/DIkXPEU9y3 pic.twitter.com/5vfmWKBVX8
これを見ると、だいぶ狙った世界観を反映できていると思います。
これがこんな簡単に実現できるのはちょっとした衝撃でした。
HunyuanVideo LoRAの可能性
ここに書いた内容は簡単にLoRAを作るための方法であり、例えば特定の動きをさせる、とか、生成した被写体に特定のエフェクトを付与させる、といった複雑な処理は実現できないと思います。
ですが、まずはここからHunyuanVideo LoRAを試してみていただいて、「動画生成AIのLoRAもこんな簡単に作ることができるんだ!」という感想を持ってもらえたら嬉しいです。
最初にも書いた通り、HunyuanVideo LoRAの勢いはStable Diffusionの1.5時代を彷彿とさせるものがありますし、今年は間違いなくローカルで動かせる、オープンウェイトな動画生成モデルも進化していく年になるかと思います。
ぜひHunyuanVideo LoRAを活用して、思い思いの動画表現をしていって頂けたらと思います!